






前言
LeNet是深度学习领域的‘hello,world’。大部分人学习深度学习都是从最简单的卷积神经网络入手,结合我自己的学习经验,整理记录一下学习笔记,与大家交流。开源的精髓是分享,独乐乐不如众乐乐。只有一起交流沟通,才能更好的学习。
一、一些简单介绍
深度学习领域的大神之一,YANN LECUN,在他的paper《Gradient-Based Learning Applied to Document Recognition》中提出了LeNet架构,尽管在今天看来,文章中的一些观念已经过时了,但这篇文章确实是神经网络的奠基作。YANN LECUN将此网络命名为LeNet。LeNet实现了一个卷积神经网络,并基于此在Mnist手写数字数据集上进行了实现。Mnist数据集也是我们目前学习卷积神经网络的入门数据集。
今天我们重新再来看这篇文章,首先回顾一下LeNet的网络结构:
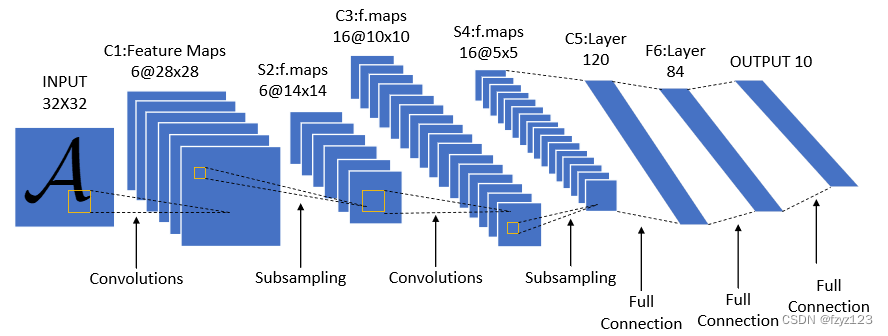 LeNet网络结构整体比较简单,包括两个卷积层,两个池化层,然后后面接了三个全连接层。给定一个3232像素的输入,经过6个55的卷积核,得到6@2828的特征,然后经过一个池化层AvgPool,通道不变,高宽减半,得到6@1414的特征,接着使用16个55的卷积核,得到16@1010的特征,再经过一个池化层AvgPool,高宽减半,得到16@5*5的特征,后面是三个全连接层MLP,最后得到十分类的输出。
LeNet网络结构整体比较简单,包括两个卷积层,两个池化层,然后后面接了三个全连接层。给定一个3232像素的输入,经过6个55的卷积核,得到6@2828的特征,然后经过一个池化层AvgPool,通道不变,高宽减半,得到6@1414的特征,接着使用16个55的卷积核,得到16@1010的特征,再经过一个池化层AvgPool,高宽减半,得到16@5*5的特征,后面是三个全连接层MLP,最后得到十分类的输出。
网络架构参考如下,我们只需要实例化一个Sequential块并将需要的层连接在一起。
#构建网络架构LeNet-5
net = nn.Sequential(
nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid()(),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Flatten(),
nn.Linear(16*5*5,120),nn.Sigmoid()(),
nn.Linear(120,84),nn.Sigmoid()(),
nn.Linear(84,10)
)
几点补充说明:目前我们使用的激活函数通常用nn.ReLU(),池化操作通常用MaxPool。
关于MNIST数据集
- 图像数量
MNIST数据集包含60,000张训练图像和10,000张测试图像,这些图像代表了0到9之间的手写数字。 - 图像规格
每张图像都是28x28像素的灰度图像,这意味着每个像素点的强度值范围从0(白色)到255(黑色),但通常在使用前会进行归一化处理,将其缩放到0到1之间。 - 数据来源
这些手写数字图片来源于大约250个不同的人,其中一半是高中生,另一半是人口普查局的工作人员,确保了多样性和泛化能力。 - 数据结构
数据集被分为四个部分,分别是训练图像、训练标签、测试图像和测试标签,便于模型的训练和验证。
二、Mnist手写数据集上的LeNet实现,基于pytorch
开始代码复现之前,我们需要Anaconda+Pyorch+Jupyter+Vscode的编程环境实现,我一开始入门,折腾环境配置折腾了好几天才算搞明白。这部分不在这里讲,网上有很多教程可以参考,自己动手折腾几遍就熟悉了。
1.引入库
我们需要使用torch和torchvision库,然后我们导入了d2l库(李沐的课上用的,偷懒用,有很多函数已写好)
import torch
from torch import nn
from torch.utils import data
from d2l import torch as d2l
import torchvision
from torchvision import datasets,transforms
2.加载数据集
第一步加载数据集,代码如下,其他数据集可以直接在此基础上修改。
#加载数据集
trans = transforms.ToTensor()
mnist_train = datasets.MNIST(root='./data',train=True,transform=trans,download=True)
mnist_test = datasets.MNIST(root='./data',train=False,transform=trans,download=True)
batch_size = 256
train_data_iter = data.DataLoader(mnist_train,batch_size,shuffle=True)
test_data_iter = data.DataLoader(mnist_test,batch_size,shuffle=False)
我们使用torchvision.datasets模块加载训练集和测试集。
- torchvision.datasets模块
内置数据集提供了多种预处理过的标准数据集,如:MNIST、CIFAR10/CIFAR100、Fashion-MNIST、ImageNet等。
我们使用数据集加载器torch.utils.data.DataLoader,可以方便地对数据进行批量处理、随机打乱、并行加载等操作,提高了数据处理效率。
3.定义性能评估函数
通过使用GPU,可以用它加快训练。由于完整的数据集位于内存中,因此在模型使用GPU计算数据集之前,我们需要将其复制到显存中。我们定义了一个evalute_acc_gpu函数,用来计算正确率。
def evalute_acc_gpu(net,data_iter,device=None):
if isinstance(net,nn.Module):
# 将模型设为评估模式
net.eval()
if not device:
device=next(iter(net.parameters())).device
metric = d2l.Accumulator(2)
with torch.no_grad():
# 遍历数据迭代器,计算模型预测的准确率
for X,y in data_iter:
if isinstance(X,list):
X=[x.to(device) for x in X]
else:
X= X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X),y), y.numel())
return metric[0]/metric[1]
4.定义训练函数
我们定义了一个训练函数,进行批量训练,我们使用Xavier随机初始化模型参数。与全连接层一样,我们使用交叉熵损失函数和小批量随机梯度下降。我们定义了一个动画器animator来进行图标的可视化。
#定义训练函数
def train(net,train_iter,test_iter,lr,num_epochs,device):
#初始化权重,这里使用Xavier初始化
def init_weights(m):
if type(m)==nn.Linear or type(m)==nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('train on',device)
# 将模型移动到指定的计算设备(通常是GPU)
net.to(device)
# 设置优化器(这里使用SGD)和损失函数(交叉熵损失)
optimizer=torch.optim.SGD(net.parameters(),lr=lr)
loss = nn.CrossEntropyLoss()
# 使用d2l.Animator来实时可视化训练过程中的损失和准确率变化。
animator = d2l.Animator(xlabel='epoch',xlim=[1,num_epochs],legend=['train loss','train acc','test acc'])
timer,num_batches=d2l.Timer(),len(train_iter)
#遍历每个epoch,对每个小批量数据进行前向传播、反向传播和权重更新。
#记录训练损失和准确率,每训练完一定比例的小批量就更新动画。
#每个epoch结束时,评估并记录测试集上的准确率。
for epoch in range(int(num_epochs)):
metric=d2l.Accumulator(3)
net.train()
for i ,(X,y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X,y =X.to(device),y.to(device)
y_hat = net(X)
l=loss(y_hat,y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l*X.shape[0],d2l.accuracy(y_hat,y),X.shape[0])
timer.stop()
train_l = metric[0]/metric[2]
train_acc = metric[1]/metric[2]
if (i+1)%(num_batches//5)==0 or i==num_batches-1:
animator.add(epoch+(i+1)/num_epochs,
(train_l,train_acc,None))
test_acc = evalute_acc_gpu(net,test_iter)
animator.add(epoch+1,(None,None,test_acc))
# 最后,打印出训练损失、训练准确率和测试准确率,以及每秒处理的样本数
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
5.训练
最后,我们使用上述的模型进行训练。
通过调整学习率lr,和迭代轮次num_epochs,可以观察到我们的输出结果。
lr, num_epochs = 0.1, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.051, train acc 0.985, test acc 0.976
25902.3 examples/sec on cuda:0

可以观察到,我们的结果在迭代4轮以后就开始收敛了,最终的test_acc达到了0.976,这是一个相对简单的数据集,通过调参,我们是可以接近甚至达到100%的。
总结
本文主要是我学习过程的总结,大概介绍了LENET的基本结构,并利用pytorch在mnist数据集上进行了复现。代码可以作为一个模板,对一系列数据集进行LENET网络的实现。只需要修改加载数据集部分代码即可。
写在最后:码字不易,倘若您读着还满意,觉得有那么一丁点点收获,没有浪费您宝贵的几分钟,就请点赞收藏加关注哈。。。















 1702
1702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









