







一、什么是PCA?
在数据挖掘或者图像处理等领域(大维度数据)经常会用到主成分分析(Principle Component Analysis),
这样做的好处是使要分析的数据的维度降低了,在减小计算所需消耗的内存并提高运算速度的情况下,
能够将数据的主要信息保留下来。
PCA是最常见的降维算法,其定义,可以从两个方面来理解:
①
最大化投影后数据的方差(让数据更分散)
;②
最小化投影造成的损失
。
这两个思路最后都能推导出同样的结果。
下图是从第二个角度来理解PCA的。
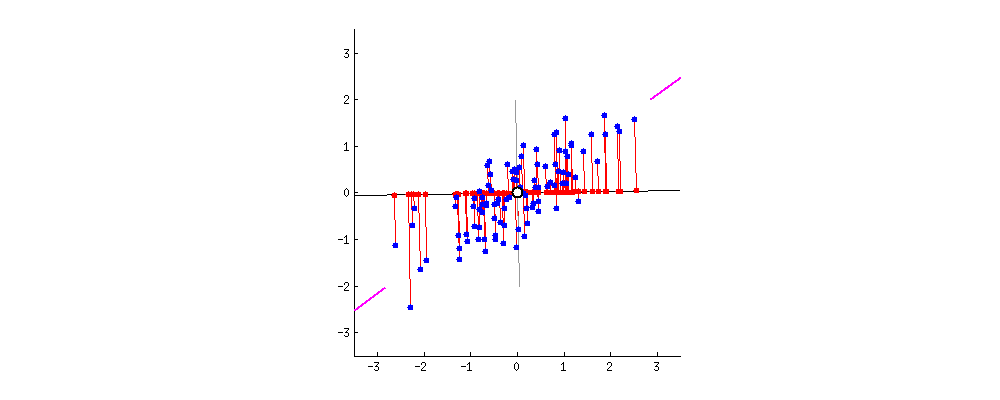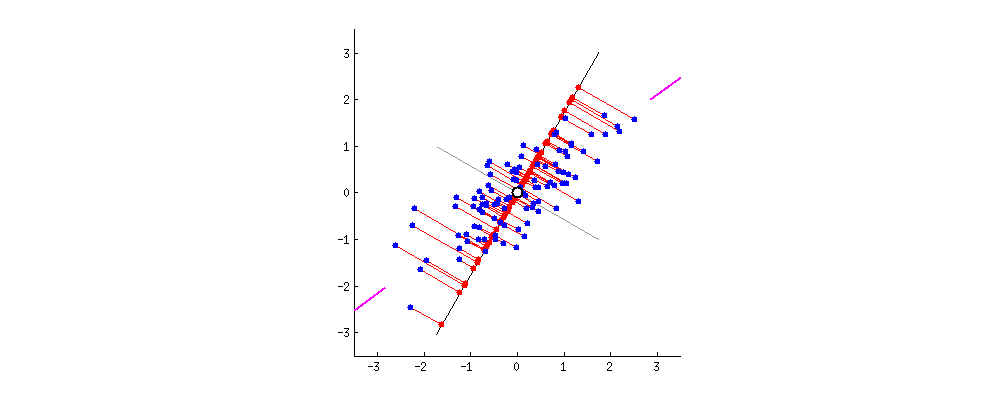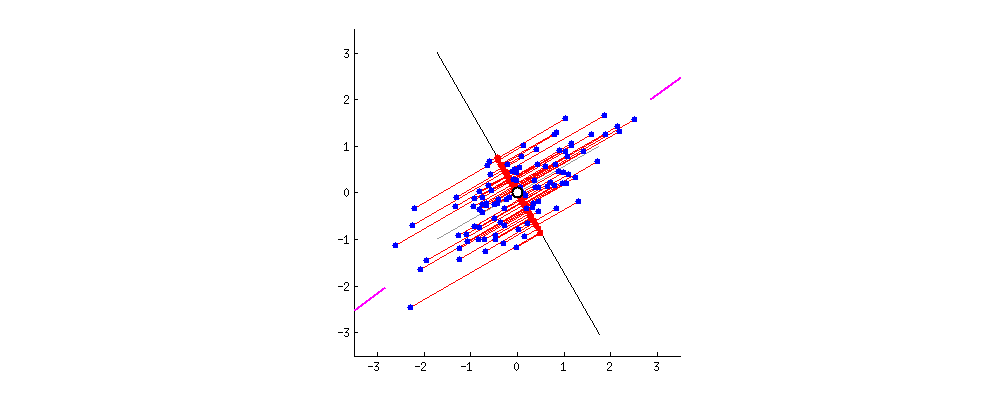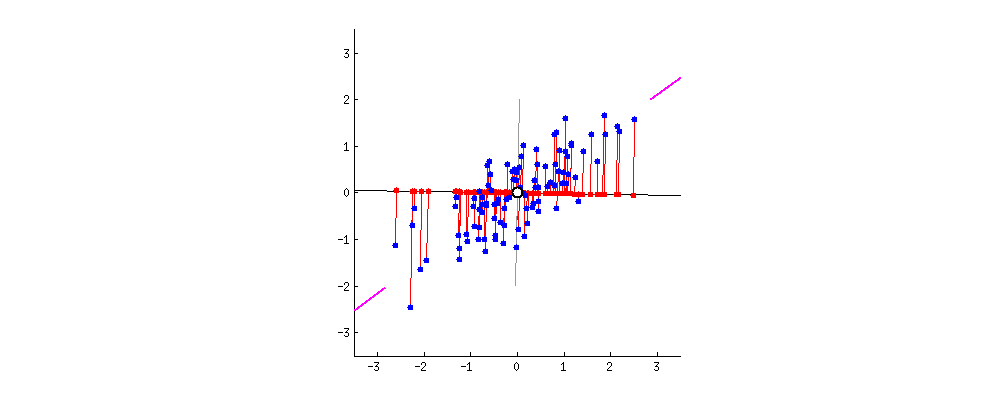

即对上面的二维的数据而言,我们想把其降为一维,即找出一个方向向量(Vector Direction),把所有的样本点都投影到该向量上,计算所有样本到这个向量的 垂线长度 (见上图,称为 投射误差 (Projection Error)))。
二、数据降维怎么理解?
以三维空间为例,假设三维空间中有一系列样本点,这些点分布在斜面上,如果你用自然坐标系x1,x2,x3这三个轴来表示这组数据的话,需要使用三个维度。而事实上,这些点的分布可能仅仅是在一个二维的平面上,那么,为什么会这样呢?我们要看到这个过程的本质,如果把这些数据按列排成一个矩阵(3行m列,每一列为一个样本),那么这个矩阵的秩(rank)就为2(矩阵中秩的概念),即行数据之间是有相关性的,这些数据构成的过原点的向量的最大线性无关组包含2个向量。有趣的是,由于三点一定共面,也就是说三维空间中任意三点中心化后都是线性相关的,一般来讲n维空间中的n个点一定能在一个n-1维子空间中分析。所以,不要说数据不相关,那是因为坐标没选对!

上图为将数据从三维转换为二维表示。
三、PCA推导
由于按PCA的第二种方法推导起来有困难,即求垂线距离这块会增加很多计算量。
这里还是采用第一种方法:最大化投影后数据的方差(让数据更分散)。
Step One:数据去中心化
对数据集(m个样本,n个维度)
,其中每个样本形式为
。

计算每个维度的均值
![]() ,然后将每个样本减去这个均值,
,然后将每个样本减去这个均值,
得到![]() 去中心化的矩阵
去中心化的矩阵
 。
。
。
Step Two:选择最大化的投影后数据方差
我们用一组(n个)标准正交基 (实际上就是坐标系)
(实际上就是坐标系)
(实际上就是坐标系)
来描述各样本点在其上的投影( 根据数据维度n,我们定义n个标准正交基,j=1,2,....,n)。计算投影的方法就是做内积:假设我们要找的投影方向是,
所以,我们的目的是使得目标函数最大化。
目标函数由向量性质,可以转换为:

将 记为S
记为S![]() ,这里用拉格朗日乘子法构造最大化问题
,这里用拉格朗日乘子法构造最大化问题![]() 。
。
记为S
此时,让上式最大化,即:
得到:
![]() ,将此式代入原始的目标函数中,得
,将此式代入原始的目标函数中,得 。
。
。
Step Three:选择主特征
根据前两步可以得出结论:要使得目标函数最大,即主轴选取应该按特征值的大小来排序:特征值最大的为第一个特征,依次类推。
同样,当需要去除某几个维度的时候,即按特征值lambda大小排序,把最小的几个特征值去掉即可。
四、遗留问题
Q1:为什么S有极大值?
Answer:对S而言,如果前面没有1/m,那它就是一个标准的二次型。由于二次型必为实对称矩阵,所以下面证明S是半正定:对于对称矩阵而言,半正定的充要条件是特征值都大于等于0。

Q2:为什么不是计算协方差矩阵?对协方差矩阵进行矩阵分解?(如SVD等)
因为在去中心化的时候,我们实际上就已经得到![]() 为
为![]() 。而S实际上就是协方差矩阵的形式(因为S的特征值和1/m无关)。
。而S实际上就是协方差矩阵的形式(因为S的特征值和1/m无关)。
结语:
这里只讲述了用拉格朗日乘子法求解的方式,这种方法是适用于样本数和特征数相等的情况(即方阵,
因为如果不相等,
那么每个样本点xi为1xn,而uj为mx1.显然在m不等于n的情况下,xi不能投影到uj上。)
因此实际上,(m大于n)应该
用SVD求解。如需转载,请联系qq:314913739














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









