







目录
前言
本文提供代码主要是基于 https://github.com/NotGlop/docker-drag 提供的代码修改的。链接中提供的代码应该是是基于HTTPS api V2 Manifest V 2, Schema 1实现的,在 Schema 2 下无法正常运行,而开源作者没有进行相应的更新,于是就自己想办法解决了。后续对上述链接里的代码简称为原代码。
下载镜像代码
修改为适配 HTTPS api V2 Manifest V 2, Schema 2 的代码如下所示
import argparse
import os
import sys
import gzip
from io import BytesIO
import json
import hashlib
import shutil
import requests
import tarfile
import urllib3
urllib3.disable_warnings()
if len(sys.argv) < 2 :
print('Usage:\n\tdocker_pull.py [registry/][repository/]image[:tag|@digest]\n')
exit(1)
# Look for the Docker image to download
repo = 'library'
tag = 'latest'
parser = argparse.ArgumentParser()
parser.add_argument("--os", type=str,required=False)
parser.add_argument('--digest', type=str,required=False)
parser.add_argument('--architecture', type=str,required=False)
args = parser.parse_known_args()[0]
manifest_os = args.os
manifest_digest = args.digest
manifest_architecture = args.architecture
imgparts = sys.argv[1].split('/')
try:
img,tag = imgparts[-1].split('@')
except ValueError:
try:
img,tag = imgparts[-1].split(':')
except ValueError:
img = imgparts[-1]
# Docker client doesn't seem to consider the first element as a potential registry unless there is a '.' or ':'
if len(imgparts) > 1 and ('.' in imgparts[0] or ':' in imgparts[0]):
registry = imgparts[0]
repo = '/'.join(imgparts[1:-1])
else:
registry = 'registry-1.docker.io'
if len(imgparts[:-1]) != 0:
repo = '/'.join(imgparts[:-1])
else:
repo = 'library'
repository = '{}/{}'.format(repo, img)
# Get Docker authentication endpoint when it is required
auth_url='https://auth.docker.io/token'
reg_service='registry.docker.io'
resp = requests.get('https://{}/v2/'.format(registry), verify=False)
if resp.status_code == 401:
auth_url = resp.headers['WWW-Authenticate'].split('"')[1]
try:
reg_service = resp.headers['WWW-Authenticate'].split('"')[3]
except IndexError:
reg_service = ""
# Get Docker token (this function is useless for unauthenticated registries like Microsoft)
def get_auth_head(type):
resp = requests.get('{}?service={}&scope=repository:{}:pull'.format(auth_url, reg_service, repository), verify=False)
access_token = resp.json()['token']
auth_head = {'Authorization':'Bearer '+ access_token, 'Accept': type}
return auth_head
# Docker style progress bar
def progress_bar(ublob, nb_traits):
sys.stdout.write('\r' + ublob[7:19] + ': Downloading [')
for i in range(0, nb_traits):
if i == nb_traits - 1:
sys.stdout.write('>')
else:
sys.stdout.write('=')
for i in range(0, 49 - nb_traits):
sys.stdout.write(' ')
sys.stdout.write(']')
sys.stdout.flush()
# Fetch manifest v2 and get image layer digests
auth_head = get_auth_head('application/vnd.docker.distribution.manifest.v2+json')
resp = requests.get('https://{}/v2/{}/manifests/{}'.format(registry, repository, tag), headers=auth_head, verify=False)
#resp = requests.get('https://{}/v2/{}/blobs/{}'.format(registry, repository, "sha256:ea0203747a6b779d26ceee879ff9c1d8b70c0d10196a4f969f8ceb4d1e3904bb"), headers=auth_head, verify=False)
if (resp.status_code != 200 or not 'layers' in resp.json()):
print('[-] Cannot fetch manifest for {} [HTTP {}]'.format(repository, resp.status_code))
print(resp.content)
auth_head = get_auth_head('application/vnd.docker.distribution.manifest.list.v2+json')
resp = requests.get('https://{}/v2/{}/manifests/{}'.format(registry, repository, tag), headers=auth_head, verify=False)
opt_manifest_digest = None
opt_mediaType = None
if (resp.status_code == 200):
manifests = resp.json()['manifests']
for manifest in manifests:
if manifest_digest == manifest['digest']:
opt_manifest_digest = manifest_digest
opt_mediaType = manifest['mediaType']
break
if manifest["platform"]["architecture"] == manifest_architecture and manifest["platform"]["os"] == manifest_os:
opt_manifest_digest = manifest['digest']
opt_mediaType = manifest['mediaType']
break
for key, value in manifest["platform"].items():
sys.stdout.write('{}: {}, '.format(key, value))
print('digest: {},mediaType :{}'.format(manifest["digest"],manifest["mediaType"]))
if opt_manifest_digest is None:
print('[+] Manifests found for this (use the --digest or --os --architecture to pull the corresponding image):')
exit(1)
else:
auth_head = get_auth_head(opt_mediaType)
resp = requests.get('https://{}/v2/{}/manifests/{}'.format(registry, repository, opt_manifest_digest), headers=auth_head,
verify=False)
layers = resp.json()['layers']
# Create tmp folder that will hold the image
imgdir = 'tmp_{}_{}'.format(img, tag.replace(':', '@'))
os.mkdir(imgdir)
print('Creating image structure in: ' + imgdir)
config = resp.json()['config']['digest']
confresp = requests.get('https://{}/v2/{}/blobs/{}'.format(registry, repository, config), headers=auth_head, verify=False)
file = open('{}/{}.json'.format(imgdir, config[7:]), 'wb')
file.write(confresp.content)
file.close()
content = [{
'Config': config[7:] + '.json',
'RepoTags': [ ],
'Layers': [ ]
}]
if len(imgparts[:-1]) != 0:
content[0]['RepoTags'].append('/'.join(imgparts[:-1]) + '/' + img + ':' + tag)
else:
content[0]['RepoTags'].append(img + ':' + tag)
empty_json = '{"created":"1970-01-01T00:00:00Z","container_config":{"Hostname":"","Domainname":"","User":"","AttachStdin":false, \
"AttachStdout":false,"AttachStderr":false,"Tty":false,"OpenStdin":false, "StdinOnce":false,"Env":null,"Cmd":null,"Image":"", \
"Volumes":null,"WorkingDir":"","Entrypoint":null,"OnBuild":null,"Labels":null}}'
# Build layer folders
parentid=''
for layer in layers:
ublob = layer['digest']
# FIXME: Creating fake layer ID. Don't know how Docker generates it
fake_layerid = hashlib.sha256((parentid+'\n'+ublob+'\n').encode('utf-8')).hexdigest()
layerdir = imgdir + '/' + fake_layerid
os.mkdir(layerdir)
# Creating VERSION file
file = open(layerdir + '/VERSION', 'w')
file.write('1.0')
file.close()
# Creating layer.tar file
sys.stdout.write(ublob[7:19] + ': Downloading...')
sys.stdout.flush()
auth_head = get_auth_head('application/vnd.docker.distribution.manifest.v2+json') # refreshing token to avoid its expiration
bresp = requests.get('https://{}/v2/{}/blobs/{}'.format(registry, repository, ublob), headers=auth_head, stream=True, verify=False)
if (bresp.status_code != 200): # When the layer is located at a custom URL
bresp = requests.get(layer['urls'][0], headers=auth_head, stream=True, verify=False)
if (bresp.status_code != 200):
print('\rERROR: Cannot download layer {} [HTTP {}]'.format(ublob[7:19], bresp.status_code, bresp.headers['Content-Length']))
print(bresp.content)
exit(1)
# Stream download and follow the progress
bresp.raise_for_status()
unit = int(bresp.headers['Content-Length']) / 50
acc = 0
nb_traits = 0
progress_bar(ublob, nb_traits)
with open(layerdir + '/layer_gzip.tar', "wb") as file:
for chunk in bresp.iter_content(chunk_size=8192):
if chunk:
file.write(chunk)
acc = acc + 8192
if acc > unit:
nb_traits = nb_traits + 1
progress_bar(ublob, nb_traits)
acc = 0
sys.stdout.write("\r{}: Extracting...{}".format(ublob[7:19], " "*50)) # Ugly but works everywhere
sys.stdout.flush()
with open(layerdir + '/layer.tar', "wb") as file: # Decompress gzip response
unzLayer = gzip.open(layerdir + '/layer_gzip.tar','rb')
shutil.copyfileobj(unzLayer, file)
unzLayer.close()
os.remove(layerdir + '/layer_gzip.tar')
print("\r{}: Pull complete [{}]".format(ublob[7:19], bresp.headers['Content-Length']))
content[0]['Layers'].append(fake_layerid + '/layer.tar')
# Creating json file
file = open(layerdir + '/json', 'w')
# last layer = config manifest - history - rootfs
if layers[-1]['digest'] == layer['digest']:
# FIXME: json.loads() automatically converts to unicode, thus decoding values whereas Docker doesn't
json_obj = json.loads(confresp.content)
del json_obj['history']
try:
del json_obj['rootfs']
except: # Because Microsoft loves case insensitiveness
del json_obj['rootfS']
else: # other layers json are empty
json_obj = json.loads(empty_json)
json_obj['id'] = fake_layerid
if parentid:
json_obj['parent'] = parentid
parentid = json_obj['id']
file.write(json.dumps(json_obj))
file.close()
file = open(imgdir + '/manifest.json', 'w')
file.write(json.dumps(content))
file.close()
if len(imgparts[:-1]) != 0:
content = { '/'.join(imgparts[:-1]) + '/' + img : { tag : fake_layerid } }
else: # when pulling only an img (without repo and registry)
content = { img : { tag : fake_layerid } }
file = open(imgdir + '/repositories', 'w')
file.write(json.dumps(content))
file.close()
# Create image tar and clean tmp folder
docker_tar = repo.replace('/', '_') + '_' + img + '.tar'
sys.stdout.write("Creating archive...")
sys.stdout.flush()
tar = tarfile.open(docker_tar, "w")
tar.add(imgdir, arcname=os.path.sep)
tar.close()
shutil.rmtree(imgdir)
print('\rDocker image pulled: ' + docker_tar)使用方法
方法1
首先执行如下命令
python docker_pull.py minio/minio此时控制台会输出如下日志。可以从中选择自己想要下载版本镜像的Manifest
os 为镜像所属系统
architecture 为镜像所属cpu架构(amd64即x86的)
digest 作为唯一key选择使用的清单
将自己选择的 Manifest 对应的 digest 代入如下命令执行
pyhon docker_pull.py minio/minio --digest=<digest>

方法二
直接执行如下命令
python docker_pull.py minio/minio --os=linux --architecture=amd64上述命令的意思是从 Manifest 列表中选择第一个为 linux 系统且 cpu 架构为 amd64 的Manifest 进行下载
os 和 architecture 根据自己的需要配置
按上述方法如果下载成功则可以在 docker_pull.py 问题同目录看到如下 tar 文件
原代码中无法适配 Schema 2 的原因浅析
首先原代码是请求下面的链接
http get /v2/<name>/manifests/<tag>Schema 1 中上面链接是可以直接返回一个镜像 manifest 的详情,返回结果中会包含镜像对应的图层 layers 字段。然后原代码会拿去这个 layers 字段相关的参数去拉取镜像文件。
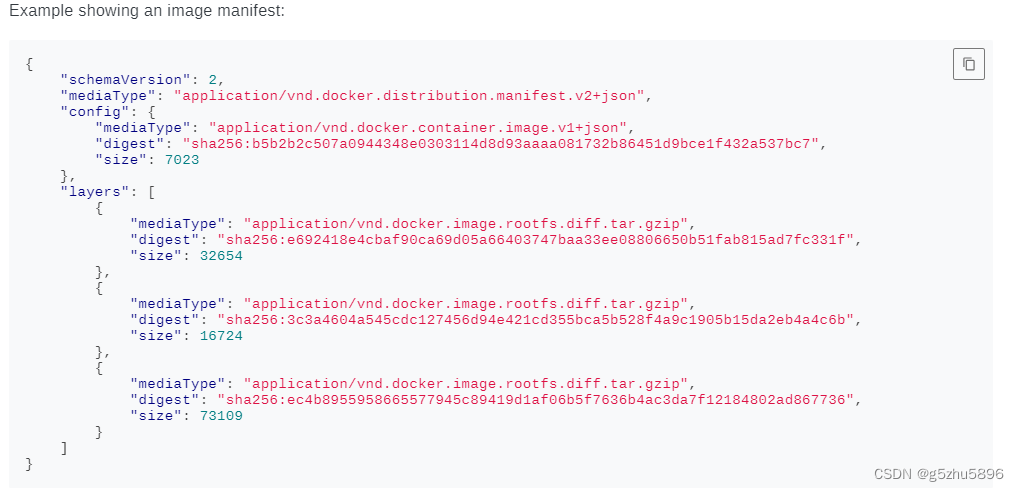
而Schema 2 中则返回一个 manifest 列表,列表中包含不同平台的及不同 cpu 架构对应的manifest,如下图所示

图中并不包含 layers,因此原开源代码使用出现了如下的错误

上述说法无法确保正确。有兴趣的可以自行看下面两个链接
https://distribution.github.io/distribution/spec/manifest-v2-2/
https://distribution.github.io/distribution/spec/api/
如何解决
Schema 2中 返回的 manifest 列表的每条manifest 会包含 manifest 的唯一识别码 digest 和 mediaType,可以拿 digest 和 mediaType 请求如下链接(mediaType 是放在请求头 Accept 中)
http get /v2/<name>/manifests/<digest>从而获取到 manifest 的详情,此处的详情是包含layers的,如下图所示
于是可以根据这个返回结果中的 layers 走原代码之前的逻辑去拉取镜像包。
相对原代码改动的东西
只改了如下两个地方,其他东西都没懂
1.增加了如下代码
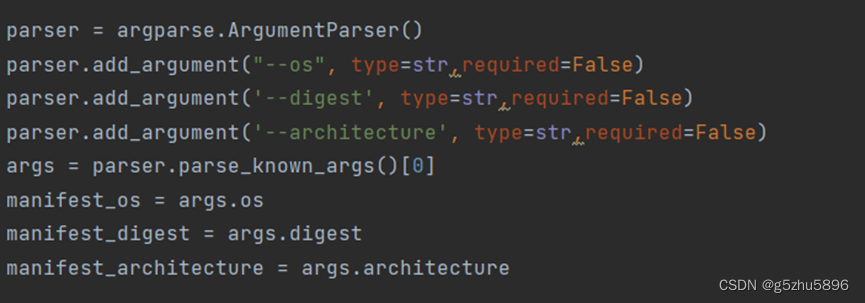
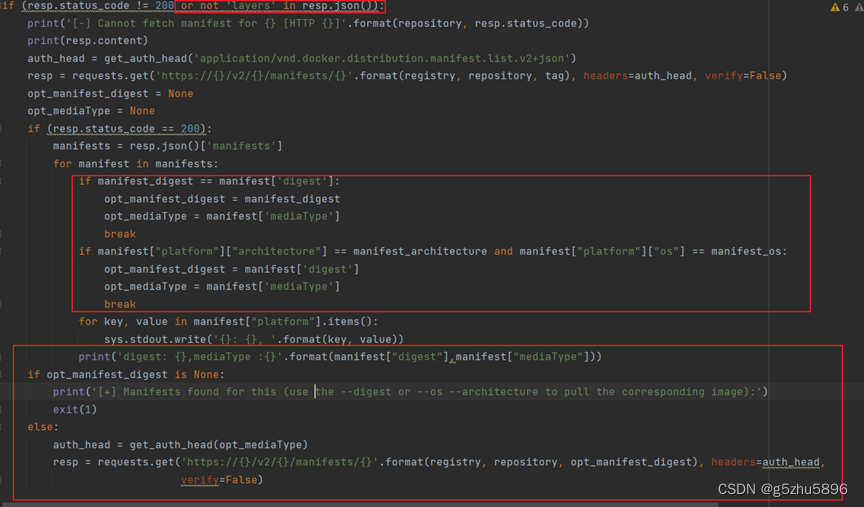
2.增加或修改了如下红框中的代码















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









