






导言
据Gartner称:到2020年,25亿辆联网汽车将成为物联网的主要对象。联网车辆预计每小时可以生成25GB的数据,对这些数据进行分析实现实时监控。大数据目前是10个主要领域之一,利用它可以使城市更加智能。例如,对GPS汽车数据的分析可以实现城市实时交通流量的优化。
Uber正在利用大数据完善它们的流程,从计算定价到寻找汽车的最佳定位都争取实现利润最大化。在这一系列的文章中,我们将使用公共Uber旅行数据来讨论构建分析和监控汽车GPS数据的实时示例。机器学习通常有两个阶段,包括实时数据:
数据发现。第一阶段涉及分析历史数据以构建机器学习模型;
使用该模型进行分析。第二阶段在现场活动中使用该模型;(Spark确实提供了一些流媒体机器学习算法,但仍然经常需要对历史数据进行分析。)
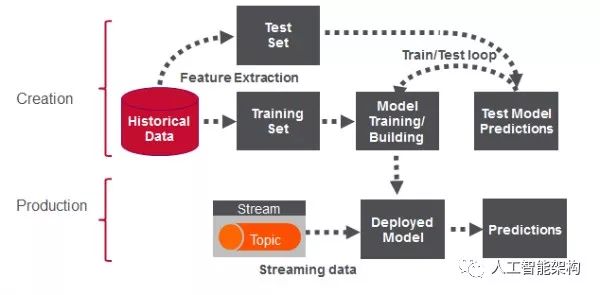
这是系列文章的第一篇,我们将一起开始使用Apache Spark的机器学习K-means算法根据位置聚类Uber数据。
聚类
Google新闻使用集群技术,根据标题和内容将新闻报道分为不同的类别。聚类算法发现数据集合中出现的分组。
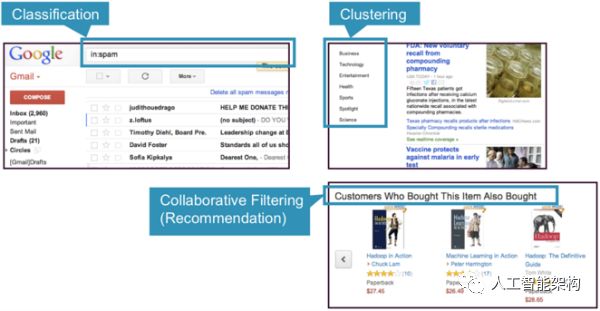
在聚类中,算法通过分析输入示例之间的相似性将对象分组。群集的示例包括:
搜索结果分组;
客户分组;
异常检测;
文本分类;

聚类使用无监督算法,对输入数据不提前标记。
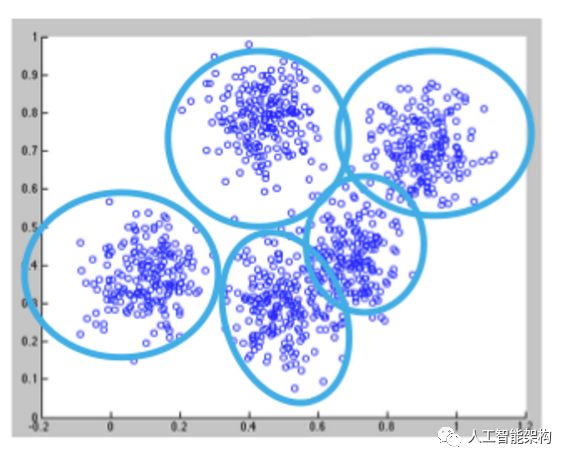
K-means是最常用的聚类算法之一,它将数据点聚类成预定数量的聚类(k)。使用K-means算法进行聚类首先将所有坐标初始化为k个质心。随着每次使用算法,每个点基于一些距离度量被分配到其最近的质心,该距离度量通常是Euclidean距离。然后,将质心更新为该通道中分配给它的所有点的“中心”,这种情况一直重复,直到中心发生最小变化。
示例数据集
示例的数据集是Uber旅行数据,从NYC Taxi & Limousine Commission获得的FiveThirtyEight数据。在这个例子中,我们将根据经度和纬度发现Uber数据的集群,然后将按日期/时间分析集群中心。数据集具有以下模式:
1、Date/Time:Uber的日期和时间;
2、Lat:Uber的纬度;
3、Lon:Uber的经度
4、Base:隶属于Uber的TLC公司;
数据记录采用CSV格式。如下所示:
12014-08-01 00:00:00,40.729,-73.9422,B025982014-08-01 00:00:00,40.729,-73.9422,B02598
示例代码
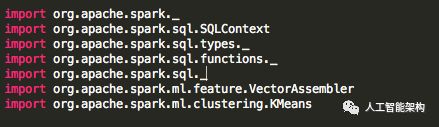
先导入Spark ML K-means和SQL所需的包。
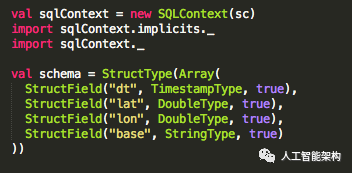
使用Spark Structype指定模式(如果你使用的是笔记本,则不必创建SQLContext)。
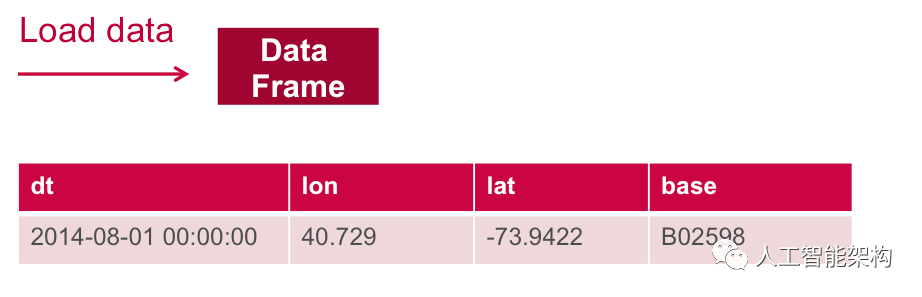
接下来,将CSV文件中的数据加载到Spark DataFrame中。
使用Spark 1.6 packages com.databricks:spark-csv_2.10:1.5.0,从CSV文件数据源创建DataFrame,并使用架构。

或者使用Spark 2.0,可以指定要加载到DataFrame中的数据源和架构,如下所示:
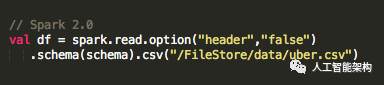
对于Spark 2.0,在将数据加载到DataFrame时指定模式将提供比模式推断更好的性能。DataFrame printSchema() 以树形格式将模式打印到控制台,如下所示:

DataFrame show() 显示前20行:

定义要素数组
为了使机器学习算法使用这些特征,将特征变换并放入特征向量中,特征向量是表示每个特征的值的数字向量。下面,VectorAssembler用于转换并返回包含向量列中所有要素列的新DataFrame。
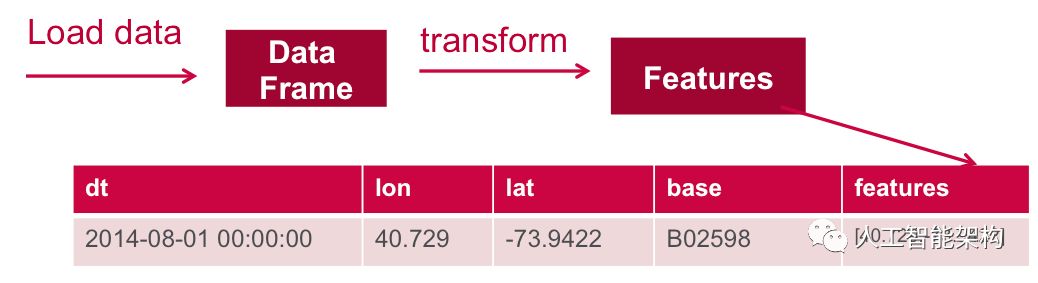

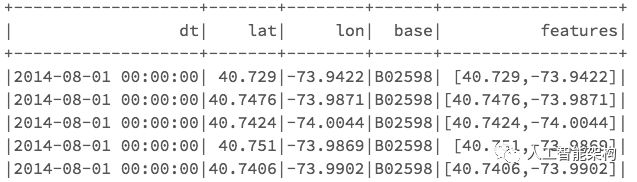
输出df2.show:
接下来,我们创建一个KMeans对象,设置参数以定义簇的数量和确定簇的最大迭代次数,并使模型适合输入数据。


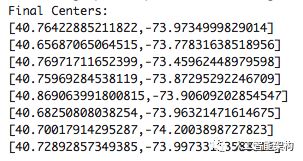
模型输出clusterCenters:
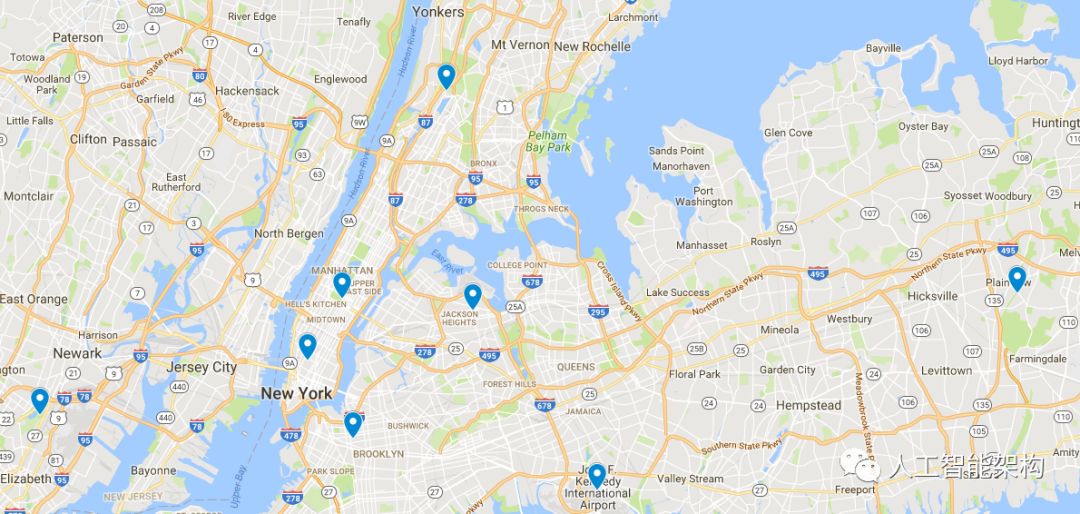
下面,群集中心显示在Google地图上:
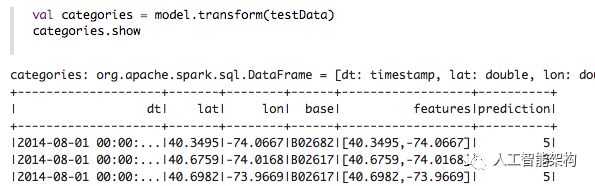
接下来,我们使用该模型获取测试数据的集群,以便进一步分析集群。

现在我们可以提出一些问题,例如“一天中哪个时间和哪个集群载客次数最多?”
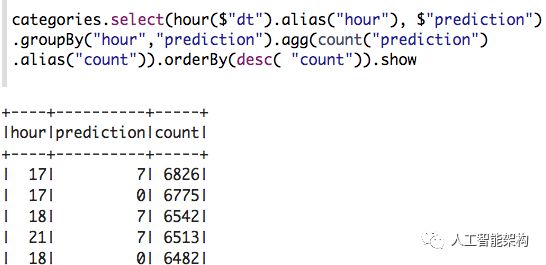
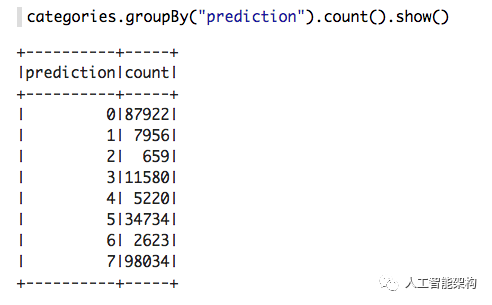
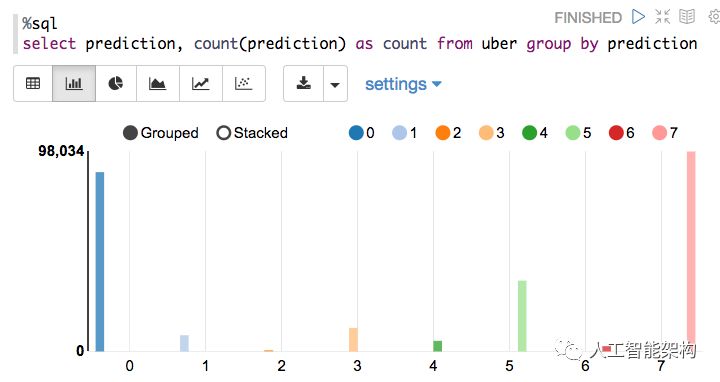
每个集群中发了了多少次?
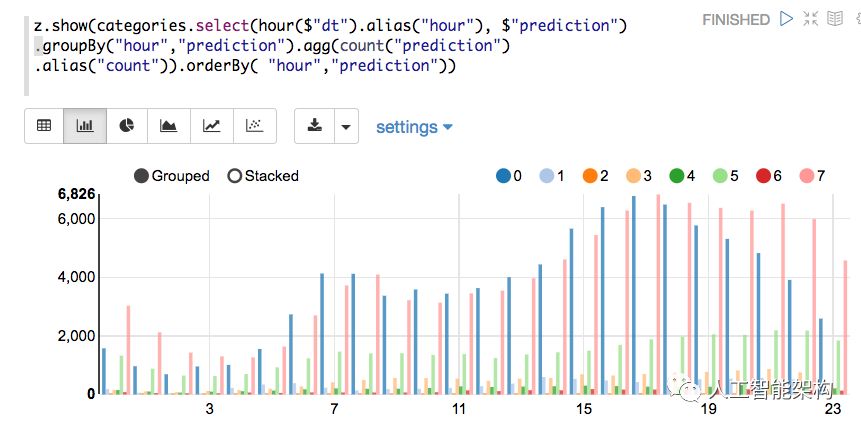
如果使用Zeppelin笔记本,我们还可以在条形图或图表中显示查询结果。下面,x轴是小时,y轴是计数,颜色代表不同的簇。
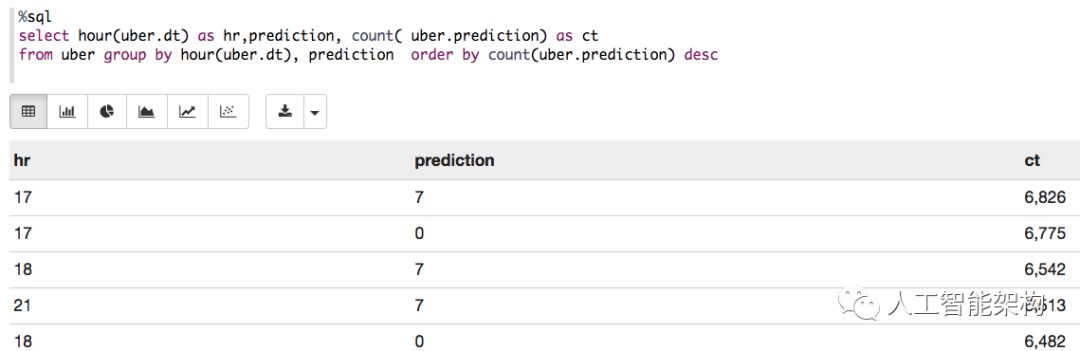
例如,你可以使用给定的名称将DataFrame注册为临时表df.registerTempTable("uber"),然后使用提供的的SQL方法运行SQL语句sqlContext。以下是Zeppelin笔记本中的一个示例。
该模型可以持久的保存在磁盘,如下所示,以便以后使用(如,使用Spark Streaming)。

系列指南
使用Apache API监控实时Uber数据,第1部分:Spark机器学习
使用Apache API监控实时Uber数据,第2部分:Kafka和Spark Streaming
使用Apache API监控实时Uber数据,第3部分:使用Vert.x的实时仪表板
使用Apache API监控实时Uber数据,第4部分:Spark Streaming,DataFrames和HBase
长按订阅↓
















 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









