







009 文件操作
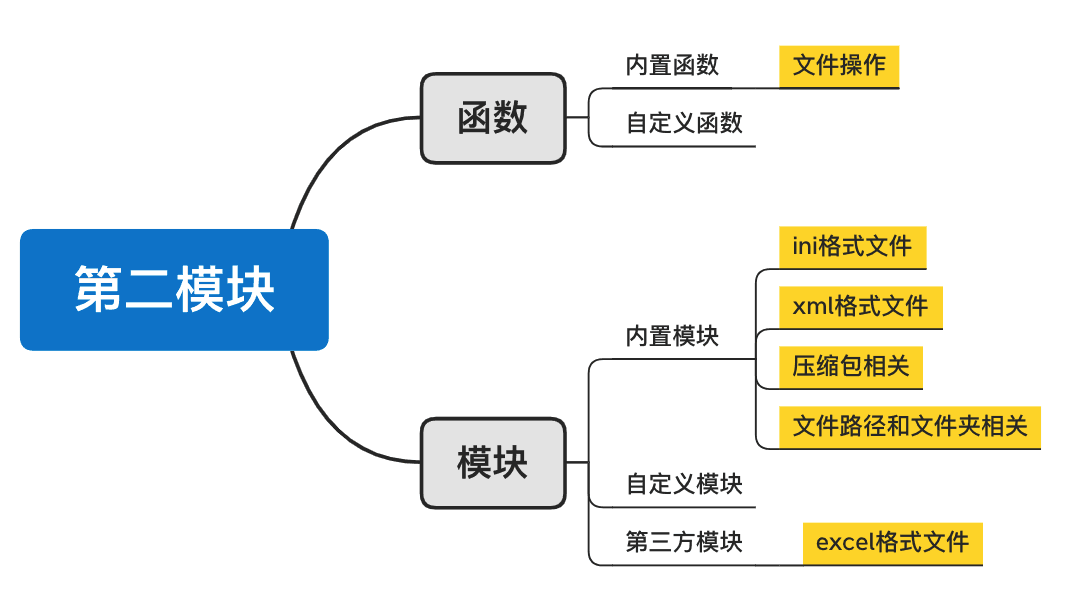
1、文件操作
-
读文件
-
读文本文件(字符串:rt、r)
打开:file_object = open('info.txt', mode='rt', encoding='utf-8') 读写:data = file_object.read() 关闭:file_object.close() -
读图片等非文本内容文件(二进制字节:rb)
打开:file_object = open('a1.png', mode='rb') 读写:data = file_object.read() 关闭:file_object.close() -
路径
相对路径:pwd(查看当前目录)、拼接当前路径 绝对路径:转义的问题解决(斜杠前再加一个斜杠、路径前加r) file_object = open('C:\\new\\info.txt', mode='rt', encoding='utf-8') file_object = open(r'C:\new\info.txt', mode='rt', encoding='utf-8') # 推荐 -
读文件时,文件不存在,程序会报错,所以在读文件前要先判断文件的存在性。
import os file_path = "/Users/wupeiqi/PycharmProjects/luffyCourse/day09/info.txt" exists = os.path.exists(file_path) # 存在:True、不存在:False if exists: file_object = open('info.txt', mode='rt', encoding='utf-8') ...
-
-
写文件
-
写文本文件(字符串:wt、w)
打开:file_object = open('t1.txt', mode='wt', encoding='utf-8') 写入:file_object.write("武沛齐") 关闭:file_object.close() -
写图片等非文本文件(二进制字节:wb)
打开:f1 = open('a1.png',mode='rb') 读取:content = f1.read() # 读进内存:二进制信息(bytes) 关闭:f1.close() 打开:f2 = open('a2.png',mode='wb') 写入:f2.write(content) # 先写进缓冲区、再刷到硬盘 关闭:f2.close() -
爬虫:requests模块
import requests res = requests.get(url="网址", headers={请求头}) print(res.content) # 网络传输原始的二进制信息(bytes) 打开:file_object = open('files/log1.txt', mode='wb') 写入:file_object.write(res.content) 关闭:file_object.close() -
w模式写文件时注意:
- 文件不存在,会先新建文件、再写入内容;
- 文件存在时,会先清空文件、再写入内容。
-
-
文件打开模式
-
只读:
r、rt、rb(常用)- 存在时,读取
- 不存在,报错(先判断存在性)
-
只写:
w、wt、wb(常用)- 存在时,清空再写
- 不存在,创建再写
-
只写:
x、xt、xb- 存在时,报错
- 不存在,创建再写。
-
只写:
a、at、ab【尾部追加】(最常用)- 存在时,尾部追加。
- 不存在,创建再写。
-
读写:
r+、rt+、rb+,默认光标位置:起始位置 w+、wt+、wb+,默认光标位置:起始位置(清空文件) x+、xt+、xb+,默认光标位置:起始位置(新建文件) a+、at+、ab+,默认光标位置:末尾位置 # 移动光标:f.seek(字节数)
-
-
其他读写功能
-
read,读
mode='r':字符串(文本文件) mode='rb':字节(非文本文件) f.read():读全部 f.read(n):读n个 f.readline():读1行 f.readlines():读全部行,每行作为列表的一个元素 # for循环读大文件(readline加强版) for line in f: print(line.strip())
-
-
write,写
f = open('info.txt', mode='a', encoding='utf-8') f.write("武沛齐") f.close() -
flush,刷到硬盘
# 写文件时,会把内容先写在缓冲区,系统再将缓冲区的内容刷到硬盘,但无法确定什么时候刷。 f.write("武沛齐") f.flush() # 写完就刷 -
光标的字节位置
# seek,移动光标到字节位置 f.seek(3) # tell,获取光标的字节位置 f.tell() # 注意:在a模式下,调用write向文件中写入内容时,永远只能将内容写入到尾部,不会写到光标的位置。 -
with上下文管理(推荐:自动关闭文件)
with open("xxxx.txt", mode='rb') as file_object: data = file_object.read() print(data)
2、csv格式文件
**csv( Comma-Separated Values )逗号分隔值文件,**以纯文本形式存储表格数据(数字、文本)。
ID,用户名,头像
26044585,Hush,https://hbimg.huabanimg.com/51d46dc32abe7ac7f83b94c67bb88cacc46869954f478
import os
import requests
with open('files/mv.csv', mode='r', encoding='utf-8') as file_object:
file_object.readline() # 跳过第一行
for line in file_object:
user_id, username, url = line.strip().split(',')
print(username, url)
# 1.下载:根据URL下载图片(res.content)
res = requests.get(
url=url,
headers={
"User-Agent": """Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"""
}
)
# 2.判断:检查images目录是否存在?若不存在,则创建images目录
if not os.path.exists("images"):
os.makedirs("images") # 创建images目录
# 3.保存:将图片的内容写入到文件
with open("images/{}.png".format(username), mode='wb') as img_object:
img_object.write(res.content)
3、ini格式文件(configparser)
**ini文件是Initialization File的缩写, 即为初始化文件,**是Windows系统配置文件所采用的存储格式,平时用于存储软件的的配置文件。例如:MySQL数据库的配置文件。
[mysqld]
datadir=/var/lib/mysql
[mysqld_safe]
log-error=/var/log/mariadb/mariadb.log
pid-file=/var/run/mariadb/mariadb.pid
[client]
default-character-set=utf8
import configparser
config = configparser.ConfigParser() # 实例化对象
config.read('files/my.ini', encoding='utf-8') # 调用read方法读取ini格式文件
获取所有的节点:config.sections()
获取某个节点下的键值:config.items('节点')
获取某个节点下的键对应的值:config.get('节点','键')
检查节点:config.has_section("节点")
添加节点:
config.add_section("节点") # 只写在内存
config.set('节点','键','值')
config.write(open('files/new.ini', mode='w', encoding='utf-8')) # 写进文件
删除节点:
config.remove_section('节点') # 只写在内存
config.remove_option('节点','键')
config.write(open('files/new.ini', mode='w', encoding='utf-8')) # 写进文件
4、XML格式文件(ElementTree)
**XML可扩展标记语言,**是一种简单的数据存储语言,被设计用来存储、传输数据。(后被json替代)
-
存储,可用来存放配置文件,例如:java的配置文件。
-
传输,网络传输时以XML格式存在,例如:早期ajax传输的数据、soap协议等。
<data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2023</year> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2026</year> </country> </data> -
读取文件、内容
from xml.etree import ElementTree as ET tree = ET.parse("files/xo.xml") # 打开xml文件 root = tree.getroot() # 获取根标签 content = """xml字符串""" root = ET.XML(content) # 获取根标签 -
读取节点数据
# 获取根标签:XML("xml字符串") root = ET.XML(content) # 找到子标签:find("子标签名") country_object = root.find("country") print(country_object.tag, country_object.attrib) # 子标签的标签名、属性 # 找到孙标签:find("子标签名") gdppc_object = country_object.find("gdppc") print(gdppc_object.tag, gdppc_object.attrib, gdppc_object.text) # 标签名、属性、内容 # 遍历根标签的子标签 for child in root: print(child.tag, child.attrib) # 遍历子标签的孙标签 for node in child: print(node.tag, node.attrib, node.text) # 去所有的子子孙孙标签里找 year 标签 for child in root.iter('year'): print(child.tag, child.text) # 找所有的 country 标签 v1 = root.findall('country') # 找第一个 country 标签下的 rank 标签 v2 = root.find('country').find('rank') -
修改和删除节点
# 获取根标签 root = ET.XML(content) # 找到孙标签 rank = root.find('country').find('rank') # 修改内容 rank.text = "999" # 添加属性 rank.set('update', '2020-11-11') # 删除节点 root.remove( root.find('country') ) # 以上操作都是在内存中进行的,需要保存到文件 tree = ET.ElementTree(root) tree.write("newnew.xml", encoding='utf-8') -
构建新的文档
<home> <son name="儿1"> <grandson name="儿11"></grandson> </son> </home>from xml.etree import ElementTree as ET # 创建根标签 root = ET.Element("home") # 1、创建子节点 son1 = ET.Element('son', {'name': '儿1'}) # 2、基于根节点创建子节点 son1 = root.makeelement('son', {'name': '儿1'}) # 1、创建孙子节点 grandson1 = ET.Element('grandson', {'name': '儿11'}) # 2、基于子节点创建孙节点 grandson1 = son1.makeelement('grandson', {'name': '儿11'}) # 把孙子节点添加到大儿子节点中 son1.append(grandson1) # 把子节点添加到根节点中 root.append(son1) # 以上操作都是在内存中进行的,需要保存到文件 tree = ET.ElementTree(root) tree.write('oooo.xml', encoding='utf-8', short_empty_elements=False)<famliy> <son name="儿1"> <age name="儿11">孙子</age> </son> </famliy>from xml.etree import ElementTree as ET # 创建根节点 root = ET.Element("famliy") # 基于根节点创建子节点,并直接添加到根节点 son1 = ET.SubElement(root, "son", attrib={'name': '儿1'}) # 基于子节点创建孙节点,并直接添加到子节点 grandson1 = ET.SubElement(son1, "age", attrib={'name': '儿11'}) # 设置节点的内容 grandson1.text = '孙子' et = ET.ElementTree(root) #生成文档对象 et.write("test.xml", encoding="utf-8")
5、Excel格式文件(openpyxl)
-
读sheet
from openpyxl import load_workbook # 载入excel文件 wb = load_workbook("files/p1.xlsx") # 1.获取excel文件中的所有sheet名称 print(wb.sheetnames) # 2.选择sheet:sheet名称、索引 sheet = wb["数据导出"] # 选中工作表:基于sheet名称 sheet = wb.worksheets[0] # 选中工作表:基于索引位置 cell = sheet.cell(1, 2) # 选中单元格 print(cell.value) # 获取单元格数据 # 3.循环遍历所有的sheet for sheet in wb: # 基于excel文件 cell = sheet.cell(1, 1) print(cell.value) for sheet in wb.worksheets: # 基于工作表 cell = sheet.cell(1, 1) print(cell.value) for name in wb.sheetnames: # 基于工作表名称 sheet = wb[name] cell = sheet.cell(1, 1) print(cell.value) -
读sheet中单元格的数据
from openpyxl import load_workbook wb = load_workbook("files/p1.xlsx") # 载入excel文件 sheet = wb.worksheets[0] # 选中第一张工作表 # 1.获取某个单元格(位置是从1开始) cell = sheet.cell(1, 1) # 选中单元格:基于索引,1行1列 cell = sheet["A2"] # 选中单元格:基于名称,A行2列 # 内容、样式、字体、对齐 print(cell.value, cell.style, cell.font, ,cell.alignment) # 2.获取某行单元格的数据 for cell in sheet[1]: print(cell.value) # 3.获取某几行单元格的数据:遍历所有列、再获取某几行 for col in sheet.columns: print(col[0].value, col[1].value) # 4.获取某几列单元格的数据:遍历所有行、再获取某几列 for row in sheet.rows: print(row[0].value, row[1].value) -
读取合并的单元格
from openpyxl import load_workbook wb = load_workbook("files/p1.xlsx") sheet = wb.worksheets[2] # 获取某个单元格(位置是从1开始) c1 = sheet.cell(1, 1) print(c1) # <Cell 'Sheet1'.A1> print(c1.value) # 用户信息 c2 = sheet.cell(1, 2) print(c2) # <MergedCell 'Sheet1'.B1> print(c2.value) # None -
在原Excel文件基础上写
from openpyxl import load_workbook wb = load_workbook('files/p1.xlsx') # 打开excel文件 sheet = wb.worksheets[0] # 选中第一张工作表 # 选中单元格,并修改单元格的内容 cell = sheet.cell(1, 1) cell.value = "新的开始" # 将excel文件保存到p2.xlsx文件中 wb.save("files/p2.xlsx") -
新建Excel文件写
from openpyxl import workbook wb = workbook.Workbook() # 创建excel且默认会创建一张工作表(名称为Sheet) sheet = wb.worksheets[0] # sheet = wb["Sheet"] -
其他操作
# 1. 修改sheet名称 sheet.title = "数据集" # 2. 创建sheet并设置sheet颜色 sheet = wb.create_sheet("工作计划", 0) sheet.sheet_properties.tabColor = "1072BA" # RGB颜色对照表 # 3. 默认打开的sheet wb.active = 0 # 4. 拷贝sheet new_sheet = wb.copy_worksheet(wb["Sheet"]) # 5.删除sheet del wb["用户列表"] # 1. 选中某个单元格,修改值 cell = sheet.cell(1, 1) # 先选中、后改值 cell.value = "开始" sheet["B3"] = "Alex" # 选中、改值同时进行 # 2. 选中多个单元格,修改值 cell_list = sheet["B2":"C3"] # 两行两列 for row in cell_list: # 遍历行 for cell in row: # 遍历每行的列 cell.value = "新的值" # 3. 对齐方式 # 水平对齐、垂直对齐、旋转角度、是否自动换行 cell.alignment = Alignment(horizontal='center', vertical='distributed', text_rotation=45, wrap_text=True) # 4. 边框 cell.border = Border( top=Side(style="thin", color="FFB6C1"), # 上下左右 bottom=Side(style="dashed", color="FFB6C1"), left=Side(style="dashed", color="FFB6C1"), right=Side(style="dashed", color="9932CC"), diagonal=Side(style="thin", color="483D8B"), # 对角线 diagonalUp=True, # 左下 ~ 右上 diagonalDown=True # 左上 ~ 右下 ) # 5.字体 cell.font = Font(name="微软雅黑", size=45, color="ff0000", underline="single") # 6.背景色 cell.fill = PatternFill("solid", fgColor="99ccff") # 7.渐变背景色 cell.fill = GradientFill("linear", stop=("FFFFFF", "99ccff", "000000")) # 8.宽高(索引从1开始) sheet.row_dimensions[1].height = 50 sheet.column_dimensions["E"].width = 100 # 9.合并单元格 sheet.merge_cells("B2:D8") sheet.merge_cells(start_row=15, start_column=3, end_row=18, end_column=8) sheet.unmerge_cells("B2:D8") # 解除合并单元格 # 10.写入公式 sheet["D2"] = "=B2*C2" # 自定义格式 sheet["D3"] = "=SUM(B3,C3)" # 内置公式 # 11.删除行列 sheet.delete_rows(idx=1, amount=20) # (从哪删,删几个) sheet.delete_cols(idx=1, amount=3) # 12.插入行列 sheet.insert_rows(idx=5, amount=10) # (从哪插,插几个) sheet.insert_cols(idx=3, amount=2) # 13.循环写内容 cell_range = sheet['A1:C2'] for row in cell_range: for cell in row: cell.value = "xx" for row in sheet.iter_rows(min_row=5, min_col=1, max_col=7, max_row=10): for cell in row: cell.value = "oo" # 14.移动 # 将H2:J10范围的数据,向下移动1个位置、向右移动15个位置 sheet.move_range("H2:J10",rows=1, cols=15) sheet.move_range("B1:D3",cols=10, translate=True) # 自动翻译公式 # 15.打印区域 sheet.print_area = "A1:D200" # 16.打印时,每个页面的固定表头 sheet.print_title_cols = "A:D" sheet.print_title_rows = "1:3"
6、压缩文件(shutil)
import shutil
# 1. 压缩文件(make_archive):名称、格式、对象
shutil.make_archive(base_name=r'datafile',format='zip',root_dir=r'files')
# 2. 解压文件(unpack_archive):对象、路径、格式
shutil.unpack_archive(filename=r'datafile.zip', extract_dir=r'xxxxxx/xo', format='zip')
7、路径相关(os)
-
路径转义:加转义符\、加r(正则表达式也如此)
-
程序当前路径:项目中如果使用了相对路径,那么一定要注意当前所在的位置
import os # 1.获取当前运行的py脚本所在的绝对路径 abs_path = os.path.abspath(__file__) # 2.返回上级目录 sup_dir = os.path.dirname(abs_path) # 3.获取项目根目录:当前脚本路径的上级目录 base_dir = os.path.dirname(os.path.abspath(__file__)) # 4.拼接路径:自适应不同系统的分隔符(斜杠、反斜杠) file_path = os.path.join(base_dir, 'files', 'info.txt') # 读文件时,若文件不存在,会报错,所以需要在读文件前先判断存在性。 if os.path.exists(file_path): file_object = open(file_path, mode='r', encoding='utf-8') # 打开 data = file_object.read() # 读取 file_object.close() # 关闭 print(data) else: print('文件路径不存在') -
文件和路径相关
import shutil import os # 1. 获取当前脚本绝对路径:abspath() abs_path = os.path.abspath(__file__) # 2. 获取当前文件的上级目录:dirname() base_path = os.path.dirname( os.path.dirname(当前文件的路径) ) # 3. 路径拼接:join() p1 = os.path.join(base_path, 'xx') p2 = os.path.join(base_path, 'xx', 'oo', 'a1.png') # 4. 判断路径是否存在:exists() exists = os.path.exists(file_path) # 5. 创建文件夹:os.makedirs(路径) file_path = os.path.join(base_path, 'xx', 'oo', 'uuuu') if not os.path.exists(file_path): os.makedirs(file_path) # 6. 判断是否是文件夹:isdir() file_path = os.path.join(base_path, 'xx', 'oo', 'uuuu.png') is_dir = os.path.isdir(file_path) # 7. 删除文件、文件夹:remove、rmtree os.remove("文件路径") path = os.path.join(base_path, 'xx') # 文件夹路径 shutil.rmtree(path) # 8. 拷贝文件夹:copytree shutil.copytree("/Users/wupeiqi/Desktop/图/csdn/", "/Users/wupeiqi/PycharmProjects/CodeRepository/files") # 9.拷贝文件:copy shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png", "/Users/wupeiqi/PycharmProjects/CodeRepository/") # 10.文件或文件夹重命名:move shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/x.png", "/Users/wupeiqi/PycharmProjects/CodeRepository/xxxx.png")
010 函数入门
1、初识函数
-
函数,可以当做是一大堆功能代码的集合。
-
两种应用场景:
-
代码重复,增加代码的重用性;
-
代码太长,增强代码的可读性。
-
-
面向过程编程 ----> 函数式编程
2、函数的参数
-
参数
- 两种分类:
- 形参:定义时使用(普通参数、默认参数、动态参数)
- 实参:调用时使用(位置传参、关键字传参)
- 两种传参方式:
- 位置传参(须有序):add(1,22)
- 关键字传参(可无序):add(n1=1, n2=22)、add(n2=1, n1=22)
- 一个注意事项:
- 位置传参和关键字传参混用时,关键字参数必须放后面:add(1,n2=22)
- 两种分类:
-
默认参数
- def func(a1, a2, a3=10):
- 默认参数不传时,使用默认值:func(1, 2)
- 默认参数传值时,使用传入值:func(1, 2, 3)
- def func(a1, a2, a3=10):
-
动态参数
- def func(*args):
- 参数是元组类型
- 只能按位置传参(多种形式):func(22, 33, 99)、func((22, 33))、func({22, 33, })、func(*(22, 33, 99))
- def func(**kwargs):
- 参数是字典类型
- 只能按关键字传参(两种形式):func(n1=“武沛齐”, age=18)、func(**{n1=“武沛齐”, age=18})
- def func(*args, **kwargs):
- 位置传参关键字传参混用时,关键字传参必须放在后面
- func(22, 33, 99, n1=“武沛齐”, age=18)
- 推荐:func(*(22, 33, 99), **{n1=“武沛齐”, age=18})
- def func(*args):
-
注意事项
- ** 必须放在 * 的后面
- 普通参数和动态参数混合时,动态参数必须放在最后;
- 默认参数和动态参数混合时,默认参数最好使用关键字传参。
3、函数返回值
- 完成某种行为,并希望得到结果:发邮件的结果、加密后的密文…
- 返回值可以是任意类型,如果函数中没写return,则默认返回None。
- 当在函数中
未写返回值或return或return None,执行函数获取的返回值都是None。 - return后面的值若有多个,要用逗号分割,则会将返回值转换成元组形式。
- 函数一旦遇到return,就会立即退出函数;而break只能退出本层循环。
4、总结
- 如何定义函数
- 函数的名称:同变量名的命名规范
- 函数的参数:形参(普通、默认、动态)
- 函数的注释:“”" “”"
- 函数返回值:
- 返回None:不写、只写return、写了return None
- 遇到return,退出函数
011 函数进阶
1、参数的补充
-
传入参数的内存地址
-
函数执行传参时,传递的是内存地址;
-
这一特性有两个好处:
- **节省内存:**形参、实参指向同一块内存。
- **同步变化:**若参数是可变类型且在函数中修改了元素的内容,则所有的地方都会修改。
-
特殊情况:
- 实参是可变类型 ,但形参重新赋值了,形参就会新开辟一块内存空间。
- 实参是不可变类型,形参无法修改内部元素,只能重新赋值,形参也会新开辟一块内存空间。
-
若不想让外部的变量和函数内部参数的变量一致,也可以将外部值先拷贝一份,再传给函数。
v1 = [11, 22, 33] new_v1 = copy.deepcopy(v1) # 拷贝一份数据 func(new_v1) # 形参new_v1、实参data指向同一块内存,同步变化。
-
-
函数的返回值是内存地址
def func(): data = [11, 22, 33] print(data, id(data)) return data v1 = func() # [11,22,33] 2272107244104 :返回值data赋值给v1,变量data被回收 print(v1, id(v1)) # [11,22,33] 2272107244104 -
参数的默认值(默认参数)
- 原理:Python在创建函数(未执行)时,如果发现函数的参数中有默认值,则在函数内部会创建一块内存区域并维护这个默认值。
- 执行函数未传默认值时(默认值不变),则让a2继续指向函数维护的那个值的内存地址。
- 执行函数传默认值时(默认值改变),则让a2指向新传入的值的内存地址。
- 原理:Python在创建函数(未执行)时,如果发现函数的参数中有默认值,则在函数内部会创建一块内存区域并维护这个默认值。
-
动态参数
- 定义函数时,在形参位置用
*或**可以接任意个参数。在执行函数时,也可以用*或**:- 形参固定,实参可用
*和** - 形参用
*和**,实参也用*和** **kwargs只有两种传参方式:func( name=“武沛齐”, age=18)、func(**{“k1”: 1, “k2”: 2})
- 形参固定,实参可用
- 值得注意:按照这个方式将数据传递给args和kwargs时,数据是会重新拷贝一份的(可理解为内部循环每个元素并设置到args和kwargs中)。
- 定义函数时,在形参位置用
2、函数和函数名
-
函数名其实就是一个变量,只不过这个变量代指函数而已。
-
注意:函数必须先定义、后调用(解释型语言自上而下)。
-
函数名做元素
-
无参函数(即参数一致)
- 函数名可做列表、字典的元素;根据选项,取出函数名,加括号执行。
- 某种特定情况下,要实现依次发送短信、微信、邮件,for循环遍历列表里的函数名。
-
有参函数(参数不一致)
# 字典套列表:按键取值 function_dict = { "1": [ send_message, ['15131255089', '你好呀']], "2": [ send_image, ['xxx/xxx/xx.png', '消息内容']], } item = function_dict.get(1) # [ send_message, ['15131255089', '你好呀']] func = item[0] # 函数名:send_message param_list = item[1] # 参数:['15131255089', '你好呀'] func(*param_list) # 执行函数:send_message(*['15131255089', '你好呀']) # 列表套字典:for循环遍历取出 func_list = [ {"name": send_msg, "params": {'mobile': "151xxx", "content": "新短消息"}}, {"name": send_wechat, "params": {'user_id': 1, 'content': "约吗"}}, ] # item:{"name": send_msg, "params": {'mobile': "151xxx", "content": "新短消息"}}, for item in func_list: func = item['name'] # send_msg param_dict = item['params'] # {'mobile': "151xxx", "content": "新短消息"} func(**param_dict) # send_msg(**{'mobile': "151xxx", "content": "新短消息"})
-
-
函数名赋值
-
函数名其实就个变量,代指某函数;如果将函数名赋值给另外一个变量,则此变量也会代指该函数。
def func(): pass func1= func # 函数名赋值给另一个变量func1 func1() # 等同于func() func_list = [func,func,func] # 函数名赋值给列表的元素 func_list[0]() # 等同于func() -
如果将函数名修改为其他值(或再定义同名函数),则函数名便不再代指原函数。(避免和内置函数重名)
-
-
函数名做参数、返回值(原函数特殊的调用方法:先取函数名、再加括号执行)
def plus(num): return num + 100 def handler(func): """函数名做参数""" res = func(10) # 110:等同于res = plus(10) msg = "执行func,并获取到的结果为:{}".format(res) print(msg) # 执行func,并获取到的结果为:110 # 执行handler函数,将plus作为参数传递给handler的形式参数func,再加括号执行 handler(plus) def handler(): """函数名做返回值""" print("执行handler函数") return plus result = handler() # plus:获取函数名 data = result(20) # 120:等同于data = plus(20) print(data) # 120 -
原函数特殊的调用方法:先取函数名,再加括号执行,调用更加灵活。
- 函数名做列表、字典的元素
- 函数名被赋值给另一个变量
- 函数名做另一函数的参数、返回值
3、返回值和print
- 在函数中使用print,只是用于在某个位置输出内容而已。
- 在函数中使用return,是为了将函数的执行结果返回给调用者,以便于后续进行其他操作。
4、作用域
作用域,可以理解为一块空间,这块空间的数据是可以共享的。通俗点来说,作用域就类似于一个房子,房子中的东西归里面的所有人共享,而房子外的人无法获取。
-
以函数为作用域
- Python以函数为作用域,在函数内创建的所有数据,可以在函数内使用,无法在其他函数中使用。
-
全局和局部
- Python中以函数为作用域,函数的作用域其实是一个局部作用域。
- 在全局作用域中创建的变量称为全局变量(大写),可以在全局作用域、局部作用域中使用。
- 在函数内部创建的变量称为局部变量(小写),局部变量只能在函数内使用。局部作用域中想要使用某个变量时,寻找的顺序为:
优先在局部作用域中寻找,如果没有则去上级作用域中寻找。 - 在局部作用域中,可以读取全局作用域的变量,反之不行。
- 局部作用域(函数内)和全局作用域(函数外)的变量同名,调用函数时,会使用局部变量,全局不变。
-
global关键字
- 在局部作用域对全局变量只能读取、修改内部元素(可变类型),无法对其进行重新赋值。(是新建了)
- 若想在局部作用域中对全局变量重新赋值(而非新建一个局部变量),则可以基于
global关键字实现。
012 函数高级
1、函数嵌套
- Python中以函数为作用域,在作用域中定义的相关数据,只能被当前作用域或其子作用域使用。
- 在函数内,调用另一函数:
- 函数也可以是定义在作用域中的数据,在执行函数时候,也同样遵循:优先在自己的作用域中寻找,没有则向上级作用域寻找。
- 在函数内,定义另一函数并执行:
- 函数一般定义在全局作用域,但也可以定义在局部作用域,即函数的嵌套。
- 应用场景:(简化代码、避免冲突)
- 当我们定义一个函数去实现某功能,想要将内部功能拆分成N个函数,又担心这个N个函数放在全局会与其他函数名冲突时(尤其多人协同开发),可以选择使用函数的嵌套。比如,生成随机验证码。
- 函数嵌套引发的作用域问题、解决办法:
- 在函数外部,无法直接调用在函数内部定义的函数;
- **闭包:**可以将内部函数的函数名作为外部函数的返回值;先执行外部函数,获取其返回值(内部函数名)并赋值给一个变量,这个变量再加括号就可以执行内部函数了。(朱老师:内部函数引用了外部函数的变量,从内部函数返回一个值到全局。)
- 三句话搞定作用域:
- 优先在自己的作用域找,自己没有就去上级作用域找。
- 在作用域中寻找值时,要确定此次此刻的值是什么。
- 分析函数的执行过程,并确定函数
作用域链。(函数嵌套)
2、闭包
- 闭包是将数据(函数)封装在一个包(区域)中,使用时再取出(函数名:通过return返回);闭包本质上是基于函数嵌套的一种特殊嵌套,使得函数的调用更加灵活。
- 闭包应用场景:
- 封装数据,防止污染全局;(嵌套的内部函数,定义后会立即全部执行)
- 封装数据(函数名)封到一个包里(列表),需要时再取用(先索引取函数名,再加括号执行)。
3、装饰器
-
现在给你一个函数,在不修改函数源码的前提下,实现在函数执行前和执行后分别输入 “before” 和 “after”。
def func(): print("我是func函数") value = (11, 22, 33, 44) return value def outer(origin): # 1、外部函数 def inner(): # 2、内部函数 print('inner') # 额外功能(1) res = origin() # 3、原函数 print("after") # 额外功能(2) return res # 返回原函数的执行结果 return inner # 返回内部函数的函数名 func = outer(func) # inner:将返回值inner赋值给一个变量func,这个变量是原函数名 result = func() # func = inner,等同于执行result = inner() # 这样虽然添加了额外功能,但改变了原函数的调用方法,使得调用起来比较麻烦# 装饰器函数 def outer(origin): # 1、外部函数 def inner(): # 2、内部函数 print('inner') # 额外功能(1) res = origin() # 3、原函数 print("after") # 额外功能(2) return res # 返回原函数的执行结果 return inner # 返回内部函数的函数名 @outer # 语法糖 def func(): print("我是func函数") value = (11, 22, 33, 44) return value func() # 在原函数上面加语法糖,会在执行原函数前先执行装饰器函数,将得到的返回值(内部函数名)再赋值给原函数名 -
在这3个函数执行前和执行后,分别输入 “before” 和 “after”。
- 装饰器在不修改原函数前提下,通过@函数(语法糖)添加一些额外功能,批量操作更有意义。
-
装饰器优化:支持传多个参数
def outer(origin): def inner(*args, **kwargs): print("before") res = origin(*args, **kwargs) # 调用原函数:func() print("after") return res return inner @outer def func(): pass func() -
装饰器总结:
-
**实现原理:**基于@语法糖和函数闭包,将原函数封装在闭包中,然后将函数赋值为一个新的函数(内层函数),执行(外部)函数时,先获取内层函数的函数名,再到内层函数执行闭包中的原函数。
-
**实现效果:**可以在不改变原函数内部代码、调用方式的前提下,实现原函数执行和执行扩展功能。
-
**适用场景:**多个函数统一在执行前后,自定义一些额外功能。(取消也很方便)
-
-
装饰器的伪应用场景:
- 在编写一个网站时,如果项目共有100个页面,其中99个是需要登录成功之后才有权限访问,就可以基于装饰器来实现。
-
重要补充:functools
-
装饰器实际上就是将原函数更改为其他的函数,然后在此函数中,再去调用原函数。解决:functools
import functools def auth(func): @functools.wraps(func) def inner(*args, **kwargs): return func(*args, **kwargs) return inner @auth def handler(): pass handler() print(handler.__name__) # handler
-
013 内置函数和推导式
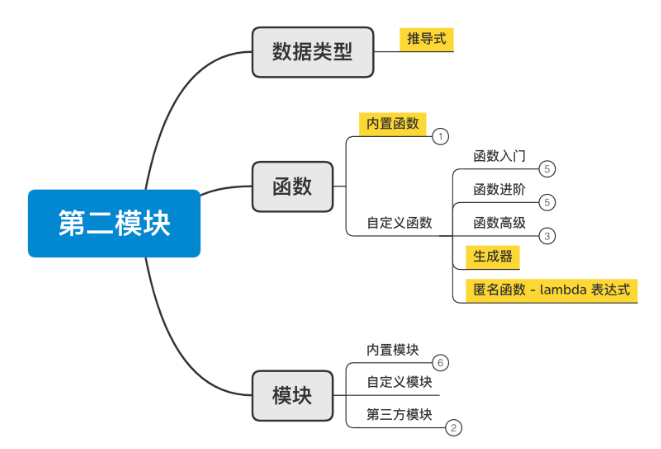
1、匿名函数:lambda
-
传统函数的定义包括:函数名 + 函数体。
-
函数名的使用:直接执行;间接执行(当做列表的元素、赋值给另一个变量、当做另一函数的参数或返回值)
-
**匿名函数,**是基于lambda表达式定义一个没有名字的函数;格式为:
lambda 参数:函数体-
参数,支持任意参数;
-
函数体,只能支持单行的代码;
-
返回值,将函数体(单行代码)执行的结果返回给函数的执行者。
-
应用场景,匿名函数适用于简单的业务处理,可以快速、简单地创建函数。
-
定义与调用
# 方式一 func = lambda a1,a2: a1+a2 v1 = func(1, 2) # 方式二 data_list = [lambda x: x + 100, lambda x: x + 110, lambda x: x + 120] data_list[0](1) # 101 data_list[1](1) # 111 data_list[2](1) # 121
-
-
三元运算
- 简单的函数,可以基于lambda表达式实现;简单的条件语句,可以基于三元运算实现。
- 格式:结果 = 条件成立时的值 if 条件 else 条件不成立时的值
- 示例:data = “老色批” if “苍老师” in str else “正经人”
- 使用三元运算的匿名函数,可以处理稍微复杂点的情况。
- 示例:func = lambda x: “大了” if x > 66 else “小了”
2、生成器:yield
-
生成器是由函数+yield关键字创造出来的,可以帮助我们节省内存。(自定义的迭代器)
-
生成器函数,若函数中有yield存在时,这个函数就是生成器函数。
-
生成器对象,执行生成器函数时,会先返回一个生成器对象,而函数内部代码还未执行。
# 生成器函数:有yield关键字 def func(): print(111) yield 1 # yield关键字:有点像return,执行到这个位置之后,就不再执行。 ... print(444) # return None # 程序就会报错,生成器中的代码执行完毕了:StopIteration data = func() # 生成器对象 # 元组推导式:不会立即执行内部循环去生成数据,而是得到一个生成器。 data = (i for i in range(10)) print(data) # <generator object <genexpr> at 0x000001EF4E0679E8> for item in data: print(item) # 生成器对象的两种创建方法:执行生成器函数、元组推导式 -
生成器对象的使用
# 1、next方法:next里面放生成器对象,进入生成器函数并执行其中的代码 v1 = next(data) # 输出111,返回值:1 print(v1) # 1 # 从上次yield返回位置继续向下 v2 = next(data) # 输出222,返回值:2 print(v2) # 2 # 结束或中途遇到return,程序报错:StopIteration # 2、for循环:基于for循环执行生成器对象 for item in data: print(item) # 3、send方法 n1 = data.send(None) print(n1) # 生成器对象的使用:next(生成器对象)、for循环、生成器对象.send() # 生成器的特点:记录在函数中的执行位置,下次执行next时,基于上一次继续向下执行。 -
生成器的应用:生成 300w个随机的4位数(在内存中一次性创建300w个:太耗内存)
import random def gen_random_num(max_count): counter = 0 while counter < max_count: yield random.randint(1000, 9999) counter += 1 data_list = gen_random_num(3000000) # 生成 300w个随机的4位数 # 使用生成器动态创建,用一个创建一个 n1 = next(data_list) n2 = next(data_list)
3、内置函数
-
abs,绝对值:abs(-10)
-
pow,指数:pow(2, 5),2的5次方
-
sum,求和:sum([-11, 22, 33, 44, 55])
-
divmod,取商、取余:v1, v2 = divmod(9, 2)
-
round,四舍五入、保留n位小数:round(4.11786, 2)
-
min,最小值
- min(11, 2, 3, 4, 5, 56)
- min([11, 22, 33, 44, 55])
- min([-11, 2, 33, 44, 55], key=lambda x: abs(x))
-
max,最大值:同最小值
-
all,是否全部为True:all([11, 22, 44, “”])
-
any,是否存在True:any([11, 22, 44, “”])
-
进制转换:
- bin,十进制转二进制
- oct,十进制转八进制
- hex,十进制转十六进制
-
字符、码点转换:
- ord,获取字符对应的unicode码点(十进制):ord(“武”)
- chr,获取码点获取对应的字符:chr(27494)
-
int,转十进制整型
-
foat,转浮点型
-
str,转字符串(unicode编码)
-
bytes,转字节(utf-8、gbk编码):
- bytes(v1, encoding=“utf-8”)
- v1.encode(‘utf-8’),通过编码转字节
-
bool,转布尔型
-
list,转列表
-
dict,转字典
-
tuple,转元组
-
set,转集合
-
len,长度
-
print,输出
-
input,输入
-
open,打开文件
-
type,获取数据类型
-
range,Python3 返回的是一个可迭代对象(类型是对象),而不是列表类型。
-
enumerate,枚举,将一个可遍历的数据对象(列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
v1 = ["武沛齐", "alex", 'root'] for num, value in enumerate(v1, 1): print(num, value) # 1 武沛齐 # 2 alex # 3 root -
id,获取内存地址
-
hash,获取哈希值:v1 = hash(“武沛齐”)
-
help,帮助信息
- pycharm,不用
- 终端,使用
-
zip,用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组构成的列表。如果各个迭代器的元素个数不一致,则返回的列表长度与最短的对象相同。
result = zip(list1, list2, listv3) print(result) # <zip object at 0x0000029884A09DC8>:迭代器 for item in result: print(item) -
callable,是否可执行,后面是否可以加括号。(即判断是否是函数)
-
sort,列表的专用排序
-
sorted,其他数据类型的排序(结果以列表保存)
# 列表 v1 = sorted([11, 2, 33, 47, -23]) # 默认升序 v1 = sorted([11, 2, 33, 47, -23], reverse=True) # 改为降序 # 将字典的“键”按升序排 v1 = sorted(dic) # 将字典的“键值对”按匿名函数的规则降序排 result = sorted(info.items(), key=lambda x: x[1]['id'], reverse=True) # 将字典的“键值对”按匿名函数的规则降序排,再取列表的第一个元素(键值对)的键 winner = sorted(player.items(), key=lambda x: x[1][-1], reverse=True)[0][0]
4、推导式
推导式可以通过一行代码实现创建list、dict、tuple、set ,同时初始化一些值。
# 列表推导式
num_list = [ "武沛齐-{}".format(i) for i in range(10) if i > 6 ]
# ['武沛齐-7', '武沛齐-8', '武沛齐-9']
# 集合推导式
num_set = { (i,i,i) for i in range(10) if i>3 }
# {(6, 6, 6), (5, 5, 5), (4, 4, 4), (9, 9, 9), (7, 7, 7), (8, 8, 8)}
# 字典推导式
num_dict = { i:(i,11) for i in range(10) if i>7}
# {8: (8, 11), 9: (9, 11)}
# 元组推导式(生成器):不会立即执行内部循环去生成数据,而是得到一个生成器。
data = (i for i in range(10))
print(data) # <generator object <genexpr> at 0x000001EF4E0679E8>
for item in data:
print(item)
014 模块
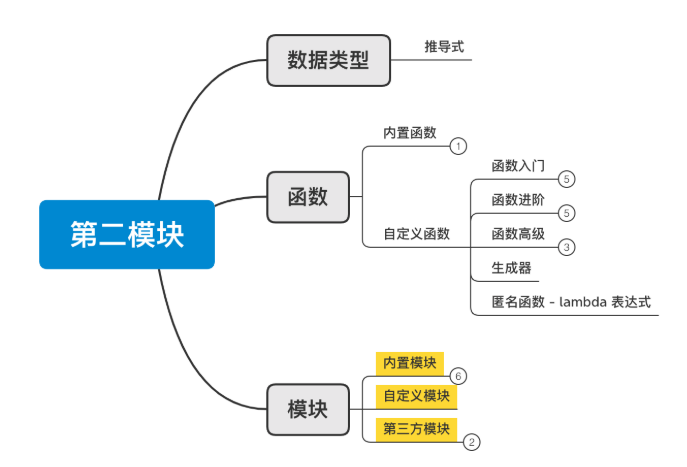
1、自定义模块:py文件
-
模块和包
- 模块(module):一个py文件(代码结构更清晰、增加代码的重用性)
- 包(package):含多个py文件的文件夹
- 在包(文件夹)中,有一个默认内容为空的
__init__.py的文件,描述当前包的信息。
-
导入
-
导入,本质上是将模块、包先加载的内存中,使用时再去内存中拿。(单例模式)
-
导入时的路径:
-
导入模块、包时,都会按照指定顺序去特定的**路径集(sys.path)**里查找。
-
也可以自动手动在sys.path中添加指定路径:
import sys sys.path.append("路径A")
-
-
注意:
- 自定义模块时,名称千万不能和内置模块、第三方模块同名;(会覆盖)
- pycharm中默认会将项目根目录加入到sys.path中;
- 项目执行文件一般都在项目根目录,若嵌套在内层目录,就需要自己手动在sys.path中添加路径。
-
Python开发中常用的导入的方式有2类,每类方式也都有多种情况:
- import xxxx as 别名:多用于导入sys.path目录下的一个py文件
- 模块级别(一个py文件)
- 包级别(一个包含多个py文件的文件夹)
- from xxx import xxx as 别名:用于多层嵌套和导入模块中某个成员
- 成员级别:一个函数、多个函数(逗号分割)、全部函数(*)
- 模块级别(一个py文件)
- 包级别(一个包含多个py文件的文件夹)
- import xxxx as 别名:多用于导入sys.path目录下的一个py文件
-
导入模块时一般要遵循的规范:
-
注释:文件顶部或init文件中。
-
在文件顶部导入
-
有规则地导入,并用空行分割:先内置模块、再第三方模块、最后自定义模块
-
-
-
相对导入
- 在导入模块时,对于
from xx import xx这种模式,还支持相对导入。一点(同级)、两点(上级) - 相对导入只能用在包中的py文件中(即:嵌套在文件中的py文件才可以使用,项目根目录下无法使用)
- 在导入模块时,对于
-
使用别名(避免覆盖、方便调用)
-
若有重名,后导入的模块会覆盖之前导入的,为了避免这种情况的发生,Python支持重命名;
-
重命名后,调用也会更简单;
import commons.page v1 = commons.page.pagination() import commons.page as pg v1 = pg.pagination()
-
-
主文件
-
主文件,其实就是在程序执行的入口文件,通常 run.py,其他的py文件都是一些功能代码(只定义);当我们去执行一个文件时,文件内部的
__name__变量的值是__main__ -
执行一个py文件时:执行文件的name,
__name__ = "__main__" -
导入一个py文件时:被导入模块的name,
__name__ = "模块名" -
只有以主文件的形式运行此脚本时,start函数才会执行,被导入时则不会被执行。
if __name__ == '__main__': start()
-
2、第三方模块
- 安装第三方模块的方式:
- pip管理工具(推荐)
- 安装命令:pip install 模块名称==版本
- pip 更新:python -m pip install --upgrade pip
- 豆瓣源:
pip install 模块名称 -i https://pypi.douban.com/simple/
- 源码安装
- 下载requests源码:
下载地址:https://pypi.org/project/requests/files - 进入目录:cd
- 执行编译和安装命令:
python setup.py build、python setup.py install
- 下载requests源码:
- wheel格式
- 安装wheel格式支持:pip install wheel
- 进入下载目录,在终端基于pip直接安装:pip install xxx.whl
- pip管理工具(推荐)
- 第三方模块默认的安装路径:C:\…\site-packages\
3、内置模块
-
os模块
import os # 1. 获取当前脚本的绝对路径:abspath abs_path = os.path.abspath(__file__) # 2. 获取当前文件的上级目录:dirname base_path = os.path.dirname( os.path.dirname(路径) ) # 3. 路径拼接:join file_path = os.path.join(base_path, 'xx', 'oo', 'a1.png') # 4. 判断路径是否存在:exists exists = os.path.exists(file_path) # 5. 创建文件夹:makedirs os.makedirs(路径) # 6. 是否是文件夹:isdir is_dir = os.path.isdir(file_path) # 7. 删除文件或文件夹:remove、rmtree os.remove("文件路径") path = os.path.join(base_path, 'xx') shutil.rmtree(path) # 8.查看目录下所有的文件:listdir data = os.listdir("/Users/wupeiqi/PycharmProjects/luffyCourse/day14/commons") # 9.查看目录下所有的文件(含子孙文件):walk data = os.walk("/Users/wupeiqi/Documents/视频教程/路飞Python/mp4") # 生成器 for path, folder_list, file_list in data: # (路径、目录名、文件) for file_name in file_list: # 遍历文件、获取文件名 file_abs_path = os.path.join(path, file_name) # 文件绝对路径 ext = file_abs_path.rsplit(".",1)[-1] # 获取后缀名 if ext == "mp4": print(file_abs_path) -
os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下。
- 格式:os.walk(top),top 是你所要遍历的目录的地址, 返回的是一个三元组(root, dirs, files)
- root 所指的是当前正在遍历的这个文件夹的本身的地址
- dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
- 格式:os.walk(top),top 是你所要遍历的目录的地址, 返回的是一个三元组(root, dirs, files)
-
shutil模块:删除拷贝重命名、压缩文件解压缩
import shutil # 1、删除文件夹:rmtree path = os.path.join(base_path, 'xx') shutil.rmtree(path) # 2、拷贝文件夹:copytree shutil.copytree("/Users/wupeiqi/Desktop/图/csdn/", "/Users/wupeiqi/PycharmProjects/CodeRepository/files") # 3、拷贝文件:copy shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png", "/Users/wupeiqi/PycharmProjects/CodeRepository/") # 4、文件或文件夹重命名:move shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/x.png", "/Users/wupeiqi/PycharmProjects/CodeRepository/xxxx.png") # 5、压缩文件(make_archive):名称、格式、对象 shutil.make_archive(base_name=r'datafile',format='zip',root_dir=r'files') # 6、解压文件(unpack_archive):对象、路径、格式 shutil.unpack_archive(filename=r'datafile.zip', extract_dir=r'x/xo', format='zip') -
sys模块
import sys # 1. 获取解释器的版本 print(sys.version) # 2. 获取导入模块路径 print(sys.path) # 3.argv,执行脚本时,python解释器后面传入的参数(要执行的文件路径) print(sys.argv) # ['/Users/wupeiqi/PycharmProjects/luffyCourse/day14/2.接受执行脚本的参数.py'] -
random模块:整数小数、一个多个、打乱顺序
import random # 1. 获取范围内的随机整数:randint v = random.randint(10, 20) # 2. 获取范围内的随机小数:uniform v = random.uniform(1, 10) # 3. 随机抽取一个元素(选择):choice v = random.choice([11, 22, 33, 44, 55]) # 4. 随机抽取多个元素(样本):sample v = random.sample([11, 22, 33, 44, 55], 3) # 5. 洗牌:shuffle data = [1, 2, 3, 4, 5, 6, 7, 8, 9] random.shuffle(data) -
hashlib模块
import hashlib hash_object = hashlib.md5("iajfsdunjaksdjfasdfasdf".encode('utf-8')) # 加盐 hash_object.update("武沛齐".encode('utf-8')) result = hash_object.hexdigest() print(result) # md5加密后无法通过密文反解出密码,但可以把可能的密码加密后形成一个强大的密码本,再通过这个密码本解出密码,这种操作称之为“撞库”。
015 内置模块和开发规范
1、内置模块
-
json模块
json模块用于python格式数据、json格式数据的相互转换; json格式本质上就是个字符串,常用于网络数据传输。(通用的数据交换格式) # Python格式 data = [ {"id": 1, "name": "武沛齐", "age": 18}, ('wupeiqi',123), ] # JSON格式:字符串、无()格式、内部都是双引号(因为最外层用的是单引号) value = '[{"id": 1, "name": "武沛齐", "age": 18},["wupeiqi",123]]'-
核心功能:跨语言数据传输
-
不同语言的基础数据类型格式也不同。为了方便数据传输,大家约定一种格式(json格式),每种语言都可将自己数据类型转换为json格式,也可以将json格式的数据转换为自己的数据类型。
-
**dumps:序列化,**Python数据类型 -> json格式
res = json.dumps(data, ensure_ascii=False) -
**loads:反序列化,**json格式 -> Python数据类型
data_list = json.loads(data_string)
-
-
类型要求:只支持如下的数据类型(其他类型需要自定义
JSONEncoder才能实现)+-------------------+---------------+ | Python | JSON | +===================+===============+ | dict | object | +-------------------+---------------+ | list, tuple | array | +-------------------+---------------+ | str | string | +-------------------+---------------+ | int, float | number | +-------------------+---------------+ | True | true | +-------------------+---------------+ | False | false | +-------------------+---------------+ | None | null | +-------------------+---------------+ -
其他功能
json.dump,将数据序列化并写入文件(不常用)json.load,读取文件中的数据并反序列化为python的数据类型(不常用)
-
-
时间处理:time模块、datatime模块
-
time模块
import time # 获取当前时间戳(自1970-1-1 00:00) v1 = time.time() # 时区 v2 = time.timezone() # 阻塞n秒,再执行后续的代码。 time.sleep(5) -
datetime模块
from datetime import datetime, timezone, timedelta # 当前本地时间 v1 = datetime.now() # 当前UTC时间 v2 = datetime.utcnow() # 当前东8区时间 tz = timezone(timedelta(hours=8)) v3 = datetime.now(tz)# datetime类型 + timedelta类型:时间的加减(计算会员到期时间) v1 = datetime.now() v2 = v1 + timedelta(days=140, minutes=5) # datetime类型 - datetime类型:计算间隔时间(不能相加) v1 = datetime.now() v2 = datetime.utcnow() data = v1 - v2 print(data.days) # datetime类型 比较 datetime类型# 字符串格式时间 ---> datetime格式时间 st = "2021-11-11" dt = datetime.strptime(st, '%Y-%m-%d') # datetime格式时间 ----> 字符串格式时间 dt = datetime.now() st = dt.strftime("%Y-%m-%d %H:%M:%S")# 时间戳格式 --> datetime格式 ctime = time.time() # 11213245345.123 dt = datetime.fromtimestamp(ctime) # datetime格式 ---> 时间戳格式 v1 = datetime.now() val = v1.timestamp()
-
-
正则表达式
-
字符相关
import re text = "你好wupeiqi,阿斯顿发wupeiqasd 阿士大夫能接受的wupeiqiff" data_list = re.findall("wupeiqi", text)wupeiqi匹配确定的字符串“wupeiqi”[abc]匹配包含”a或b或c“的一个字符[^abc]匹配除了abc以外的其他字符[a-z]匹配a~z的任意一个字符( [0-9]类似 ).代指除换行符以外的任意一个字符\w代指一个字母、数字、下划线(可以是汉字)\d代指一个数字\s代指一个任意的空白符,包括空格、制表符等
-
数量相关
*重复0次或多次+重复1次或多次?重复0次或1次{n}重复n次{n,}重复n次或多次{n,m}重复n到m次
-
括号(分组)
- 提取数据区域
- 一个区域:姓孙的名字
- 两个区域:单词的前缀、后缀
- 嵌套区域:某省身份证号码、生日
- 获取指定区域 + 或条件
- 一个区域:93年或94年
- 嵌套区域:生日、2月或3月
- 提取数据区域
-
起始和结束:一般用于对用户输入数据格式的校验(精确匹配)
^开始$结束
-
特殊字符:由于正则表达式中
* . \ { } ( )等都具有特殊的含义,所以匹配时需要转义
-
-
re模块
- findall,获取匹配到的所有数据
- match,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
- search,浏览整个字符串,匹配成功返回一个对象,未匹配成功返回None
- sub,替换匹配成功的字符(敏感词)
- split,根据匹配成功的字符分割(不包括分隔符)
- finditer,迭代匹配(数据量大)、命名分组
2、项目开发规范
-
单文件应用
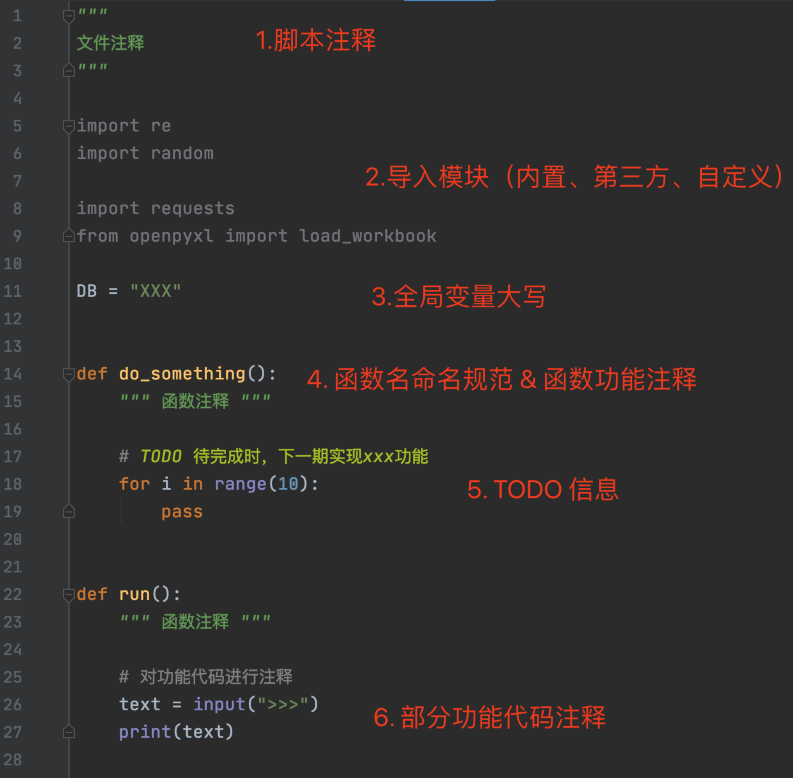
-
单可执行文件
crm ├── app.py 文件,程序的主文件(尽量精简) ├── config.py 文件,配置文件(放相关配置信息,代码中读取配置信息,如果想要修改配置,即可以在此修改,不用再去代码中逐一修改了;比如发邮件时的用户名、密码、服务器邮箱、个人邮箱等) ├── db 文件夹,存放数据(用户信息) ├── files 文件夹,存放文件(别人写好的excel文件、图片) ├── src 包,业务处理的代码(登录、注册) └── utils 包,公共功能(发邮件、发微信) -
多可执行文件
killer ├── bin 文件夹,存放多个主文件(可运行、启动文件) │ ├── app1.py │ └── app2.py ├── config 包,配置文件 │ ├── __init__.py │ └── settings.py ├── db 文件夹,存放数据(用户信息) ├── files 文件夹,存放文件(别人写好的excel文件、图片) ├── src 包,业务代码(登录、注册) │ └── __init__.py └── utils 包,公共功能(发邮件、发微信) └── __init__.py
016 阶段总结
1、知识补充
- nolocal关键字:使用上一级作用域的变量
- yield from 函数:原函数执行到此处时,先执行另一函数的代码,再接着执行原函数余下的代码
- 深浅拷贝
- 浅拷贝:v2 = copy.copy(v1)
- 不可变类型:由于python内部优化机制,拷贝后的内存地址是相同的;
- 可变类型:只拷贝第一层,如列表的内存地址,而内部的元素及其内存地址都不会拷贝;
- 深拷贝:v2 = copy.deepcopy(v1)
- 不可变类型:不拷贝
- 可变类型,找到所有层级的 【可变类型】或【含有可变类型的元组】均拷贝一份
- 特殊的元组(不可变类型):
- 元组元素无可变类型(都是不可变类型),不拷贝
- 元组元素中有可变类型,找到所有【可变类型】或【含有可变类型的元组】均拷贝一份
- 总结:
- 深浅拷贝一般都是说的可变类型:set、list、dict(不可变类型在进行深浅拷贝时无意义-内部都不会去拷贝,永远是同一块内存地址)
- 浅拷贝,只拷贝第一层的可变类型
- 深拷贝,拷贝所有层的可变类型 + 元组中如果有可变类型,也会被拷贝。
- 浅拷贝:v2 = copy.copy(v1)
思维导图
链接:https://www.zhixi.com/view/ded6b99d
密码:9028















 1563
1563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









