







一、指针的定义与使用
指针是高级编程语言中非常重要的概念,在高级语言的编程中发挥着非常重要的作用,它能使得不同区域的代码可以轻易的共享内存数据。指针使得一些复杂的链接性的数据结构的构建成为可能,有些操作必须使用指针,比如申请堆内存,还有C++或者C语言中函数的调用中值传递都是按值传递的,如果在函数中修改被传递的对象,就必须通过这个对象指针来完成。指针就是内存地址,指针变量就是用来存放内存地址的变量,不同类型的指针变量所占用的存储单元长度是相同的,而存放数据的变量因为数据类型不同,因此所占的存储空间长度也不同。使用指针不仅可以对数据本身,也可以对存储数据变量的地址进行操作。很多萌新在刚开始学习编程的时候会被指针搞蒙,那现在就让我给大家详细讲解指针的使用。
1、指针的引入(函数返回中return语句的局限性)
函数的缺陷:
一个函数只能返回一个值,就算我们在函数里面写多了return语句,但是只要执行任何一条return语句,整个函数调用就结束了。
数组可以帮助我们返回多个值,但是数组是相同数据类型的结合,对于不同数据类型则不能使用数组
使用指针可以有效解决这个问题,使用指针我们想反回几个值就能返回几个值,想返回什么类型就可以返回什么类型的值。在程序设计过程中,存入数据还是取出数据都需要与内存单元打交道,计算机通过地址编码来表示内存单元。指针类型就是为了处理计算机地址数据的,计算机将内存划分为若干个存储空间大小的单元,每个单元大小就是一个字节,即计算机将内存换分为一个一个的字节,然后为每一个字节分配唯一的编码,这个编码即为这个字节的地址。指针就是用来表示这些地址的,即指针型数据不是什么字符型数据,而存的是我们内存中的地址编码。指针可以提高程序的效率,更重要的是能使一个函数访问另一个函数的局部变量,指针是两个函数进行数据交换必不可少的工具。
地址及指针的概念:
程序中的数据(变量,数组等)对象总是存放在内存中,在生命期内这些对象占据一定的内存空间,有确定的存储位置,实际上,每个内存单元都有一个地址,即以字节为单位连续编码。编译器将程序中的对象名转换成机器指令识别的地址,通过地址来存储对象值。
int i; double f;
计算机为int 类型数据分配4个字节,为double 类型分配8个字节。按对象名称存取对象的方式成为对象直接访问,如:i=100; f=3.14; 通过对象地址存取对象的方式成为指针间接访问
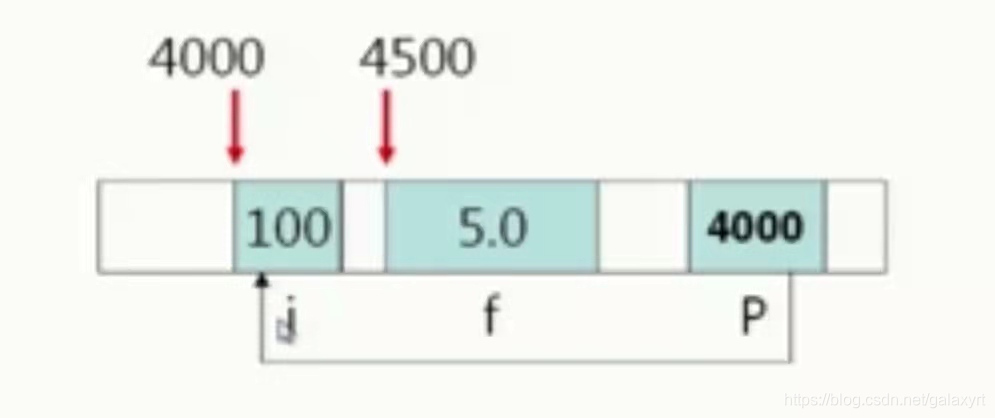 如图,这里有一个名为4000的存储空间它放的不是数值,而是 i 这个变量的地址,i 占有四个字节每个字节都有一个地址,这个变量的地址其实就是第一个字节的地址,在这里 i 的地址指就是他第一个字节的地址,假设第一个地址是4000,这里有一个p,先不管他是个啥东西,他占了一段存储空间,他里面放的就是 i 的地址,现在我们要访问 i 但是我们不直接访问,不出现 i 的名字,而是通过找到 p 得到了p里面放的 i 的地址以后就能间接的去访问 i ,就是说我们不是直接访问这个地址的,而是通过 P 这个量去访问 i 的值,这样的访问方式就叫做指针间接访问。即通过对象的地址来存储对象的方式称为指针间接访问。
如图,这里有一个名为4000的存储空间它放的不是数值,而是 i 这个变量的地址,i 占有四个字节每个字节都有一个地址,这个变量的地址其实就是第一个字节的地址,在这里 i 的地址指就是他第一个字节的地址,假设第一个地址是4000,这里有一个p,先不管他是个啥东西,他占了一段存储空间,他里面放的就是 i 的地址,现在我们要访问 i 但是我们不直接访问,不出现 i 的名字,而是通过找到 p 得到了p里面放的 i 的地址以后就能间接的去访问 i ,就是说我们不是直接访问这个地址的,而是通过 P 这个量去访问 i 的值,这样的访问方式就叫做指针间接访问。即通过对象的地址来存储对象的方式称为指针间接访问。
现在我们来举个例子详细了解一下指针到底是一个什么东东
一个快递员送快递,如果送的是一个老顾客,那么快递员可以直接跑到顾客的办公地点,将快递交给她就行了,这就是直接访问。但是如果现在快递员拿到了一个不认识的人的快递他是一个新顾客,那么快递员跑到他的办公地点,办公地点有很多人,他也分不清谁是谁,于是快递员找到了这里的一个保安问“张三是谁”保安就会给他指出张三就是这个人。然后快递员才能把快递送到顾客手上。此时这个中间来指出张三的人(保安)就是起了指针的作用,快递员无法直接找到张三,因此他只有通过保安才能给他指出张三是谁,这就叫做间接访问。
2、指针的定义形式方法及其含义
c++将专门用来存放对象地址的变量叫做指针变量,下面是指针变量定义形式:
指针类型* 指针变量名;
例如:
int* p, i; //定义指针变量p,i为整形变量
p = &i; //指针变量p指向i
把 i 的地址放到p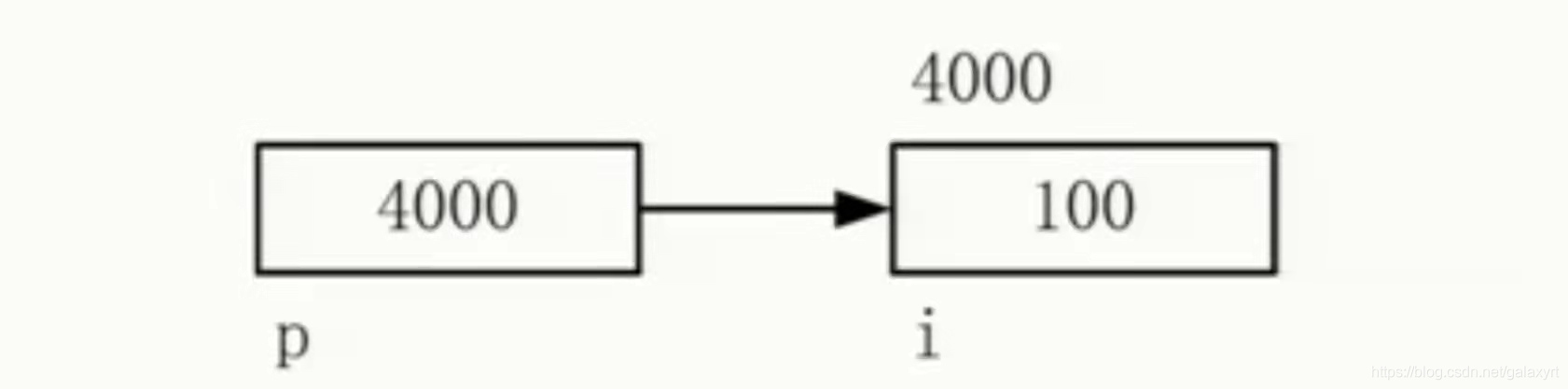
i 里放的是100这个数他的地址是4000,p里面放的就是i 的地址,然后就将p 指向i,他俩的关系即为p指向i,

假定指针变量p 的值是4000,三种写法:
char* p;
int* p;
double* p;
指针的类型其实就是它所指向的对象的类型指针的类型:
指针的类型表明的就是他所指向的对象的类型,把p定义为char类型,即用char类型的指针P来间接访问它指向的对象时我们间接引用的是一个字节的空间,假设p放的是4000,则系统会默认p指向的是4000这一个字节里面的内容,若将p定义成整形那么意味着我们用间接引用的方式来用指针指向对象的时候,系统就会认为你 的指针占4个字节这个对象就是4000,4001, 4002, 4003 这四个字节共同组成这个对象,若定义为double类型,那么系统就会认为他指向的对象时8个字节的即4000~~4007这八个字节都认为是P所指向的对象。这就是指针类型的含义,指针的类型应该和他指向的对象的类型一致,即整形指针应该指向整形变量,实型指针指向实型的变量。
3、通过指针间接访问
通过间接引用运算 * 可以访问指针所指向的对象或者内存单元,即在指针前面加上一个 * 就表明指针所引用的东西
int a, * p = &a;
a = 100;//直接访问a(对象直接访问)
*p = 100;//*p就是a,间接访问a(指针间接访问)
*p = *p + 1;//等价于a=a+1int a, b, * p1 = &a, * p2;
&*p1 的含义:
&和*都是自右向左运算符,因此先看p1是指针,*p1即为p1指向的对象,
因此*p1等价于a,因此a 的前面加一个&,表示的就是 a 的地址
因此:&*p1 ,p1 ,&a 三者等价
*&a 的含义:a的地址前加*表示的就是a本身,指针就是用来放地址的,地址前面加*表示的就是这个对象
因此: *&a ,a ,*p 三者等价
int main()
{
int i = 100, j = 200;
int* p1, * p2;
p1 = &i, p2 = &j;//p1指向i,p2指向j
*p1 = *p1 + 1;//等价于i=i+1
p1 = p2;//将p2的值赋给p1,则p1指向j
*p1 = *p1 + 1;//等价于j=j+1
return 0;
}4、指针的初始化,可以在定义指针时对它进行初始化
指针类型* 指针变量名 = 地址初值,......
int a;
int* p = &a;//p的初值为变量a 的地址
int b, * p1 = &b;//p1初始化是变量b已有地址值由于指针数据的特殊性,他的初始化和赋值运算是有约束条件的,只能使用以下四种值:
(1)0值常量表达式:
int a, z = 0;
int p1 = null; //指针允许0值常量表达式
p1 = 0;//指针允许0只常量表达式
下面三中形式是错误的:
int* p1 = a;//错误 地址初值不能是变量
int p1 = z;//错误 整形变量不能作为指针,即使值为0
p1 = 4000;//错误,指针允许0值常量表达式
(2)相同指向类型的对象的地址。
int a, * p1;
double f, * p3;
p1 = &a;
p3 = &f;
p1 = &f;//错误p1和f指向类型不同
(3)相同指向类型的另一个有效指针
int x, * px = &x;
int* py = px;//相同指向类型的另一个指针
(4)对象存储空间后面下一个有效地址,如数组下一个元素的地址
int a[10], * px = &a[2];
int* py = &a[++i];5、指针运算
指针运算都是作用在连续存储空间上才有意义。
(1)指针加减整数运算
int x[10], n = 3, * p = &x[5];
p + 1 //指向内存空间中x[5]后面的第1个int 型存储单元
p + n //--------------------------n(3)个
p - 1 //-------------------前面-----1个
p - n //
(2)指针变量自增自减运算
int x[10], * p = &x[5];
p++ //p指向x[5]后面的第1个int型内存单元
++p //-----------------1--------------
p-- //p指向x[5]前面的第1个int型内存单元
--p //--------------------------------
(3)两个指针相减运算
设p1, p2是相同类型的两个指针,则p2 - p1的结果是两支针之间对象
的个数,如果p2指针地址大于p1则结果为正,否则为负
int x[5], * p1 = &x[0], * p2 = &x[4];
int n;
n = p2 - p1;//n 的值为4 即为他们之间间隔的元素的个数
运算方法:(p2储存的地址编码-p1储存的地址编码)/4 若是double类型则除以8 char类型除以1
(1)指针加减整数运算
int x[10], n = 3, * p = &x[5];
p + 1 //指向内存空间中x[5]后面的第1个int 型存储单元
p + n //--------------------------n(3)个
p - 1 //-------------------前面-----1个
p - n //
(4)指针的运算关系
设p1、p2是同一个指向类型的两个指针,则p1和p2可以进行关系运算,
用于比较这两个地址的位置关系即哪一个是靠前或者靠后的元素
int x[4], * p1 = &x[0], * p2 = &x[4];
p2 > p1; //表达式为真
6、指针的const限定
(1)一个指针变量可以指向只读型对象,称为指向const对象的指针定义形式是:
const 指向类型 *指针变量,...即在指针变量前加const限定符,其含义是不允许通过指针来改变所指向的const对象的值,不能通过间接引用来改变它所指向的对象的值
const int a = 10, b = 20;
const int* p;
p = &a;//正确 p不是只读的,把a的地址赋给p,给p赋值是允许的
p = &b;//正确,p不是只读的
*p = 42;//把42赋给p所指向的对象。错误,*p是只读的(2)把一个const对象的地址赋给一个非const对象的指针是错误的,例如:
const double pi = 3.14;
double* ptr = π//错误,ptr是非const所指向的变量
const double* cptr = π//正确,cptr是const指针变量(3)允许把非const对象的地址赋给指向const对象的指针,不能使用指向const对象的指针修改指向对象,然而如果该指针指向的是一个非const对象,可以用其他方法修改其所指向的对象
const double pi = 3.14;
const double* cptrf = π//正确
double f = 3.14;//f是double类型(非const类型)
cptr = &f;//正确,允许将f的地址赋给cptrf
f = 1.68;//正确,允许修改f的值
*cptrf = 10.3;//错误不能通过引用cptr修改f的值(4)实际编程过程中,指向const的指针常用作函数的形参,以此确保传递给函数的参数对象在函数中不能被修改
void fun(const int* p)
{
...
}
int main()
{
int a;
fun(&a);
}
指针作为函数的形参,在主函数中,我们定义整形变量a然后将a的地址传递给了子函数,对于子函数来说,
他的形参就是用const修饰过 的整型变量p指向主函数里a这个变量
这样的一系列操作就使得我们不能在子函数中通过p间接引用a 来改变a 的值,因为a 是用const修饰过的作就使得我们不能在子函数中通过p间接引用a 来改变a 的值,因为a 是用const修饰过的7、const指针
一个指针变量可以是只读的,成为const指针它的定义形式:
指针类型* const 指针变量, ...;
注意观察将const放在变量名的前面,与上面的形式不同,
int a = 10, b = 20;
int* const pc = &a;//pc是const指针
pc = &b;//错误pc 是只读的
pc = pc;//错误pc是只读的
pc++;//错误pc是只读的
*pc = 100;//正确,a被修改pc是指向int型对象的const指针
不能使pc再被赋值指向其他对象,任何企图给const指针赋值的操作都会导致编译错误
但是可以通过pc间接引用修改该对象的值
二、一维数组与指针
1、数组的首地址
数组有若干个元素组成,每个元素都有相应的地址,通过取地址运算符&可以得到每个元素的地址,数组的地址就是这一整块存储空间中,第一个元素的地址即a[0]
int a[10];
int* p = &a[0];//定义指向一维数组元素的指针,用a数组的地址来初始化p,称p指向a
p = &a[5];//指向a[5] 重新给p赋值,指针数组元素的地址跟取变量的地址是一样的效果,
c++中规定数组名既代表数组本身,又代表整个数组的地址,还是数组首元素的地址值即:与a第0个元素的地址& a[0]相同
例如:
下面两个语句是等价的:
p = a;
p = &a[0];
数组名是一个指针常量,因而他不能出现在左值和某些算数运算中
例如:
int a[10], b[10], c[10];
a = b;//错误,a是常量,不能出现在左值的位置
c = a + b;//错误,a,b是地址值,不允许加法运算
a++;//错误,a 是常量不能使用++运算2、指向一维数组的指针变量
定义指向一维数组元素的指针变量时,指向类型应该与数组元素类型一致
int a[10], * p1;
double f[10], * p2;
p1 = a;//正确
p2 = f;//正确
p1 = f;//错误,指向类型不同不能赋值3、通过指针访问一维数组
由于数组的元素地址是规律性增加的,根据指针 运算规律,可以利用指针及其运算来访问数组元素
int* p, a[10] = { 1,2,3,4,5,6,7,8,9,0 };
p = a;//指向数组a,其实就是让p指向了a[0]
p++;//指向了下一个数组元素即a[1]
根据上图,我们设:
a是一个一维数组,p是指针变量,且p=a;下面我们来访问一个数组元素 a[i];
(1)数组下标法:a[i];
(2)指针下标法:p[i]; p里面已经放了数组的地址了,因此数组名和p 是等价的所以 p[i]与a[i]含义相同
(3)地址引用法:*(a+i); a表示的是下标为0 的元素的地址 (a+i) 即为a这个数组往后数第 i 个元素的地址 即第 i 个元素的地址 那么*(a+i)相当于地址再加一个星号表示的就是这个地址对应的存储单元,或者说对应的对像即为 a[i]这个元素
(4)指针引用法:*(p+i);将a替换成p跟(3)含义相同
下面我们用多种方法来遍历一维数组元素:
(1)下标法:优点是程序写法直观,能直接知道访问的是第几个元素
#include<iostream>
using namespace std;
int main()
{
int a[4];
for (int i = 0; i < 4; i++)
cin >> a[i];
for (int i = 0; i < 4; i++)
cout << a[i] << " ";
return 0;
}(2)通过地址间接访问数组元素
#include<iostream>
using namespace std;
int main()
{
int a[5],i;
for (i = 0; i < 5; i++)
cin >> *(a + i);
for (i = 0; i < 5; i++)
cout << *(a + i) << " ";
}(3)通过指向数组的指针变量间接访问数组,用指针作为循环控制变量 优点是指针直接指向元素,不必每次都重新计算地址,能提高运行效率(我们用P某一个元素的时候p本身已经放了这个元素的地址,因此计算机就不用再去计算这个元素的地址,因为取一个元素的时候要先知道他的地址),将自增自减运算用于指针变量十分有效,可以使指针变量自动向前或者向后指向数组的下一个或前一个元素
#include<iostream>
using namespace std;
int main()
{
int a[5], * p;
for (p = a; p < a + 5; p++)
cin >> *p;
for (p = a; p < a + 5; p++)
cout << *p << " ";
}指针p初值为a,即一开始指向元素a[0],指针可以进行比较运算 p
cin>>*p;即为间接的引用了p所指向的数组元素。
三、用指针来操纵字符串
可以利用一个字符型的指针来处理字符串,其中过程与通过指针访问数组元素相同,使用指针可以简化字符串的处理。
c++允许定义一个字符指针,初始化是指向一个字符常量,一般形式为:
char* p = "C Language";
或者
char* p;
p="C Language"
初始化时,p存储了这个字符串字符地址,而不是字符串常量本身,相当于char类型的指针指向"C Language"这个字符串的首地址,即第一个元素C的地址称p指向字符串
下面我们通过字符串指针来访问字符串
char str[] = "C Language", * p = str;//p指向字符串的指针相当于p指向了str[0]
cout << p << endl;//输出:C Language 跟cout<<str<<endl;效果相同
cout << p + 2 << endl;//输出:Language 从字符L开始输出直到结束
cout << &str[7] << endl;//输出:age 从第7个元素开始输出
#include<iostream>
using namespace std;
int main()
{
char str[] = "C language", * p = str;
cout << p << endl;
return 0;
}
运行结果:

#include<iostream>
using namespace std;
int main()
{
char str[] = "C language";
char* p = str;
cout << p+2 << endl;
return 0;
}

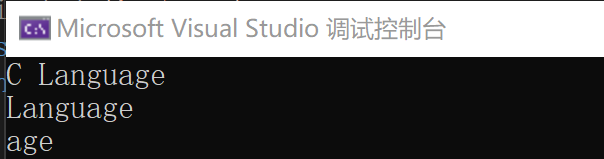
#include<iostream>
using namespace std;
int main()
{
char str[] = "C Language";
char* p = str;
cout << p << endl;
cout << p+2 << endl;
cout << &str[7] << endl;
return 0;
}
通过字符指针来遍历字符串
char str[] = "C Language", * p = str;
while (*p!='\0')cout << *p++;
判断p指向的元素是不是字符串结束的标志*p++ 的含义:先输出p指向的元素然后p++(后置增增,先做完其他事再自增)
假设从str[0]开始,p指向的是C满足(*p!='\0')因此执行循环,下一个循环p指向“空格”不是字符串结束的标志,继续
循环直到遇到字符串结束的标志后结束循环
举例:
#include<iostream>
using namespace std;
int main()
{
char str[100], * p = str;
cin >> str;
while (*p)p++;
cout << "strlen=" << p - str << endl;
return 0;
}
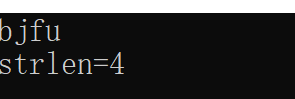
while(*p)p++;的含义:进入循环判断逻辑值p是否为真,(非零为真,零为假)即判断p是否指向字符串结束标志(字符串结束标志符ASLL码为0)若p指向的字符不是空字符则括号内容为真执行循环p++(p指向下一个字符),否则结束循环
p-str为指针相减运算即看这两个指针中间相隔了多少个元素,这里的p已经是字符串结束标志,str表示的str[0]
注意:
指针可以指向数组,这使得数组访问多了一种方式,单指针不能代替数组存储大批量元素
char s[100] = "Computer";
s是数组名不能赋值,自增自减运算
char* p = "Computer";
p是一个指针,他存放的是这个字符串的首地址
p是一个指针变量,他能指向这个字符串也能指向其他东西可以进行赋值和自增自减
1、存储内容不同
2、运算方式不同
3、赋值操作不同
s一旦赋初值之后就不能再用其他字符来赋值,然而p却能重新指向其他字符
int a = 10, * p;
int& b = a;
p = &a;
string s = "C++";
string* ps = &s;
cout << p << endl; //输出指针p的值,a变量的首地址
cout << b << endl; //输出b的值是10
cout << *p << endl; //输出指针p指向的变量,即a的值10
cout << ps << endl;; //输出指针ps的值,s变量的地址
cout << *ps << endl; //输出指针ps指向的变量的值,即“C++”
二维数组字符串:
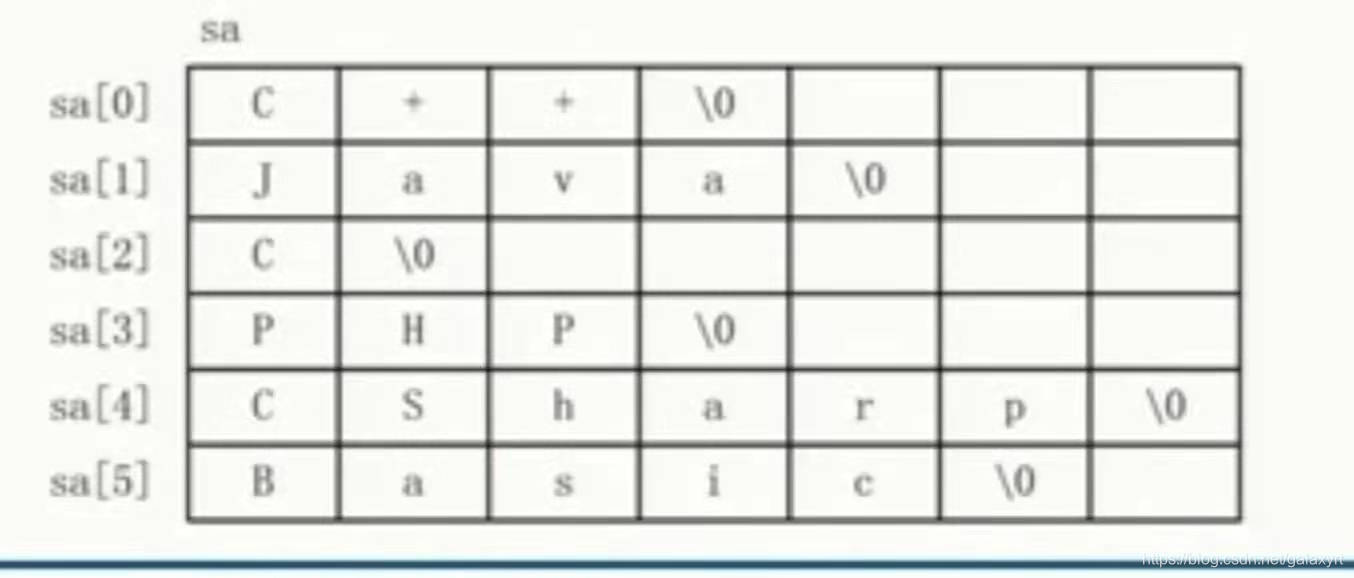
char s[6][7] = { "C++","Java","C","PHP","CSharp","Basic" };
内存形式
615134

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









