






第一次参加阿里天池的比赛,虽然总成绩没能进前十,但是网页题做的还不错(最终排名第二,成绩0.8312分)。在这里记录一下网页文本分类题的解题思路和赛后总结:
出题背景是阿里云服务器上存在着很多非法网页,需要通过机器学习算法识别出网页的类别,对非法网页进行打击。原始数据是网页静态html代码,但可转换为文本分类问题。训练集的标签已给出,共有4个类别:
1. fake_card(证件卡票):提供伪造证件、发票、证明材料等制作服务;
2. gambling(赌博类):包括赌博交易、网络博彩、赌博器具等;
3. sexy(色情类):包括色情传播、文图视频、网络招嫖等;
4. normal(正常类):不包含以上内容的网页。
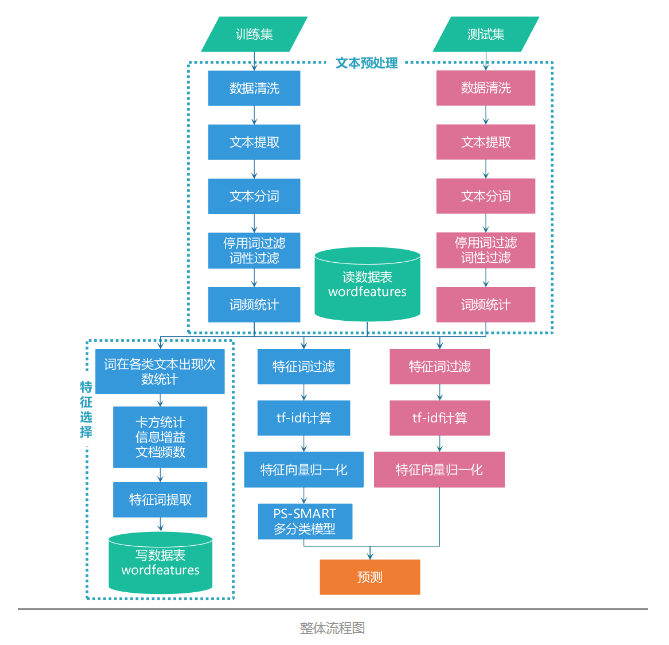
算法整体流程图:
关键步骤:
1、数据预处理
训练数据中,id字段是经过hash处理的,会出现id重复的情况,需要根据id对数据进行去重;另外对各类型网页html文本长度的统计结果如下所示:
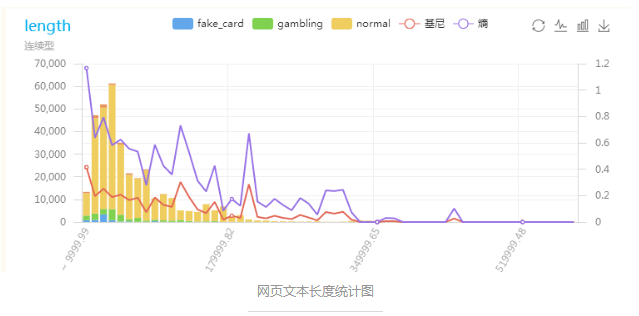
网页文本长度大于200000的不到网页数据总量的1%,且基本不包含风险网页,所以对其进行清除,减少后续的计算量;观察出字符长度小于200的网页中大部分内容为"404 ERROR","正在等待响应...",'"排队中..."等内容,对模型的训练没有用处,也要进行清除。代码在下方:
--计算id的出现次数
select id, risk, html, count(id) over (partition by id) as count from ${t1} ;
--计算html文本的长度
select *, length(html) as html_length from ${t1} ;
--数据清理
select * from ${t1} where count = 1 and html_length > 200 and html_length < 200000 ;
2、网页文本提取
html字段是网页的源代码,包含了结构化的html标签,<style>、<script>等标签中的内容不包含语义信息,参考文献[5]中结论,实验中只对title、keywords、description、body标签中的文本进行提取,另外去除文本中的特殊字符,仅保留英文、中文以及常见的标点符号。html中文本内容的提取通过在MapReduce的map函数中调用jsoup库实现(因为ODPS有沙箱隔离的限制,实验中抽取了jsoup的核心代码放到自定义的包中打包上传)
package cn.edu.whu.tianchi_htmlclassify; import cn.edu.whu.tianchi_htmlclassify.nodes.Document; import cn.edu.whu.tianchi_htmlclassify.nodes.Element; import cn.edu.whu.tianchi_htmlclassify.select.Elements; import com.aliyun.odps.OdpsException; import com.aliyun.odps.data.Record; import com.aliyun.odps.data.TableInfo; import com.aliyun.odps.mapred.JobClient; import com.aliyun.odps.mapred.MapperBase; import com.aliyun.odps.mapred.conf.JobConf; import com.aliyun.odps.mapred.utils.InputUtils; import com.aliyun.odps.mapred.utils.OutputUtils; import com.aliyun.odps.mapred.utils.SchemaUtils; import java.io.IOException;
public class HtmlExtractor {
public static void main(String[] args) throws OdpsException {
JobConf job = new JobConf();
job.setMapperClass(MapperClass.class);
job.setMapOutputKeySchema(SchemaUtils.fromString("id:string"));
job.setMapOutputValueSchema(SchemaUtils.fromString("title:string,keywords:string,description:string,bodytext:string"));
job.setNumReduceTasks(0);
InputUtils.addTable(TableInfo.builder().tableName(args[0]).build(), job);
OutputUtils.addTable(TableInfo.builder().tableName(args[1]).build(), job);
JobClient.runJob(job);
}
<span class="hljs-keyword">public</span> <span class="hljs-keyword">static</span> <span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">MapperClass</span> <span class="hljs-keyword">extends</span> <span class="hljs-title">MapperBase</span> </span>{
<span class="hljs-keyword">private</span> Record output;
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">void</span> <span class="hljs-title">setup</span><span class="hljs-params">(TaskContext context)</span> <span class="hljs-keyword">throws</span> IOException </span>{
output = context.createOutputRecord();
}
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">void</span> <span class="hljs-title">map</span><span class="hljs-params">(<span class="hljs-keyword">long</span> key, Record record, TaskContext context) </span><span class="hljs-keyword">throws</span> IOException </span>{
<span class="hljs-comment">//id原样设置</span>
output.set(<span class="hljs-number">0</span>, record.get(<span class="hljs-string">"id"</span>).toString());
String html = record.get(<span class="hljs-string">"html"</span>).toString();
String bodyText = <span class="hljs-keyword">new</span> String();
String title = <span class="hljs-keyword">new</span> String();
String description = <span class="hljs-keyword">new</span> String();
String keywords = <span class="hljs-keyword">new</span> String();
Document doc = <span class="hljs-keyword">null</span>;
<span class="hljs-keyword">try</span> {
<span class="hljs-comment">//使用Jsoup解析html</span>
doc = Jsoup.parse(html);
<span class="hljs-comment">//去除隐藏的html标签</span>
doc.select(<span class="hljs-string">"*[style*=display:none]"</span>).remove();
<span class="hljs-comment">//获取title文本</span>
Elements titles = doc.select(<span class="hljs-string">"title"</span>);
<span class="hljs-keyword">for</span> (Element element : titles) {
title = title + element.text();
}
<span class="hljs-comment">//获取keywords文本</span>
Elements metaKey = doc.select(<span class="hljs-string">"meta[name=keywords]"</span>);
<span class="hljs-keyword">for</span> (Element element : metaKey) {
keywords = keywords + element.attr(<span class="hljs-string">"content"</span>);
}
<span class="hljs-comment">//获取description文本</span>
Elements metaDes = doc.select(<span class="hljs-string">"meta[name=description]"</span>);
<span class="hljs-keyword">for</span> (Element element : metaDes) {
description = description + element.attr(<span class="hljs-string">"content"</span>);
}
<span class="hljs-comment">//获取body文本</span>
Elements body = doc.select(<span class="hljs-string">"body"</span>);
<span class="hljs-keyword">for</span> (Element element : body) {
bodyText = bodyText + element.text();
}
} <span class="hljs-keyword">catch</span> (Exception e) {
bodyText = <span class="hljs-string">""</span>;
} <span class="hljs-keyword">finally</span> {
<span class="hljs-comment">//仅保留数字、字母、中文、常用的标点符号</span>
output.set(<span class="hljs-number">1</span>,title.replaceAll(<span class="hljs-string">"[^0-9a-zA-Z\u4e00-\u9fa5.,、,。?“”]+"</span>, <span class="hljs-string">""</span>));
output.set(<span class="hljs-number">2</span>,keywords.replaceAll(<span class="hljs-string">"[^0-9a-zA-Z\u4e00-\u9fa5.,、,。?“”]+"</span>, <span class="hljs-string">""</span>));
output.set(<span class="hljs-number">3</span>,description.replaceAll( <span class="hljs-string">"[^0-9a-zA-Z\u4e00-\u9fa5.,、,。?“”]+"</span>, <span class="hljs-string">""</span>));
output.set(<span class="hljs-number">4</span>,bodyText.replaceAll(<span class="hljs-string">"[^0-9a-zA-Z\u4e00-\u9fa5.,、,。?“”]+"</span>, <span class="hljs-string">""</span>));
context.write(output);
}
}
}
}
3、文本分词
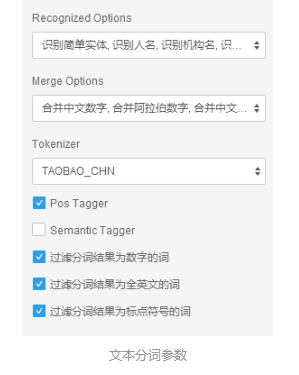
在中文文本分类中,常用的特征单元有字、词、字串(character n-gram)及其组合,中文中单个字的语义质量不是很好,一般不作为特征单元,词与二字串的效果相似。在天池PAI平台上,有基于AliWS(Alibaba Word Segmenter的简称)的分词组件,若用户指定了词性标注或语义标注相关参数,则会将分词结果、词性标注结果和语义标注结果一同输出。在这里勾选词性标注,在词的初步过滤中会用到词性。
4、词初步过滤
1. 停用词过滤
使用https://github.com/JNU-MINT/TextBayesClassifier 中停用词;
2. 词性过滤(仅保留动词、名词)
参考[7]中实验结果,仅适用动词、名词作为特征词。
查看更多内容,欢迎访问天池技术圈官方地址:网页文本分类题赛后总结(排名第二)_天池技术圈-阿里云天池


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









