






关联比赛: 首届云原生编程挑战赛【复赛】实现一个 Serverless 计算服务调度系统
一、初赛赛道一(实现一个分布式统计和过滤的链路追踪)
赛题分析
1、数据来源
采集自分布式系统中的多个节点上的调用链数据,每个节点一份数据文件。数据格式进行了简化,每行数据(即一个span)包含如下信息:
traceId | startTime | spanId | parentSpanId | duration | serviceName | spanName | host | tags
具体各字段的:
traceId:全局唯一的Id,用作整个链路的唯一标识与组装
startTime:调用的开始时间
spanId: 调用链中某条数据(span)的id
parentSpanId: 调用链中某条数据(span)的父亲id,头节点的span的parantSpanId为0
duration:调用耗时
serviceName:调用的服务名
spanName:调用的埋点名
host:机器标识,比如ip,机器名
tags: 链路信息中tag信息,存在多个tag的key和value信息。格式为key1=val1&key2=val2&key3=val3 比如 http.status_code=200&error=1
数据总量足够大
文件里面有很个调用链路(很多个traceId)。每个调用链路内有很多个span(相同的traceId,不同的spanId)
例如文件1有
d614959183521b4b|1587457762873000|d614959183521b4b|0|311601|order|getOrder|192.168.1.3|http.status_code=200
d614959183521b4b|1587457762877000|69a3876d5c352191|d614959183521b4b|305265|Item|getItem|192.168.1.3|http.status_code=200
文件2有
d614959183521b4b|1587457763183000|dffcd4177c315535|d614959183521b4b|980|Loginc|getLogisticy|192.168.1.2|http.status_code=200
d614959183521b4b|1587457762878000|52637ab771da6ae6|d614959183521b4b|304284|Loginc|getAddress|192.168.1.2|http.status_code=2
2、需求
用户需要实现两个程序,一个是数量流的处理程序,该机器可以获取数据源的http地址,拉取数据后进行处理,一个是后端程序,和客户端数据流处理程序通信,将最终数据结果在后端引擎机器上计算
3、要求
找到所有tags中存在 http.status_code 不为 200,或者 error 等于1的调用链路。输出数据按照 traceId 分组,并按照startTime升序排序。记录每个 traceId 分组下的全部数据,最终输出每个traceId下所有数据的CheckSum(Md5值)。
4、难点
如何快速找到error trace,这也是赛题的核心,由于每个trace会分布在多个节点,某trace在当前节点不为error trace,但在其他节点却可能为error trace
缓存设计
数据流缓存:采用环的形式,缓存大小:2GB+最大行长度
metadata缓存:用于记录数据流缓存中的数据,采用环的形式,最大容量:(WINDOW_SIZE * 64 * 2)条
struct TraceOffsetLink
{
uint64_t traceId; //traceId
uint64_t globaloffset; //文件中的偏移 缓存中的偏移 =(文件中的偏移%(数据流缓存大小-最大行长度))
uint64_t lineIndex; //行号
int32_t prev; //用于记录该span 前一个tracespan的位置,如果不使用map,可以去掉
uint16_t len; //长度
uint16_t flag; //标志
};
1、客户端分别记录处理长度和最大下载长度。
拉数据时确保: 最大下载长度 - 处理长度 < 数据流缓存大小 - 最大行长度 - 单次下载大小
处理时确保: 最大下载长度 - 处理长度 > 最大行长度
2、客户端分别记录本地处理行数和所有客户端的最小处理行数
处理时确保: 本地处理行数 - 最小处理行数 < metadata最大长度 - 窗口大小
客户端<->后端引擎 通信逻辑
1、同步
客户端每隔一段时间(2个窗口大小的时间,可调整),向后端引擎发送其处理行数,
后端引擎会记录所有客户端的处理行数,并计算一个最小值,每当最小值发生变化时,会将这个最小值发送给所有客户端,
2、发送wrongtrace
A、客户端使用map的方案
每个客户端独自维护一个map,用于记录每个trace在metadata缓存中最后一次出现的位置。(同一trace下的span组成一个链表)
每个客户端按行处理判断span是否为wrongtrace
如果当前span为wrong trace,发送traceid给后端引擎,后端引擎收到后发给其它客户端,其它客户端收到后到,在map中查找该trace最后一次出现的位置。对于当前客户端则直接查找。
-
如果map中查找到该trace有记录位置且为-1,表示曾经已经判断该trace为wrong了,不需要做处理,只需要发当前span给后端引擎(trace一旦已经判断为wrong trace了,前面出现的该trace下的span会全部发给后端引擎,这时再出现不需要考虑前面的),
-
如果map中查找到该trace有记录位置且为不为-1,这时需要将前面出现的该trace下的span全部发给后端引擎,并更新map中的位置为-1,发送时根据prev回溯(同一trace下的span组成一个链表),直到遇到-1。
-
如果map中查找到该trace没有记录位置,在map中插入-1
如果当前span不为wrong trace,在map中查找该trace最后一次出现的位置:
-
如果map中查找到该trace有记录位置且为-1,表示曾经已经判断该trace为wrong了,不需要做处理,只需要发当前span给后端引擎
-
如果map中查找到该trace有记录位置且不为-1,更新map中的位置为当前span的位置,并把当前span的prev指向map原来的记录的位置
-
如果map中查找到该trace没有记录位置,在map中插入当前span的位置,并把当前span的prev指向-1
B、客户端不使用map的方案
-
每个客户端按行处理判断span是否为wrongtrace,如果是wrong trace,则发送traceid和对应行数给后端引擎。
-
后端引擎收到后先检查一下是否已经收到过该traceid,没有收到过,则将该traceid和对应行数发给所有客户端。
-
客户端收到后,在metadata中对应行数位置遍历前后2万条,对应traceid的span数据发送给后端引擎。
查找wrong trace(核心)
查找wrong trace最终有2个方案,纯处理的话方案2大概比方案1快2百多ms。(后面由于加入了长tag,方案1应该比原来快一点)
2个方案在线上用时无差异,都是下载速度跟不上处理速度(前期测试的,后期只测试了方案2)
1、基于单字符搜索&再匹配
此方法很准确,速度也快,但相比方案2较慢(后面由于加入了长tag,应该比原来快一点)
第一步,同时寻找&和\n,
第二步,如果为\n,退出查找,如果为&,判断下一字符是否为'h'或'e',
第三步,如果下一字符为'h'或'e',则进一步判断是否为"http.status_code=200&"或"error=1&"或"http.status_code=200\n"或"error=1\n",否则回到第一步
2、基于双字符搜索直接查找字符串
在"http.status_code=200"中选取1对交叉的长度为2的低频子串,例如
"s_" "_c"
或
".s" "_c"
当搜索到这2个子串时,再进一步判断是否为 "http.status_code=200"
" error=1" 同理
此方法速度稍快,但有一些缺陷
-
因为此方法没有以&为边界,而是相当于直接匹配"http.status_code=200"或"error=1"这2个字符串, 因此如果出现某个tag包含子串"http.status_code=200"或"error=1"的情况时,将会误判。
-
在判断行结尾时,因为是双字符查找,所以导致每行至少需要3个字符,用于判断是否结束(如果是单字符搜索,可以用'\n'判断是否结束),这里选用了下一行的startTime前的'|' 以及startTime前2个字符判断结束(所以此方法有一定取巧),当然也可用低频单字符查找来搜索匹配字符串,但速度将降低,因为单字符出现频率较高
二、初赛赛道三(服务网格控制面分治体系构建)
赛题分析
https://code.aliyun.com/middleware-contest-2020/pilotset
赛题解析 | 初赛赛道三:服务网格控制面分治体系构建_天池技术圈-阿里云天池
思路分析
1、数据处理
原本的appName 和 pilotName都是字符串,程序内部统一采用唯一的索引(int32)表示,最终输出再转换为字符串
由于需要记录每个pilot的app,且需要进行增删查操作,使用hash table记录是一个不错的选择。
但是优化过程中频繁涉及到随机选择(查找),hash table效率低下。
最终的方案是将数据堆砌在一起(便于随机选取),并为其构造一个索引表(便于增删查)
2、初始化
随机初始化
随机为每一个app选择pilot
贪心算法
首先将app按 sidecarNum/SrvNode排序,然后按顺序选择局部最优的pilot
两种初始化方法差异不大
3、优化
不管是贪心算法还是随机初始化,解的质量都是比较差的
注意点: 每一轮只能对本次新增的app随意移动,如果要移动之前的app,要保证原pilot加载的数据一直存在
优化算法大体上有3个,效果差异不大
这里主要介绍排行榜最终得分的算法
核心思想,随机选择pilot和app,进行迭代迁移
首先将pilot按 sidecarNum/SrvNode排序
选择时pilot保证sidecarNum SrvNode 不均匀的pilot被选中的概率更大,
sidecarNum偏大的pilot选中SrvNode偏大的概率更大(互补)
选择app服从均匀分布,然后进行迭代迁移
模拟退火,递归枚举最优解(局部)
多线程加速
由于线上评测机器是4核,评测时间时间卡的比较严,为了充分利用cpu。
将原pilot随机划分为几个子集单独优化,再合并,再划分...
三、复赛(实现一个Serverless计算服务调度系统)
关键代码
/cpp/include/scheduler、/cpp/src/scheduler
文件夹下的代码为scheduler的实现,其余基本为本地评测相关代码
/cpp/include/config.h
配置文件,里面有详细注释这里不再赘述
/cpp/include/scheduler/container.hpp
记录容器信息(id、函数、Node),运行统计
/cpp/include/scheduler/functionInfo.hpp
函数类,记录函数的mete信息,容器,内存、cpu等信息统计。函数cpu、mem更新,调用统计(压力,周期性探测),周期性回收,创建
/cpp/include/scheduler/node.hpp
Node类,记录地址,端口,内存、cpu等信息统计。Node上的容器创建,回收。函数信息探测
/cpp/include/scheduler/resourceManager.hpp
资源管理类,Node的创建,回收。容器选择,创建,回收,后台优化(迁移,回收,预创)
/cpp/include/scheduler/server.hpp
apiserver->scheduler入口
AcquireContainer位置: /cpp/include/scheduler/server.hpp 53行
ReturnContainer位置: /cpp/include/scheduler/server.hpp 140行
赛题分析
赛题背景( 首届云原生编程挑战赛【复赛】实现一个 Serverless 计算服务调度系统_程序设计大赛_赛题与数据_天池大赛-阿里云天池的赛题与数据 )
Serverless 计算服务(如阿里云函数计算)让用户无需管理服务器等基础设施,只需编写并上传代码,服务会准备好计算资源,并以弹性、可靠的方式运行用户代码。服务根据代码实际执行时间收费,让使用者无需为闲置资源付费,其背后是服务采用各种调度策略降低请求的响应时间,并且使用尽可能少的资源。
传统的应用通常根据某些指标来扩展所需要的计算资源,比如根据CPU,内存等硬件资源的使用情况,或者根据延迟,队列积压等业务指标。而一些云厂商提供的函数即服务(FaaS)如阿里云函数计算,AWS Lambda采用了一种基于请求的调度方式,根据当前系统的资源所能够支撑的并发请求数和实际请求数作为主要依据调度资源。本题目是关于设计和实现一个函数计算服务的调度系统,为函数调用请求高效的管理计算资源,不限制使用何种方式作为调度的依据。
赛题特点:
-
函数类型多样,CPU紧密型,内存紧密型,周期请求型
-
评测过程短(20min),函数周期短(秒级),执行时间短(微秒级-秒级)
-
分配Node耗时极短
1288 1301 1303 1333 1461 1477 1484 1488 1503 1516 1525 1541 1541 1562 1604 1610 1626 1741 2222 2243 2527 平均时间在1614μs左右 -
创建容器时间较⻓,且同一Node并⾏创建容器明显性能下降
445176μs - 4997857μs
最快可以在几百毫秒,如果Node负载过高,创建容器时间甚至需要好几秒 -
创建、迁移容器成本太⾼,有的函数创建⼀个容器的时间远⼤于函数所有调⽤时间之和, 总响应时间基本取决于首次创建容器的时间
-
成本需同时考虑响应时间和资源使用量,即要求请求能够被及时处理,又使用较少的资源
优化方向:
-
冷启动优化
由于无法提前知道函数信息,同一函数前几次请求必然无法提前准备容器,必然会有冷启动 -
容器选择优化
尽量做到负载均衡,充分利用CPU、MEM,提高响应速度 -
资源优化
尽量使用更少的Node
具体优化点:
- 创建容器耗时太长,应尽量在请求到来之前,准备好容器,减少冷启动次数。
- 冷启动时避免在同⼀Node同时创建容器,保证Node创建容器任务均衡。
- 创建、迁移容器成本太⾼,应该尽量在创建容器的时候就保持资源均衡。
- 评测过程短,函数周期短,执⾏时间短,在请求到来时容器的选择上做到负载均衡
- 容器尽量分散,sleep型和CPU紧密型函数保持均衡, CPU使⽤量和MEM使⽤量保持均衡
- 同⼀函数Node之间并⾏数量尽量分配均衡。
- 尽量并行,充分利⽤CPU资源,特别是后⾯增加了⼀种模型内存常驻的函数,并行就显得更为重要,并行可以减少模型加载次数,减少内存浪费,从⽽使⽤更少的资源
核心思路
-
容器的创建
-
请求到来时容器的选择
具体思路
程序流程
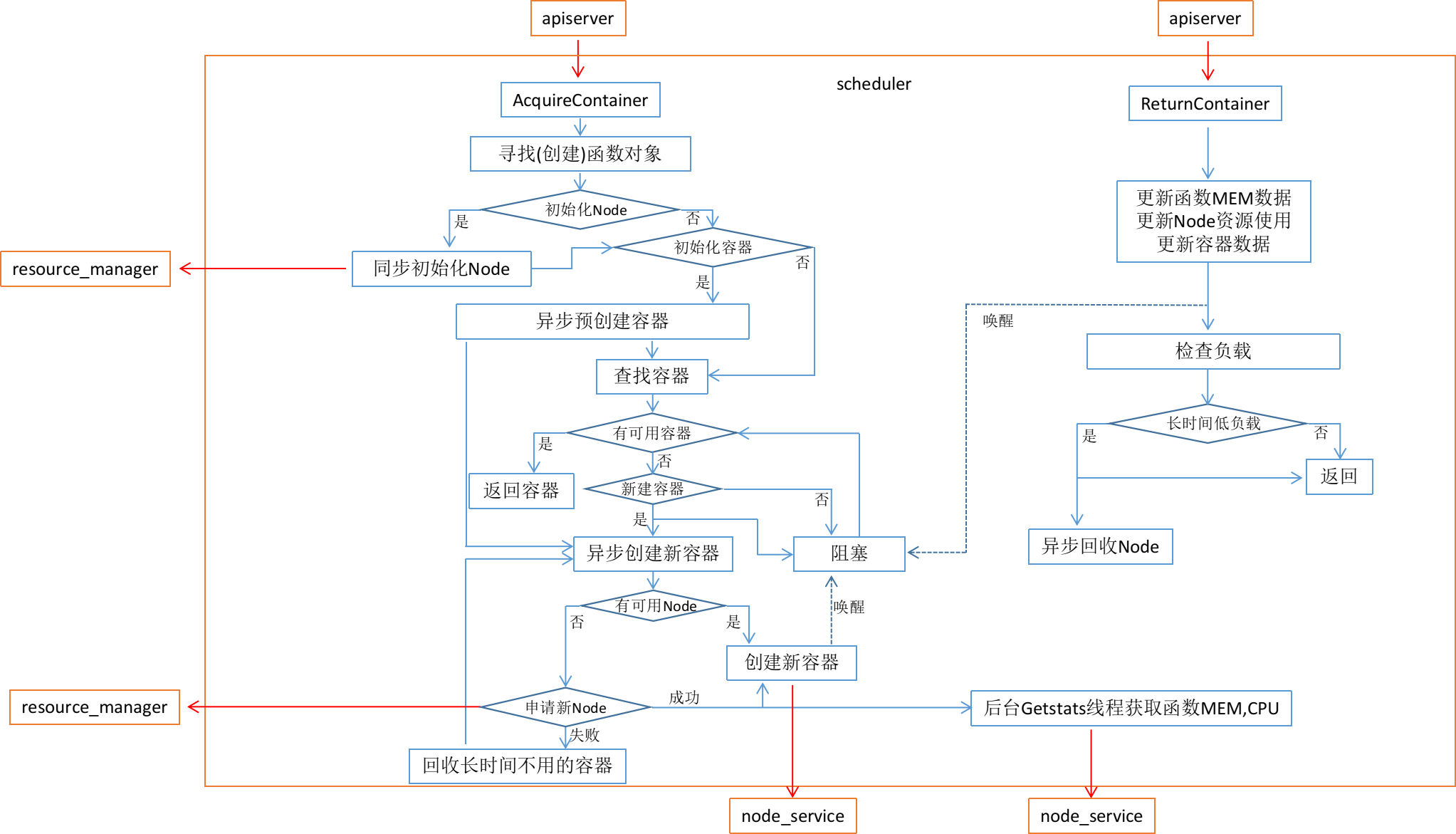
说明:
-
在第⼀个请求到来的时候会同步进⾏Node的初始化,预分配几个Node,后⾯会根据压力自动扩展
-
每个Node申请后,会后台启动GetStats线程探测函数信息,当超过一段时间没有新函数出现时,暂停探测
-
在某函数第⼀个请求到来的时候会异步进行容器的初始化,预创建几个容器,然后会根据压力再分配,当获取到某个函数的统计信息后,会对⼩内存容器进⼀步预分配,后面会根据压⼒再分配。
-
当创建容器时,如果没有可用Node,会申请新的Node,如果没有可申请的Node, 则回收长时间不使用的容器,创建完成后,唤醒正在等待容器的请求。创建容器时,尽量选择负载低的Node
-
当整体负载长时间过低时,后台回收Node(及其上⾯创建的容器)
-
最开始做了后台容器优化(预分配、迁移、回收),后台Node回收,由于迁移代价巨大,所以尽量在创建、选择容器时保持均衡,不再进行后台优化
-
周期请求型函数处理,由于周期请求型函数周期太小,最开始加了周期性回收、预创建,由于回收创建成本太高,效果明显不好,故周期请求型函数不做特殊处理
-
选择容器的原则,首先内存必须充⾜,并⾏数量少,Node上sleep型和CPU紧密型函数比例保持均衡,Node上 CPU使⽤量和MEM使⽤量比例保持均衡( scheduler会在本地记录、更新各个Node的CPU、MEM、并⾏数量等使用详情)。
健壮性分析
冷启动的处理
程序会通过预创建容器,尽量减少冷启动的次数
OOM的处理
程序会严格计算、记录资源,控制Node内存并预留一定空间,一般不会出现OOM。
假设由于GetStats误差出现OOM,或出现其它错误,会移除出错的容器,防止后续调用失败
大压力请求或超多函数的情景
对于大压力请求或超多函数的情况下,不会轻易崩溃。
程序支持自动扩容资源,支持回收长时间不用的容器,支持回收Node释放资源。
即使资源不足,程序也不会返回错误。如果资源不足且没有资源可回收时,则阻塞该请求到有足够资源运行,或该函数其它请求调用完毕(但是超时时间过短,可能会出现调用超时,但是这在资源不足的情况下也是无法避免)
比赛经验总结和感想
感谢举办方提供这样一个机会和平台,特别是复赛,应该动用了不少的机器评测。
无论是初赛还是复赛,我觉得都是比较有趣的,特别是赛道一。这次比赛我学到了很多,比如socket编程、http协议、grpc、proto、docker相关知识,sse指令优化,同时也认识了一些朋友,对阿里云的技术以及云原生有了更加深刻的认识和了解
查看更多内容,欢迎访问天池技术圈官方地址:首届云原生编程挑战赛总决赛冠军比赛攻略_greydog.队_天池技术圈-阿里云天池















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









