






项目整体流程图
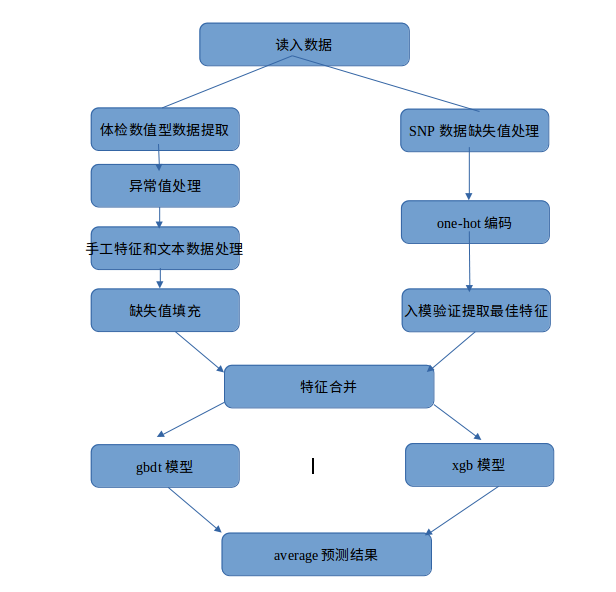
解题思路及详细步骤
比赛概述:
美年健康AI大赛是利用体检数据预测本人的血压血脂等指标,复赛中加入了基因数据,由于体检项目众多,每个人体检项目有限,导致了数据很大的缺失值率. 此外对于文本,医生体检项目表达不一,所以面临的是半结构化文本和一些掺杂的数据结构,也加大了数据处理的难度.最后由于体检项目是脱敏的,所以很难根据现有知识进行数据组合发现新特征.
对于基因数据,总计384个点位,one-hot编码后有1200多列,这么高的维度直接添加进特征会造成严重过拟合.因此我们需要进行细致的特征筛选.
针对数据的情况我们整体思路如下:
1去掉缺失值率非常高的特征,复赛总计3047条训练数据,全部数据为5077条,体检数据的总纬度达到1600多纬,但是但部分缺失值率非常高,我们过滤掉非空值数量低于40的特征.
2 对于夹杂有字符的数值列进行正则表达式提取数值,对夹杂有阴性阳性的数值型特征,阴性按照0替换,阳性采用肉眼观察法按照较大值进行填充
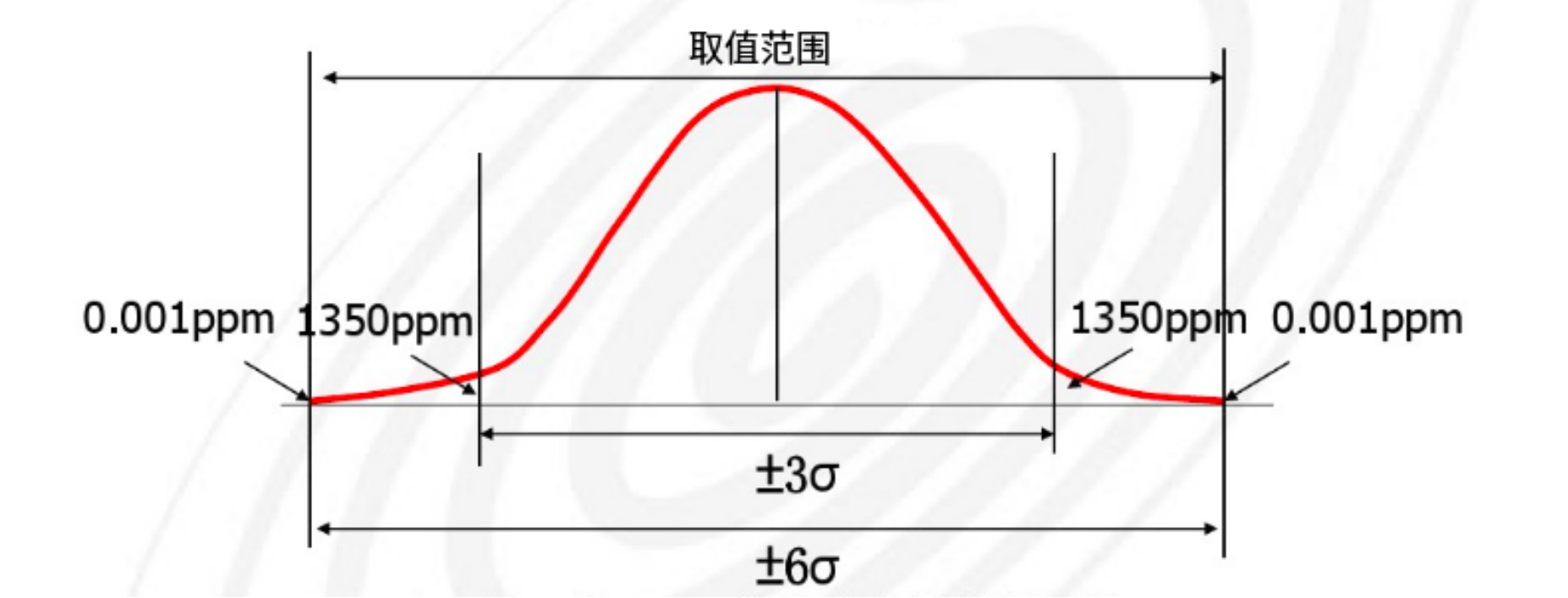
3针对数值型数据进行异常值处理: 按照6sigma原则,超过 平均值+6sigma 的数据按照平均值+6sigma 平滑替换,低于 平均值-6sigma的值按照 平均值-6sigma替换
4处理文本型特征,首先利用器官提取性别重要特征,其次利用老年病如骨质疏松判断是否中老年,利用提取关键词判断语义的方式进行文本特征处理.对于有严重程度区别的特征进行按照严重程度映射为数值型分级,这样不仅可以降低纬度,由于减少了稀疏性更有利于模型学习.最后对文本进行one-hot编码.
5缺失值,根据模型重要性反馈,重要性前30名并且缺失值在30%以上的进行预测填充,其余利用性别和年龄信息group之后进行均值填充
6 snp数据one-hot 编码之后维度非常高,1300维左右.因此必须进行特征过滤.我们首先用秩和检验和T检验的方法去除一些显著性非常低的列,以满足平台table不允许超过1200列的要求.然后通过入模筛选的方式,选取重要性高的列即可.
1 导入数据
导入系统数据,并将两部分训练集合并为X_train;
此处对y_train进行log1p变换(其中,舒张压低于40按照异常值处理替换为40,同理hdl低于0.3按照0.3处理,高于4按照4处理),
2 SNP数据处理
2.1 缺失值填充
对于snp缺失值,我们我们认为是包含了一定特性在里面导致其不易被检测到.所以所有缺失值单独编码进行处理,按照null填充.
2.2 显著性检验
2.2.1甘油和高密度脂蛋白秩和检验
甘油和高密度脂蛋白,分布属于非正态分布,我们采取秩和检验,找到一些显著性不明显的点位,用于one-hot编码之前过滤
2.2.2 舒张压,收缩压和低密度脂蛋白T检验
舒张压,收缩压和低密度脂蛋白,分布属于正态分布,我们采取T检验,找到一些显著性不明显的点位,用于one-hot编码之前过滤
2.3 特征筛选
我们假设,血压和血脂只与少部分点位有关,因此我们需要用一定方法筛选出这些重要的点位.
由于T检验与秩和检验只能判断单点位的显著性,并不能发现特征组合的,所以我们采用入模验证的方法来过滤特征(后期根据模型表现有微调),
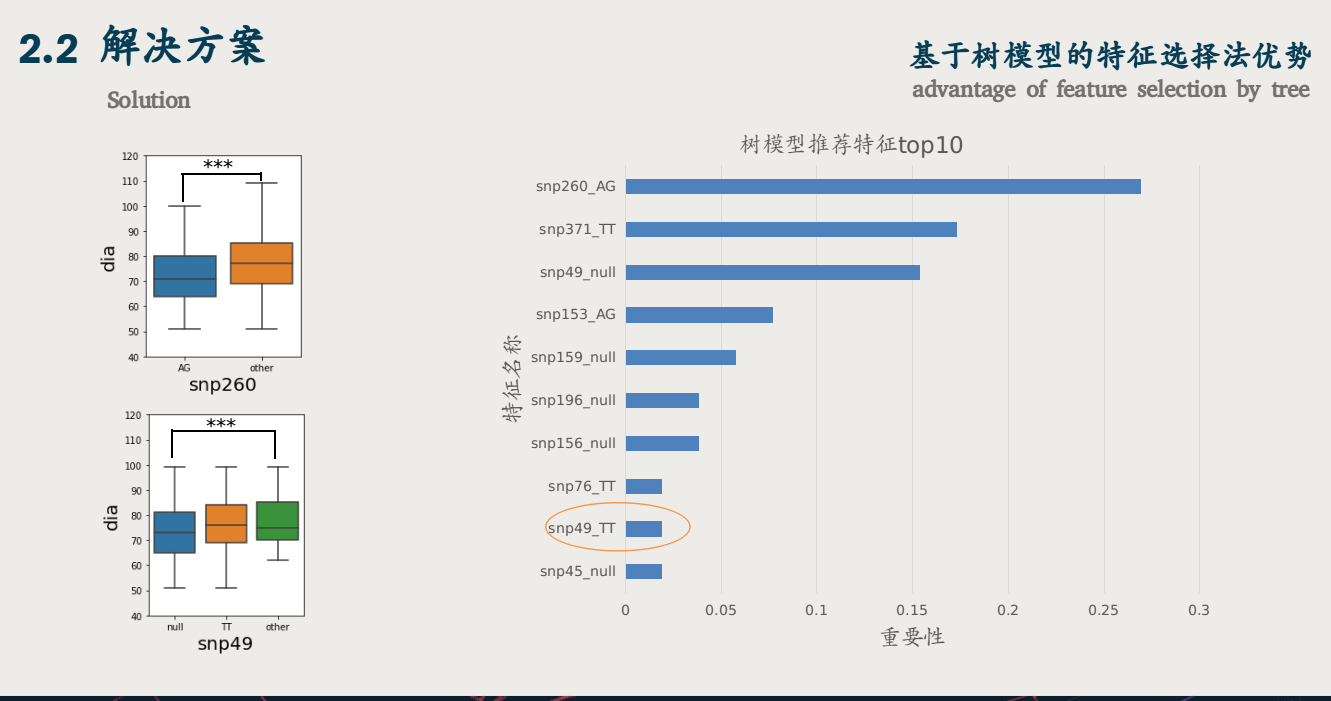
我们知道人的血压舒张压平均值在78左右,我们用显著性检验会得到snp260AG是显著的,snp49null是显著的,但是我们的树模型特征选择却返回了除了snp260ag和snp49null外 还提供了snp49TT的特征,从右图 我们就可以看到树模型特征选择的优势,由于树模型采用的是节点分裂的方式进行预测,所以天然就具备选取最佳组合的能力
3 体检数据处理
3.1 数值型数据提取
数值型数据大约分为3类,
1 纯数字列:如2403,2404并不需要处理,直接用于特征即可
2 需要提取的数值的列,如1308的视力.采用正则表达式进行提取
3 含有阴性阳性的数值列.如:300005. 此处需要肉眼观察,赋予阳性阴性一个合理的值
3.2 异常值处理
数值特征非常多,采用绘图方法来查看异常值是非常费时费力的,机器学习中只要不是极端异常值对结果影响并没有那么大,所以我们简单按照6sigma原则,超过 平均值+6sigma 的数据按照平均值+6sigma 平滑替换,低于 平均值-6sigma的值按照 平均值-6sigma 替换,效果不错.
3 手工特征及文本型特征处理
3.3.1 手工特征
根据器官信息,提取性别特征
根据老年病提取年龄信息
3.3.2 文本型特征处理
由于体检报告中是半结构化文本,所以通过提取关键词的方式来判断器官是否正常是简单可行的.我们通过观察报告内容判断体检报告中是否有相应的词语出现即可断定某器官是否正常.
对于有严重程度之分的文本特征我们将其映射为数值型特征来反应其严重程度.
丢弃一些所有都是正常或不正常例子非常少的文本特征.
体检数据特征筛选总结:

3.4 缺失值填充
根据模型重要性反馈,重要性前30名并且缺失值在30%以上的进行预测填充,其余利用性别和年龄信息group之后进行均值填充.
缺失值预测填充的理论基础是特征之间并不是完全独立,这种情况在体检数据中非常明显,那么我们利用其他特征来预测当前特征,我们的原则是对于高重要性的特征,存在与之相关系数大于0.3的特征,并且非空值>800,我们就对其进行预测填充,预测填充的优势非常明显,将重要性不高的特征转化为好的特征,实际效果明显优于均值填充.过拟合方面我们除了通过限制模型参数和降维外,我们还采用average两个模型的方式降低过拟合程度,提高泛化性能.
最后是各个方法提升性能的总结

4 训练并预测
4.1 合并数据,创建最终训练集和测试集
合并体检数据和入模筛选的基因数据,生成各个指标自己的训练集和测试集,
gbdt中通过pai的join组件实现. xgb通过sql代码实现
4.2 gbdt模型训练并预测
第一层Join组件实现训练集上体检数据和入模筛选的基因特征组合.
第二层join组件实现测试集进行与训练集同样的特征组合.
GDBT回归组件对各个指标的数据集合进行训练
预测组件对各个指标进行预测
最后再用join组件将各个指标的预测结果连接.
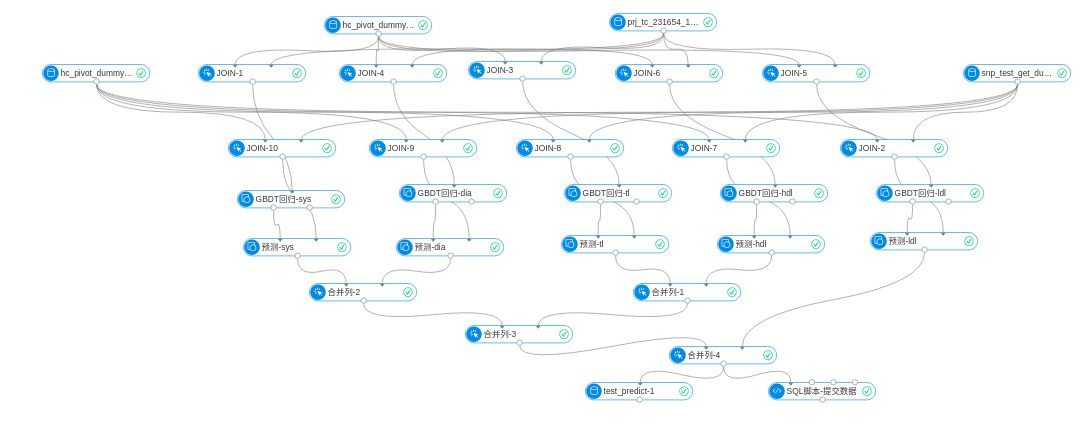
4.3 xgb模型训练并预测
xgb模型是通过pai代码实现,所用的特征与gbdt相同,即体检数据和入模筛选特征的组合.此处我们对单个指标进行单个建模和调参以达到最好的效果.最后将各个预测结果合并为最终结果.
4.4 average预测结果
将xgb预测结果与gbdt预测结果取平均值作为最终提交结果,
4.5模型调优
通过调整入模筛选的参数,调整选取snp数据的特征
通过交叉验证的方式舍弃了体检数据中一些无关的特征,调整了各个模型的参数.
以上就是我们的思路,希望能对大家有所帮助,希望能一起讨论,共同学习进步.
查看更多内容,欢迎访问天池技术圈官方地址:美年健康AI算法大赛--季军解决方案_天池技术圈-阿里云天池















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









