






注解的基本概念
注解即元数据,元数据是用来描述数据的数据,更通俗一点的说法就是描述代码之间的关系或者代码与其他资源之间内在联系的数据。对于Struts来说struts-config.xml文件,对于hibernate来说指的是hbm.xml映射文件,但是现有的xml活其他方式存在的元数据文件都有一些不便之处,第一·与被描述的文件分离,不利于一致性的维护,第二,所有这样的文件都是ASSII文件,没有显示的类型支持。
基于元数据的广泛应用,从javaSE5开始,java引入注解的概念(Annotation)的概念来描述元数据,为我们提供了一种在代码中添加信息的方法,使用我们可以再稍后某个时刻非常方便的使用这些信息。因此注解也被称为元数据。Annotation在一定程度上把信息和源代码文件结合在一起,这些信息在编译,类加载,运行时被读取,并执行相应的处理。
Annotation是一个接口,程序运行时可以利用反射获取指定程序元素的Annotation对象,然后通过Annotation对象来获取注解里面的信息,Annotation可以向修饰符一样被使用,可以修饰包,类型,构造方法,方法,成员变量,参数,本地变量,参数,本地变量等。被Annitation修饰的程序元素可以关联相关信息,这些信息本存储在Annotation的“name=value”(名-值)结构对中,可以方便我们稍后使用。这里存在着一个基本规则:
Annotation不能影响程序代码的正常执行,无论增加,删除Annotation,代码都始终如一执行。
注解提供提供用来完整的描述程序所需的信息,而这些信息是无法用java来表达的,因此我们可以利用注解实现以下功能:
.编写文档:通过代码里标识的元数据生成文档,常用的有@param,@return等;
。代码分析:通过代码标识的元数据对代码进行分析获取信息,或生成描述文件,甚至或是新的类定义
。编译检查:通过代码里的标识的元数据让编译器能实现基本的编译检查。
如果需要对注解中的信息进行访问和处理,我们需要利用反射API来构造自定的注解处理器来获取注解中的信息。如果需要利用注解在编译阶段生成描述文件,甚至或是新的类的定义,就需要用这届处理工具APT(Annotation Processing Tool)来实现。
注解的使用:
注解的使用比较简单,在要使用的注解名前加上@符号,并把该注解当成一个修饰符使用,用于修饰符支持的程序元素,如下
public class User {
@Test public static void test (){
}
}
用@Test注解的test方法与其他方法没有区别,只是表示提供了一个额外信息。在这个例子中,注解@Test可以与任何修饰符共同作用于方法,例如public、final、static等。从语法角度看,注解的使用方式几乎与修饰符的使用一模一样。编译器并没有规定注解与其他修饰符的位置顺序,可以随意搭配,但是通常我们习惯把注解放在其他修饰符最前面。有时候由于使用注解时可能还需要为其信息变量指定值,因而注解的长度可能较长,所以通常把注解另放一行:
public class User {
@Test
public static void test (){
}
}
没有限制的情况下,注解可以用于修饰任何元素,包括类,接口,方法,字段等,而且多个不同注解可以修饰同一个程序元素,但是相同的注解不能修饰同一个程序元素:
public class User {
@Test//不能有两个@Test注解修饰该方法
@Test1
@Test2
}
编译器允许程序猿对同一个目标同时使用多个注解,使用多个注解时,同一个注解不能重复使用
没有限制的情况下,注解可以用于修饰任何元素,包括类,接口,方法,字段等,而且多个不同注解可以修饰同一个程序元素,但是相同的注解不能修饰同一个程序元素:
内置三种注解:@Override
在Java中内置了三个常见的注解,这三个基本注解都定义在java.lang包下:
@Override,表示当前的方法定义将覆盖超类中的方法。如果你不小心拼写错误,或者方法签名对不上被覆盖的方法,编译器就会发出错误。注意,@Override注解只能用于作用于方法,不能用于作用于其它程序元素。
package com.cry;
public class Human {
public void Say() {
}
}
class Student extends Human {
@Override //标红报错,Error:(9, 5) java: 方法不会覆盖或实现超类型的方法
public void Say(int a) {
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
@Override告诉编译器检查这个方法是否满足重写规则,如果满足编译通过,否则编译报错。
@Deprecated,用于表示某个程序元素(类,方法等)已经过时,编译器将不鼓励使用这个被标注的程序元素。当其他程序使用过时的是程序元素时,编译器会发出警告信息。
这种修饰具有一定的 “延续性”:如果我们在代码中通过继承或者覆盖的方式使用了这个过时的类型或者成员,虽然继承或者覆盖后的类型或者成员并不是被声明为@Deprecated,但编译器仍然要报警。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
编译器发出的警告信息: Warning:(10, 22) java: com.cry.Human中的Say()已过时
@SuppressWarnings,关闭编译器的警告信息。
在java5.0,sun提供的javac编译器为我们提供了-Xlint选项来使编译器对合法的程序代码提出警告,此种警告从某种程度上代表了程序错误。例如当我们使用一个泛型类而又没有提供它的类型时,编译器将提示出unchecked warning的警告。通常当这种情况发生时,我们就需要查找引起警告的代码。如果它真的表示错误,我们就需要纠正它。例如如果警告信息表明我们代码中的switch语句没有覆盖所有可能的case,那么我们就应增加一个默认的case来避免这种警告。
有时我们无法避免这种警告,例如,我们使用必须和非泛型的旧代码交互的泛型集合类时,我们不能避免这个unchecked warning。此时@SuppressWarning就要派上用场了,在调用的方法前增加@SuppressWarnings修饰,告诉编译器停止对此方法的警告。被@SuppressWarnings修饰的程序元素(以及在程序元素中的所有子元素)将取消显示指定的编译器警告。
通常情况下,如果程序中使用没有泛型限制的集合将会引起编译器警告:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
编译器警告信息:
Information:java: D:\DevelopSoftWare\IdeaProjects\src\com\cry\Human.java使用了未经检查或不安全的操作。
Information:java: 有关详细信息, 请使用 -Xlint:unchecked 重新编译。
- 1
- 2
为了避免这种编译器警告,可以使用@SuppressWarnings注解,下面程序取消了没有使用泛型的编译器警告:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
当我们使用@SuppressWarnings注解来关闭编译器警告时,一定要在插号里使用name=value对来为该注解的中的元素设置值,unchecked字段常被用于抑制未检测的警告,也就是-Xlint后的警告名unchecked。SuppressWarnings中的元素value是一个数组类型,所以我们可以用大括号来声明数组值,表示抑制多个警告,如:@SuppressWarnings({ "rawtypes", "unchecked" })(因为元素名是value所以可以省略,后面会讲到)。
SuppressWarnings注解的常见参数值的简单说明:
1. all:所有情况的警告。
2. unchecked:执行了未检查的转换时的警告,例如当使用集合时没有用泛型 (Generics) 来指定集合保存的类型;
3. fallthrough:当 Switch 程序块直接通往下一种情况而没有 Break 时的警告;
4. path:在类路径、源文件路径等中有不存在的路径时的警告;
5. serial:当在可序列化的类上缺少 serialVersionUID 定义时的警告;
6. finally:任何 finally 子句不能正常完成时的警告;
7. unused:变量未被使用的警告;
8. deprecation:使用了不赞成使用的类或方法时的警告;
……还有很多。
注解的定义
注解的定义与接口的定义很像,用@interface来定义一个注解(关键字interface前面多加了一个@符号)。与其他任何java接口一样,注解也将会编译成class文件。下面定义了一个简单的注解:
- 1
- 2
- 3
- 4
- 5
除了@符号以外,@Test的定义很像一个空接口。定义注解时,还需要一些元注解(meta-annotation),就如上面的@Target和@Retention。@Target用来定义你的注解将应用用于什么程序元素(类、字段、方法),如上面表示该注解只能修饰方法。@Retention用来定义需要在什么阶段(源代码、类文件、运行时)保存该注解信息,如上面表示在运行阶段该注解信息还存在。
当然不使用元注解修饰也不会出现任何问题,比如没有@Target修饰,那么该注解默认就可以修饰任何程序元素。如果没有@Retention修饰,注解信息默认只保留到class文件中,运行时是获取不到注解信息的。
注意,注解不能支持继承,不能使用关键字extends来继承某个@interface。
注解元素
我们可以在注解体中定义元素(相当于注解信息)用于表示某些值。当分析处理注解时,程序或工具就可以利用这些值了:
- 1
- 2
- 3
- 4
- 5
- 6
上面注解中定义两个元素id和description。注解的元素的定义与接口中的方法定义几乎一样,但是注解中的元素必须是以无参的方法来定义。我们还可以使用关键字default,指定该元素的默认值。description元素就有一个默认值”no description”,如果在注解某个方法时没有给出description的值,就会使用此元素的默认值。
下面的类中,有两个方法被注解修饰:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注解的元素在使用时表现为name-value(名-值)对的形式,必须要置于@Test声明之后的括号内。在test2方法中的注解,并没有给出description元素的值,因此使用的是默认值。注意,使用注解时必须要为其所有元素进行赋值,除非其中某个元素有设置默认值。
注解元素并不什么类型都可以,可用的类型如下所示:
- 所以基本类型(int,float,boolean等)
- String
- Class
- enum
- Annotation(注解类型也可以作为元素类型)
- 以上类型的数组
如果你使用了其他类型,那么编译器就会报错。注意,注解是不能使用除了上面以外的普通类(Object)作为元素的类型,这也包括任何包装类型。而且注解也可以作为元素的类型,也就是说注解可以嵌套。
我们把没有元素的注解称为标记注解(market annotation)
默认值限制
注解中的元素不能有不确定的值。也就是说,元素必须要么具有默认值,要么在使用注解时提供元素的值。
对于非基本类型的元素,无论在源代码中声明时,或是在注解接口中定义默认值时,都不能以null为值。这个约束使得处理器很难表现一个元素的存在或缺失的状态,因为在每个注解的声明中,所有的元素存在,并且都具有相应的值。为了绕开这个约束,我们只能定义一些特殊的值,例如空字符串或负数,以此表示某个元素不存在:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在定义注解的时候,这算得上是一个习惯用法。
value元素
如果注解中的元素以value来命名,并且在应用该注解的时候,如果该元素是唯一需要赋值的一个元素,那么此时无需使用名-值对的这种语法,而只需要在括号内给出value元素所需的值即可。这可以应用于任何合法类型的元素。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
下面会自动为vaule值自动赋值为10。
- 1
- 2
- 3
- 4
- 5
- 6
注意:如果description元素没有默认值,也就是说该注解必须为两个元素进行赋值,那么就不能以自定赋值的方式为元素vlaue进行赋值,而必须以名-值对的方式:
- 1
- 2
- 3
- 4
元注解
java除了在java.lang下提供了3个基本的注解之外,还在java.lang.annotation包下提供了四个元注解(meta-annotation)。元注解专职负责注解其他的注解。元注解也是注解类型,也就是说注解可以注解其他注解。
@Target
表示该注解可以用于修饰哪些程序元素。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
@Target注解中有一个枚举类型元素value,ElementType参数包括:
- ANNOTATION_TYPE:指定该注解只能修饰注解,就如
@Target元注解只能用于修饰其他注解 - CONSTRUCTOR:修饰构造器。
- FIELD:修饰成员变量(包括enum实例)
- LOCAL_VARIABLE:修饰局部变量
- METHOD:修饰方法声明
- PACKAGE:修饰包声明
- PARAMETER:修饰参数声明
- TYPE :修饰类、接口(包括注解类型)、enum声明。
没有@Target修饰的注解,可以用于修饰任何程序元素。
@Retention
表示该注解可以保留多长时间。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
@Target注解中有一个枚举类型元素value,RetentionPolicy 参数包括:
- SOURCE:注解在编译成class文件后直接丢弃,注解只存在于Java源码中。
- CLASS:注解在class文件中可用,当运行java程序时,JVM将注解丢弃。
- RUNTIME:注解在class文件中可用,JVM将在运行期也保留注解,因此可以通过反射机制读取注解的信息。
没有@Retention修饰的注解,默认使用的是CLASS方式。
@Documented
表示该注解将被javadoc工具提取成文档。如果定义注解类时使用了@Documented修饰,则所有使用该注解修饰的程序元素API文档中将会包含该Annotation说明。
- 1
- 2
- 3
- 4
- 5
定义一个@Documented修饰的注解:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
用该注解修饰test1方法:
- 1
- 2
- 3
- 4
- 5
使用javadoc工具为User .java ,User 文件生成api文档后如下面所示
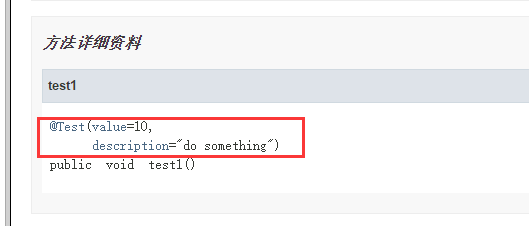
如果没有@Documented修饰将不会生成如上的注解信息。
@Inherited
允许子类继承父类的注解。如果某个类使用了注解,那么其子类将自动具有该注解。
- 1
- 2
- 3
- 4
- 5
下面使用@Inherited元注解定义了一个Annotation,该Annotation将具有继承性:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
下面程序定义了一个User基类,该基类使用了@Test修饰,则User类的子类将自动具有@Test注解:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
程序输出为true,如果没有@Inherited修饰注解Test,那么将会输出false。
嵌套注解
注解元素类型允许存在注解类型,从而实现注解嵌套的功能。我们定义如下两个注解Extra和Student,然后在Student注解中使用Extra注解:
Extra注解:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Student注解:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们在Student注解中定义了一个other元素,它是Extra注解类型。other元素的默认值是@Extra,由于在@Extra注解类型之后,没有在括号中指明@Extra元素的值,因此,other元素的默认值实际上就是一个所有元素都为默认值的@Extra注解。如果要令嵌入的@Extra注解中的指定元素赋值,并以此作为other元素的默认值,则需要如下定义该元素:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们用Student注解来注解如下字段:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在上面的字段中除了student4以外都使用了嵌入的@Extra注解的默认值,而student4因为情况特殊我们就可以为其嵌套注解@Extra中指定额外的信息。
注解处理器
大多时候,程序猿主要是自己定义自己的注解,并编写自己的注解处理器来处理他们。如果没有用来读取注解的工具,那么注解也不会比注释更有用,使用注解的过程中,很重要的一部分是创建和使用自己的注解处理器。java扩展了反射机制API一帮助程序猿构造这类工具。同时,它还提供了一个外部工具apt帮助程序员解析带有注解的java源代码。
这里我们定义的注解都默认继承自Anonation接口(java.lang.annotation),Annotation接口所有注解都默认继承自Annotation接口(java.lang.annotation包下),Annotation接口是多有注解类型的父接口。反射中Class、Method、Constructor、Field、Package等类都继承了AnnotatedElement接口(java.lang.reflect 包下),AnnotatedElement接口中提供了四个方法来获取相关程序元素的注解:
| 方法 | 说明 |
|---|---|
| T getAnnotation(Class annotationClass) | 返回改程序元素上存在的、指定类型的注解,如果该类型注解不存在,则返回null。 |
| Annotation[] getAnnotations() | 返回该程序元素上存在的所有注解。 |
| boolean isAnnotationPresent(Class annotationClass) | 判断该程序元素上是否包含指定类型的注解,存在则返回true,否则返回false。 |
| Annotation[] getDeclaredAnnotations() | 返回直接存在于此元素上的所有注解。与此接口中的其他方法不同,该方法将忽略继承的注解。(如果没有注解直接存在于此元素上,则返回长度为零的一个数组。)该方法的调用者可以随意修改返回的数组;这不会对其他调用者返回的数组产生任何影响。 |
下面使用反射机制,打印出一个类中方法的所有注解信息。
首先定义一个运行时可用的注解:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在User类中的方法上使用这些注解:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
利用反射机制,输出注解的元素:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
上面的例子只是为了纯粹展示API的使用。
总结
注解时真正语言级的概念。她提供了一种结构化,并且具有类型检查能力的途径,从而使程序猿能够真正为代码加入元数据,而不会导致代码杂乱且难以阅读。使用注解能够帮助我们避免累赘的部署描述文件,以及其他文件的生成。而通过扩展的API或者外部的字节码工具类库,程序猿拥有对源代码以及字节码强大的检查和操作能力。
转自:http://blog.csdn.net/mcryeasy/article/details/52452341
















 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









