







目录
python下载与安装
Index of python-local
这里面下载的版本,应该是32位的python,不能用于cuda
查看安装的python版本

python cuda环境搭建
cuda toolkit官方下载
CUDA Toolkit 11.7 Downloads | NVIDIA Developer
11.6下载
CUDA Toolkit 11.6 Downloads | NVIDIA Developer
windows cuda安装指南
Installation Guide Windows :: CUDA Toolkit Documentation
python默认安装路径
C:\Users\lingan\AppData\Local\Programs\Python\Python39
pip等路径
C:\Users\lingan\AppData\Local\Programs\Python\Python39\Scripts
创建虚拟环境
C:\Users\lingan\AppData\Local\Programs\Python\Python39\python -m venv Venv_code39x64
cuda运行样例
NvvmSupportError: libNVVM cannot be found. Do conda install cudatoolkit: library nvvm not found问题解决
在环境变量中添加
NUMBAPRO_NVVM = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\nvvm\bin\nvvm64_40_0.dll
NUMBAPRO_LIBDEVICE = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\nvvm\libdevice\
E:\Datasync\Studying\002GPU_CUDA\001 Packt.Hands-On.GPU.Computing.with.Python.1789341078.pdf
Tesla GPUs can immensely contribute to simulations and largescale calculations (especially floating-point calculations—this is where double precision can be a huge advantage).
Tesla and Quadro GPUs have higher double-precision power when compared to consumer-level GeForce GPUs.
GPU结构
https://www.likecs.com/show-204370950.html
全局内存(Global memory),位于片外存储体中。容量大、访问延迟高、传输速度较慢。在2.X计算力之后的GPU上,都会使用二级缓存(L2 cache)做缓冲,达到较快的传输速度,但这并不能减少访问的延迟(Latency)。
本地内存(Local memory),一般位于片内存储体中,在核函数编写不恰当的情况下会部分位于片外存储器中。当一个线程执行核函数时,核函数的变量、数组、结构体等都存放在本地内存(Local memory)中。
共享内存(Shared memory)位于每个流处理器组中(SM)中,其访问速度仅次于寄存器,特点是一个线程块(Block)中的所有线程都可以访问。主要存放频繁修改的变量。
寄存器内存(Register memory)位于每个流处理器组中(SM)中,访问速度最快的存储体,用于存放线程执行时所需要的变量。
常量内存(Constant memory)位于每个流处理器(SM)中和片外的RAM存储器中。常量内存是只读的,不能在核函数执行的过程中被修改。但是可以在核函数执行前,通过重新传入数据进行修改。
纹理内存(Texture memory)位于每个流处理器(SM)中和片外的RAM存储器中。它与常量内存非常类似。但是他有两点不同:
-
- 纹理内存,顾名思义就是专门用于纹理贴图操作的,故在该操作上使用纹理内存更加高效。
- 纹理内存具有广播机制。
GPU 内存的分级综述(gpu memory hierarchy)_Jerry_ICCAS的博客-CSDN博客
①寄存器内存(Register memory)
优点:访问速度的冠军!
缺点:数量有限
使用:在__global__函数 ,或者___device__ 函数内,定义的普通变量,就是寄存器变量。
②共享内存(Shared memory)
优点:
1缓存速度快 比全局内存 快2两个数量级
2 线程块内,所有线程可以读写。
3 生命周期与线程块同步
缺点:大小有限制
使用:关键词 __shared__ 如 __shared__ double A[128];
③全局内存 (Global Memory)
优点:
1空间最大(GB级别)
2.可以通过cudaMemcpy 等与Host端,进行交互。
3.生命周期比Kernel函数长
4.所有线程都能访问
缺点:访存最慢
scikit-cuda
basic
Reference — scikit-cuda 0.5.2 documentation
Pycuda
比较底层,没有fft的直接支持,需要自己写。
CuPy
Installation — CuPy 10.5.0 documentation
| v11.6 | $ pip install cupy-cuda116 |
Basics of CuPy — CuPy 10.5.0 documentation
Basics of CuPy — CuPy 10.5.0 documentation
cupy.asarray() can be used to move a numpy.ndarray, a list, or any object that can be passed to numpy.array() to the current device:
>>> x_cpu = np.array([1, 2, 3])
>>> x_gpu = cp.asarray(x_cpu) # move the data to the current device.
cupy.asarray() can accept cupy.ndarray, which means we can transfer the array between devices with this function.
>>> with cp.cuda.Device(0):
... x_gpu_0 = cp.ndarray([1, 2, 3]) # create an array in GPU 0
>>> with cp.cuda.Device(1):
... x_gpu_1 = cp.asarray(x_gpu_0) # move the array to GPU 1
cupy.asarray() does not copy the input array if possible. So, if you put an array of the current device, it returns the input object itself.
If we do copy the array in this situation, you can use cupy.array() with copy=True. Actually cupy.asarray() is equivalent to cupy.array(arr, dtype, copy=False).
Move array from a device to the host
Moving a device array to the host can be done by cupy.asnumpy() as follows:
>>> x_gpu = cp.array([1, 2, 3]) # create an array in the current device
>>> x_cpu = cp.asnumpy(x_gpu) # move the array to the host.
We can also use cupy.ndarray.get():
>>> x_cpu = x_gpu.get()
## AMD Ryzen 9 5900X 12-core对比GTX GPU 1066
# CPU运算时只用了4个CPU线程,耗时CPU time:1.8002000331878663
# GPU time:0.05439991950988769 GPU time:0.052400064468383786
# 提速34.6倍
## AMD Ryzen 9 5900X 12-core对比GTX GPU 1066
# CPU运算时只用了4个CPU线程,耗时CPU time:1.8002000331878663
# GPU time:0.05439991950988769 GPU time:0.052400064468383786
# 提速34.6倍
#float32单精度浮点:符号位,8 位指数,23 位尾数, 4Byte
#float64双精度浮点:符号位,11 位指数,52 位尾数, 8Byte
#complex64复数,由两个 32 位浮点表示(实部和虚部), 8Byte
#complex128复数,由两个 64 位浮点表示(实部和虚部), 16Byte
#对于np.complex64 100,000,000的数据占用内存763MB; 1e8*8/1024/1024=762.9MB,符合计算。
#对于64GBaud 25倍上采样, 2^16个数据点,采用complex128存储,(1/64e9*2**16)/(1/((64*25)*1e9))*16/1024/1024=25Mb
N_point = 100000000
N_mean = 10
##
import numpy as np
import time
from scipy.fft import fft
print("Start processing TEST")
a = np.random.random(N_point).astype(np.complex64)
start_cpu = time.time()
# print(str(start_cpu))
for k in range(N_mean):
a = fft(a,norm='ortho') # equivalent to cufft.fft(a)
print(a[0:4])
end_cpu = time.time()
# print(str(end_cpu))
time_gpu = (end_cpu - start_cpu)/N_mean
print("CPU time:"+str(time_gpu))
##
#https://docs.cupy.dev/en/stable/user_guide/fft.html
# Since SciPy v1.4 a backend mechanism is provided so that users
# can register different FFT backends and use SciPy’s API to perform
# the actual transform with the target backend, such as CuPy’s
# cupyx.scipy.fft module. For a one-time only usage, a context
# manager scipy.fft.set_backend() can be used:
import cupy as cp
import cupyx.scipy.fft as cufft
import scipy.fft
import time
print("Start processing TEST1")
a = cp.random.random(N_point).astype(cp.complex64)
start_gpu = time.time()
# print(str(start_gpu))
with scipy.fft.set_backend(cufft):
for k in range(N_mean):
a = scipy.fft.fft(a,norm='ortho') # equivalent to cufft.fft(a)
print(a[0:4])
end_gpu = time.time()
# print(str(end_gpu))
time_gpu = (end_gpu - start_gpu)/N_mean
print("GPU time:"+str(time_gpu))
##
import time
import cupy as cp
import cupyx.scipy.fft as cufft
import scipy.fft
scipy.fft.set_global_backend(cufft)
print("Start processing TEST2")
a1 = cp.random.random(N_point).astype(cp.complex64)
start_gpu1 = time.time()
for k in range(N_mean):
a1 = scipy.fft.fft(a1,norm='ortho') # equivalent to cufft.fft(a)
print(a1[0:4])
end_gpu1 = time.time()
time_gpu1 = (end_gpu1 - start_gpu1)/N_mean
print("GPU time:"+str(time_gpu1))
不再更新,合并到cupy中。
cuFFT :: CUDA Toolkit Documentation
二次方的整数倍是最快的,算法速度为nlogn,可以计算双精度
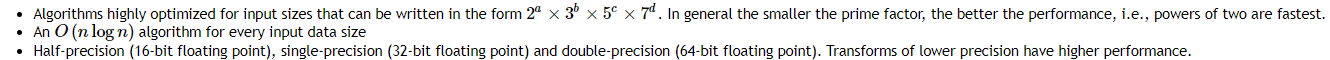
The cuFFT Library provides GPU-accelerated FFT implementations that perform up to 10X faster than CPU-only alternatives.
fft速度大概是几十倍的提升?还是十几倍的提升?
The cuFFT Device Extensions (cuFFTDx) library enables you to perform Fast Fourier Transform (FFT) calculations inside your CUDA kernel. Fusing FFT with other operations can decrease the latency and improve the performance of your application.
NVIDIA cuFFTDx — cuFFTDx 1.0.0 documentation
numba
Numba documentation — Numba 0.55.2+0.g2298ad618.dirty-py3.7-linux-x86_64.egg documentation
比较底层,没有fft的直接支持,需要自己用python语言编写基本的操作。
# %%
import time
import math
from numba import cuda, float32
import numpy as np
# %%
def matmul_cpu(A,B,C):
for y in range(B.shape[1]):
for x in range(A.shape[0]):
tmp = 0
for k in range(A.shape[1]):
tmp += A[x,k]*B[k,y]
C[x,y] = tmp
# %% [markdown]
# 第二步,实现CUDA核函数
# %%
@cuda.jit
def matmul_gpu(A,B,C):
row,col = cuda.grid(2)
if row < C.shape[0] and col < C.shape[1]:
tmp = 0.
for k in range(A.shape[1]):
tmp += A[row,k]*B[k,col]
C[row,col] = tmp
# %% [markdown]
# 第三步,利用SM中的Shared memory来优化核函数
# %%
TPB = 16
@cuda.jit
def matmul_shared_mem(A,B,C):
sA = cuda.shared.array(shape=(TPB,TPB), dtype=float32)
sB = cuda.shared.array(shape=(TPB,TPB), dtype=float32)
x,y = cuda.grid(2)
tx = cuda.threadIdx.x
ty = cuda.threadIdx.y
if x>=C.shape[0] or y >= C.shape[1]:
return
tmp = 0.
for i in range(int(A.shape[1]/TPB)):
sA[tx, ty] = A[x, ty+i*TPB]
sB[tx, ty] = B[tx+i*TPB, y]
cuda.syncthreads()
for j in range(TPB):
tmp += sA[tx,j]*sB[j,ty]
C[x,y] = tmp
# %% [markdown]
# 第四步,定义main函数,在这部中,我们初始化A,B矩阵,并将数据传输给GPU
# %%
def main_matrix_mul():
TPB = 16
A = np.full((TPB*10,TPB*10), 3.0, np.float32)
B = np.full((TPB*10,TPB*10), 4.0, np.float32)
C_cpu = np.full((A.shape[0],B.shape[1]), 0, np.float32)
#Start in CPU
print("Start processing in CPU")
start_cpu = time.time()
matmul_cpu(A,B,C_cpu)
end_cpu = time.time()
time_cpu = (end_cpu - start_cpu)
print("CPU time: "+str(time_cpu))
#Start in GPU
A_global_mem = cuda.to_device(A)
B_global_mem = cuda.to_device(B)
C_global_mem = cuda.device_array((A.shape[0],B.shape[1]))
C_shared_mem = cuda.device_array((A.shape[0],B.shape[1]))
threadsperblock = (TPB, TPB)
blockspergrid_x = int(math.ceil(A.shape[0]/threadsperblock[0]))
blockspergrid_y = int(math.ceil(A.shape[1]/threadsperblock[1]))
blockspergrid = (blockspergrid_x,blockspergrid_y)
print("Start processing in GPU")
start_gpu = time.time()
matmul_gpu[blockspergrid, threadsperblock](A_global_mem,B_global_mem,C_global_mem)
cuda.synchronize()
end_gpu = time.time()
time_gpu = (end_gpu - start_gpu)
print("GPU time(global memory):"+str(time_gpu))
C_global_gpu = C_global_mem.copy_to_host()
print("Start processing in GPU (shared memory)")
start_gpu = time.time()
matmul_shared_mem[blockspergrid, threadsperblock](A_global_mem,B_global_mem,C_global_mem)
cuda.synchronize()
end_gpu = time.time()
time_gpu = (end_gpu - start_gpu)
print("GPU time(shared memory):"+str(time_gpu))
C_shared_gpu = C_shared_mem.copy_to_host
# %% [markdown]
# 第五步,执行main函数,对比使用不同的方法来加速矩阵乘的速度差异
# %%
if __name__=='__main__':
print(tuple.__itemsize__)
main_matrix_mul()
CuPy and Numba on the GPU – Lesson Title
GPU Acceleration in Python using CuPy and Numba | NVIDIA On-Demand
Interoperability — CuPy 10.5.0 documentation
#code from https://docs.cupy.dev/en/stable/user_guide/interoperability.html
import cupy
from numba import cuda
import numpy as np
N_point = 100000
@cuda.jit
def add(x, y, out):
start = cuda.grid(1)
stride = cuda.gridsize(1)
for i in range(start, x.shape[0], stride):
out[i] = x[i] + y[i]
a_cpu = np.random.random(N_point).astype(np.complex64)
a = cupy.asarray(a_cpu)#将host数据拷贝到device
b = a * 2
out = cupy.zeros_like(a)
print(out) #cupy数据天然在device中
add[128, 32](a, b, out)
result = out.get()#通过get()方法将device数据拷贝到host
print(result)















 3600
3600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









