





3 编程接口
3.2 CUDA运行时
cuda运行时的实现在cudart库中,通过静态链接或动态链接库的方式链接到应用程序。
3.2.4 页锁定宿主内存
cuda运行时(runtime)库提供页锁定宿主内存(相对于malloc分配的可分页内存)相关函数:
- cudaHostAlloc和cudaFreeHost分配和释放页锁定宿主内存
- cudaHostRegister页锁定malloc分配的内存
使用页锁定内存有几点好处:
- 在某些设备上,页锁定宿主内存与设备内存之间的数据拷贝操作和内核执行操作可以并发执行
- 在某些设备上,页锁定内存可以映射到设备的地址空间,从而不需要与设备内存之间进行显式的数据拷贝
- 在有前端总线的设备上,如果宿主内存为页锁定内存,宿主内存与设别内存间的带宽比较高,如果宿主内存进一步为写合并内存则带宽更高,传输效率更高。
但是页锁定内存相对于可分页内存是比较稀缺的资源,耗尽后分配可能会失败。并且,由于会降低操作系统分页的物理内存,因此分配过多的页锁定内存会降低系统整体性能。
3.2.4.1 portable内存
页锁定内存可以与系统中的任何一个设备结合使用,但默认情况下上文提到的几点好处,只有页锁定内存分配时的当前设备才能获得。为了让所有的设备都能获得使用页锁定内存的好处,调用分配函数cudaHostAlloc的时候需要指定标志cudaHostAllocPortable,调用锁定函数cudaHostRegister的时候指定标识cudaHostRegisterPortable。
3.2.4.2 写合并内存
默认情况下页锁定内存是可缓存的。可以在调用cudaHostAlloc的时候指定标志cudaHostAllocWriteCombined分配写合并内存。写合并内存节约宿主的L1和L2缓存供其他程序使用。并且在通过PCI高速总线传输数据的时候速度提升40%。
注意宿主读取写合并内存的速度很慢(因为没有缓存),因此它应该被用于宿主只写的场景下。
3.2.4.3 映射内存
调用cudaHostAlloc时传入标志cudaHostAllocMapped或调用cudaHostRegister传入cudaHostRegisterMapped ,页锁定内存可以映射到设备内存空间。这块内存将有两个个地址:由cudaHostAlloc或malloc返回一个宿主地址,由cudaHostGetDevicePointer返回一个设备地址供内核中使用。
内核中直接访问宿主内存的带宽不如访问设备内存的带宽,但是也有几点优点:
- 无需分配一块设备内存,以及在设备内存与宿主内存间拷贝数据。数据拷贝由内核按需隐式完成
- 无需使用流就可以实现数据传输与内核执行的并发,内核发起的数据传输自动的与内核执行并发
由于映射页锁定内存被宿主和设备共享,因此程序必须他通过流或则事件的机制进行内存访问的同步,避免潜在的读后写,写后读或则写后写问题。
为了获取映射页锁定内存的设备地址,必须通过调用cudaSetDeviceFlags并传入cudaDeviceMapHost标志激活页锁定内存的映射功能。否则cudaHostGetDevicePointer会返回错误。
当设备不支持映射页锁定内存功能,cudaHostGetDevicePointer也会返回错误。程序可以通过查询设备属性canMapHosttMemory来确实十分支持,此属性取值为1表示支持。
3.2.5 异步并发执行
CUDA中的下列操作为独立任务,可以并发执行:
- 宿主中的计算
- 设备中的计算
- 由宿主到设备的内存传输
- 由设备向宿主的内存传输
- 设备内部内存的传输
- 设备之间内存的传输
这些操作实际能达到的并发程度依赖设备的特征和计算能力。
3.2.5.1 宿主与设备间的并发执行
cuda的异步接口在设备完成请求的任务之前将控制返回给宿主线程,实现并发宿主执行的目的。下列的设备操作可以异步操作:
- 内核启动
- 单设备内部的内存拷贝
- 由宿主向设备小于64KB的内存拷贝
- 后缀为Async的库函数发起的内存拷贝
- 内存设置函数调用
开发者可以设置环境变量CUDA_LAUNCH_BLOCKING=1来关闭内核启动的异步操作。这个特性的目标是调试,不要在生产环境中使用。
3.2.5.2 并发内核执行
计算能力2.x以上的设备可以同时执行多个内核。程序可以通过查询设备属性concurrentKernels检查是否支持,属性值为1表示支持。
设备可同时执行的内核数量依赖当前设备的计算能力。
3.2.5.3 数据传输与内核执行的并发
一些设备支持数据传输与内核执行的并发,可以通过查询设备属性asyncEngineCount来确认。数据传输涉及的宿主内粗必须是页锁定内存。
3.2.5.4 数据传输并发
计算力2.x以上的一些设备支持并发向设备的数据拷贝和源自设备的数据拷贝。可通过设备属性asyncEngineCount来说去人是否支持。
3.2.5.5 流
程序通过流来管理以上的并发操作。一条流就是一组按顺序执行的操作的序列。不同流中的操作的执行顺序是不可预期的,可能并发执行,也可能先后执行。程序不能依赖不同流中操作的执行顺序。当操作的依赖条件都满足后将会被执行,操作的依赖可以是同一流中的前置操作,也可以是不同流中的操作。
3.2.5.5.1 流的创建于销毁
流的定义方式为创建一个流对象,并将它作为内核启动和内存拷贝的参数。下面的代码创建了两个流对象,分配了一个float数组:
cudaStream_t stream[2];
for (int i = 0; i < 2; ++i)
cudaStreamCreate(&stream[i]);
float* hostPtr;
cudaMallocHost(&hostPtr, 2 * size);
没一条流都包含以下的操作:从宿主向设备的内存拷贝,内核启动,从设备向宿主的内存拷贝
for (int i = 0; i < 2; ++i) {
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size,
size, cudaMemcpyHostToDevice, stream[i]);
MyKernel <<<100, 512, 0, stream[i]>>>
(outputDevPtr + i * size, inputDevPtr + i * size, size);
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size,
size, cudaMemcpyDeviceToHost, stream[i]);
}
流通过cudaStreamDestroy方式销毁:
for (int i = 0; i < 2; ++i)
cudaStreamDestroy(stream[i]);
本例中调用cudaStreamDestroy函数时设备仍在运行中,cudaStreamDestroy函数会立即返回,流相关的资源在设别执行完流的操作后会被自动释放。
3.2.5.5.2 默认流
未指定任何流或则指定流为零的内核启动以及宿主设备间的内存拷贝操作,将添加到默认流,他们将按顺序执行。使用编译选项–default-stream per-thread或引用头文件cuda.h和cuda_runtime.h之前定义宏CUDA_API_PER_THREAD_DEFAULT_STREAM,每个宿主线程将有自己单独的默认流。
注意:直接使用nvcc编译时无法使用#define CUDA_API_PER_THREAD_DEFAULT_STREAM 1的方式激活线程独立默认流的行为,应为nvcc自动包含了cuda_runtime.h头文件。所以需要使用–default-stream per-thread或则-DCUDA_API_PER_THREAD_DEFAULT_STREAM=1编译选项。
使用编译先选–default-stream legacy后,默认流是一条特别的流,被称为NULL流,对于宿主的每个线程每个设备只有唯一的一条默认流。NULL流比较特殊的原因在于他会导致隐式的同步。隐式同步在后面介绍。不指定任何–default-stream编译选项的,–default-stream legacy是默认选项。
3.2.5.5.3 显式同步
有很多流同步的方式。
cudaDeviceSynchronize等待所有宿主线程的所有流完成。
cudaStreamSynchronize等待指定的流完成。
cudaStreamWaitEvent参数包含一个流和一个事件,在事件完成后开始执行流中的操作。
cudaStreamQuery查询流是否完成。
3.2.5.5.4 隐式同步
下面的任何一个条件满足,则来自不同流的两个操作将不能并行执行:
- 页锁定内存分配
- 设备内存分配
- 设备内存设置
- 向同一个设备地址的内存拷贝
- NULL流的CUDA操作
3.2.5.5.5 重叠行为
两个流重叠执行的程度依赖于两个流操作的添加的顺序,以及设备是否支持数据传输与内核执行重叠、并行内核执行、并行数据传输。
3.2.5.5.6 宿主函数(回调函数)
通过cudaLaunchHostFunc开发者者可以在流中插入一个CPU函数。
下面的代码中的CPU函数MyCallback会在device-to-hostt拷贝完成后开始执行。
void CUDART_CB MyCallback(cudaStream_t stream, cudaError_t status, void *data){
printf("Inside callback %d\n", (size_t)data);
}
...
for (size_t i = 0; i < 2; ++i) {
cudaMemcpyAsync(devPtrIn[i], hostPtr[i], size, cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>(devPtrOut[i], devPtrIn[i], size);
cudaMemcpyAsync(hostPtr[i], devPtrOut[i], size, cudaMemcpyDeviceToHost, stream[i]);
cudaLaunchHostFunc(stream[i], MyCallback, (void*)i);
}
CPU函数之后添加到流中的操作将在CPU函数执行完后开始执行。
添加到流中的CPU函数不可以直接或间接的调用CUDA API,因为这样可能会造成死锁。
3.2.5.5.7 流优先级
流的相对优先级可以通过cudaStreamCreateWithPriority创建时设置。优先级的取值范围可以通过cudaDeviceGetStreamPriority函数获取。运行时高优先级流的操作优先于低优先级流的操作。
下面的代码获取当前设备优先级的取值范围,创建了最高优先级流和最低优先级流:
// get the range of stream priorities for this device
int priority_high, priority_low;
cudaDeviceGetStreamPriorityRange(&priority_low, &priority_high);
// create streams with highest and lowest available priorities
cudaStream_t st_high, st_low;
cudaStreamCreateWithPriority(&st_high, cudaStreamNonBlocking, priority_high);
cudaStreamCreateWithPriority(&st_low, cudaStreamNonBlocking, priority_low);
3.2.5.6 图
图提供了一种新的任务提交模型。图包含一系列操作,以及操作之间的依赖关系。
使用图提交任务包含三个阶段:定义,实例化和执行.
- 定义阶段,程序创建操作和依赖的描述
- 实例化阶段,校验、设置和初始化图
- 执行阶段,执行图的操作
3.2.5.6.1 图结构
一个操作构成图的一个阶段,操作间的依赖构成图的边。操作的依赖约束操作的执行顺序。
任何节点的依赖的节点完成之后开始被调度执行。
3.2.5.6.1.1 节点类型
图节点的类型可以是:
- 内核
- CPU函数
- 内存拷贝
- 内存赋值
- 空节点
- 子图:为了执行嵌套的图,如图十一
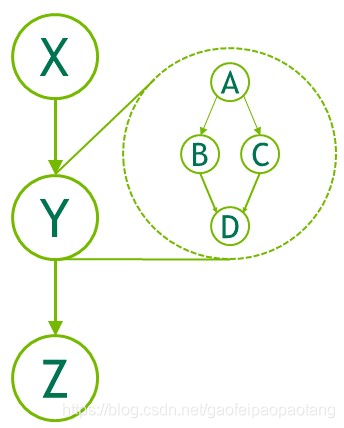
图十一:嵌套子图
3.2.5.6.2 图创建
可以有两种方式创建图:显式创建和流捕捉。下面是一个创建和执行图的例子
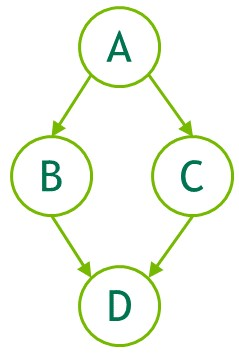
图十二:显式创建图例子
// Create the graph - it starts out empty
cudaGraphCreate(&graph, 0);
// For the purpose of this example, we'll create
// the nodes separately from the dependencies to
// demonstrate that it can be done in two stages.
// Note that dependencies can also be specified
// at node creation.
cudaGraphAddKernelNode(&a, graph, NULL, 0, &nodeParams);
cudaGraphAddKernelNode(&b, graph, NULL, 0, &nodeParams);
cudaGraphAddKernelNode(&c, graph, NULL, 0, &nodeParams);
cudaGraphAddKernelNode(&d, graph, NULL, 0, &nodeParams);
// Now set up dependencies on each node
cudaGraphAddDependencies(graph, &a, &b, 1); // A->B
cudaGraphAddDependencies(graph, &a, &c, 1); // A->C
cudaGraphAddDependencies(graph, &b, &d, 1); // B->D
cudaGraphAddDependencies(graph, &c, &d, 1); // C->D
3.2.5.6.3 流捕获创建图
流捕获机制提供了一种使用流api创建图的机制:
cudaGraph_t graph;
cudaStreamBeginCapture(stream);
kernel_A<<< ..., stream >>>(...);
kernel_B<<< ..., stream >>>(...);
libraryCall(stream);
kernel_C<<< ..., stream >>>(...);
cudaStreamEndCapture(stream, &graph);
除了NULL流之外,任何流都可以被捕捉。
3.2.5.6.3.1 跨流的依赖与事件
通过cudaEventRecord和cudaStreamWaitEvent可以处理跨流的依赖关系,下面代码创建的图结果如图十二所示:
// stream1 is the origin stream
cudaStreamBeginCapture(stream1);
kernel_A<<< ..., stream1 >>>(...);
// Fork into stream2
cudaEventRecord(event1, stream1);
cudaStreamWaitEvent(stream2, event1);
kernel_B<<< ..., stream1 >>>(...);
kernel_C<<< ..., stream2 >>>(...);
// Join stream2 back to origin stream (stream1)
cudaEventRecord(event2, stream2);
cudaStreamWaitEvent(stream1, event2);
kernel_D<<< ..., stream1 >>>(...);
// End capture in the origin stream
cudaStreamEndCapture(stream1, &graph);
// stream1 and stream2 no longer in capture mode
3.2.6 多设备系统
3.2.6.1 枚举设备
系统可能有多个设备,通过下面的方式可以枚举和查询设备的属性:
int deviceCount;
cudaGetDeviceCount(&deviceCount);
int device;
for (device = 0; device < deviceCount; ++device) {
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, device);
printf("Device %d has compute capability %d.%d.\n",
device, deviceProp.major, deviceProp.minor);
}
3.2.6.2 选择设备
宿主线程可以在任何时候调用cudaSetDevice设置当前设备。设备内存分配和内核启动都是针对当前设备的操作;流和事件也是对当前设备创建的。如果没有调用cudaSetDevice,则默认的当前设备为0。
size_t size = 1024 * sizeof(float);
cudaSetDevice(0); // Set device 0 as current
float* p0;
cudaMalloc(&p0, size); // Allocate memory on device 0
MyKernel<<<1000, 128>>>(p0); // Launch kernel on device 0
cudaSetDevice(1); // Set device 1 as current
float* p1;
cudaMalloc(&p1, size); // Allocate memory on device 1
MyKernel<<<1000, 128>>>(p1); // Launch kernel on device 1
3.2.6.3 流和事件
如果一个内核启动指定的流不是当前设备的流,则会失败:
cudaSetDevice(0); // Set device 0 as current
cudaStream_t s0;
cudaStreamCreate(&s0); // Create stream s0 on device 0
MyKernel<<<100, 64, 0, s0>>>(); // Launch kernel on device 0 in s0
cudaSetDevice(1); // Set device 1 as current
cudaStream_t s1;
cudaStreamCreate(&s1); // Create stream s1 on device 1
MyKernel<<<100, 64, 0, s1>>>(); // Launch kernel on device 1 in s1
// This kernel launch will fail:
MyKernel<<<100, 64, 0, s0>>>(); // Launch kernel on device 1 in s0
内存拷贝即使指定了非当前设备的流也会成功。
cudaEventRecord的输入为非当前设备的流或事件,则会失败。
cudaEventSynchronize和cudaEventQuery可以指定非当前设备的事件。
cudaStreamWaitEvent可以指定非当前设备的流和事件。
每个设备都有自己的默认流。不同设备默认流的操作可能会顺序或并发执行。
3.2.6.4 对等内存访问
设备可能可以直接访问其他设备的内存,取决于系统特性,特别是PCIe和NVLINK拓扑结构。cudaDeviceCanAccessPeer返回true则表示当前设备可以访问目标查询设备的内存。
对等内存访问只支持64位系统,并需要调用cudaDeviceEnablePeerAccess。
cudaSetDevice(0); // Set device 0 as current
float* p0;
size_t size = 1024 * sizeof(float);
cudaMalloc(&p0, size); // Allocate memory on device 0
MyKernel<<<1000, 128>>>(p0); // Launch kernel on device 0
cudaSetDevice(1); // Set device 1 as current
cudaDeviceEnablePeerAccess(0, 0); // Enable peer-to-peer access
// with device 0
// Launch kernel on device 1
// This kernel launch can access memory on device 0 at address p0
MyKernel<<<1000, 128>>>(p0);
3.2.6.1 对等内存拷贝
不同设备的内存可以执行拷贝操作:
cudaSetDevice(0); // Set device 0 as current
float* p0;
size_t size = 1024 * sizeof(float);
cudaMalloc(&p0, size); // Allocate memory on device 0
cudaSetDevice(1); // Set device 1 as current
float* p1;
cudaMalloc(&p1, size); // Allocate memory on device 1
cudaSetDevice(0); // Set device 0 as current
MyKernel<<<1000, 128>>>(p0); // Launch kernel on device 0
cudaSetDevice(1); // Set device 1 as current
cudaMemcpyPeer(p1, 1, p0, 0, size); // Copy p0 to p1
MyKernel<<<1000, 128>>>(p1); // Launch kernel on device 1
3.2.7 统一虚拟地址空间
当程序为64位进程,设备计算能力为2.0及以上,宿主和设备将使用统一的虚拟地址空间。所有通过cuda api分配的宿主内存和设备内存在统一的虚拟内存空间中,导致:
- 内存的位置可以通过内存指针的值判断,通过调用cudaPointerGetAttributes
- 内存拷贝类的API中,内存类型参数可以设置为cudaMemcpyDefault.
- cudaHostAlloc分配的内存可以直接在内核中使用
3.2.8 进程间通信
宿主线程创建的设备内存指针或则事件句柄,可以被同一进程的其他任何线程引用,但不能直接被其他进程的线程引用。
为了在进程间共享设备内存指针和事件句柄,必须调用跨进程API。跨进程API只支持64位Linux和计算能力2.0以上的GPU设备。注意跨进程API不支持cudaMallocManaged分配的内存。
通过跨进程API,进程调用cudaIpcGetMemHanlle获取设备内存指针的IPC句柄,然后通过标准的跨进程通信机制(比如跨进程共享内存或文件)将句柄传给另一个进程。另一个进程拿到句柄后调用cudaIpcOpenMemHandle获取句柄对应的设备内存地址。事件句柄的共享方式类似。
举一个调用跨进程API的例子:主进程生成一批输入数据,然后把地址传给若干子进程处理,可以避免了数据的重复生成和拷贝。
通过CUDA跨进程通信的进程必须编译和链接相同的CUDA驱动和运行时。
注意:CUDA跨进程API不支持Tegra设备

















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









