






 本文介绍了一种基于C3D-LSTM的模型,用于评估动作质量,通过合并多个动作的样本以提高性能。作者验证了行为质量的共性假设,并提供了开源代码实现,包括数据加载、预处理、模型训练和测试流程,以保证实验的可重复性。
本文介绍了一种基于C3D-LSTM的模型,用于评估动作质量,通过合并多个动作的样本以提高性能。作者验证了行为质量的共性假设,并提供了开源代码实现,包括数据加载、预处理、模型训练和测试流程,以保证实验的可重复性。
论文内容简介
本文作者主要验证两个问题:
学会衡量一个行为的质量是否有助于衡量其他行为的质量?
来自多个操作的合并样本是否有助于改进当前方法的性能?
作者提出的模型:C3D-LSTM
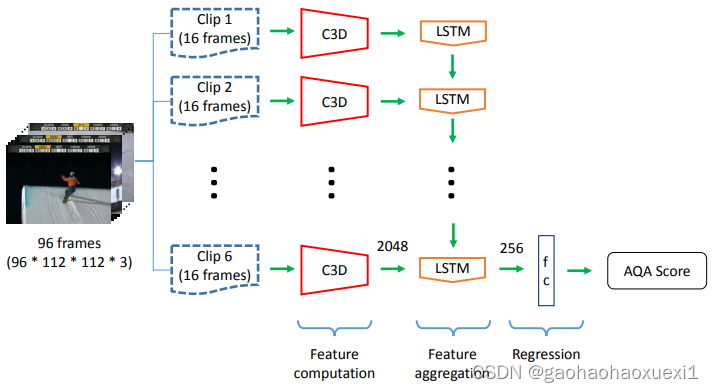
动作质量高度依赖于动作本身,但作者假设行动具有共性,虽然存在个体差异,但共性仍是可以被利用的,为验证假设是否正确,作者提出C3D-LSTM网络框架,如上图所示,这个网络包含了一个较小版本的C3D网络,后面是一个256维的LSTM层和一个全连接层,输出最终的相对质量评分分数。视频以16帧的片段进行处理,以生成连接到LSTM层进行时序特征聚合的C3D特征,其中使用欧几里得距离作为损失函数进行最小化,用于衡量预测分数与真实分数之间的差异。在训练过程中,C3D网络保持冻结状态,因此只有LSTM和最终的fc层参数被调整。这项工作的主要区别在于,与为每个动作构建独立模型(作者将其称为动作特定或单一动作模型)不同,该方法通过使用来自所有/多个动作的样本进行训练,学习一个单一模型(我们将其称为全动作或多动作模型)。
论文代码介绍
这篇论文开源了代码。网站如下GitHub - ParitoshParmar/C3D-LSTM--PyTorch: C3D-LSTM implementation in PyTorch [WACV 2019]

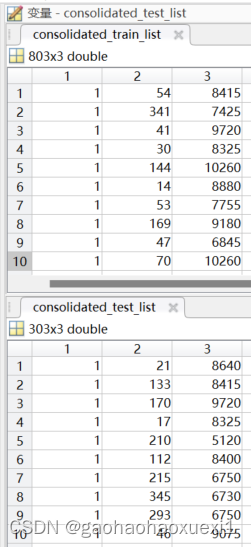
input文件:包含consolidated_test_list.mat和consolidated_train_list.mat两个文件,是训练集和测试集的注释文件,后面加载数据要用到。
models文件:包含C3D和LSTM_anno两个python脚本
data_loader.py文件:用于处理视频数据的PyTorch数据集类

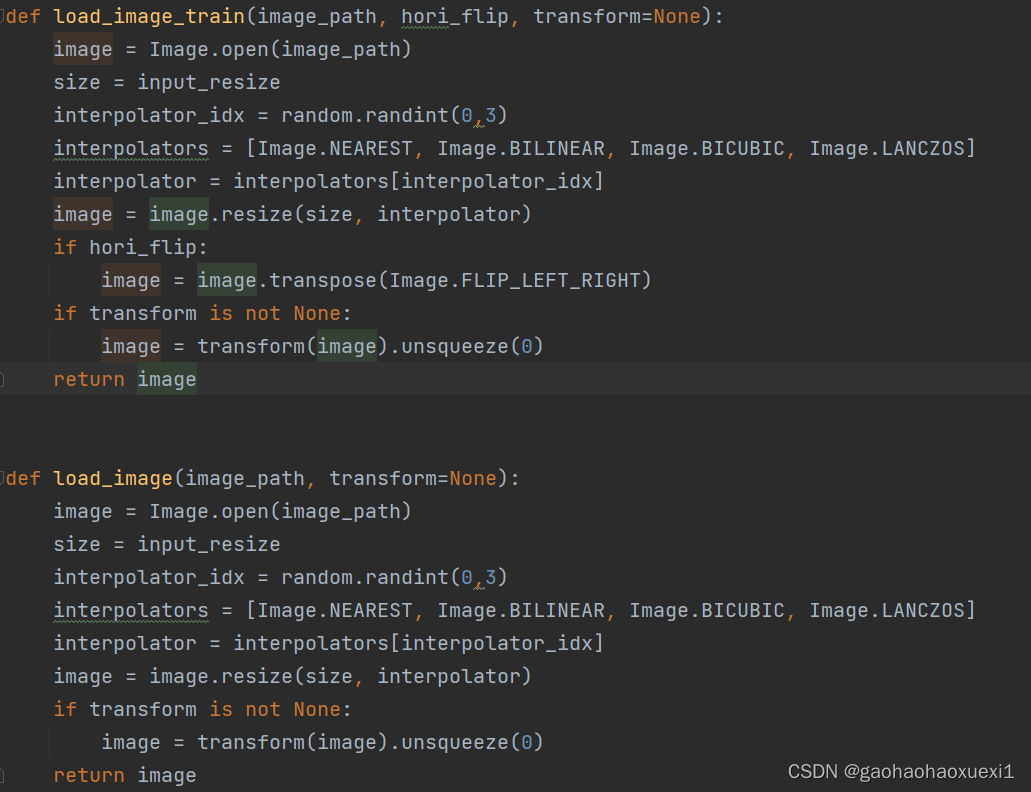
图像加载函数
这两个函数用于加载图像。load_image_train用于训练阶段,可以进行水平翻转(hori_flip)。load_image用于测试阶段。使用PIL库打开图像,进行一些预处理(例如调整大小和规范化),并返回一个包含图像的张量。
VideoDataset类用于处理视频数据集
__init__初始化方法,用于设置数据集的模式(训练或测试)和加载相应的注释数据。如果模式是 'train',则加载训练集注释,否则加载测试集注释。

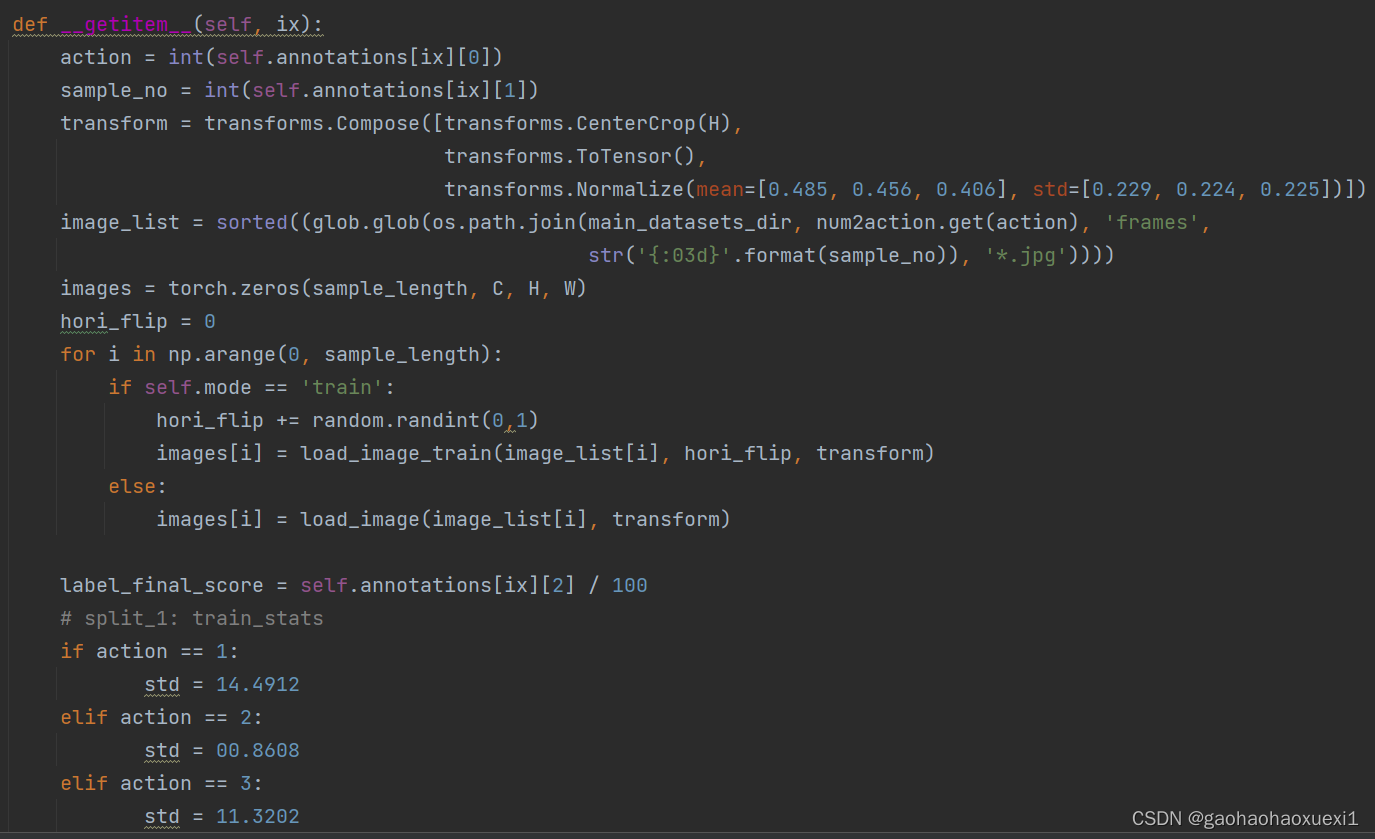
__getitem__方法:用于获取数据集中特定索引 ix 处的样本。它首先获取 action 和sample_no,然后加载图像列表,并使用前面定义的 load_image_train 和 load_image 函数加载图像。最后,标准化标签并返回包含图像、标签和动作信息的数据字典。
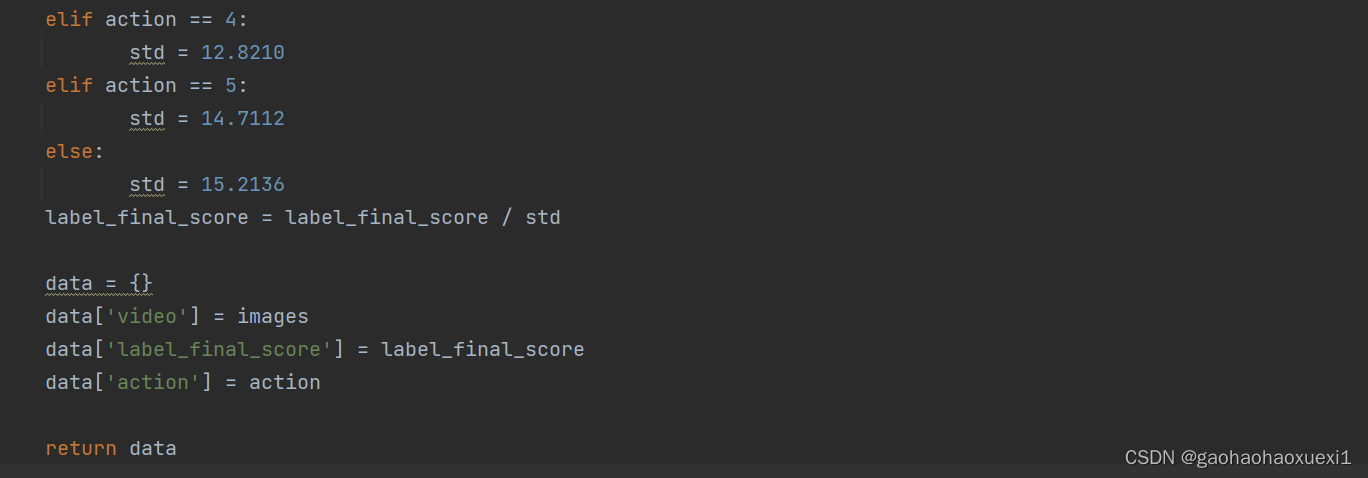
__len__:返回数据长度

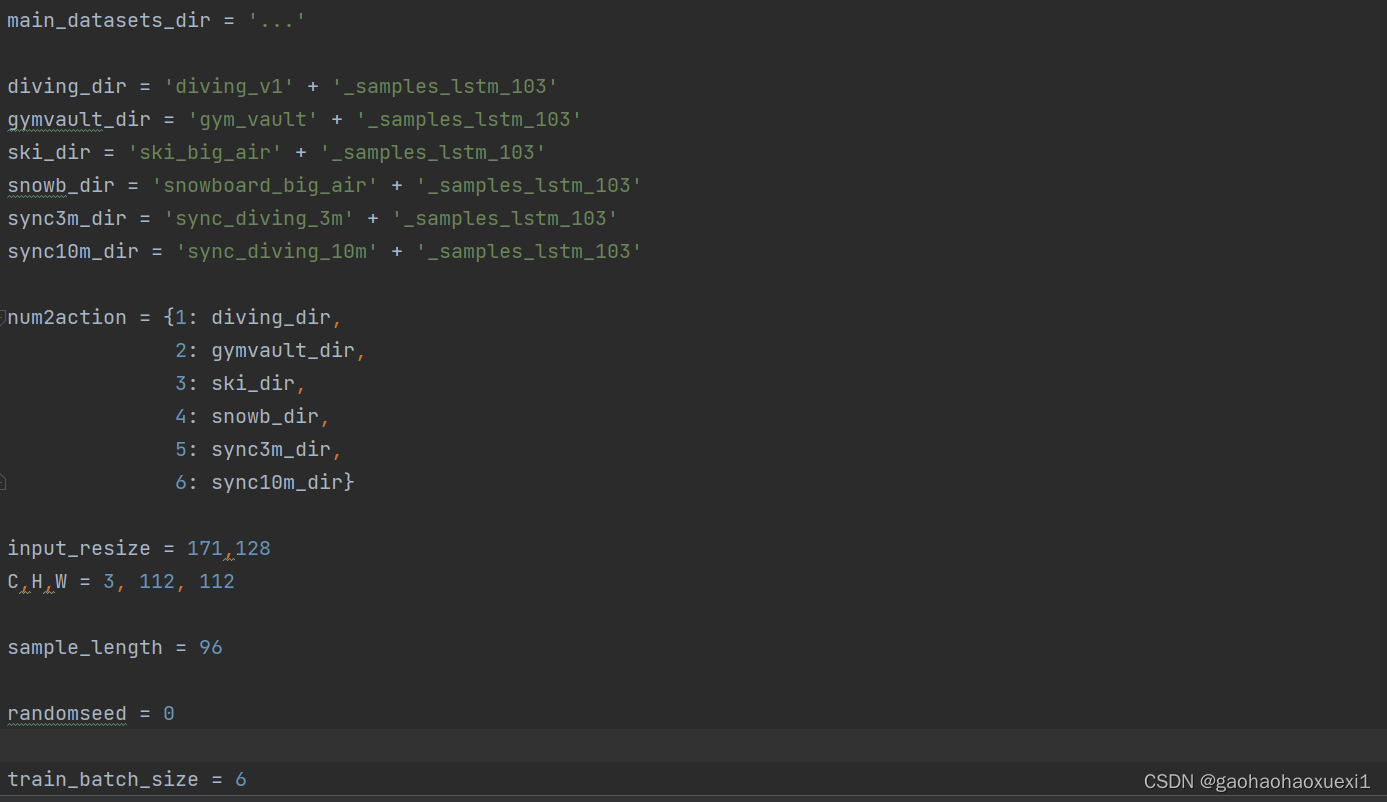
opts.py文件:主要是一些参数设置和数据集加载,配置数据集处理和训练过程

train_c3d_lstm.py文件:模型训练和测试

模型保存函数

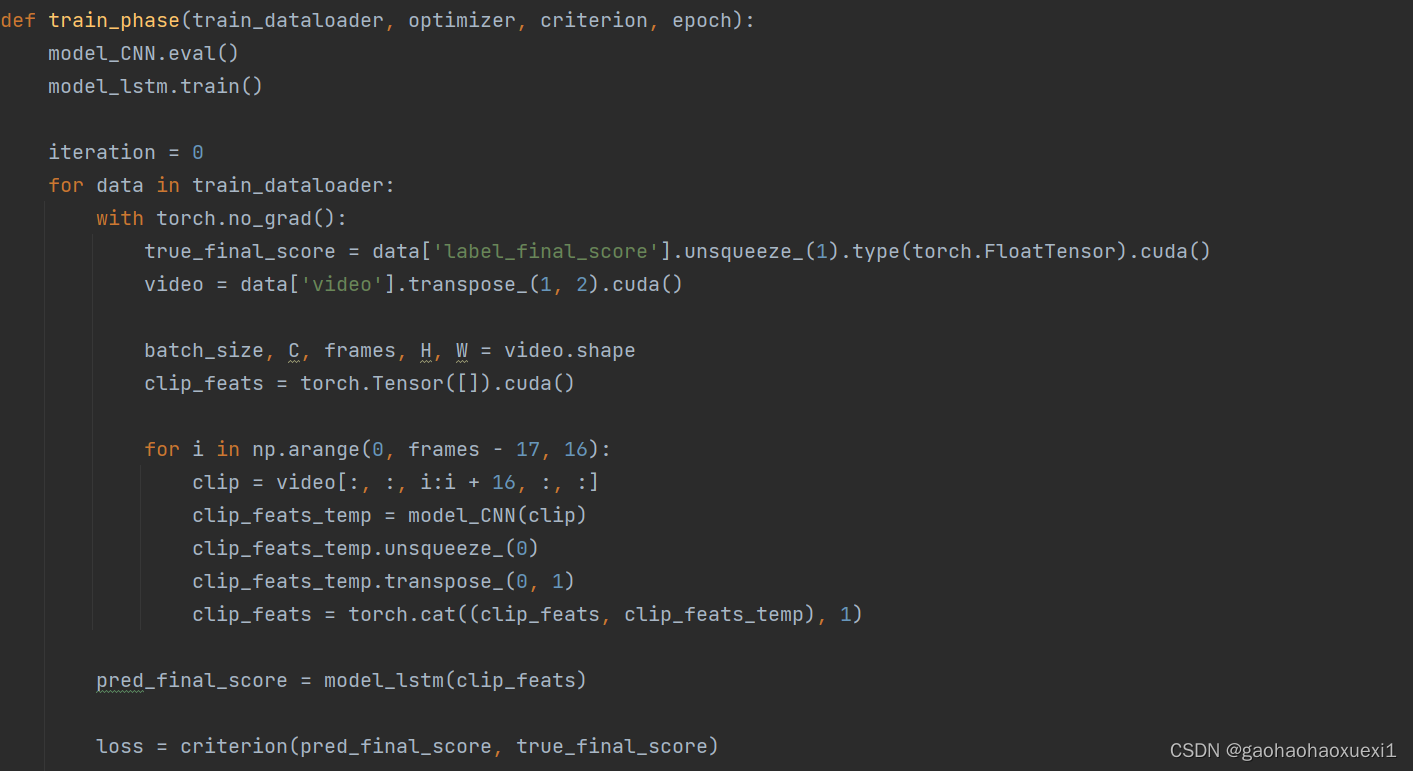
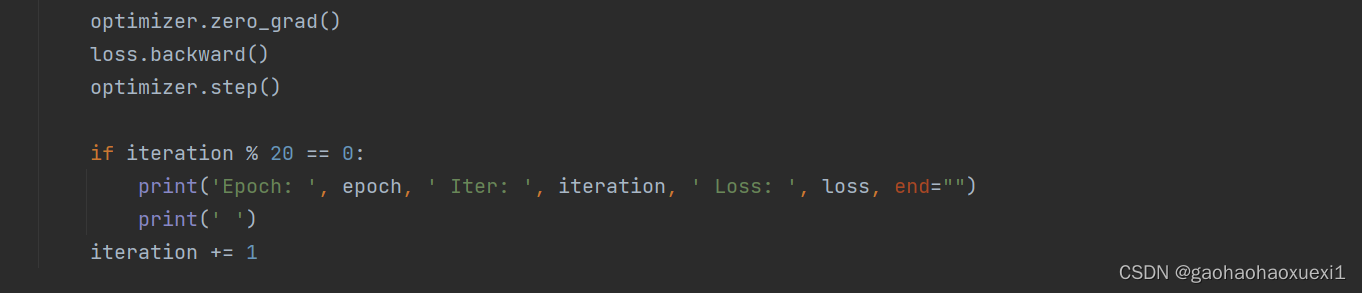
训练阶段函数,对训练数据进行迭代,计算并优化模型损失
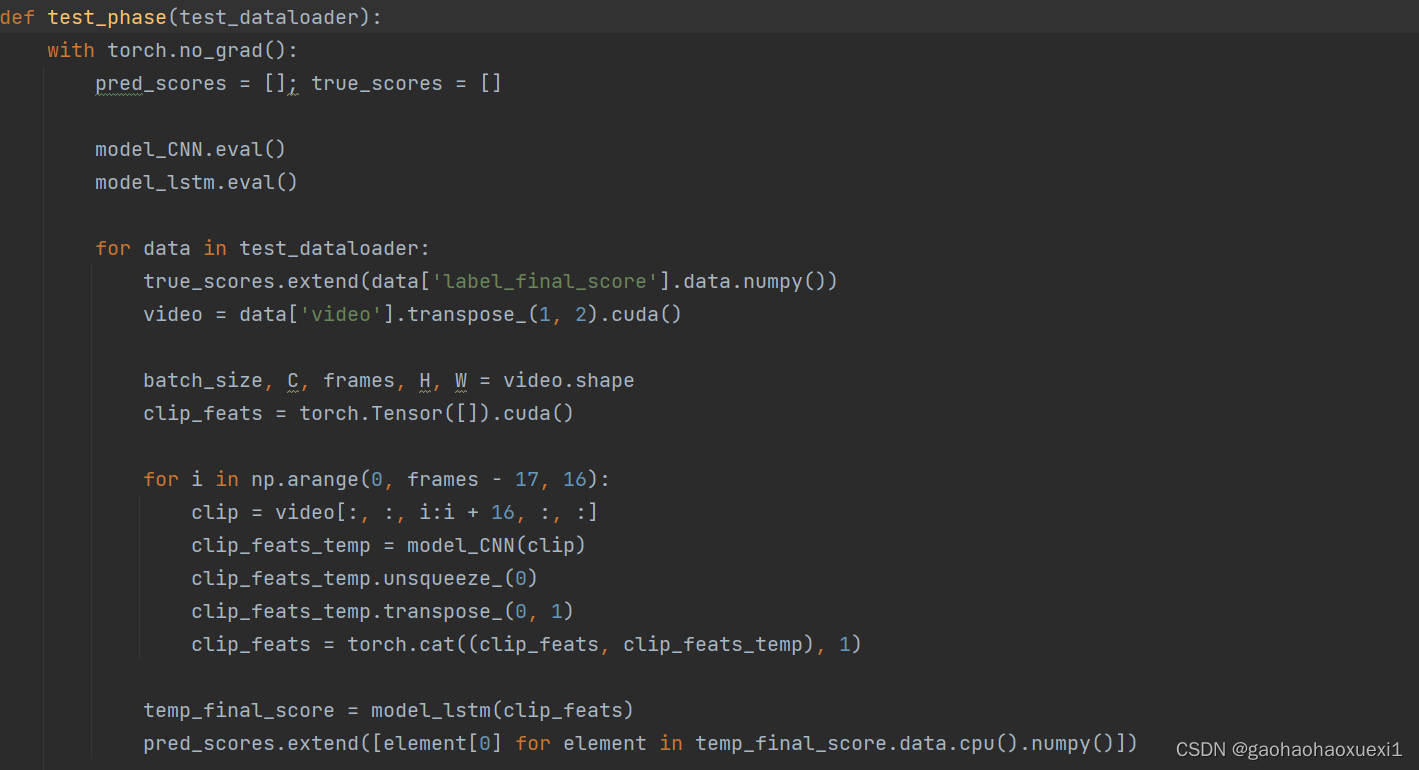
测试阶段函数,对测试数据进行迭代,计算模型的预测分数并输出相关性。

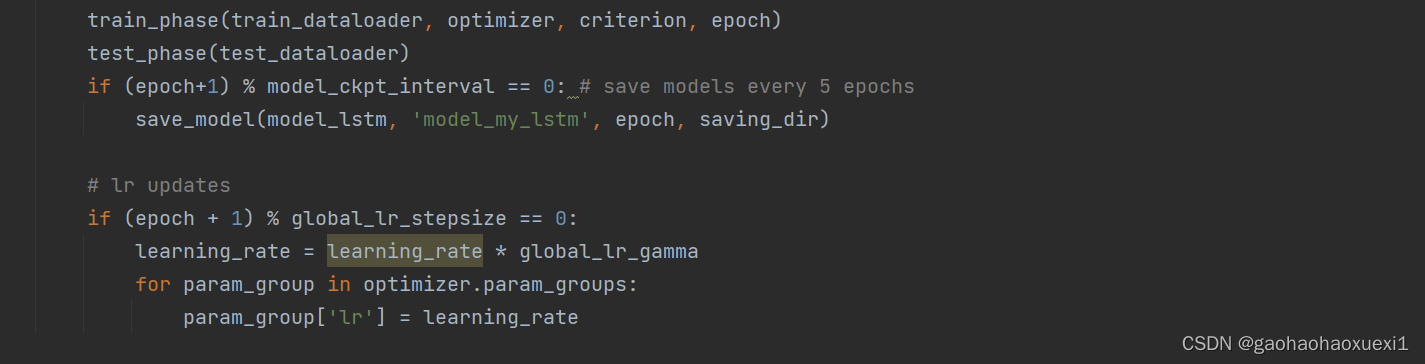
主函数,包含模型训练和测试的迭代过程。在每个 epoch 中进行训练和测试,并在每5个 epochs 保存模型,并进行学习率的更新。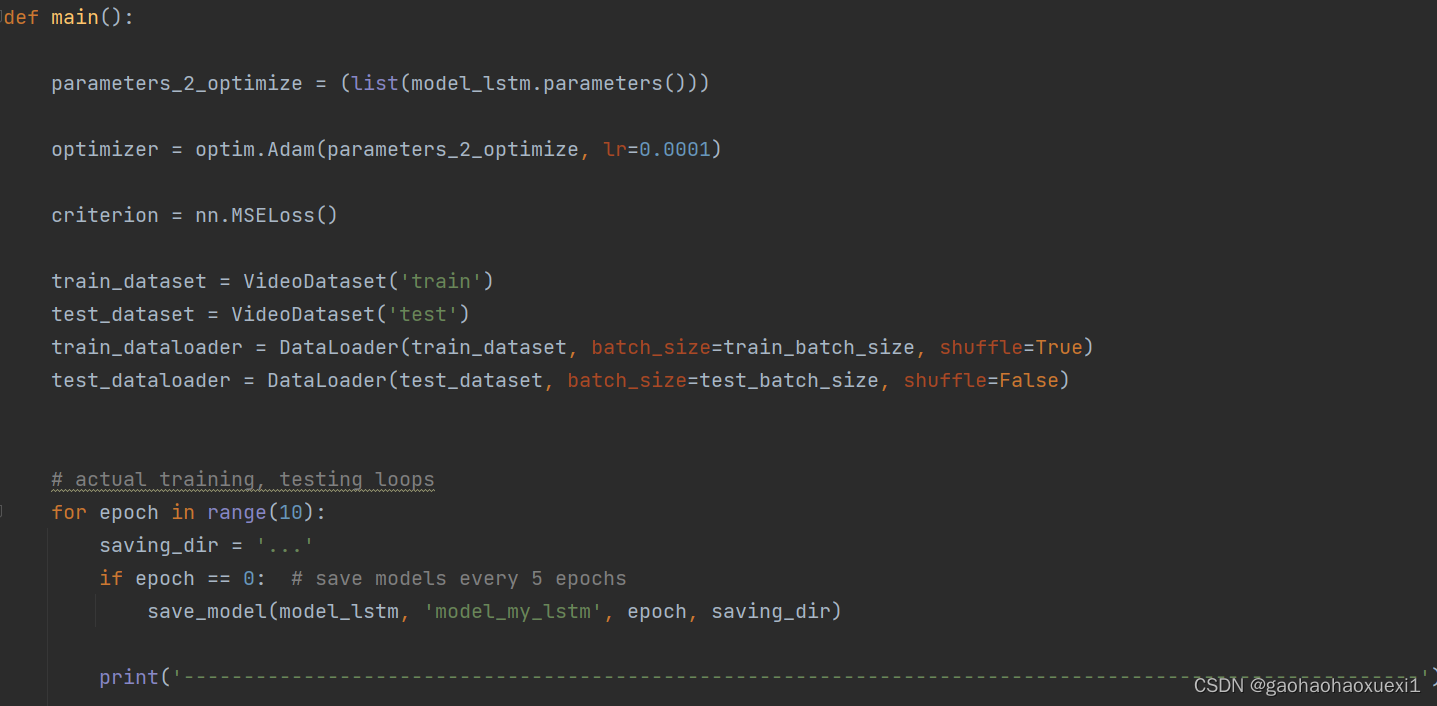
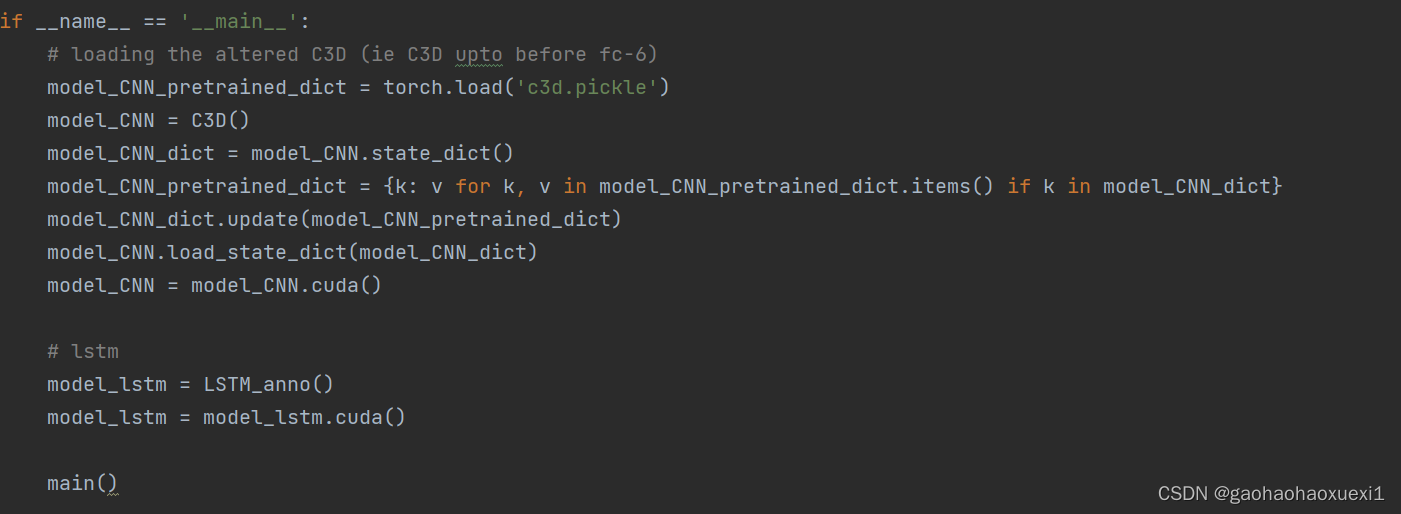
__name__:加载预训练的 C3D 模型,初始化模型并执行主函数。















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









