







持续更新中...欢迎各位大佬点评指教!
基本信息
clip-level:是16或15帧作为1个clip提取的特征
《Learning To Score Olympic Events》
introduction
动作识别和动作质量评估之间有一些关键的区别:
(1)对于一个动作识别任务来说,两种不同类别的动作之间存在显著的差异。动作之间的差异与细粒度分类非常相似。
(2)只看到整个动作的一小部分来衡量一个动作的质量是没有意义的。
学习时空特征的3D神经网络(C3D)《Learning spatiotemporal features with 3d convolutional networks》,多用于动作识别。
循环神经网络被用来捕捉视频的时间演变。
为了训练深度网络,需要大数据集。
可用的动作质量数据集少。扩充动作质量数据集需要合格的人工注释来对动作进行评分。
本文提出了多个框架,这些框架使用视觉信息进行动作质量评估,并对短时动作(跳水和健身房跳伞)和长时间动作(花样滑冰)进行评估。
贡献:
(1)增加新的体育成绩评估数据集:现有的麻省理工学院跳水数据集从159个样本增加到370个样本。收集了一个新的体操跳马数据集,包括176个样本。http://rtis.oit.unlv.edu/datasets.html
(2)提出了多种直接利用视觉信息的动作质量评估方法。现有的方法包含噪音的人体姿态信息在复杂的运动动作中很难被获取。
(3)提出了一种增量LSTM训练策略,用于在样本有限的情况下进行有效的训练,提高了预测质量,训练时间减少了约70%。
(4)演示如何使用基于LSTM的方法来确定哪里的操作质量受到了影响,这些方法可以用来提供错误反馈。
方法
提出的系统没有明确使用人体姿势信息,而是利用视觉活动信息来评估动作的质量。
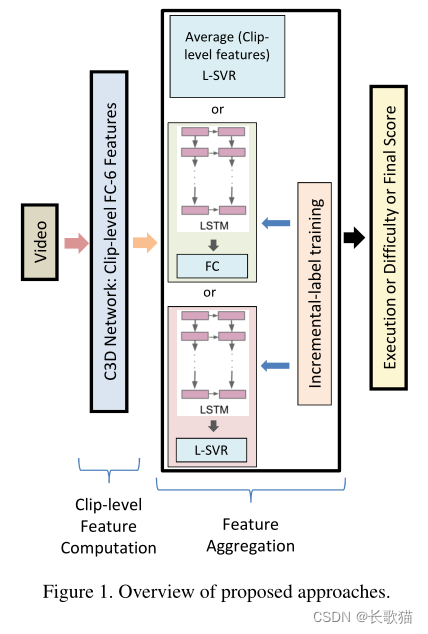
运动表现的质量不仅取决于外观,而且依赖于时间的演变。因此运动评估系统的第一阶段使用C3D网络从视频中提取时空特征。
在特征提取之后,提出了三种不同的框架,这三种框架在通过聚合剪辑级特征以获得视频级(或样本级)描述的方式上有所不同。
第一种:SVR(支持向量回归)直接构建在剪辑平均(clip-averaged)的C3D特征上。
第二种:使用LSTM显式地模拟动作的顺序性质。
第三种:结合了LSTM和SVR。
C3D-SVR
《Learning spatiotemporal features with 3d convolutional networks》中将整个动作视频划分为16帧的片段,对每个片段使用C3D提取特征。通过平均剪辑级的特征,得到视频级动作描述符,并将其作为支持向量机的输入,来输出预测动作类。
本文第一个框架用SVR代替了SVM。剪辑级特征从C3D网络的FC-6层获得,得到的是归一化的时间片段平均值,并作为使用动作分数(质量值)进行训练的SVR的输入。通过剪辑级聚合,会丢失动作的时间演化和计时。
C3D-LSTM
剪辑级别的C3D特征被组合以通过LSTM层对序列(时间)效果进行建模,以生成视频级别的描述。
C3D的FC-6层激活被用作LSTM的输入(在本工作中,有两个并行的LSTM分别对执行和难度分数进行编码)。每个LSTM后面跟随一个完全连接的回归层,以将剪辑演化的LSTM特征映射到分数。
C3D功能除了可以进行时空描述以外的另一个优势是,提供了比帧级别CNN更紧凑的视频表示,从而减少了处理视频的步骤。比如:使用C3D功能和16帧(一个clip)的时间跨度,我们可以只使用145/16=9个时间步长来表示整个动作实例;而如果我们使用帧级别的描述,我们的动作实例将是145个时间步长。
LSTM最终标签训练
动作质量评估的问题本质上是一个多对一的映射问题,给定一堆帧的情况下,预测分数。
在单个最终标签上训练LSTM,即在事件结束时打分,称为最终标签培训。在最终标签训练中,视频中的所有剪辑被顺序地传播进LSTM网络,并且在完成时通过与最终视频分数(图3中的红色)进行比较来计算误差。
使用来自C3D的FC-6层激活,使用欧几里德距离作为训练的损失函数。
在最终标签培训过程中需要确定两组未知数:
第一组未知数是归因于动作不同阶段的部分分数;
第二组未知数是看完所有输入片段后的总分。
对于有限大小的数据集(<400个示例),这将是一项困难的任务。
LSTM增量标签培训
预计随着时间的推移,随着动作的推进,分数应该增加(如果质量足够好)或被处罚(如果质量低于标准)。分数应该以非递减函数的形式通过操作进行累积。
与最终标签训练不同,在增量标签训练中,在训练LSTM时使用中间标签,而不是只对整个动作实例使用最终标签。对于给定时间步长的中间标签
应该指到剪辑片段
结束时的累积分数。增量分数的概念在图3中用蓝色表示。
中间标签可以以监督或非监督的方式获得。
在受监督的情况下,注释员必须识别子动作(动作的较小片段)和每个子动作时间的累积分数。在实践中,使用监督评分是不可行的,因为这将需要一名专家裁判来划分子动作,并使用官方规则来评估它们的价值。
无监督分配可以节省时间和精力,并提供可扩展的解决方案。一个视频被分成几个片段,总分被平均地分给每个片段(每个片段贡献相同的分数)。每个片段的中间分数为:
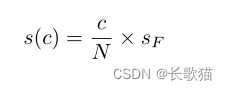

增量标签训练用于在训练阶段引导LSTM到具有中间输出的最终分数(即,在每个片段之后发生反向传播)。由于无监督作业不严格尊重子动作得分,在实践中,使用了两步训练过程:LSTM首先使用增量标签训练进行几千次迭代。在较低的学习速率下,使用最终标签训练对模型进行微调,最终标签微调在实践中效果良好,放松了增量标签对分数增长的限制。
C3D-LSTM-SVR
在C3D-LSTM-SVR中,使用相同的C3D-LSTM网络。在LSTM被移除后的最终全连接回归层,训练一个SVR,根据LSTM层的激活,预测动作质量分数。该体系结构通过LSTM提供了一个动作的显式序列和时间建模,同时利用浅判别 SVR 在有限数据下进行泛化。
Error detection
当时间分数在LSTM结构中变化时,它被用作识别动作的“好”和“差”组件。假设一个完美执行的动作会有一个不递减的分数积累,而错误会导致分数的损失。
LSTM反馈机制识别了clip-level的增益/损失,但没有提供对其原因的真实解释。
实验与结果
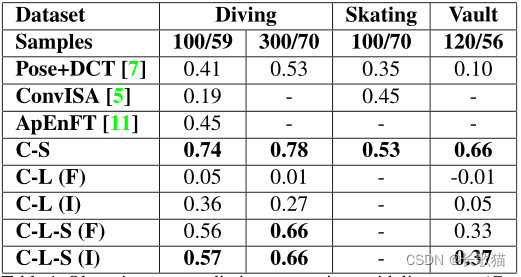
跳水:
MIT-Dive,由159个样本组成,通过包括2012年奥运会(UNLV-Dive)半决赛和决赛的潜水,这些样本已扩展到总共370个样本。
跳水分数是由“执行力”乘以跳水“难度”的乘积,再乘以基于跳水类型的固定协议值得出的。
执行得分在[0,30]范围内,每增加0.5次,而难度没有明确的上限。跳水样本是从一致的侧视图记录下来的,几乎没有视图变化。
花滑:
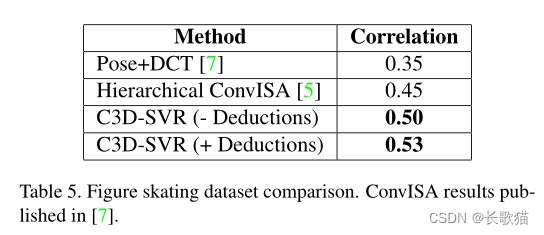
《End-To-End Learning for Action Quality Assessment》
introduction
《Learning to Score Figure Skating Sport Videos》
https://github.com/loadder/MS_LSTM.git.
introduction
1.提出网络:Self-Attentive LSTM + Multi-scale Convolutional Skip LSTM
2.提供数据集:Fis-V,500个视频,平均时长2'50"。9个裁判的两个分数:Total Element Score(TES)+Total Program Component Score(PCS)。
Fis-V:
(1)每个视频只拍摄一名滑冰运动员的整个表演。
(2)对滑冰运动员不相关的部分(如热身、表演后向观众鞠躬)被修剪掉。
(3)每个视频的长度约为2分50秒。
(4)总共收集了来自20多个不同国家的149名专业花样滑冰运动员的500个视频。
(5)收集了9名不同国际裁判在比赛中的打分。
使用数据集:Fis-V+MIT-skate《Assessing the quality of actions》
3.灵感来源:Pirsiavash et al.《Assessing the quality of actions》,模型必须理解花样滑冰视频的每个片段(每一帧),对不同长度的视频进行处理
4.主要挑战:
(1)与consumer video不同,花样滑冰视频是时长较长(平均2分50秒)的专业体育视频。
(2)花滑视频评分由专家或裁判提供,而基于 classification/detection 的视频分析任务的标签以众包?的方式收集。
(3)不是所有的视频片段都对分数回归有用,因为裁判只考虑技术动作(TES)或对音乐的良好诠释(PCS)的那些片段的分数。
5.提出一个端到端的框架预测花滑视频分数:两个互补的子网络,Self-Attentive LSTM和Multi-scale Convolutional Skip LSTM(M-LSTM)。
S-LSTM主要学习表示局部信息:使用简单的自我关注策略用来选择重要的片段特征,并直接用于回归任务。
M-LSTM在多尺度上对局部信息和全局信息进行建模,并通过跳跃LSTM来节省总计算代价。
两个子网络可以直接用作预测的模型,也可以集成到一个框架中进行最终的回归任务。
6.贡献:
(1)提出的自关注LSTM可以通过自关注策略有效地学习对局部序列信息建模。
(2)提出了一种M-LSTM模型来学习多尺度上的局部和全局信息,同时它可以通过跳过一些视频特征来节省计算成本。
(3)贡献了一个高质量的花样滑冰视频数据集:Fis-V数据集。
花样滑冰视频数据集Fis-V
1.数据集构造:
(1)数据集来源:来自高标准国际比赛,具有更好和更一致的视觉质量。
(2)选择标准:为了比分具有可比性,只使用了过去十年发生的关于女子单打短节目的比赛视频。
(3)不是 rush video:删除如热身、表演后向观众鞠躬、在Kiss&Cry等待比分等冗余的内容,并且视频只定位、跟踪一名运动员。
2.预处理和评分:
(1)预处理:程序裁剪、手动裁剪不连贯视频、重复镜头、热身镜头等。每场表演约2分50秒,符合国际标准2分40秒±10s。每个视频大约有4300帧,帧速率为25。
(2)花样滑冰的得分:TES判断所有技术动作的难度和执行力,PCS评估滑冰运动员对音乐的表现和诠释。同一名滑冰运动员在不同的比赛中可能会因为她的表现而获得非常不同的分数。将数据集随机分为400个训练视频和100个测试视频。
3.数据分析:
TES和PCS相关性不大。
与现有的麻省理工学院花样滑冰数据集相比
Fis-V拥有更大的数据规模(超过3倍的视频)
更高的标注质量(提供了PCS和TES),
收集了更多更新的花样滑冰视频(Fis-V视频来自2012年至2017年的12场比赛)。麻省理工学院滑冰比赛的所有视频都来自2012年前的比赛。
方法
1.问题设置:
(1)弱标记回归:
花滑比赛中,裁判随着比赛的进行动态增加TES。运动员完成特定动作,动作相应的TES和PCS被添加。
理想情况是需要每个技术动作的分数。实际情况是不可能将递增添加的分数与每个视频剪辑同步。因此,只提供TES和PCS的最终分数。
预测这些分数的任务可以被表示为弱标签回归任务。并将TES和PCS的预测作为两个独立的回归任务。
(2)视频特征:
采用深度时空卷积网络实现更强大的视频表示能力。
从3D卷积网络中提取现有的 deep clip-level 特征,这些特征是在大规模数据集上进行预训练的。
使用在Sports-1M上预训练的C3D的FC6层的 clip-based 4096维的特征,这是一个包含1,133,158个视频的大规模数据集,这些视频已经被自动标注了487个体育标签。
在视频时间域上使用16帧大小的滑动窗口来分割步幅为8的视频片段。
2.Self-Attentive LSTM(S-LSTM)
提出一种自关注特征嵌入来选择性地学习压缩特征表示。这种表示可以有效地对局部信息进行建模。
由于每段视频约有4300帧,持续时间为2分50秒,因此使用所有C3D功能的总计算成本将非常高。简单的做法是使用最大池化或平均池化操作符,将这些特征合并到视频级表示中。然而,并不是所有的视频剪辑/帧都对最终分数的回归做出同样的贡献。
因此,为了提取更紧凑的特征表示,需要解决两个问题:
(1)对于高难度的技术动作来说,the feature of clips 是很重要的。?
(2)产生的紧密特征表示应该是所有视频的固定长度。?
因此,提出一种自关注嵌入方案来生成视频级表示。
使用均方误差(Mean Square Error, MSE)作为损失函数。
对于自注意力机制,在MSE损失函数中加入一个惩罚项,如Eq(1)所述,以鼓励学习自注意特征嵌入M的多样性,这等于鼓励A的不同行之间的独立性。因此,鼓励A是一个稀疏矩阵,每一行的权重都很小。
为了解决回归问题,首次提出S-LSTM。与以往工作不同之处在于:
(1)自注意力策略只使用视频序列的最终输出。
(2)自注意力特征嵌入的输出用作 LSTM 的输入和回归任务的全连接层。而《Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis》是利用注意力策略来处理LSTM的输出,并直接将分类任务的特征嵌入串联起来。
3.Multi-Scale Convolutional Skip LSTM(M-LSTM)
S-LSTM是对局部序列信息进行建模,还需要对包含局部(技术动作)和全局(运动员表现)的连续帧/剪辑进行建模。因为,原则上,TES对技术动作进行评分,PCS反映运动员的整体表现。
M-LSTM学习在多个尺度上对序列信息建模。
基于密集剪辑的C3D视频特征能够很好地表示局部序列信息。
为了便于提取多个尺度的信息,M-LSTM使用了几个不同核大小的并行一维卷积层。该内核具有较小的过滤器大小,可以聚合和提取视频中持续数秒的动作模式的视觉表示。
因为花样滑冰视频时间长,LSTM的训练过程难以捕捉长期依赖关系。因此进一步提出了 skipping RNN策略。
M-LSTM基于LSTM的改进:
(1)增加二进制状态更新门,通过使用ROUND函数,当
=0,M-LSTM可以跳过不太重要的更新。
(2)修改和
的更新规则,以防止网络被迫暴露未更新的存储单元,导致误导信息
模型可以通过BPTT进行训练。
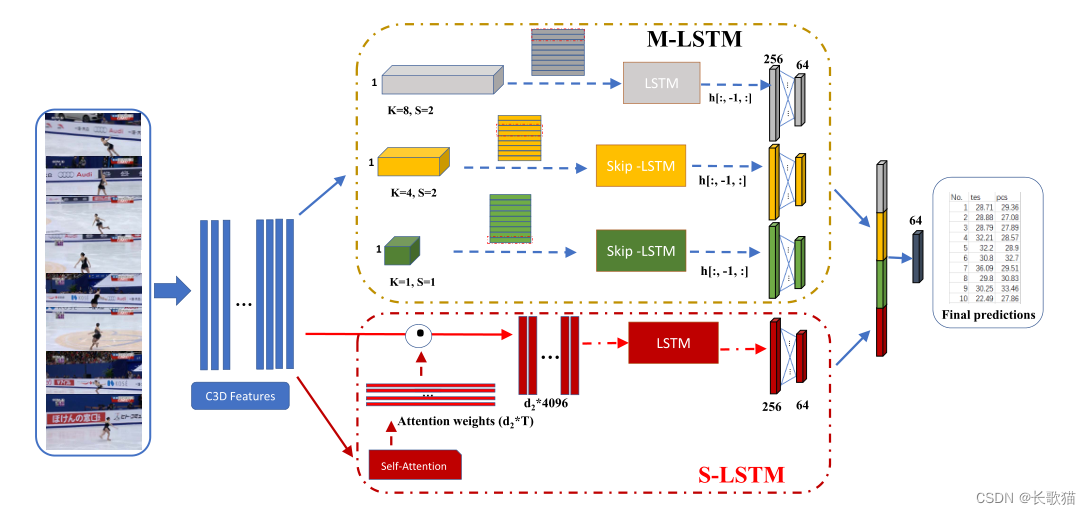
M-LSTM用来丢弃冗余信息,因此只在小核的卷积层后使用,其他卷积层使用普通的LSTM。
将所有并行LSTM的最后时间步长处的输出级联,并传输到全连接层,以回归预测分数。

















 2485
2485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









