







由于本人的近期研究方向涉及到强化学习,本科时已经学习过了,但是感觉还是有些概念和算法没有学懂学透,所以想重新系统性的学习一下,记录了整个学习过程,而且对当时没有理解不是特别深刻的内容有了一些更加深刻的理解,所以希望把学习的过程记录下来,也帮助其他的初学者能够快速入门强化学习。并且为了加深理解,会涉及一些公式。欢迎点赞,收藏!
(ps:第二遍学习了,知识真的越学越新,如果第一遍没有读懂,可能过一遍,等应用学习一段时间,可以返回来再看,真的有不同的理解),希望这份笔记能给你带来帮助。)
前提:这篇博客适合具有基础的高等数学(如:链式求导法则),概率统计(离散或连续的概率密度函数),基础的机器学习背景。因为本篇博客想要不停留在表面,所以涉及了部分对理解算法非常重要的公式及推导。
记录一下时间:第一次撰写时间:20241111 00:04
第二次撰写时间:20241113 22:03
第三次撰写时间:20241115 14:38
第四次撰写时间:20241117 20:21
强化学习(Reinforcement Learning)
一.总体概念
首先从大致上理解一下强化学习。传统的机器学习可以大致分为:有监督学习、无监督学习、强化学习。
- 有监督学习 是从外部监督者提供的带标签的训练集中学习。
- 非监督学习 是从为标注的数据集中找到隐含结构的学习过程,例如K-means聚类算法
- 强化学习更偏重于智能体与环境之间的交互。一个智能体(agent)在一个特定的环境(environment)中最大化它所能获得的奖励。通过感知所处的环境的状态(state)作出行动(action),与环境交互之后进行状态转移并得到对应的奖赏(reward),最终得到累积回报(return)。而这的方式被叫做强化学习或RL(Reinforcement Learning)。而RL学习的范式非常类似于人类学习知识的过程,也正因如此,RL被视为实现AGI重要途径。

二.强化学习特点:
- 试错学习:强化学习一般没有直接的指导信息,Agent 要以不断与 Environment 进行交互,通过试错的方式来获得最佳策略(Policy)。
- 延迟回报:强化学习的指导信息很少,而且往往是在事后(最后一个状态(State))才给出的。比如 围棋中只有到了最后才能知道胜负。
三.相关术语
根据上述对于强化学习的描述,可以注意到对应的术语包括environment, state,action,reward,return,以下将详细介绍对应的概念。
- 环境(environment)是一个外部系统,智能体处于这个系统中,能够感知到这个系统并且能够基于感知到的状态作出一定的动作,并且环境根据作出的动作给智能体一个奖赏。
- 状态(state):状态是对环境的当前状态的完整描述,不会隐藏环境的信息。所有的状态构成了状态空间(state space)
- 行动(action):智能体处于当前环境状态下作出一个动作。所有可以执行的动作构成了动作空间(action space),其中包括离散动作空间(例如:前后左右四个动作)和连续的状态空间(例如:智能体的旋转角度,360度都可以)。
- 奖励(reward):是由环境所给的一个反馈信号,该信号表明了智能体在某一步采取动作的表现,如果表现的很好,对应的reward大一点,否则就小一点。
- 回报(return):智能体从当前状态一直到最终状态所获的累积奖励
(这里注意区别return和reward)
四.强化学习问题的基本设定:
根据上述的描述,已经对强化学习有了基本的概念,接下来让我们用形式化的数学语言来更好的表示强化学习问题:
强化学习可以用一个四元组表示,如下:
<A, S, R, P>
Action space : A
State space : S
Reward: R : S × A × S → R
Transition : P :S × A → S
说明:<A,S,R,P>是强化学习的形式化表达。其中A代表智能体的动作空间(包括离散的状态空间和连续的状态空间);S表示状态空间;R是奖赏,可以看出来是一个函数映射的形式,表示智能体处在状态s,执行了某一个动作a,与环境交互后转换到了s‘,得到的奖赏(Reward)为r。所以,
(
s
,
a
,
s
′
)
→
r
(s,a,s')→r
(s,a,s′)→r;P表示状态转移函数,下一个状态完完全取决于环境。
根据上述的说明,此处也引出几个重要的概念,并详细介绍,对后续理解算法具有重要作用:
- 策略(Policy)
策略是智能体用于决定下一步之行什么动作的规则。具体是指Agent在状态s时,所要作出的action的选择,一般定义为 π \pi π,是强化学习中的核心问题。可以视为智能体在感知到环境s后动作a到一个映射。这个策略可以是确定性的,即在当前状态下只会选择一个确定的动作( a = π ( s ) a= \pi(s) a=π(s),其中a为智能体处于状态s下用策略 π \pi π所选择的动作a);也可以是随机的(不确定的),这个时候 π \pi π不再是一个确定的动作,而是当前所能选择的动作的一个概率分布(例如当前状态下智能体可以执行4个上下左右动作,在当前的策略下,对应的概率为上:0.6;下:0.1;左:0.1;右:0.2,并且概率总和为1),以上的确定策略和随机策略可以用数学表示为:
s t o c h a s t i c P o l i c y : ∑ i π ( a i ∣ s ) = 1 stochasticPolicy: \sum_i{\pi(a_i|s)}=1 stochasticPolicy:i∑π(ai∣s)=1 d e t e r m i n i s t i c P o l i c y : π ( s ) : S → A deterministicPolicy: \pi(s):S→A deterministicPolicy:π(s):S→A - 状态转移(State Transition)
智能体在环境中作出某种交互(动作)之后,将会转移到下一个状态,这种状态的转移取决于环境本身,而且这种转移也可以分为随机性和确定性转移。确定性转移表示根据当前状态和作出的动作只能转移到唯一的状态。而随机性转移则是由于环境的不确定性,导致可能下一个状态的转移是概率性的,可以用状态概率密度函数表示:
p ( s ′ ∣ s , a ) = P ( S ′ = s ′ ∣ S = s , A = a ) p(s'|s,a)=P(S'=s'|S=s,A=a) p(s′∣s,a)=P(S′=s′∣S=s,A=a)
大多数情况下,对于智能体来说,环境是未知的,并且环境也可能发生变化,而上述的函数描述了在当前环境和行动下,衡量系统状态向某一个状态转移的概率是多少。 - 回报 (Return)

回报也可以被称为累积奖赏,cumulated future reward,一般表示为U,定义为
U t = R t + R t + 1 + . . . . R T U_t = R_t+R_{t+1}+....R_T Ut=Rt+Rt+1+....RT其中 R t R_t Rt代表每一步动作的奖赏reward,而对于智能体来说,就是最大化Return,一定是累积奖赏。
未来的奖励不如现在等值的奖励那么好(比如一年后给100块不如现在就给),所以 R t + 1 R_{t+1} Rt+1的权重要比 R t R_{t} Rt的小。
在实际表示中,加入了折扣回报率用来表示折扣回报,如下:
U t = R t + γ R t + 1 + γ 2 R t + 2 + . . . U_t = R_t+\gamma R_{t+1}+\gamma ^2R_{t+2}+... Ut=Rt+γRt+1+γ2Rt+2+...其中 γ \gamma γ表示折扣率。
4.价值函数(Value-based function)
举例来说,在象棋游戏中,定义赢得游戏得1分,其他动作得0分,状态是棋盘上棋子的位置。仅从1分和0分这两个数值并不能知道智能体在游戏过程中到底下得怎么样。例如:象棋中在某一步中吃了对方的车,这步的reward会很大,但是由于这一步导致被将军,所以对于最终的目标来说,这一步也并不好。
为了对在整个游戏过程中对状态(当前的棋面对最后来说怎么样)进行评估,从而引入价值函数使用期望对未来的收益进行预测,一方面不必等待未来的收益实际发生就可以获知当前状态的好坏,另一方面通过期望汇总了未来各种可能的收益情况。使用价值函数可以很方便地评价不同策略的好坏。
注意价值函数和奖赏的区别
为了更加严谨,用数学表述:
Reward 定义的是评判一次交互中的立即的(immediate sense)回报好坏。而Value function则定义的是从长期看action平均回报的好坏。一个状态s的value是其长期期望Reward的高低。定义
V
π
(
s
)
V_\pi(s)
Vπ(s)是策略状态s长期期望收益,Q_\pi(s,a)是策略在状态s下,采取动作a的长期期望收益。
定义
G
t
G_t
Gt为长期回报期望(Return)
G
t
=
∑
n
=
0
N
γ
n
r
t
+
n
G_t = \sum_{n=0}^N \gamma^nr_{t+n}
Gt=n=0∑Nγnrt+n状态s的价值函数V为:
V
π
(
s
)
=
E
π
[
G
t
∣
S
t
=
s
]
V_\pi(s) = E_\pi[G_t|S_t=s]
Vπ(s)=Eπ[Gt∣St=s]
在状态s下采取动作a的动作价值函数Q为:
Q
π
(
s
,
a
)
=
E
π
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
Q_\pi(s,a) = E_\pi[G_t|S_t=s,A_t=a]
Qπ(s,a)=Eπ[Gt∣St=s,At=a]
在强化学习中,价值函数和Q函数之间存在一定的关系,可以通过转换公式相互表达。主要的转换方式如下:
从 Q 函数转换到状态价值函数
- 对于确定性策略
如果我们选取的是一个贪婪策略,即在状态
𝑠中选择能最大化 Q 值的动作,则价值函数可以表示为: V s = m a x a Q ( s , a ) V_s=max_aQ(s,a) Vs=maxaQ(s,a)该公式适用于寻找最优策略时(即在状态 s 中采取最佳动作的情况下)。 - 对于随机策略
如果策略 π(a∣s) 是随机的,即每个动作 𝑎 在状态 s 的概率不相同,那么价值函数可以表示为 Q 函数的期望: V s = ∑ i π ( a i ∣ s ) ∗ Q ( s , a i ) V_s=\sum_i\pi(a_i|s)*Q(s,a_i) Vs=i∑π(ai∣s)∗Q(s,ai)这里,价值函数 𝑉(𝑠)是在策略 𝜋下,对所有动作加权的 Q 值之和。这个转换公式表示的是在随机策略下,期望的长期回报。
从价值函数转换到 Q 函数
假设我们知道执行动作 𝑎会从状态 𝑠 转移到下一个状态 𝑠′,那么 Q 函数可以表示为: Q ( s , a ) = E [ r + γ V ( s ′ ) ∣ s , a ] Q(s,a) =E[ r+\gamma V(s')|s,a] Q(s,a)=E[r+γV(s′)∣s,a]在此情况下,Q 函数表示在状态 𝑠下采取动作 𝑎后获得的即时奖励 𝑟加上未来回报的折现值。而这个就是非常有名的Bellman等式
五.算法分类
按照环境是否已知划分:免模型学习(Model-Free) vs 有模型学习(Model-Based)
- Model-free就是不去学习和理解环境,环境给出什么信息就是什么信息,常见的方法有policy optimization和Q-learning。
- Model-Based是去学习和理解环境,学会用一个模型来模拟环境,通过模拟的环境来得到反馈。Model-Based相当于比Model-Free多了模拟环境这个环节,通过模拟环境预判接下来会发生的所有情况,然后选择最佳的情况。
一般情况下,环境都是不可知的,无法对环境进行建模,只能被动接受环境的反馈
按照学习方式划分:在线策略(On-Policy) vs 离线策略(Off-Policy)
- On-Policy是指agent必须本人在场, 并且一定是本人边玩边学习。典型的算法为Sarsa。
- Off-Policy是指agent可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则,离线学习同样是从过往的经验中学习, 但是这些过往的经历没必要是自己的经历,任何人的经历都能被学习,也没有必要是边玩边学习,玩和学习的时间可以不同步。典型的方法是Q-learning,以及Deep-Q-Network。
按照学习目标划分:基于策略(Policy-Based)和基于价值(Value-Based)。
- Policy-Based的方法直接输出下一步动作的概率,根据概率来选取动作。但不一定概率最高就会选择该动作,还是会从整体进行考虑。适用于非连续和连续的动作。常见的方法有Policy gradients。
- Value-Based的方法输出的是动作的价值,选择价值最高的动作。适用于非连续的动作。常见的方法有Q-learning、Deep Q Network和Sarsa。
更为厉害的方法是二者的结合:Actor-Critic,Actor根据概率做出动作,Critic根据动作给出价值,从而加速学习过程,常见的有A2C,A3C,DDPG等。
举个例子,基于策略的方法,是直接会输出当前状态下所有可选择动作的概率,(例如:上下左右,都会给一个概率),选择其中最大的并采取这步动作;基于价值的方法则是会计算当前状态下的Q-Funcion(例如: Q ( s , a i ) Q(s,a_i) Q(s,ai))然后选择最大的动作执行。
六.具体算法(重点关注深度强化学习算法,DRL)
- Q-learning算法(基于价值的方法)
- 算法思路:Q-learning算法是一个基于价值函数(value-based)的方法,不直接输出每一个状态下对应的动作的概率,而是通过计算每一步下采取某一个动作的价值,并选择动作价值最大(累计收益最大)的那个动作,从而得到最佳策略。
- 算法流程:根据算法思路,其实Q-learning算法学习的就是每一状态下采取每一个动作的价值(预期的累积收益),所以具体实现的时候就可以维护一张由state和action所组成的一张表Q-table,其中纵轴表示状态,横轴表示动作,其中每个值代表当前状态s下执行某一个动作a的Q(s,a),通过智能体与环境交互的过程不断收到环境的反馈,从而不断更新这个Qtable直到收敛了。
为了更好地理解这个算法,我们举一个例子走迷宫的例子:

问题:假设机器人必须越过迷宫并到达终点。有地雷,机器人一次只能移动一个地砖。如果机器人踏上矿井,机器人就死了。机器人必须在尽可能短的时间内到达终点。
得分/奖励系统如下:- 机器人在每一步都失去1点。这样做是为了使机器人采用最短路径并尽可能快地到达目标。
- 如果机器人踩到地雷,则点损失为100并且游戏结束。
- 如果机器人获得动力⚡️,它会获得1点。
- 如果机器人达到最终目标,则机器人获得100分。
现在,显而易见的问题是:我们如何训练机器人以最短的路径到达最终目标而不踩矿井?
我们可以思考一下,智能体处于迷宫中,在每一步中均可以执行上下左右四个动作,状态表示当前所处的位置(start,blank,power,mines,end)这样就能构成一张Q-table,如下:

有了Q-table表,初始化时所有的Q值均为0,需要在智能体作出动作之后不断的更新这个表,而具体的更新方法,则利用上述提到的Bellman公式:
Q
(
s
,
a
)
=
Q
(
s
,
a
)
+
α
(
r
+
γ
m
a
x
a
′
Q
(
s
,
a
′
)
−
Q
(
s
,
a
)
)
Q(s,a) = Q(s,a)+\alpha(r+\gamma max_{a'}Q(s,a')-Q(s,a))
Q(s,a)=Q(s,a)+α(r+γmaxa′Q(s,a′)−Q(s,a))其中
α
\alpha
α表示为学习步长,
γ
\gamma
γ表示奖赏的折扣因子。
s
′
s'
s′表示状态s下执行动作a后转变为状态s’
解释:这里的
m
a
x
a
′
Q
(
s
,
a
′
)
max_{a'}Q(s,a')
maxa′Q(s,a′)其实就是上边提到的
V
(
s
′
)
V(s')
V(s′),即状态s’的值函数(预期的累积回报)。所以这个变换公式其实可以理解为状态s下执行动作a后环境会给出一个反馈r,然后就会转移到下一个状态,而这个状态下也会有一个预期的累积回报,这样就形成了一个递推的公式。或者也可以认为
r
+
γ
m
a
x
a
′
Q
(
s
,
a
′
)
r+\gamma max_{a'}Q(s,a')
r+γmaxa′Q(s,a′)是真实的Q值,而当前的Q(s,a)为估计的,二者之间存在一个误差,然后把这个误差加到原来的Q值上就会更加准确了 ,而这个误差在RL也被称作TD误差(感兴趣的同学可以自行查阅,之后的章节也会详细讲解)。看到这里,学过数据结构或算法的同学应该能发现其实就是一个动态规划方程。
ps:如果这里不懂,可以重新看一下第四章节,要重点理解Q动作价值函数
通过上述的递推过程,不断的更新Q-table,我们就能得到一个最后最佳的Q值表,这样智能体在每一个状态下都可以得到对应动作的Q值,从而选择最大的那个动作,走到终点。
2. Deep Q Network(DQN)(基于价值的方法)
Q-learning是RL的很经典的算法,但有个很大的问题在于它是一种表格方法,也就是说它非常的直来之前,就是根据过去出现过的状态,统计和迭代Q值。一方面Q-learning适用的状态和动作空间非常小,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q-Table不现实,我们无法构建可以存储超大状态空间的Q_table。;另一方面但如果一个状态从未出现过,Q-learning是无法处理的。也就是说Q-learning压根没有预测能力,也就是没有泛化能力。
灵感乍现,突然想到, 为了能使得Q的学习能够带有预测能力,熟悉机器学习的同学很容易想到这就是一个回归问题啊!用函数拟合Q:

其中,
θ
\theta
θ代表模型参数
模型有很多种选择,线性的或非线性的。传统的非深度学习的函数拟合更多是人工特征+线性模型拟合。这几年伴随着深度学习最近几年在监督学习领域的巨大成功,用深度神经网络端到端的拟合Q值,也就是DQN,似乎是个必然了。
对于机器学习来说,非常关键的是确定模型(函数)的输入和输出,如果针对于上述
Q
(
s
,
a
)
Q(s,a)
Q(s,a)动作价值函数来说,常识肯定认为模型的输入为当前的状态s,和可能选择的动作a,模型的输出为该种情况下的动作价值函数。类似于下图中的左图,但是这样的模型架构也带来了一个问题就是在每一个状态s下的每一个动作都要进行一次向前计算,总共
∣
A
∣
|A|
∣A∣次(A为动作空间),太消耗资源。所以后来又提出了下图中的右边的模型架构,输入仅为状态s,输出当前状态下所有能执行的动作的Q值,这样计算当前状态下的所有动作的Q值仅需要一次向前传播,很好。
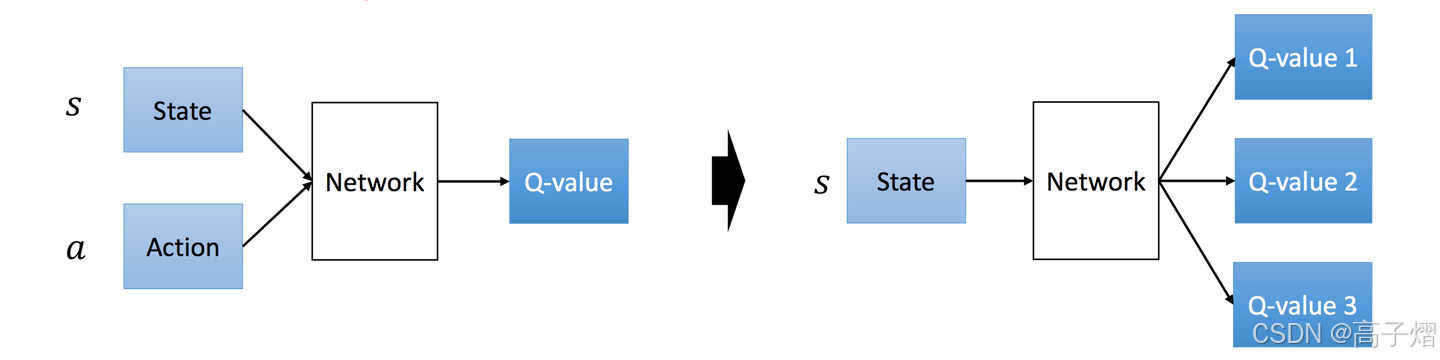
目前,我们已经确定了DQN算法的模型架构了,然后还需要确定目标函数或损失函数,然后利用梯度下降的方法不断更新。这里我们仍然沿用Q-learning中使用的Bellman公式的变形,认为对于某一个状态s和动作a的Q值
Q
(
s
,
a
)
Q(s,a)
Q(s,a)的目标为:
r
+
γ
m
a
x
a
′
Q
(
s
′
,
a
′
)
r+\gamma max_{a'}Q(s',a')
r+γmaxa′Q(s′,a′)目前的
Q
(
s
,
a
)
Q(s,a)
Q(s,a)为估计值,所以就得到了该模型的损失函数,即估计值和目标值的平方误差(二范数):
L
=
E
[
(
r
+
γ
m
a
x
a
′
Q
(
s
′
,
a
′
)
−
Q
(
s
,
a
)
)
2
]
L=E[(r+\gamma max_{a'}Q(s',a')-Q(s,a))^2]
L=E[(r+γmaxa′Q(s′,a′)−Q(s,a))2]然后有了损失函数了,就可以根据梯度下降更新参数直至收敛。下图为整体的优化,使用SGD作为优化器:

注意:其实上述我们一直都没有谈到数据的问题,上述模型训练过程是需要数据集的,而数据从哪里来呢?从智能体与环境的不断交互得到的,而每次交互得到一个(s,a,s’,r)的一个序列,把这个序列存下来,这样多起来之后就可以和正常的机器学习的有监督学习模型训练过程一致了。以下介绍为了适应DQN 这种end to end(端到端)的模型训练方式,深度强化学习所引入的2个重要方法:
- Experience Replay:DeepLearning取得重大进展的监督学习中,样本间都是独立同分布的。而RL中的样本是有关联的,非静态的(highly correlated and non-stationary),训练的结果很容易难以收敛。Experience Replay机制解决这个问题思路其实很简单,构建一个存储把样本都存储下来,通过随机采样去除相关性。(当然没有天下免费的午餐,这种方法也有弊端,比如off-policy受到了限制,也不是真正的online-learning)
- separate Target Network:原始的Q-learning中,样本标签y使用的是和训练的Q-network相同的网络。这样通常情况下,能够使得Q大的样本,y也会大,这样模型震荡和发散可能性变大。而构建一个独立的慢于当前Q-Network的target Q-Network来计算y,使得训练震荡发散可能性降低,更加稳定。
具体的算法流程:

- Policy Gradient(基于策略的方法)
首先上述介绍的Q-Learning和DQN都是基于价值的方法,在给定一个状态下,计算采取每个动作的价值,我们选择有最高Q值(在所有状态下最大的期望奖励)的行动。适用的范围仍然是在低纬离散的动作空间,而在连续连续空间就不适用了,而且我们有没有可能省略中间的步骤,即直接根据当前的状态来选择动作,也就引出了强化学习中的另一种很重要的算法,即策略梯度(Policy Gradient,PG),首先策略表示为:
π θ ( s , a ) = P [ a ∣ s , θ ] \pi_{\theta}(s,a)=\mathbb{P}[a|s,\theta] πθ(s,a)=P[a∣s,θ]其中 θ \theta θ表示为模型的参数,表示为状态s下选择a的概率大小。
策略梯度方法(Policy Gradient)是一类用于强化学习的算法,其目标是直接优化策略,使得智能体能够在环境中获得最大化的长期回报。与基于价值函数的方法(如Q-Learning)不同,策略梯度方法不直接估计状态或状态-动作对的价值,而是直接学习一种策略,使智能体在每个状态下输出一个概率分布,从而决定选择哪个动作。
核心思想
在策略梯度方法中,我们通常定义一个参数化策略,记为 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) ,表示在状态s下选择动作a的概率,且该概率由参数 θ \theta θ控制。通过优化参数 θ \theta θ,使得智能体选择能够最大化预期回报的动作。
策略梯度算法的步骤
-
定义损失函数:
策略梯度方法通常使用一个目标函数来衡量策略的优劣。常见的目标函数是累积奖励期望,记为 J ( θ ) J(\theta) J(θ):
J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T γ t r t ] J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^{T} \gamma^t r_t \right] J(θ)=Eτ∼πθ[t=0∑Tγtrt]
其中 τ \tau τ是一个完整的轨迹(即从初始状态到终止状态的状态和动作序列), γ \gamma γ是折扣因子, r t r_t rt是时间步t的奖励。 -
计算梯度:
为了最大化 J ( θ ) J(\theta) J(θ),我们可以通过梯度上升(或下降)来更新策略参数 θ \theta θ。策略梯度的更新公式为:
∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) R ( τ ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t|s_t) R(\tau) \right] ∇θJ(θ)=Eτ∼πθ[t=0∑T∇θlogπθ(at∣st)R(τ)]其中, R ( τ ) R(\tau) R(τ)是轨迹 τ \tau τ的总回报,表示累积奖励。 -
策略更新:
通过采样轨迹,估计梯度,并使用**梯度上升(或下降)**更新参数 θ \theta θ:
θ ← θ + α ∇ θ J ( θ ) \theta \leftarrow \theta + \alpha \nabla_\theta J(\theta) θ←θ+α∇θJ(θ)其中, α \alpha α是学习率。
策略梯度方法中的目标函数梯度推导(对于理解算法很重要)
-
定义目标函数
在策略梯度方法中,我们的目标是最大化策略的累积期望回报。定义目标函数为:
J ( θ ) = E τ ∼ π θ [ R ( τ ) ] J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ R(\tau) \right] J(θ)=Eτ∼πθ[R(τ)]其中, R ( τ ) R(\tau) R(τ) 是轨迹 τ \tau τ 的总回报(轨迹是从初始状态到终止状态的状态-动作序列),具体定义为:
R ( τ ) = ∑ t = 0 T γ t r t R(\tau) = \sum_{t=0}^{T} \gamma^t r_t R(τ)=t=0∑Tγtrt -
目标函数的梯度
我们希望对参数 θ \theta θ 求目标函数 J ( θ ) J(\theta) J(θ) 的梯度,以便使用梯度上升进行优化。根据定义,有:
∇ θ J ( θ ) = ∇ θ E τ ∼ π θ [ R ( τ ) ] \nabla_\theta J(\theta) = \nabla_\theta \mathbb{E}_{\tau \sim \pi_\theta} \left[ R(\tau) \right] ∇θJ(θ)=∇θEτ∼πθ[R(τ)]通过将期望值的梯度写成积分形式,我们可以用微分期望值的链式法则来计算:
∇ θ J ( θ ) = ∫ τ ∇ θ π θ ( τ ) R ( τ ) d τ \nabla_\theta J(\theta) = \int_{\tau} \nabla_\theta \pi_\theta(\tau) R(\tau) \, d\tau ∇θJ(θ)=∫τ∇θπθ(τ)R(τ)dτ -
应用对数梯度技巧
为了便于计算,我们可以将梯度移到对数项上。考虑到概率密度的性质,使用对数梯度技巧(也称策略梯度定理):
∇ θ J ( θ ) = ∫ τ π θ ( τ ) ∇ θ log π θ ( τ ) R ( τ ) d τ \nabla_\theta J(\theta) = \int_{\tau} \pi_\theta(\tau) \nabla_\theta \log \pi_\theta(\tau) R(\tau) \, d\tau ∇θJ(θ)=∫τπθ(τ)∇θlogπθ(τ)R(τ)dτ由于 π θ ( τ ) \pi_\theta(\tau) πθ(τ) 是概率密度函数,我们可以将其作为期望值来重写:
∇ θ J ( θ ) = E τ ∼ π θ [ ∇ θ log π θ ( τ ) R ( τ ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \nabla_\theta \log \pi_\theta(\tau) R(\tau) \right] ∇θJ(θ)=Eτ∼πθ[∇θlogπθ(τ)R(τ)]这个公式是策略梯度的核心,即通过对数梯度技巧,可以将期望的梯度转换为对数概率的梯度与回报的乘积的期望。 -
轨迹概率的分解
轨迹 τ \tau τ 是由一系列状态和动作构成的序列,我们可以将轨迹的概率表示为每一步状态转移和动作选择的联合概率:
π θ ( τ ) = p ( s 0 ) ∏ t = 0 T π θ ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) \pi_\theta(\tau) = p(s_0) \prod_{t=0}^{T} \pi_\theta(a_t | s_t) p(s_{t+1} | s_t, a_t) πθ(τ)=p(s0)t=0∏Tπθ(at∣st)p(st+1∣st,at)因此,轨迹的对数概率为:
log π θ ( τ ) = log p ( s 0 ) + ∑ t = 0 T ( log π θ ( a t ∣ s t ) + log p ( s t + 1 ∣ s t , a t ) ) \log \pi_\theta(\tau) = \log p(s_0) + \sum_{t=0}^{T} \left( \log \pi_\theta(a_t | s_t) + \log p(s_{t+1} | s_t, a_t) \right) logπθ(τ)=logp(s0)+t=0∑T(logπθ(at∣st)+logp(st+1∣st,at))其中: p ( s 0 ) p(s_0) p(s0): 初始状态的概率; π θ ( a t ∣ s t ) \pi_\theta(a_t | s_t) πθ(at∣st): 策略在状态 s t s_t st 下选择动作 a t a_t at 的概率; p ( s t + 1 ∣ s t , a t ) p(s_{t+1} | s_t, a_t) p(st+1∣st,at): 环境的状态转移概率。
由于策略梯度只涉及策略参数的梯度,而状态转移概率 p ( s t + 1 ∣ s t , a t ) p(s_{t+1} | s_t, a_t) p(st+1∣st,at) 与 θ \theta θ 无关,所以可以忽略不涉及 θ \theta θ 的项,得到:
∇ θ log π θ ( τ ) = ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta \log \pi_\theta(\tau) = \sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t | s_t) ∇θlogπθ(τ)=t=0∑T∇θlogπθ(at∣st) -
最终的策略梯度公式
将上述结果代入原式,得到策略梯度的最终形式:
∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) R ( τ ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t | s_t) R(\tau) \right] ∇θJ(θ)=Eτ∼πθ[t=0∑T∇θlogπθ(at∣st)R(τ)]这个公式表示,在每一步上,策略梯度等于对数概率梯度与轨迹总回报的乘积的期望。 -
使用每步回报的替代
为了减少方差,通常不会使用整个轨迹的总回报 R ( τ ) R(\tau) R(τ) 来更新梯度,而是用从某个时间步 t t t 开始的折扣累积回报 G t G_t Gt 代替: G t = ∑ k = t T γ k − t r k G_t = \sum_{k=t}^{T} \gamma^{k-t} r_k Gt=k=t∑Tγk−trk因此,策略梯度可以写为:
∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) G t ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t | s_t) G_t \right] ∇θJ(θ)=Eτ∼πθ[t=0∑T∇θlogπθ(at∣st)Gt]这个公式是REINFORCE算法的核心公式,它利用每步的累积回报 G t G_t Gt 来更新梯度,从而提高策略的期望回报。
策略梯度方法的优点与缺点
-
优点:
- 适用于连续动作空间:策略梯度方法可以在连续动作空间中使用,这是基于值函数的方法难以实现的。
- 探索能力强:通过概率输出策略,策略梯度可以在不同状态下随机选择不同的动作,具备探索的灵活性。
-
缺点:
- 方差较大:策略梯度的估计容易出现高方差,导致训练不稳定。通常需要一些技巧,如基线函数或优势函数,来减少方差。
- 收敛速度较慢:相较于基于值的强化学习方法,策略梯度方法的收敛速度通常较慢,需要更多的采样和更新。
- Actor Critic(基于价值与基于策略二者结合)
首先来思考一下,Policy Graident的基于策略的方法有什么缺点呢?因为没有价值函数,导致无法在智能体每执行一步的时候就能进行更新策略网络,只能等到最后一个回合(得到最终结果,获胜或失败)才能得到反馈。所以最经典的PG算法就是利用蒙特卡洛模拟的方式实现,通过多次模拟智能体的行动完成一个完整轨迹(一整局游戏)从而得到reward。所以就想到了能不能结合基于价值的方法和基于策略的方法,这样就可以实现在智能体通过策略网络得到某一个动作的时候都可以计算一个预计累积奖赏Q(s,a),从而指导策略网络的更新,而这样就提出了Actor-Critic
算法。
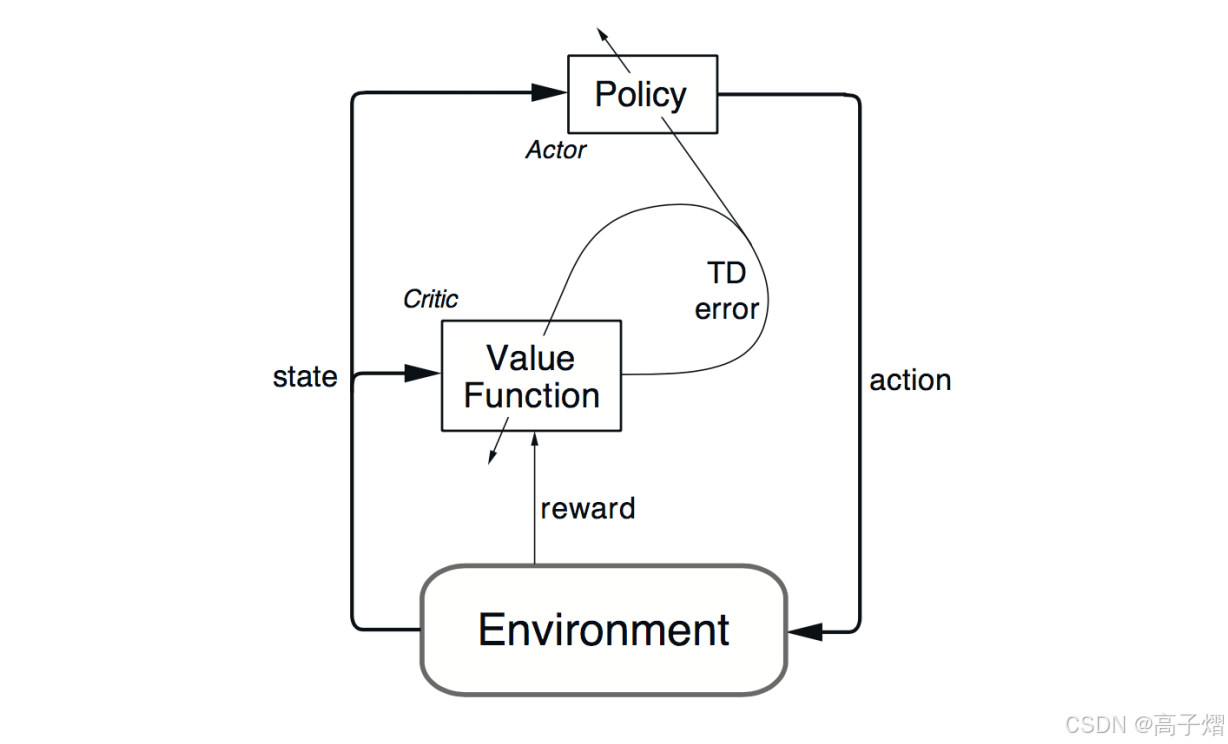
上图为actor-critic算法的一个架构图:
- 演员(Actor)是指策略函数 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s) ,即学习一个策略来得到尽量高的回报。
- 评论家(Critic)是指动作价值函数 Q ( s , a ) Q(s,a) Q(s,a),用于评价当前选择的动作的预计的累积奖赏(是否好)
- 借助于价值函数,演员-评论家算法可以进行单步更新参数,不需要等到回合结束才进行更新。
具体理解类似于Actor为智能体根据自身的策略作出决策,而Critic对根据当前策略选择的进行评价,从而根据这个评价更新自己的策略形式。
而上一章节所提到的策略可以分为确定性策略(Deterministic Policy,DP),和随机性策略(Stochastic Policy,SP),下边将根据off-line DP进行介绍Actor-Critic算法的基本流程:
- 在DDPG(Deep Deterministirc Policy Gradient,深度确定策略梯度)中actor-critic算法结合了value-based和policy-based方法。policy网络是actor(行动者),输出动作(action-selection)。value网络是critic(评价者),用来评价actor网络所选动作的好坏(action value estimated),并生成TD_error信号同时指导actor网络critic网络的更新。
- actor网络的输入时state,输出action,以DNN进行函数拟合,对于连续动作NN输出层可以用tanh或sigmod,离散动作以softmax作为输出层则达到概率输出的效果。critic网络输入为state和action,输出为Q值。
- 具体的算法流程如下:
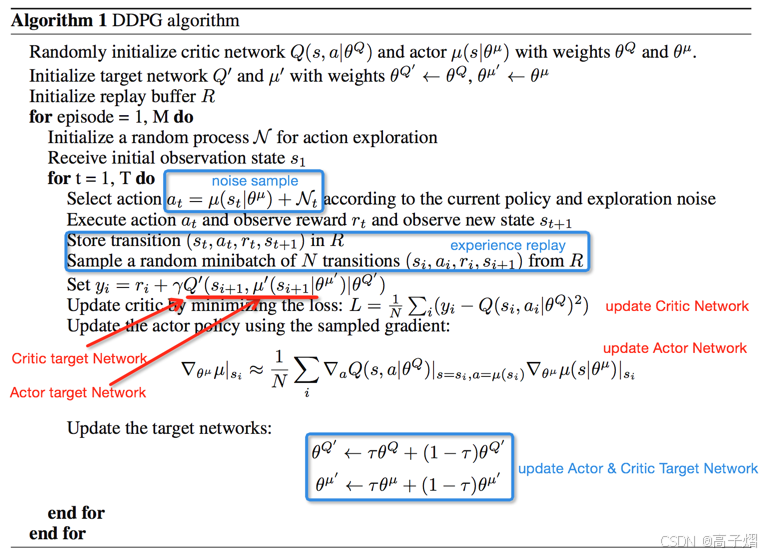
分析:
这里处理类似于DQN为了保证更好的收敛性,DDPG中借鉴了DQN的experience replay和target network。target network的具体实现与DQN略有不同,DDPG论文中的actor和critic的两个target network以小步长滞后更新,而非隔C步更新。如下将详细讲解算法流程: - 首先类似于DQN计算
y
i
y_i
yi,用于计算loss function 从而更新Q Network
y i = r + γ Q t a r g e t ( s ′ , μ t a r g e t ) ) y_i = r+\gamma Q_{target}(s',\mu_{target})) yi=r+γQtarget(s′,μtarget))其中s,s’代表当前状态及下一个状态。 - 然后更新Critic网络:因为对于Critic网络来说,它的目标函数(损失函数)就是Q,所以直接梯度下降就行了。但是这里需要注意有一个链式法则的推导,实现对Q(s,a)中的a求导,然后 μ \mu μ再对 θ \theta θ求导。
- 最后用小步长更新target Network,循环下去。
注意这里引入了Noise sample的概念:连续动作空间的RL学习的一个困难时action的探索。DDPG中通过在action基础上增加Noise方式解决这个问题。
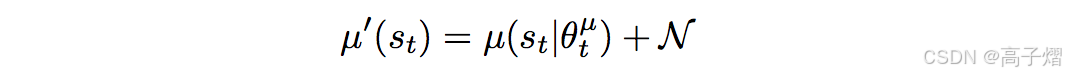
- 其他改进算法
七、附加内容
马尔可夫决策过程(MDP)
MDP的基本组成
一个MDP由以下四个关键元素构成,强化学习过程其实就是一个MDP过程:
-
状态空间(State Space, S S S)
表示环境的所有可能状态。例如,机器人在房间中的每一个位置可以被视为一个状态。 -
动作空间(Action Space, A A A)
表示智能体在每个状态下可以采取的所有可能动作。例如,机器人可以选择“向上移动”或“向右移动”。 -
转移概率(Transition Probability, P ( s ′ ∣ s , a ) P(s'|s, a) P(s′∣s,a))
描述从当前状态 s s s 通过动作 a a a 转移到下一状态 s ′ s' s′ 的概率。这个属性体现了系统的随机性。 -
奖励函数(Reward Function, R ( s , a , s ′ ) R(s, a, s') R(s,a,s′))
表示智能体在状态 s s s 执行动作 a a a 转移到 s ′ s' s′ 时获得的即时回报。它反映了某种动作在某种环境中的价值。
MDP的核心特点
5. 马尔可夫性质
系统的未来状态只依赖于当前状态和动作,而与过去的状态和动作无关。
数学表达:
P
(
s
t
+
1
∣
s
t
,
a
t
,
s
t
−
1
,
a
t
−
1
,
…
)
=
P
(
s
t
+
1
∣
s
t
,
a
t
)
P(s_{t+1} | s_t, a_t, s_{t-1}, a_{t-1}, \dots) = P(s_{t+1} | s_t, a_t)
P(st+1∣st,at,st−1,at−1,…)=P(st+1∣st,at)
很重要的性质:系统的未来状态只依赖于当前状态和动作,而与过去的状态和动作无关。
-
策略(Policy, π \pi π)
决策的规则,定义了智能体在每个状态下选择动作的方式。策略可以是确定性的(直接选择一个动作)或随机性的(为每个动作分配一个概率)。 -
目标(Objective)
最大化累积奖励,通常通过折扣因子 γ \gamma γ (取值在 0 ≤ γ ≤ 1 0 \leq \gamma \leq 1 0≤γ≤1)加权未来奖励来表示:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ = ∑ k = 0 ∞ γ k R t + k + 1 G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \dots = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} Gt=Rt+1+γRt+2+γ2Rt+3+⋯=k=0∑∞γkRt+k+1 -
TD与MC误差
TD方法的误差(Temporal Difference Error)
- 误差来源:
TD方法使用单步的预测值来更新目标值,这种预测称为“引导目标”(Bootstrapping)。因此,其误差来源于:- 即时奖励的随机性:当前获得的奖励可能具有波动性。
- 值函数的估计误差:当前估计的值函数可能不准确。
TD误差公式
δ t = R t + 1 + γ V ( s t + 1 ) − V ( s t ) \delta_t = R_{t+1} + \gamma V(s_{t+1}) - V(s_t) δt=Rt+1+γV(st+1)−V(st)其中:
- R t + 1 R_{t+1} Rt+1 是即时奖励。
- V ( s t + 1 ) V(s_{t+1}) V(st+1) 是下一状态的值函数估计。
- V ( s t ) V(s_t) V(st) 是当前状态的值函数估计。
优点与缺点
- 优点:
- 更新更快,只需当前的一步信息。
- 在线学习,可逐步改进值函数。
- 缺点:
- 误差可能会因不准确的值函数传播,导致学习变慢。
MC方法的误差(Monte Carlo Error)
- 误差来源:
MC方法使用完整的轨迹回报来更新目标值,因此误差主要来源于:- 轨迹长度的随机性:轨迹越长,累积奖励的方差越大。
- 样本不足:需要大量样本才能准确估计长期回报。
MC目标公式
$$ G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + … G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \dots Gt=Rt+1+γRt+2+γ2Rt+3+…$$
优点与缺点
- 优点:
- 不依赖当前值函数估计,不会因错误传播。
- 在轨迹足够多的情况下,误差可以收敛到真实值。
- 缺点:
- 需要完整的轨迹,不能在中间状态进行更新。
- 轨迹长度较长时,回报的方差较高。
TD与MC误差的对比
| 特性 | TD方法 | MC方法 |
|---|---|---|
| 误差来源 | 预测值误差(引导目标不准确) | 轨迹回报的方差 |
| 更新频率 | 每一步(在线更新) | 每个完整轨迹(离线更新) |
| 目标值 | 即时奖励 + 估计的下一个状态值 | 完整轨迹的累积回报 |
| 计算需求 | 较低(只需一步信息) | 较高(需完整轨迹) |
| 适用场景 | 在线学习、环境反馈迅速 | 回报明确、轨迹容易获取的任务 |
直观理解MC error和TD error的差异,假设RL的任务要预估的是上班的"到公司时长",状态是目前的位置,比如“刚出门”“到地铁了”“到国贸站了”…。MC方法需要等到真正开到公司才能校验“刚出门”状态时预估的正确性,得到MC error;而TD则可以利用“刚出门”和“到地铁了”两个状态预测的差异的1-step TD error来迭代。
总结
- TD方法适用于动态环境,因其更新频率高,误差传播较快,但需要依赖值函数的准确性。
- MC方法适用于静态环境,因其直接基于轨迹回报计算,但对数据需求较高且误差方差可能较大。


















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









