







【SAM模型应用于遥感影像|论文解读4】突破边界与一致性:SAM模型革新遥感影像语义分割
【SAM模型应用于遥感影像|论文解读4】突破边界与一致性:SAM模型革新遥感影像语义分割
文章目录
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议入口:https://ais.cn/u/mmmiUz
论文链接:https://arxiv.org/abs/2312.02464
代码连接:https://github.com/sstary/SSRS
四、EXPERIMENTS AND DISCUSSION
A. Datasets
1)ISPRS Vaihingen:
ISPRS Vaihingen 数据集包含 16 幅高分辨率真射影像,平均分辨率为 2500 × 2000 像素。每幅正射影像包括近红外、红色和绿色(NIRRG)三个通道,地面采样距离为 9 厘米。该数据集包括五个前景类别,分别是:不可渗透面、建筑物、低矮植被、树木、汽车,以及一个背景类别(杂乱物体)。这 16 幅正射影像被划分为 12 幅训练集和 4 幅测试集。训练集包括索引号为 1、3、23、26、7、11、13、28、17、32、34、37 的正射影像,而测试集包括索引号为 5、21、15、30 的正射影像。
2)LoveDA Urban:
LoveDA 数据集包含两个场景,分别是城市(Urban)和农村(Rural)。鉴于地物分布的多样性,我们选择了 LoveDA 的城市场景进行实验。LoveDA Urban 包含 1833 幅高分辨率光学遥感影像,每幅影像的大小为 1024 × 1024 像素。影像提供了红色、绿色和蓝色(RGB)三个通道,地面采样距离为 30 厘米。该数据集涵盖了七个地物类别,包括背景、建筑物、道路、水体、荒地、森林和农业【64】。这些影像来自中国的三个城市:南京、常州和武汉。1833 幅影像被划分为两个部分,其中 1156 幅用于训练,677 幅用于测试。训练集包含编号从 1366 到 2521 的影像,而测试集的编号范围为 3514 到 4190。
这两个数据集在采样分辨率、地物类别和标签精度上存在差异。值得注意的是,**ISPRS Vaihingen 数据集展示了更高的采样精度、更少的类别数以及更精确的真实标签。而 LoveDA Urban 则呈现出相反的特征。**在这两个数据集上进行实验为验证我们框架的有效性提供了有力的证据。在训练和测试过程中,使用滑动窗口动态组装训练批次,以便处理大尺寸影像而无需预先分割。滑动窗口大小设置为 256 × 256,训练时步长为 256,测试时步长调整为 32。测试时使用较小的步长可以通过对重叠区域的预测结果进行平均,来有效缓解边界效应【65, 66】。
B. Evaluation Metrics
为了评估所提框架的分割性能,我们在实验中使用了平均F1得分(mF1)和平均交并比(mIoU)。这些广泛使用的统计指标允许我们对比本方法与当前先进基线方法的性能。在 ISPRS Vaihingen 数据集中,我们计算了五个前景类别的 mF1 和 mIoU。标记为“杂乱”或“背景”的类别被视为杂乱且稀疏的类别,因此不计算其性能统计【13, 24】。在 LoveDA Urban 数据集中,我们的实验涵盖了所有七个类别。对于每个通过索引
c
c
c 识别的类别,我们使用以下公式计算 F1 和 IoU 指标:
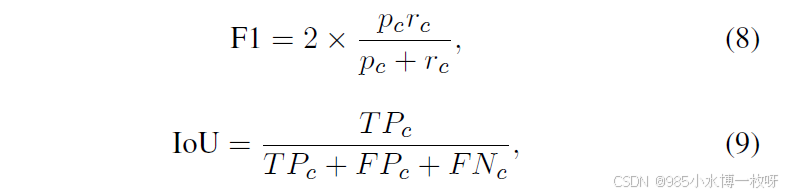
其中,
T
P
c
TP_c
TPc、
F
P
c
FP_c
FPc 和
F
N
c
FN_c
FNc 分别表示第 c 类的真正例、假正例和假负例。此外,
p
c
p_c
pc 和
r
c
r_c
rc 分别表示精度和召回率,定义如下:
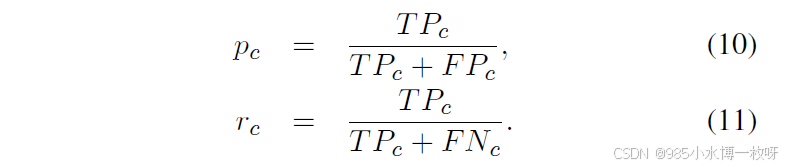
根据上述定义计算主要类别的 F1 和 IoU 后,我们得出它们的平均值,分别记为 mF1 和 mIoU。
C. Implementation details
实验使用 PyTorch 在一台配备 24GB RAM 的 NVIDIA GeForce RTX 4090 GPU 上进行。为了生成 SGO 和 SGB,我们使用了 Meta AI 提供的接口,其中涉及三个相关参数:“crop nms thresh”、“box nms thresh”和“pred iou thresh”,其定义可以在 Meta AI 文档中找到【1】。在我们的实验中,这些参数值分别设置为 0.5、0.5 和 0.96。需要注意的是,较高的 “pred iou thresh” 值倾向于生成更可靠的原始输出。阈值 K 和 S 都设置为 50。所有模型的训练均采用随机梯度下降法(SGD)作为优化算法。此外,实验使用的学习率为 0.01,动量为 0.9,衰减系数为 0.0005,批次大小为 10。
λ
o
λ_o
λo 和
λ
b
λ_b
λb 的取值基于我们的敏感性分析结果(详见第 IV-E 节)。所有实验都使用了简单的数据增强技术,如随机旋转和翻转。
D. Performance Comparison
我们在四个具有代表性的遥感图像语义分割模型上对提出的框架进行了基准测试,分别是 ABCNet【63】、CMTFNet【24】、UNetformer【21】和 FTUNetformer【21】。具体而言,这四种方法采用了最近最常见的主干网络,即基于 CNN 的 ResNet【10】和基于自注意力机制的 Swin Transformer【67】。这一选择使我们能够验证该方法在不同经典网络中的表现。定量结果列在表 I 和表 II 中。
Vaihingen 数据集上的性能比较:
如表 I 所示,提出的框架在 mF1 和 mIoU 指标上相比于四个基线方法表现出显著的改进。这些结果证明了该方法在稳健捕捉对象和边界表示方面的有效性。值得注意的是,SGO 和 SGB 信息的引入大大提升了遥感图像中语义分割的性能。为说明起见,我们重点关注第三组实验,在这组实验中,UNetformer+SAM 在五个类别中,即不透水表面、建筑物、低矮植被、树木和汽车类别上均优于 UNetformer。特别是在 ISPRS Vaihingen 数据集中,UNetformer+SAM 在汽车类别的 F1 和 IoU 上分别比 UNetformer 提高了 1.08% 和 1.78%。此外,建筑物类别的分类精度在 F1 和 IoU 上分别提高了 0.49% 和 0.91%,相较于 UNetformer。这些改进可以归因于汽车和建筑物类别的固有特性,这些类别通常比其他地物类别表现出更简单和标准化的形状。例如,汽车通常在一致的采样条件下呈现固定大小的矩形,而建筑物则通常表现为可变大小的矩形。因此,SGO 和 SGB 为这些特定类别提供了更可靠的标准,从而促进了更准确的分割。
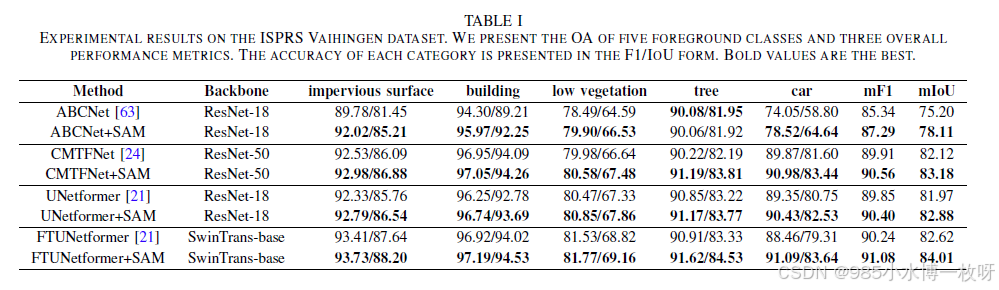
相比之下,不透水表面、低矮植被和树木通常具有复杂的边界和不同的大小。尽管它们具有复杂性,SGO 和 SGB 仍然为这些特定类别提供了有价值的补充信息。例如,不透水表面的分类精度在 F1 和 IoU 上分别提高了 0.46% 和 0.78%。同时,低矮植被和树木在 F1 和 IoU 指标上也表现出相似的改进,反映了它们相似的特征。总体表现上,UNetformer+SAM 实现了 90.40% 的 mF1 和 82.88% 的 mIoU,相比于 UNetformer 分别提高了 0.55% 和 0.91%。
表 I 中的其他对比实验进一步证实了上述观察。具体而言,采用 Swin Transformer 作为主干网络的 FTUNetformer+SAM 在汽车类别的 F1 和 IoU 指标上分别比 FTUNetformer 提高了 2.63% 和 4.33%,表现出显著的提升。此外,我们还观察到建筑物类别的分类精度有小幅提升,F1 和 IoU 分别提高了 0.27% 和 0.51%。特别是在树木类别中,提升尤为显著,而低矮植被类别的提升则有所减弱,主要是因为这两类地物之间的显著相似性。总体性能表现为 91.08% 的 mF1 和 84.01% 的 mIoU,分别比 FTUNetformer 提高了 0.84% 和 1.39%。这些结果证明了在 SGO 和 SGB 的辅助下,提出的框架在不同模型中展现了优越的泛化性能。

图 6 展示了基线方法与我们方法之间的视觉对比。在所有子图中,紫色框突出显示了感兴趣区域。首先,我们的方法在准确分割整个物体方面表现出色,特别是在建筑物的清晰划分中尤为明显。其次,我们的方法显著优化了物体边界,如低矮植被和建筑物的分割,能够更接近实际的地面真实边界。此外,我们的方法成功应对了树木、建筑物和不透水表面等难以分割的类别。这些改进主要得益于 SGO 和 SGB 中包含的目标区域和边界细节信息。利用基于目标和边界的损失函数所设计的框架,能够全面利用这些详细信息,从而带来了分割精度的提升。
LoveDA Urban 数据集的性能对比:
尽管 LoveDA Urban 数据集与 ISPRS Vaihingen 数据集在采样分辨率和地物类别上存在差异,实验结果却展现了与 ISPRS Vaihingen 数据集相似的趋势。考虑到 ABCNet 和 CMTFNet 的基准表现相对较低,我们的方法在整体性能上实现了显著的提升。观察表 II 中 UNetformer 和 UNetformer+SAM 的结果,建筑物、水体和农业的分类精度分别为 75.91%/61.17%、80.55%/67.43% 和 43.64%/27.91%,相较于 UNetformer,F1 和 IoU 指标分别提高了 6.82%/8.39%、2.89%/3.96% 和 23.1%/16.47%。同时,FTUNetformer+SAM 的结果也一致验证了在这些具有规则形状和边界较为简单的类别上具有优势。其对应的 mF1 和 mIoU 分别为 65.74% 和 50.55%,比 UNetformer 提高了 0.4% 和 1.43%,而 FTUNetformer 上的 mF1 和 mIoU 分别提升了 1.07% 和 0.97%。
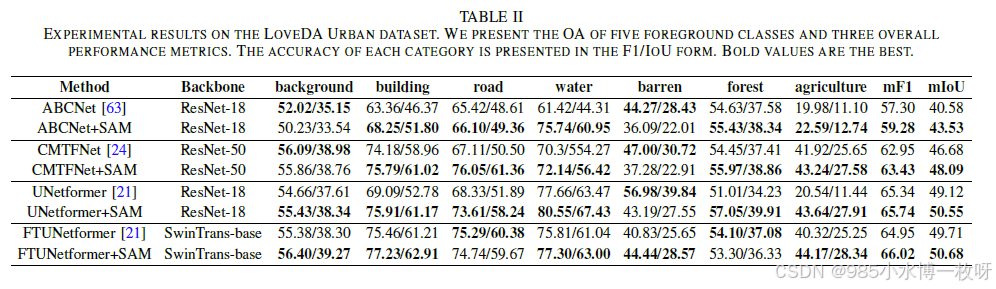
然而,在评估该数据集时,我们观察到四个基线模型的结果表现出波动。例如,UNetformer+SAM 在道路和森林类别上表现出色,而 FTUNetformer+SAM 则表现相反。相反地,UNetformer+SAM 在荒地类别上的性能有所下降,而 FTUNetformer+SAM 则有所提升。这一差异的主要原因在于这三类地物的边界复杂且尺寸变化较大。特别是,荒地所占比例非常小,导致其在实验中结果的波动【64】。尽管语义分割模型旨在提升整体性能,但无法保证每个类别都能实现一致的改进。尽管如此,我们框架的整体性能提升证明了这一方法对后续不同模型的遥感工作具有指导意义。
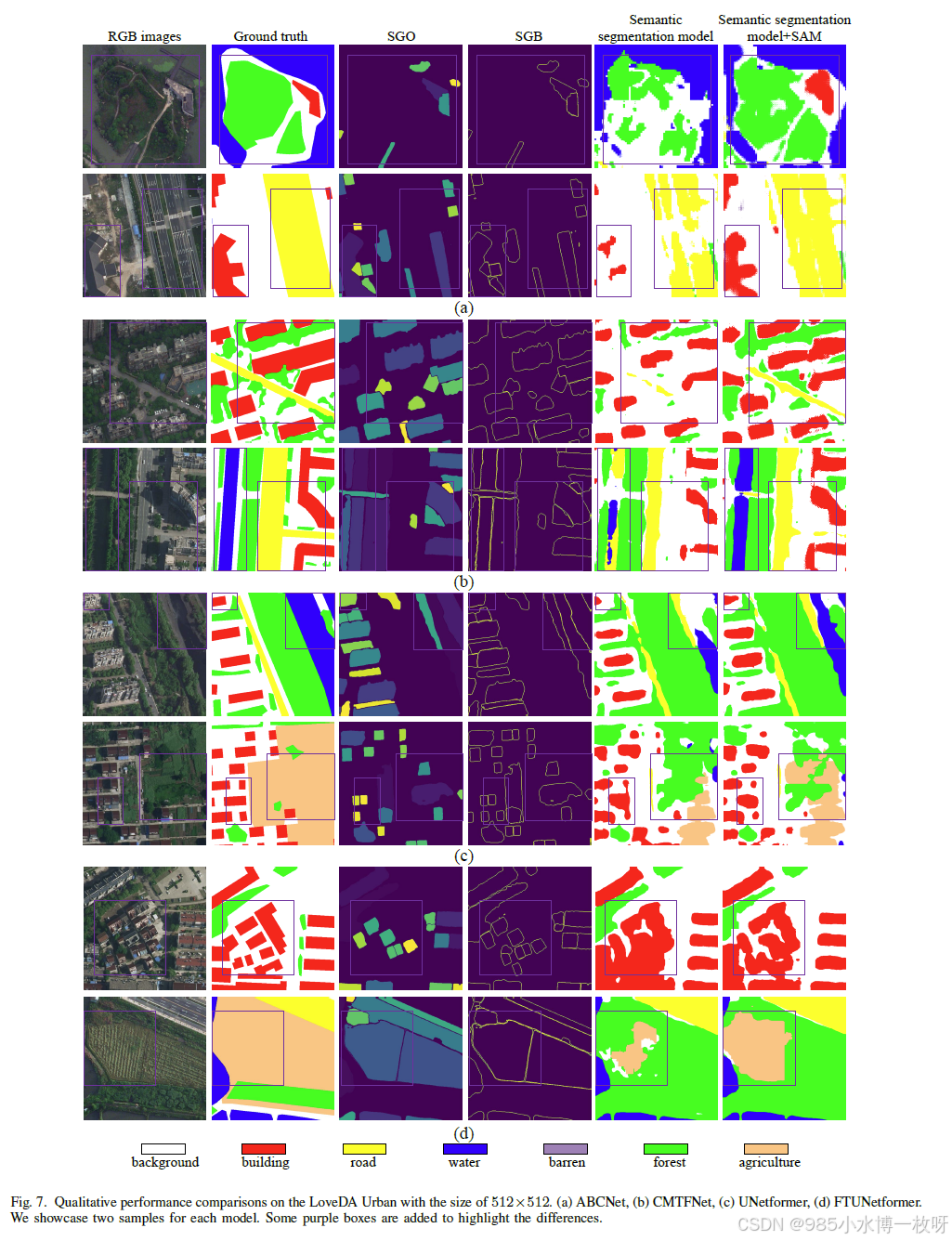
图 8 展示了 LoveDA Urban 数据集的可视化示例,所有子图中紫色框标出了感兴趣的区域。首先,该模型在建筑物识别上表现出更高的准确性,且在所有方法中均表现突出。此外,水体和农业目标的识别也更为完整。这些观察结果与表 II 中 mF1 和 mIoU 指标的提升密切吻合。
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议入口:https://ais.cn/u/mmmiUz



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











