回顾比较排序
相信阅读过前面5篇博文的童鞋们已经发现了“在排序的最终结果中,各元素的次序依赖于它们之间的比较”。于是乎,这类排序算法被统称为”比较排序“。
比较排序是通过一个单一且抽象的比较运算(比如“小于等于”)读取列表元素,而这个比较运算则决定了每两个元素中哪一个应该先出现在最终的排序列表中。
声明:下面通过在维基百科中找到的非常完美的图示来介绍一系列比较排序。
1插入排序
在该系列的【算法】1中我们便介绍了这个基本的算法,它的比较过程如下:
以下是用插入排序对30个元素的数组进行排序的动画:
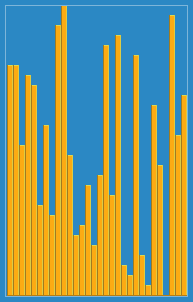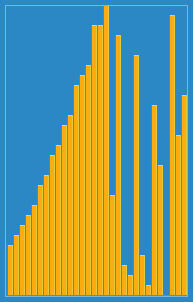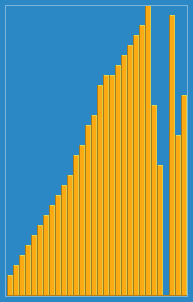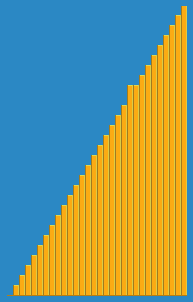
2选择排序
选择排序的比较过程如下:
其动画效果如下:

3归并排序
前面多次写到归并排序,它的比较过程如下:
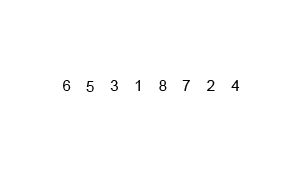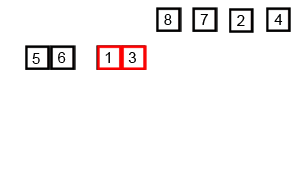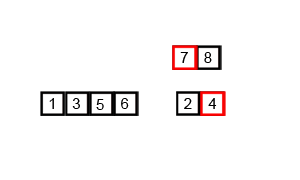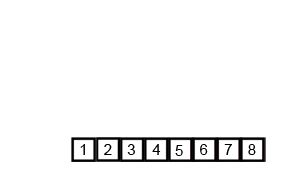
归并排序的动画如下:

4堆排序
在该系列的【算法】4中我们便介绍了快排,构建堆的过程如下:

堆排序的动画如下:
5快速排序
在该系列的【算法】5中我们便介绍了快排,它的比较过程如下:
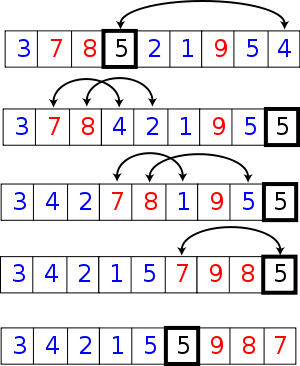
快速排序的动画如下:
另外一些比较排序
以下这些排序同样也是比较排序,但该系列中之前并未提到。
6Intro sort
该算法是一种混合排序算法,开始于快速排序,当递归深度超过基于正在排序的元素数目的水平时便切换到堆排序。它包含了这两种算法优良的部分,它实际的性能相当于在典型数据集上的快速排序和在最坏情况下的堆排序。由于它使用了两种比较排序,因而它也是一种比较排序。
6冒泡排序
大家应该多少都听过冒泡排序(也被称为下沉排序),它是一个非常基本的排序算法。反复地比较相邻的两个元素并适当的互换它们,如果列表中已经没有元素需要互换则表示该列表已经排好序了。(看到列表就想到半年前在学的Scheme,欢迎大家也去看看,我开了2个专栏来介绍它们)
上面的描述中已经体现了比较的过程,因而冒泡排序也是一个比较排序,较小的元素被称为“泡(Bubble)”,它将“浮”到列表的顶端。
尽管这个算法非常简单,但大家应该也听说了,它真的非常的慢。
冒泡排序的过程如下:
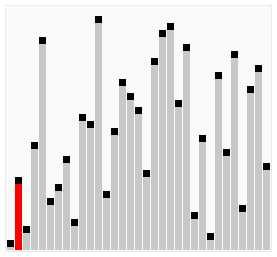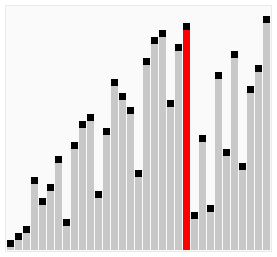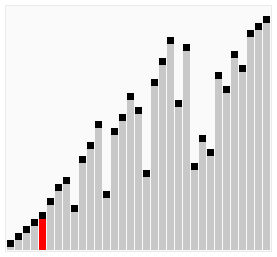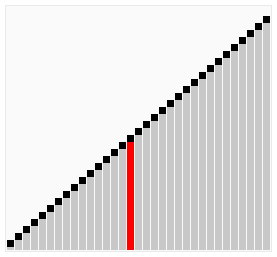
冒泡排序的动画演示:

其最好情况、最坏情况的运行时间分别是:
Θ(n)
、
Θ(n2)
。
7奇偶排序
奇偶排序和冒泡排序有很多类似的特点,它通过比较在列表中所有的单双号索引的相邻元素,如果有一对是错误排序(也就是前者比后者大),那么将它们交换,之后不断的重复这一步骤,直到整个列表排好序。
而鉴于此,它的最好情况、最坏情况的运行时间均和冒泡排序相同:
Θ(n)
、
Θ(n2)
。
奇偶排序的演示如下:

下面是C++中奇偶排序的示例:
<code class="hljs d has-numbering" style="display: block; padding: 0px; color: inherit; box-sizing: border-box; font-family: 'Source Code Pro', monospace;font-size:undefined; white-space: pre; border-top-left-radius: 0px; border-top-right-radius: 0px; border-bottom-right-radius: 0px; border-bottom-left-radius: 0px; word-wrap: normal; background: transparent;"><span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">template</span> <<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">class</span> T>
<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">void</span> OddEvenSort (T a[], <span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">int</span> n)
{
<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">for</span> (<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">int</span> i = <span class="hljs-number" style="color: rgb(0, 102, 102); box-sizing: border-box;">0</span> ; i < n ; i++)
{
<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">if</span> (i & <span class="hljs-number" style="color: rgb(0, 102, 102); box-sizing: border-box;">1</span>) <span class="hljs-comment" style="color: rgb(136, 0, 0); box-sizing: border-box;">// 'i' is odd</span>
{
<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">for</span> (<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">int</span> j = <span class="hljs-number" style="color: rgb(0, 102, 102); box-sizing: border-box;">2</span> ; j < n ; j += <span class="hljs-number" style="color: rgb(0, 102, 102); box-sizing: border-box;">2</span>)
{
<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">if</span> (a[j] < a[j-<span class="hljs-number" style="color: rgb(0, 102, 102); box-sizing: border-box;">1</span>])
swap (a[j-<span class="hljs-number" style="color: rgb(0, 102, 102); box-sizing: border-box;">1</span>], a[j]) ;
}
}
<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">else</span>
{
<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">for</span> (<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">int</span> j = <span class="hljs-number" style="color: rgb(0, 102, 102); box-sizing: border-box;">1</span> ; j < n ; j += <span class="hljs-number" style="color: rgb(0, 102, 102); box-sizing: border-box;">2</span>)
{
<span class="hljs-keyword" style="color: rgb(0, 0, 136); box-sizing: border-box;">if</span> (a[j] < a[j-<span class="hljs-number" style="color: rgb(0, 102, 102); box-sizing: border-box;">1</span>])
swap (a[j-<span class="hljs-number" style="color: rgb(0, 102, 102); box-sizing: border-box;">1</span>], a[j]) ;
}
}
}
}</code><ul class="pre-numbering" style="box-sizing: border-box; position: absolute; width: 50px; top: 0px; left: 0px; margin: 0px; padding: 6px 0px 40px; border-right-width: 1px; border-right-style: solid; border-right-color: rgb(221, 221, 221); list-style: none; text-align: right; background-color: rgb(238, 238, 238);"><li style="box-sizing: border-box; padding: 0px 5px;">1</li><li style="box-sizing: border-box; padding: 0px 5px;">2</li><li style="box-sizing: border-box; padding: 0px 5px;">3</li><li style="box-sizing: border-box; padding: 0px 5px;">4</li><li style="box-sizing: border-box; padding: 0px 5px;">5</li><li style="box-sizing: border-box; padding: 0px 5px;">6</li><li style="box-sizing: border-box; padding: 0px 5px;">7</li><li style="box-sizing: border-box; padding: 0px 5px;">8</li><li style="box-sizing: border-box; padding: 0px 5px;">9</li><li style="box-sizing: border-box; padding: 0px 5px;">10</li><li style="box-sizing: border-box; padding: 0px 5px;">11</li><li style="box-sizing: border-box; padding: 0px 5px;">12</li><li style="box-sizing: border-box; padding: 0px 5px;">13</li><li style="box-sizing: border-box; padding: 0px 5px;">14</li><li style="box-sizing: border-box; padding: 0px 5px;">15</li><li style="box-sizing: border-box; padding: 0px 5px;">16</li><li style="box-sizing: border-box; padding: 0px 5px;">17</li><li style="box-sizing: border-box; padding: 0px 5px;">18</li><li style="box-sizing: border-box; padding: 0px 5px;">19</li><li style="box-sizing: border-box; padding: 0px 5px;">20</li><li style="box-sizing: border-box; padding: 0px 5px;">21</li><li style="box-sizing: border-box; padding: 0px 5px;">22</li><li style="box-sizing: border-box; padding: 0px 5px;">23</li></ul>
8双向冒泡排序
双向冒泡排序也被称为鸡尾酒排序、鸡尾酒调酒器排序、摇床排序、涟漪排序、洗牌排序、班车排序等。(再多再华丽丽的名字也难以弥补它的低效)
和冒泡排序的区别在于它是在两个方向上遍历列表进行排序,虽然如此但并不能提高渐近性能,和插入排序比起来也没太多优势。
它的最好情况、最坏情况的运行时间均和冒泡排序相同:
Θ(n)
、
Θ(n2)
。
排序算法的下界
我们可以将排序操作进行得多块?
这取决于计算模型,模型简单来说就是那些你被允许的操作。
9决策树
决策树(decision tree)是一棵完全二叉树,它可以表示在给定输入规模情况下,其一特定排序算法对所有元素的比较操作。其中的控制、数据移动等其他操作都被忽略了。
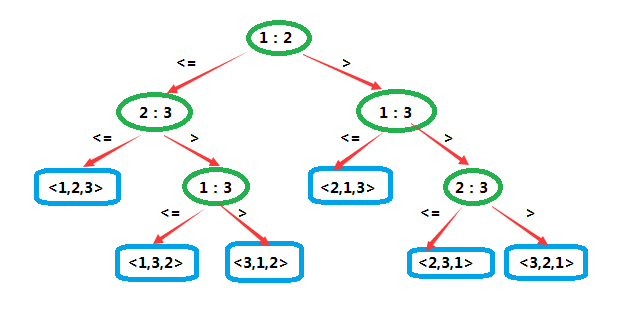
这是一棵作用于3个元素时的插入排序的决策树。标记为
i:j
的内部结点表示
ai
和
aj
之间的比较。
由于它作用于3个元素,因此共有
A33=6
种可能的排列。也正因此,它并不具有一般性。
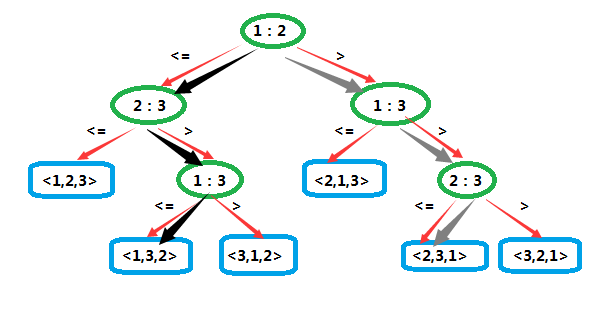
而对序列
<a1=7,a2=2,a3=5>
和序列
<a1=5,a2=9,a3=6>
进行排序时所做的决策已经由灰色和黑色粗箭头指出了。
决策树排序的下界
如果决策树是针对n个元素排序,那么它的高度至少是
nlgn
。
在最坏情况下,任何比较排序算法都需要做
Ω(nlgn)
次比较。
因为输入数据的
Ann
种可能的排列都是叶结点,所以
Ann≤l
,由于在一棵高位
h
的二叉树中,叶结点的数目不多于
2h
,所以有:
n!≤l≤2h
对两边取对数:
=>
lg2h≥lgn!
=>
lg2h=hlg2≥lgn!
又因为:
lg2<1
所以:
n≥lgn!=Ω(nlgn)
因为堆排序和归并排序的运行时间上界均为
O(nlgn)
,因此它们都是渐近最优的比较排序算法。
























 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









