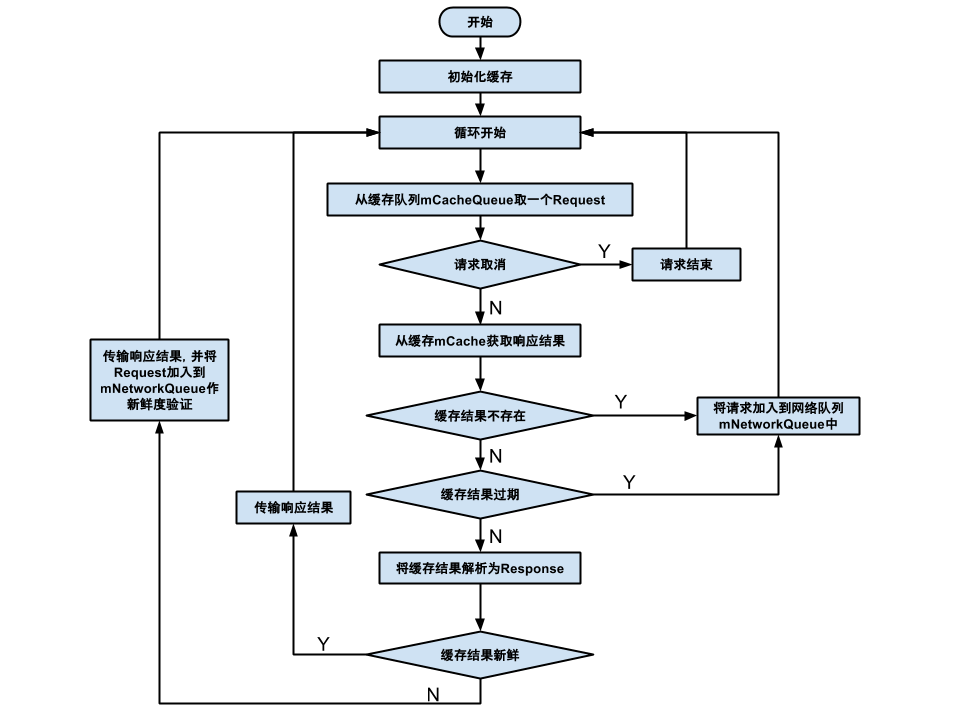
首先研究一下Volley的磁盘缓存原理,它主要包括以下几个类 CacheDispatcher缓存的具体执行类,继承ThreadDiskBasedCache 缓存核心类,基于Disk的缓存实现类Cache.Entry 真正HTTP请求的缓存实体DiskBasedCache.CacheHeader和Cache.Entry一样,就是不存储响应体,只存储了缓存的大小DiskBasedCache.CountingInputStream 添加了记录字节功能的流,继承FilterInputStream CacheDispatcher
在RequestQueue的run方法中启动了CacheDispatcher的start方法,我们先看一下它的成员变量,在看CacheDispatcher的run方法(着重关注注释) /** 可以走Disk缓存的request请求队列. */
private final BlockingQueue<Request<?>> mCacheQueue;
/** 需要走网络的request请求队列. */
private final BlockingQueue<Request<?>> mNetworkQueue;
/** DiskBasedCache缓存实现类. */
private final Cache mCache;
/** 网络请求结果传递类. */
private final ResponseDelivery mDelivery;
/** 用来停止线程的标志位. */
private volatile boolean mQuit = false ; @Override
public void run () {
android.os.Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
mCache.initialize();
while (true ) {
try {
final Request<?> request = mCacheQueue.take();
if (request.isCanceled()) {
request.finish("cache-discard-canceled" );
continue ;
}
Cache.Entry entry = mCache.get(request.getCacheKey());
if (entry == null ) {
mNetworkQueue.put(request);
continue ;
}
if (entry.isExpired()) {
request.setCacheEntry(entry);
mNetworkQueue.put(request);
continue ;
}
Response<?> response = request.parseNetworkResponse(new NetworkResponse(entry.data,
entry.responseHeaders));
if (!entry.refreshNeeded()) {
mDelivery.postResponse(request, response);
} else {
request.setCacheEntry(entry);
response.intermediate = true ;
mDelivery.postResponse(request, response, new Runnable() {
@Override
public void run () {
try {
mNetworkQueue.put(request);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
} catch (InterruptedException e) {
e.printStackTrace();
if (mQuit) {
return ;
}
}
}
}上面的注释已经说的很清楚了,请对照下面的流程图一起理解 class Entry {
/** HTTP响应体. */
public byte [] data;
/** HTTP响应首部中用于缓存新鲜度验证的ETag. */
public String etag
/** HTTP响应时间. */
public long serverDate;
/** 缓存内容最后一次修改的时间. */
public long lastModified;
/** Request的缓存过期时间. */
public long ttl;
/** Request的缓存新鲜时间. */
public long softTtl;
/** HTTP响应Headers. */
public Map<String, String> responseHeaders = Collections.emptyMap();
/** 判断缓存内容是否过期. */
public boolean isExpired () {
return this .ttl < System.currentTimeMillis();
}
/** 判断缓存是否新鲜,不新鲜的缓存需要发到服务端做新鲜度的检测. */
public boolean refreshNeeded () {
return this .softTtl < System.currentTimeMillis();
}
}注意,DiskBasedCache.CacheHeader和它的不同在于它不存储响应体,只存储了缓存的大小 它是一个添加了记录读取字节数的辅助类,看它的read函数 @Override
public int read () throws IOException {
int result = super .read();
if (result != -1 ) {
bytesRead ++;
}
return result;
}在看一下writeInt()函数就一切都明白了,作者封装了一下读取和写入的函数,让它一个字节一个字节的读或者写,为了配合CountingInputStream记录读取的字节 private static void writeInt (OutputStream os, int n) throws IOException {
os.write((n) & 0xff );
os.write((n >> 8 ) & 0xff );
os.write((n >> 16 ) & 0xff );
os.write((n >> 24 ) & 0xff );
}缓存的核心DiskBasedCache
它是缓存的核心类,基于Disk实现,我们先分析一下他的成员变量 /** 默认硬盘最大的缓存空间(5M). */
private static final int DEFAULT_DISK_USAGE_BYTES = 5 * 1024 * 1024 ;
/** 标记缓存起始的MAGIC_NUMBER. */
private static final int CACHE_MAGIC = 0x20150306 ;
/**
* High water mark percentage for the cache.
*/
private static final float HYSTERESIS_FACTOR = 0.9 f;
/**
* Map of the Key, CacheHeaders pairs.
* accessOrder为true很关键
*/
private final Map<String, CacheHeader> mEntries =
new LinkedHashMap<String, CacheHeader>(16 , 0.75 f, true );
/** 目前使用的缓存字节数. */
private long mTotalSize = 0 ;
/** 硬盘缓存目录. */
private final File mRootDirectory;
/** 硬盘缓存最大容量(默认5M). */
private final int mMaxCacheSizeInBytes;请注意这句代码,它的第三个参数很重要,辅助完善LRU算法,请参考 private final Map<String, CacheHeader> mEntries =
new LinkedHashMap<String, CacheHeader>(16 , 0.75 f, true );初始化逻辑initialize()函数
initialize()函数的作用是遍历Disk缓存系统,将缓存文件读出来分为key:url和value:CacheHeader存入到Map中 @Override
public void initialize () {
if (!mRootDirectory.exists() && !mRootDirectory.mkdirs()) {
return ;
}
File[] files = mRootDirectory.listFiles();
if (files == null ) {
return ;
}
for (File file : files) {
BufferedInputStream fis = null ;
try {
fis = new BufferedInputStream(new FileInputStream(file));
CacheHeader entry = CacheHeader.readHeader(fis);
entry.size = file.length();
putEntry(entry.key, entry);
}catch (IOException e) {
file.delete();
e.printStackTrace();
}finally {
if (fis != null ) {
try {
fis.close();
} catch (IOException ignored) {
}
}
}
}
}看一下上述函数中的CacheHeader entry = CacheHeader.readHeader(fis);这个函数的作用就是按照写入的顺序把相应的数据读出来,其实就是对象的反序列化 public static CacheHeader readHeader (InputStream is) throws IOException {
CacheHeader entry = new CacheHeader();
int magic = readInt(is);
if (magic != CACHE_MAGIC) {
throw new IOException();
}
entry.key = readString(is);
entry.etag = readString(is);
if (entry.etag.equals("" )) {
entry.etag = null ;
}
entry.serverDate = readLong(is);
entry.lastModified = readLong(is);
entry.ttl = readLong(is);
entry.softTtl = readLong(is);
entry.responseHeaders = readStringStringMap(is);
return entry;
再接着看一下putEntry(entry.key, entry);这个函数,将key和value存储到内存中,并更新总字节数(判断缓存是否满) private void putEntry (String key, CacheHeader entry) {
if (!mEntries.containsKey(key)) {
mTotalSize += entry.size;
} else {
CacheHeader oldEntry = mEntries.get(key);
mTotalSize += (entry.size - oldEntry.size);
}
mEntries.put(key, entry);
}pruneIfNeeded
这个函数很重要,当缓存满时删除最久未使用的缓存,既是队列前端的缓存,函数很简单,看完就懂了 /** Disk缓存替换更新机制. */
private void pruneIfNeeded (int neededSpace) {
if ((mTotalSize + neededSpace) < mMaxCacheSizeInBytes) {
return ;
}
Iterator<Map.Entry<String, CacheHeader>> iterator = mEntries.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, CacheHeader> entry = iterator.next();
CacheHeader e = entry.getValue();
boolean deleted = getFileForKey(e.key).delete();
if (deleted) {
mTotalSize -= e.size;
}
iterator.remove();
if ((mTotalSize + neededSpace) < mMaxCacheSizeInBytes * HYSTERESIS_FACTOR) {
break ;
}
}
}get和put
接下来我们看取出缓存和设置缓存的函数,它的作用是从mEntries中获取缓存并构造Entry,为什么要构造?注意之前我们说过CacheHeader没有响应体的内容,所以我们需要构造一个有响应体的类,看以下注释既可明白
想一想为什么要有一个看无用的DiskBasedCache.CacheHeader类,因为为了避免在内存中存储过多的东西,用的时候在临时构造(从文件中拿响应体的内容)
public synchronized Entry get (String key) {
CacheHeader entry = mEntries.get(key);
if (entry == null ) {
return null ;
}
File file = getFileForKey(key);
CountingInputStream cis = null ;
try {
cis = new CountingInputStream(new BufferedInputStream(new FileInputStream(file)));
CacheHeader.readHeader(cis);
byte [] data = streamToBytes(cis, (int )(file.length() - cis.bytesRead));
return entry.toCacheEntry(data);
} catch (IOException e) {
remove(key);
return null ;
} finally {
if (cis != null ) {
try {
cis.close();
} catch (IOException ignored) {
}
}
}
} @Override
public synchronized void put (String key, Entry entry) {
pruneIfNeeded(entry.data.length);
File file = getFileForKey(key);
try {
BufferedOutputStream fos = new BufferedOutputStream(new FileOutputStream(file));
CacheHeader e = new CacheHeader(key, entry);
boolean success = e.writeHeader(fos);
if (!success) {
fos.close();
throw new IOException();
}
fos.write(entry.data);
fos.close();
putEntry(key, e);
return ;
} catch (IOException e) {
e.printStackTrace();
}
file.delete();
}else
还有一些辅助函数,代码特别简单,并且我已经做了充分的注释 /** 清空缓存内容. */
@Override
public synchronized void clear () {
File[] files = mRootDirectory.listFiles();
if (files != null ) {
for (File file : files) {
file.delete();
}
}
mEntries.clear();
mTotalSize = 0 ;
}
/** 标记指定的cache过期. */
@Override
public synchronized void invalidate (String key, boolean fullExpire) {
Entry entry = get(key);
if (entry != null ) {
entry.softTtl = 0 ;
if (fullExpire) {
entry.ttl = 0 ;
}
put(key, entry);
}
}
/** 获取存储当前key对应value的文件句柄. */
private File getFileForKey (String key) {
return new File(mRootDirectory, getFilenameForKey(key));
}
/** 根据key的hash值生成对应的存储文件名称. */
private String getFilenameForKey (String key) {
int firstHalfLength = key.length() / 2 ;
String localFilename = String.valueOf(key.substring(0 , firstHalfLength).hashCode());
localFilename += String.valueOf(key.substring(firstHalfLength).hashCode());
return localFilename;
}
@Override
public synchronized void remove (String key) {
boolean deleted = getFileForKey(key).delete();
removeEntry(key);
if (!deleted) {
Log.e("Volley" , "没能删除key=" + key + ", 文件名=" + getFilenameForKey(key) + "缓存." );
}
}
/** 从Map对象中删除key对应的键值对. */
private void removeEntry (String key) {
CacheHeader entry = mEntries.get(key);
if (entry != null ) {
mTotalSize -= entry.size;
mEntries.remove(key);
}
}思考
LRU算法一定合理吗?如何增大缓存的命中率
因为我们是存储了缓存的过期时间的public long ttl,在删除缓存的时候pruneIfNeeded直接从队列前端删除真的好吗?有没有更好的方法?当然有,鉴于缓存的过期时间,我们可以以这个为基点,遍历一遍,优先删除快过期的缓存,或者我们存储时就按缓存过期时间存储,这样可能会让Volley有更好的表现 文件名重复问题
文件名会重复吗?答案是会的,因为不同的字符串也有可能产生相同的hash值见这边文章 ,所以Volley采用分割计算两次哈希值的方法减小重复的几率 /** 根据key的hash值生成对应的存储文件名称. */
private String getFilenameForKey (String key) {
int firstHalfLength = key.length() / 2 ;
String localFilename = String.valueOf(key.substring(0 , firstHalfLength).hashCode());
localFilename += String.valueOf(key.substring(firstHalfLength).hashCode());
return localFilename;
}























 6075
6075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









