







 本文介绍了图的几种常见存储结构,包括邻接矩阵、邻接表、十字链表和边集数组,详细讲解了每种结构的原理、特点和适用场景,并提供了相应的数据结构定义和构建方法。邻接矩阵适用于稠密图,邻接表和十字链表在稀疏图中更节省空间,边集数组则侧重于边的集合操作。
本文介绍了图的几种常见存储结构,包括邻接矩阵、邻接表、十字链表和边集数组,详细讲解了每种结构的原理、特点和适用场景,并提供了相应的数据结构定义和构建方法。邻接矩阵适用于稠密图,邻接表和十字链表在稀疏图中更节省空间,边集数组则侧重于边的集合操作。
1 概述
图(Graph)是由顶点的有穷非空集合,和顶点之间边的集合组成,通常表示为:G(V, E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
线性表中,每个数据元素只有一个直接前驱和一个直接后继;树中,每一层上的数据元素可能和下一层的多个数据元素相连,但只能和上一层的一个数据元素相连;图则不一样,结点之间的关系可以是任意的,图中任意两个元素都可以相连。
对于图的定义,还有以下需要注意的点:
(1) 线性表的数据元素称为元素,树中的数据元素称为结点,而图中的数据元素被称为顶点(Vertex);
(2) 线性表可以没有数据元素,称为空表;树可以没有结点,称为空树;但在图中,不允许没有顶点;
(3) 线性表中,相邻的数据元素之间具有线性关系;树中,相邻两层的结点有层次关系;但在图中,任意两个顶点之间都可能有关系,顶点之间的逻辑关系用边来表示,边集可以是空的;
1.1 无向和有向
若顶点Vi到Vj之间的边没有方向,则称这条边为无向边(Edge),如果图中的所有边都是无向边,则该图称为无向图(Undirected graphs)。
下图即为一个无向图:
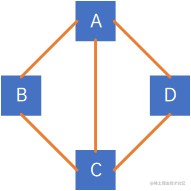
由于是无方向的,因此连接顶点A与D的边,可以表示成(A,D),也可以表示成(D,A)。
顶点集合V={A,B,C,D},边集合也没有顺序,可以表示为E={(A,B), (B,C), (C,D), (D, A), (A,C)},当然,因为是无序的,所以边集合里面的字母和边集也可以任意调换顺序。
该图则表示为G=({A,B,C,D}, {(A,B), (B,C), (C,D), (D, A), (A,C)})。
若顶点Vi到Vj之间的边有方向,则称这条边为有向边(Edge),也称为弧(Arc),如果图中的所有边都是有向边,则该图称为有向图(Directed graphs)。
下图即为一个有向图:
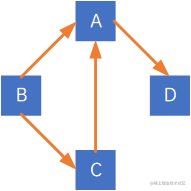
有向边的箭头尾部的顶点称为弧尾,箭头头部的顶点称为弧头,有向边的边集只能写成<弧尾,弧头>,一定要用尖括号,且顺序不能乱,如上图,顶点A和顶点D之间的边是有向边,A是弧尾,D是弧头,因此边集只能表示为<A,D>。
顶点集合V={A,B,C,D},边集合则为E={<A,D>, <B,A>, <C,A>, <B,C>},因此上图表示为G=({A,B,C,D}, {<A,D>, <B,A>, <C,A>, <B,C>})。
1.2 各种图的定义
在图中,若不存在顶点到其他自身的边,且同一条边不重复出现,则称这样的图为简单图。
以下两个图,则不为简单图:
在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图,含有n个顶点的无向完全图有n∗(n−1)÷2n * (n-1) \div 2n∗(n−1)÷2条边,下图为一个无向完全图:
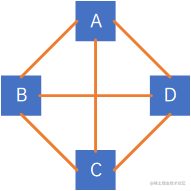
因此,对于具有n个结点和e条边的无向图,0 ≤ e ≤ n * (n - 1) /2。
在有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为有向完全图,含有n个顶点的有向完全图有n∗(n−1)n \ast (n-1)n∗(n−1)条边,如下图所示:
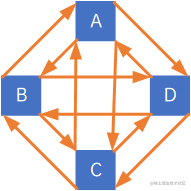
因此,对于具有n个结点和e条边的有向图,0 ≤ e ≤ n * (n - 1)。
有很少条边或弧的图称为稀疏图,反之称为稠密图。
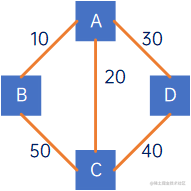
有些边或弧具有与它相关的数字,这种与图的边或弧相关的数叫权(Weight),这种带权的图称为网(Network),如下图所示:
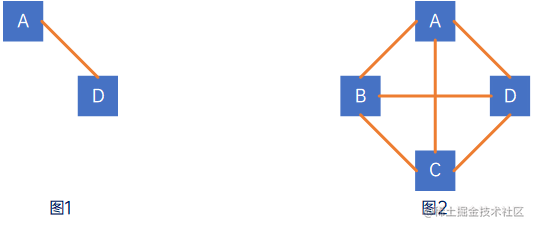
假设有两个图G=(V,E)和G’=(V’,E’),如果V′⊆VV' \subseteq VV′⊆V且E′⊆EE' \subseteq EE′⊆E,则称图G’为图G的子图(Subgraph),如下,图1为图2的子图:
1.3 图的顶点与边间的关系
对于无向图,被一条边连接的两个顶点互为邻接点(Adjacent),连接这两个顶点的边则依附(incident)于这两个顶点,或者称边与这两个顶点相关联,与顶点相关联的边的数量称为顶点的度(Degree),一般计为TD(v),而边的数量,其实就是各顶点度数和的一半(多出的一半是因为重复两次记数),即e=12∑i=1nTD(vi)e= \frac{1}{2} \sum^{n}_{i=1}TD(v_i)e=21∑i=1nTD(vi)。
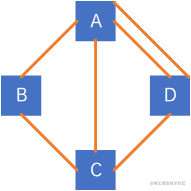
以下图为例:
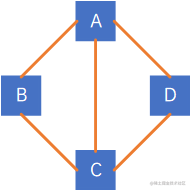
顶点A和B互为邻接点,边(A,B)依附于顶点A和顶点B,边(A,B)与顶点A相关联也与顶点B相关联,A的度为3,B的度为2,C的度为3,D的度为2,图的边E=(3+2+3+2)÷2=5E=(3+2+3+2) \div 2 = 5E=(3+2+3+2)÷2=5。
对于有向图,如果存在弧<v,v’>,则称顶点v邻接到v’,顶点v’邻接自v,弧<v,v’>与顶点v和v’相关联,以顶点v为头的弧的数目称为v的入度(InDegree),记为ID;以顶点v为尾的弧的数目称为v的出度(OutDegree),记为OD,顶点v的度为TD(v)=ID(v)+OD(v)TD(v)=ID(v)+OD(v)TD(v)=ID(v)+OD(v),有向图的边的数量与各顶点的入度和相等,也与各顶点的出度和相等,即e=∑i−1nID(vi)=∑i−1nOD(vi)e= \sum^{n}_{i-1}ID(v_i) = \sum^{n}_{i-1}OD(v_i)e=∑i−1nID(vi)=∑i−1nOD(vi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









