







1 HashTable数据结构
HashTable又称为字典、散列表或映射(map),是一种用于保存键值对的抽象数据结构。在字典中,一个键和一个值关联,这些关联的键和值就被称为键值对。字典中的每个键都不能重复。
2 哈希表
哈希表的思想主要源于数组下标随机访问数据且时间复杂度为O(1)的特点,可以说它是数组的一种扩展。假设为了方便记录学生的信息,要求可以按照学号快速找到某个学生的信息,这时可以取学号的自增序号部分,用学号的后三位作为数组的下标,把学生相应的信息存储到对应的存储空间内。哈希表存储示意图如下:
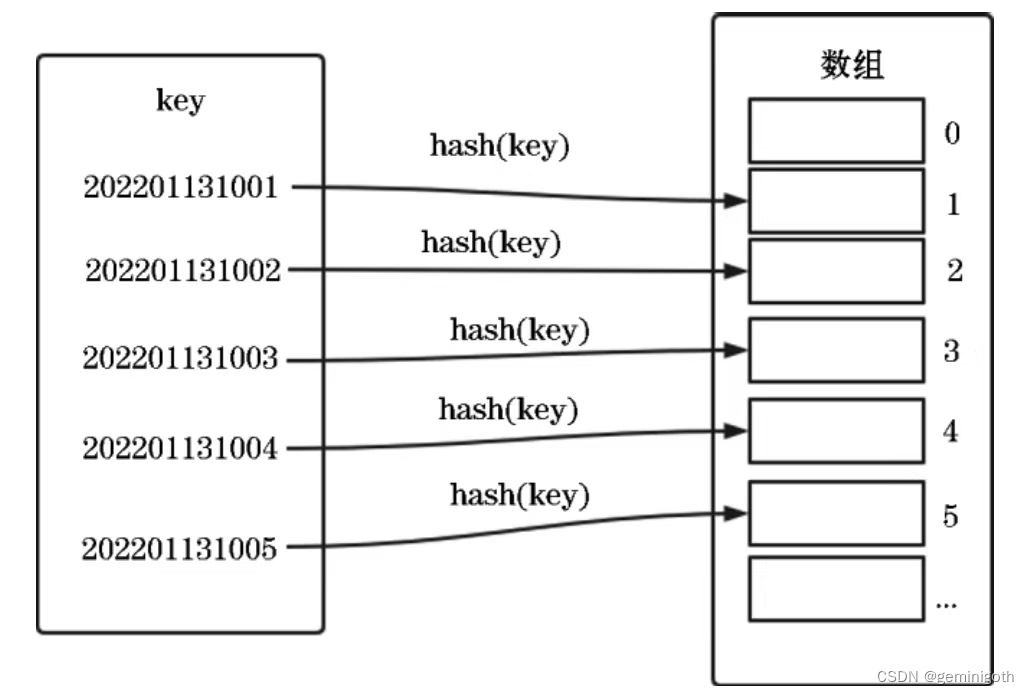
这样在查询一个学号的具体位置时,只需要把学号哈希后的值作为具体的下标,实现时间复杂度为O(1)的查询特性。
2.1 哈希冲突
哈希冲突的意思是key1 不等于key2,但是hash(key1) = hash(key2)的情况,如下图
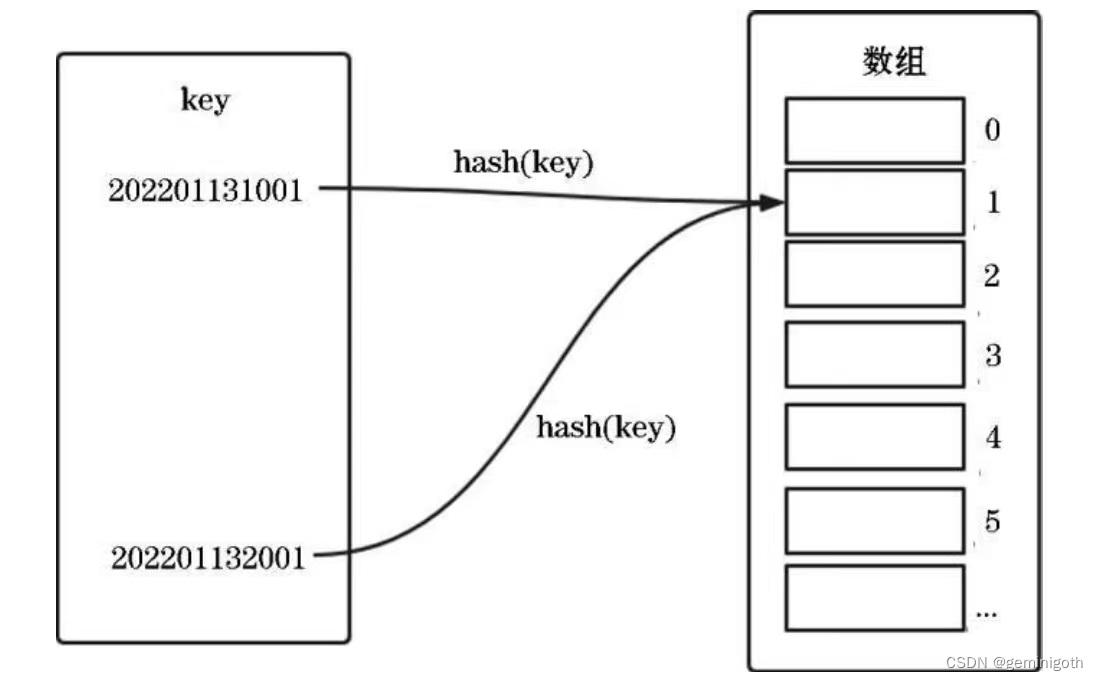
如果有100个key,而数组的下标只有50个,那么在强大的算法也不可避免哈希冲突。
2.2 链表法
链表法是一种比较常用的解决哈希冲突的办法,Redis就是使用链表法解决哈希冲突的。原理是:遇到哈希冲突的时候,在原地址新建一个空间,然后以链表节点的形式插入该空间。插入的时候,只需要通过哈希函数计算出对应的哈希槽位(slot),将其插入对应的链表中即可,链表法数据结构如下图:

链表要存储指针,所以存储比较小的对象比较消耗内存,而且链表中节点所占用的内存空间在内存中是零散分布、非连续的,所以不利于CPU缓存,这对于执行效率会有一定的影响。
3 Redis字典的实现
Redis字典主要通过三部分来实现:字典、哈希表和哈希表节点。哈希表中的table字段存放哈希表节点,哈希表节点存储对应的键值对。哈希字典存储示意图如下:
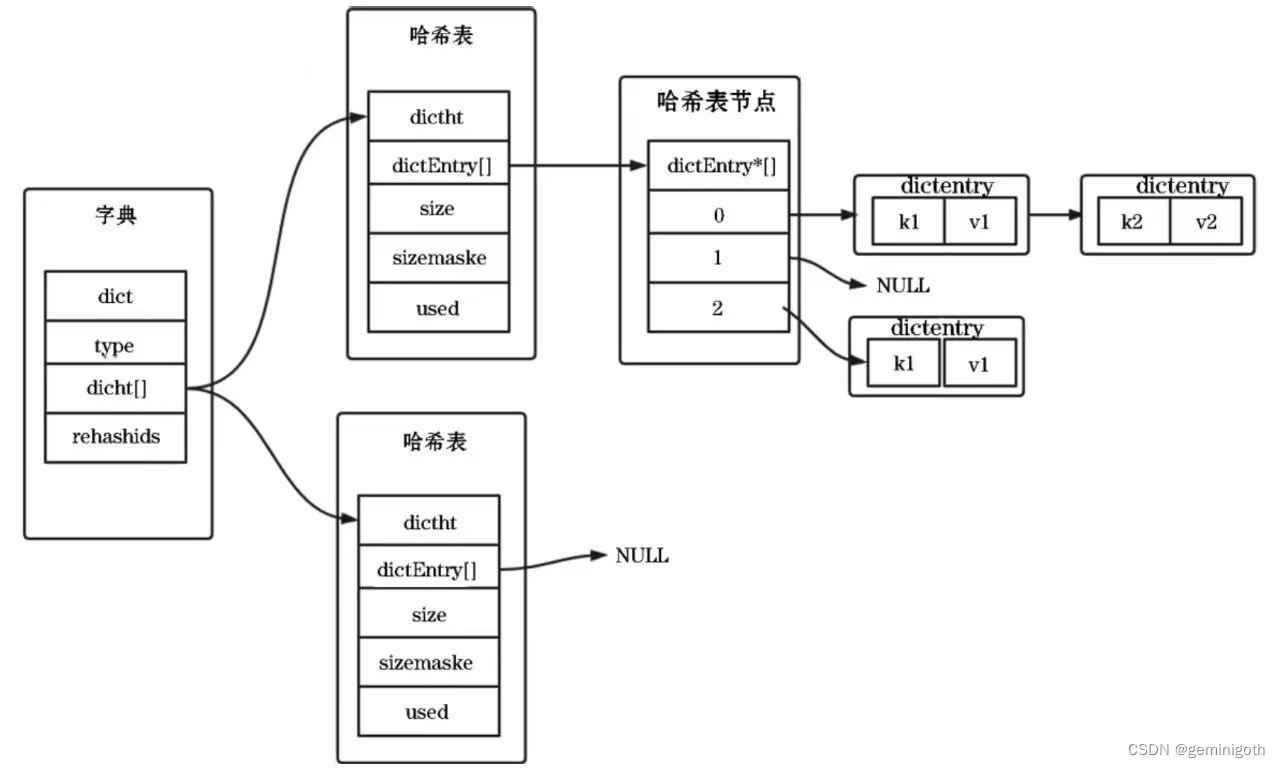
字典(dict)结构源码如下:
typedef struct dict {
//哈希表数组
dictEntry **table;
dictType *type;
//哈希表的大小
unsigned long size;
//哈希表大小是掩码,计算索引值
unsigned long sizemask;
unsigned long used;
void *privdata;
} dict;
typedef struct dictIterator {
//哈希表
dict *ht;
int index;
dictEntry *entry, *nextEntry;
} dictIterator;type是一个指向dictType结构的指针,每个dictType结构保存了一系列用于操作特定类型键值对的函数,Redis为用途不同的字典设置了不同类型的特定函数。privdata属性保存了需要传给那些特点函数的可选参数。这两个属性都是针对不同类型的键值对来创建多态字典而设置的。
ht属性是一个具有两个数据项的数组,数组中的每一项都是一个dicths哈希表。
table是一个数组,数组中的每个元素都是一个指向dictEntry结构的指针,而每个dictEntry结构保存着一个键值对。
size记录了哈希表的大小,同样也是table数组的大小。
used记录了哈希表目前已有键值对的数量
sizemask 这个属性值和哈希值一起决定了一个键应该被放到table数组的哪个下标执行的位置。
dictType源码如下:
typedef struct dictType {
//计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
//复制键的函数
void *(*keyDup)(void *privdata, const void *key);
//复制值的函数
void *(*valDup)(void *privdata, const void *obj);
//比较键大小的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
//销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
//销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;哈希表节点(dictEntry)源码如下:
typedef struct dictEntry {
//键
void *key;
//值
void *val;
//指向下一个哈希表节点
struct dictEntry *next;
} dictEntry;key保存着键值对中的键、val保存键对应的值。next属性是指向另一个哈希表节点的指针,可以将多个哈希值相同的键值对连接在一起形成链表,从而解决哈希冲突的问题。
3.1 Redis 再哈希操作
对于哈希表来说,负载因子表中实际元素个数(哈希表长度)过大或过小都不好:负载因子过大,哈希表性能下降;负载因子过小,内存不能合理使用,造成浪费。因此,需要保证负载因子维持在一个合理的范围内。
随着系统不断对数据进行操作,哈希表中保存的键值对也会增加或减少。为了保证负载因子维持在一个合理的范围内,当哈希表内的键值对过多或过少时,则需要定期进行再哈希(rehash)操作,以提升哈希表的性能或节省内存。
3.2扩容
扩容的两个条件:
(1)当哈希表中元素的个数大于第一维数组的长度时(负载因子 > 1)
(2)允许扩容dict_can_resize(没有写时复制的时候)或者负载因子大于指定阈值(dict_force_resize_ratio)时(默认为5)。
在字典(dict)中设两个哈希表:ht[0]和ht[1]。对于字典本身而言,存在两种状态:一种是正常状态,另一种是rehash(再哈希)状态。正常状态指的是不存在rehash过程的状态,这种状态下字典内部只使用ht[0]。当判断需要扩展内存时,Redis会开始扩容(expand),扩展ht[1]的内存,使得ht[1]的容量足以容纳当前的数据,之后字典就会进入rehash状态。在rehash状态下,Redis会间断地把[0]的数据再哈希到ht[1]中,此时再释放掉ht[0]的内存,将ht[0]重定向到ht[1]的内存空间上,并返回正常状态,这样就完成一次动态扩展的过程。在这个过程中,需要注意以下几点:
1、Redis将数据从ht[0]再哈希到ht[1]过程中,对于再哈希而言,如果哈希表当前大小为2GB,要想扩容为原来的两倍,就需要对2GB的数据重新计算哈希值,并且从原来的哈希表迁移到新的哈希表。这种情况非常耗时。为了解决一次性扩容耗时过多的问题,可以将扩容操作穿插在新增数据的过程中分批完成。当负载因子到达阈值后,只申请新空间,并不是一次性将旧的的数据迁移到新的哈希表中。当有新数据写入时,将新数据插入到新哈希表的同时,在从旧哈希表取出一个数据放入新哈希表中。此后每次操作(增删改查)哈希表时都重复这个过程。经过多次操作后,旧哈希表中的数据就会慢慢全部迁移到新哈希表中,避免一次全部迁移带来的耗时问题。如果没有后续命令来出发这个迁移,Redis还会在任务中定时对字典进行主动迁移。
Redis为了解决这个问题采用渐进式再哈希的方式,过程如下
1.1、为ht[1]分配空间,让字典同时拥有ht[0]、ht[1]两个哈希表。
1.2、在字典中维持一个下标计数器(rehashidx),并将它的只设置为0,表示再哈希正式开始。
1.3、再哈希进行期间,每次对字典执行增删改查操作时,程序除了执行指定的操作外,还会顺带经ht[0]的rehashidx下标指定的所有键值对重新哈希到ht[1],当本次再哈希完成后,程序将rehashidx属性的值增1。
1.4、随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被再哈希到ht[1],这是程序将rehashidx属性的值设为-1,表示再哈希已全部完成。
2、在再哈希状态下,字典的基本操作将于正常状态下不同。在插入操作时,正常状态下数据会插入ht[0],而再哈希状态下会插入ht[1]。在执行查找和删除操作时,正常状态下只涉及ht[0],而再哈希状态下则涉及ht[0]和ht[1]。
3、扩容期间。已用的数据项大于等于ht[0]的容量时,扩容的容量为与已用数据项最近的2的n次方数。例如,ht[0].used=3,则ht[1] = 8。
4、如果在rehash状态下又出现需要扩容的情况,则系统报错。这种情况很难出现,因为在rehash状态下每进行一次基本操作,都会顺带着进行一次数据迁移,基本操作的次数多了,数据迁移的速度也会加快。
扩容的源码如下:
/* 字典扩容 */
static int _dictExpandIfNeeded(dict *ht) {
/* 正在进行再哈希,直接返回 */
if (ht->size == 0)
return dictExpand(ht, DICT_HT_INITIAL_SIZE);
/* 如果哈希使用的元素等于哈希的长度,那么扩容2倍*/
if (ht->used == ht->size)
return dictExpand(ht, ht->size*2);
return DICT_OK;
}static int dictExpand(dict *ht, unsigned long size) {
//构建一个新的字典
dict n;
unsigned long realsize = _dictNextPower(size), i;
/* 如果字典的元素超过字典所允许的大小,返回错误 */
if (ht->used > size)
return DICT_ERR;
//字典初始化
_dictInit(&n, ht->type, ht->privdata);
n.size = realsize;
n.sizemask = realsize-1;
n.table = calloc(realsize,sizeof(dictEntry*));
/* 数据从旧的hashtable迁移到新的hashtable
* 如果旧的hashtable为空,那么dictExpand方法只会创建一个新的hashtable
*/
n.used = ht->used;
for (i = 0; i < ht->size && ht->used > 0; i++) {
dictEntry *he, *nextHe;
if (ht->table[i] == NULL) continue;
/* 遍历每个槽位的entry */
he = ht->table[i];
while(he) {
unsigned int h;
nextHe = he->next;
/*获取新元素的下标 */
h = dictHashKey(ht, he->key) & n.sizemask;
he->next = n.table[h];
n.table[h] = he;
ht->used--;
/*指向下一个元素 */
he = nextHe;
}
}
assert(ht->used == 0);
free(ht->table);
*ht = n;
return DICT_OK;
}数据定时迁移的源码如下:
void databasesCron(void) {
/* 如果再哈希状态下 */
if (server.activerehashing) {
for (j = 0; j < dbs_per_call; j++) {
int work_done = incrementallyRehash(rehash_db);
if (work_done) {
/* 如果此时已经做了一些迁移,会停在这里,
* 在下次循环中做更多迁移
*/
break;
} else {
/* 如果不再需要再哈希,下次再试 */
rehash_db++;
rehash_db %= server.dbnum;
}
}
}
}
}//如果迭代器数量等于0时,才能进行1步再哈希
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
int dictRehash(dict *d, int n) {
//要访问的最大存储桶数
int empty_visits = n*10;
unsigned long s0 = d->ht[0].size;
unsigned long s1 = d->ht[1].size;
if (dict_can_resize == DICT_RESIZE_FORBID || !dictIsRehashing(d)) return 0;
if (dict_can_resize == DICT_RESIZE_AVOID &&
((s1 > s0 && s1 / s0 < dict_force_resize_ratio) ||
(s1 < s0 && s0 / s1 < dict_force_resize_ratio)))
{
return 0;
}
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* 分为N步,而且ht[0]上还有没迁移的节点 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
//将rehashidx移动到ht[0]有节点的下标
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
//ht[0]下标为rehashidx,得到该节点的地址
de = d->ht[0].table[d->rehashidx];
/* 将ht[0]表中每次找到的非空桶中的链表复制到ht[1]中 */
while(de) {
uint64_t h;
nextde = de->next;
/* 获取新hash table的索引 */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
//迁移后,将该下标的指针置为空
d->ht[0].table[d->rehashidx] = NULL;
//rehashidx 自增1
d->rehashidx++;
}
/* 如果ht[0]上已经没有节点,则迁移完成 */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* 否则还有节点等待迁移 */
return 1;
}扩容示意图如下:

3.3 缩容
判断当前的容量是否带达到最低阈值,Redis会对哈希表进行缩容来减少哈希表的第一维数组占用的内容空间。缩容的条件是元素个数低于数组长度的10%,达到了则调用dictResize函数进行缩容,缩容后的容量实质为已占有内容空间的最小的n次方整数,缩容操作和扩容操作的实质差不多,最后都调用了dictExpand函数,之后的操作和扩容相同。
缩容的源代码如下:
int dictResize(dict *d)
{
unsigned long minimal;
//如果dict_can_resize是0,表示不能进行再哈希或正在进行再哈希,并返回错误标志DICT_ERR
if (dict_can_resize != DICT_RESIZE_ENABLE || dictIsRehashing(d)) return DICT_ERR;
//获得已有节点的数量作为最小限度minimal
minimal = d->ht[0].used;
//minimal不能小于最低值
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
//用minimal值调整字典d大小
return dictExpand(d, minimal);
}下面是调用dictExpand,与扩容相同:
static int dictExpand(dict *ht, unsigned long size) {
//构建一个新的字典
dict n;
unsigned long realsize = _dictNextPower(size), i;
/* 如果字典的元素超过字典所允许的大小,返回错误 */
if (ht->used > size)
return DICT_ERR;
//字典初始化
_dictInit(&n, ht->type, ht->privdata);
n.size = realsize;
n.sizemask = realsize-1;
n.table = calloc(realsize,sizeof(dictEntry*));
/* 数据从旧的hashtable迁移到新的hashtable
* 如果旧的hashtable为空,那么dictExpand方法只会创建一个新的hashtable
*/
n.used = ht->used;
for (i = 0; i < ht->size && ht->used > 0; i++) {
dictEntry *he, *nextHe;
if (ht->table[i] == NULL) continue;
/* 遍历每个槽位的entry */
he = ht->table[i];
while(he) {
unsigned int h;
nextHe = he->next;
/*获取新元素的下标 */
h = dictHashKey(ht, he->key) & n.sizemask;
he->next = n.table[h];
n.table[h] = he;
ht->used--;
/*指向下一个元素 */
he = nextHe;
}
}
assert(ht->used == 0);
free(ht->table);
*ht = n;
return DICT_OK;
}3.4 查找元素
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (dictSize(d) == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);
//获取键的哈希值
h = dictHashKey(d, key);
//遍历查找哈希表
for (table = 0; table <= 1; table++) {
//根据哈希值获取对应的下标值
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
//如果值存在,则遍历该值中的单链表,并返回该节点
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
//如果没有再哈希操作,则只读取ht[0]
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}具体步骤如下:
1、根据键调用哈希函数获取哈希值
2、根据哈希值取得下标值(即索引值)
3、遍历字典哈希表,读取下标对应的元素
4、遍历钙元素的单链表,若找到了与自身键匹配的键则返回该元素,否则返回null、
3.5 添加元素
当往哈希表中添加元素时,首先调用dictFind函数判断键是否存在,如果存在就调用dbOverwrite函数修改键值对,如果不存在就调用dbAdd函数添加元素。
dictAdd函数源码如下:
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
//该字典是否在进行再哈希操作,如果是就执行一次再哈希
if (dictIsRehashing(d)) _dictRehashStep(d);
/* 查找键,如果找到则直接返回-1,如果找不到就返回新节点的下标值*/
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
/* 是否进行再哈希,如果是就插入哈希表ht[1]中,否则插入哈希表ht[0] */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
//如果遇到哈希表容量不足,则进行扩容
//为新节点申请内存,插入哈希表中给新节点存入键信息
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}需要注意的是,如果在添加过程中遇到了哈希表容量不够的情况,则会进行扩容,而且为了不影响再哈希,就会把数据加入ht[1]中,而不会在ht[0]中插入数据。
3.6 修改元素
修改元素的源码如下:
void dbOverwrite(redisDb *db, robj *key, robj *val) {
//查找键是否存在,返回存在的节点
dictEntry *de = dictFind(db->dict,key->ptr);
serverAssertWithInfo(NULL,key,de != NULL);
dictEntry auxentry = *de;
//获取旧节点的val字段值
robj *old = dictGetVal(de);
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
val->lru = old->lru;
}
//给节点设置新值
dictSetVal(db->dict, de, val);
if (server.lazyfree_lazy_server_del) {
freeObjAsync(old);
dictSetVal(db->dict, &auxentry, NULL);
}
//释放旧节点占用的内存
dictFreeVal(db->dict, &auxentry);
}修改键的过程如下:
1、调用dictFind查找键是否存在
2、如果不存在则中断执行
3、如果存在,修改节点键值对中的值为新值
4、释放旧节点占用的内存
3.7 删除元素
删除元素源码如下:
void tryResizeHashTables(int dbid) {
//判断是否需要缩容
if (htNeedsResize(server.db[dbid].dict))
dictResize(server.db[dbid].dict);
if (htNeedsResize(server.db[dbid].expires))
dictResize(server.db[dbid].expires);
}/* 缩容*/
int dictResize(dict *d)
{
unsigned long minimal;
//如果dict_can_resize是0,表示不能进行再哈希或正在进行再哈希,并返回错误标志DICT_ERR
if (dict_can_resize != DICT_RESIZE_ENABLE || dictIsRehashing(d)) return DICT_ERR;
//获得已有节点的数量作为最小限度minimal
minimal = d->ht[0].used;
//minimal不能小于最低值
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
//用minimal值调整字典d大小
return dictExpand(d, minimal);
}删除元素步骤如下:
1、查找改键是否存在于字典中,如果存在则把该节点从单链表中删除
2、释放该节点对应键、值分别占用的内存,以及节点本身占用的内存
3、给对应的哈希表的used字典执行减1操作
3.8 遍历
3.8.1 边遍历边修改
Redis存储对象本身是字典,如果对象很多,这个字典也会很大。当我们使用keys命令搜索执行模式的键时,它会遍历整个主干字典。需要注意的是,在遍历的过程中,满足模式匹配条件的键被找到之后还需要判断键指向的对象是否已经过期,如果过期了就要从主干字典中将该键删除。
void keysCommand(client *c) {
//迭代器
dictIterator *di;
//迭代器当前的entry
dictEntry *de;
//keys的匹配模式参数
sds pattern = c->argv[1]->ptr;
int plen = sdslen(pattern), allkeys;
unsigned long numkeys = 0;
void *replylen = addReplyDeferredLen(c);
di = dictGetSafeIterator(c->db->dict);
//判断是否获取所有键,例如用于keys这样的命令
allkeys = (pattern[0] == '*' && plen == 1);
while((de = dictNext(di)) != NULL) {
sds key = dictGetKey(de);
robj *keyobj;
if (allkeys || stringmatchlen(pattern,plen,key,sdslen(key),0)) {
keyobj = createStringObject(key,sdslen(key));
//判断键是否过期,如果过期需要删除
if (!keyIsExpired(c->db,keyobj)) {
addReplyBulk(c,keyobj);
numkeys++;
}
decrRefCount(keyobj);
}
}
dictReleaseIterator(di);
setDeferredArrayLen(c,replylen,numkeys);
}3.8.2 重复遍历问题
字典在扩容的时候要进行渐进式迁移,此时会存在两个哈希表。遍历需要对这两个哈希表依次进行,先遍历完旧的哈希表,在继续遍历新的哈希表。如果在遍历的过程中进行定时再哈希操作,将已经遍历过的旧哈希表中的元素迁移到新哈希表中,那么会重复遍历元素吗?下面看一下Redis是如何解决这个问题的。
Redis为字典提供了两种迭代器:一种是安全迭代器,另一种是不安全迭代器。
typedef struct dictIterator {
//目标字典对象
dict *d;
//当前遍历的槽位置,初始化为-1
long index;
//table: ht[0]或ht[1]
//safe: 表示迭代器是否安全
int table, safe;
//*entry 迭代器当前指向的对象
//*nextEntry 迭代器下一个指向的对象
dictEntry *entry, *nextEntry;
/* 迭代器指纹 */
unsigned long long fingerprint;
} dictIterator;dictIterator *dictGetSafeIterator(dict *d) {
dictIterator *i = dictGetIterator(d);
i->safe = 1;
return i;
}安全迭代器指的是在遍历过程中,可以对字典进行查找和修改,同样在查找和修改过程中会触发过期判断,删除内部元素,而且安全迭代过程不会重复遍历元素,为了保证不重复,会禁止定时再哈希。
安全迭代器在刚开始遍历时会给字典打上一个标记,有了这个标记,定时再哈希就不会执行,遍历时就不会重复遍历元素。如果当前字典有安全迭代器在运行,则不进行渐进式再哈希操作,再哈希操作暂停,字典中的数据就不会被重复遍历,这样就确保读取数据的准确性。
迭代相关源码如下:
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;
//这个就是标记,它表示当前加在字典上的安全迭代器的数量
unsigned long iterators;
} dict;//如果是安全迭代器,就不在进行再哈希
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}dictEntry *dictNext(dictIterator *iter)
{
while (1) {
if (iter->entry == NULL) {
//遍历一个新槽位下面的链表,数组的下标往前移动
dictht *ht = &iter->d->ht[iter->table];
if (iter->index == -1 && iter->table == 0) {
//第一次遍历,刚刚进入遍历过程
//也就是ht[0]数组的第一个元素下面的链表
if (iter->safe)
//给字典打上安全标记,禁止字典进行再哈希
iter->d->iterators++;
else
//记录迭代器指纹,如果遍历过程中字典有变动,那么指纹就会变
iter->fingerprint = dictFingerprint(iter->d);
}
iter->index++;
if (iter->index >= (long) ht->size) {
//如果处理再哈希状态中,就会继续遍历第二个哈希表
if (dictIsRehashing(iter->d) && iter->table == 0) {
iter->table++;
iter->index = 0;
ht = &iter->d->ht[1];
} else {
break;
}
}
//将当前遍历的元素记录到迭代器中
iter->entry = ht->table[iter->index];
} else {
//直接将下一个元素记录为本次迭代的元素
iter->entry = iter->nextEntry;
}
if (iter->entry) {
iter->nextEntry = iter->entry->next;
return iter->entry;
}
}
return NULL;
}不安全迭代是指遍历过程中字典是只读的,不可以修改,即迭代器过程中字典数据的增删改查等操作都不能进行,否则会报异常。只能调用dictNext对字典进行持续遍历,不能调用任何能触发过期判断的函数。
//获取非安全迭代器,只读迭代器,允许定时再哈希
dictIterator *dictGetIterator(dict *d)
{
dictIterator *iter = zmalloc(sizeof(*iter));
iter->d = d;
iter->table = 0;
iter->index = -1;
iter->safe = 0;
iter->entry = NULL;
iter->nextEntry = NULL;
return iter;
}void dictReleaseIterator(dictIterator *iter)
{
if (!(iter->index == -1 && iter->table == 0)) {
if (iter->safe)
iter->d->iterators--;
else
assert(iter->fingerprint == dictFingerprint(iter->d));
}
zfree(iter);
}//计算字典的指纹,只要有任意结构的变动,指纹都会发生变化
//如果只是某个元素的值被修改了,指纹不会发生变化
unsigned long long dictFingerprint(dict *d) {
unsigned long long integers[6], hash = 0;
int j;
integers[0] = (long) d->ht[0].table;
integers[1] = d->ht[0].size;
integers[2] = d->ht[0].used;
integers[3] = (long) d->ht[1].table;
integers[4] = d->ht[1].size;
integers[5] = d->ht[1].used;
for (j = 0; j < 6; j++) {
hash += integers[j];
/* For the hashing step we use Tomas Wang's 64 bit integer hash. */
hash = (~hash) + (hash << 21); // hash = (hash << 21) - hash - 1;
hash = hash ^ (hash >> 24);
hash = (hash + (hash << 3)) + (hash << 8); // hash * 265
hash = hash ^ (hash >> 14);
hash = (hash + (hash << 2)) + (hash << 4); // hash * 21
hash = hash ^ (hash >> 28);
hash = hash + (hash << 31);
}
return hash;
}在迭代器的选择上,需要注意以下几点:
1、bgrewriteaof需要遍历所有对象转换成操作命令进行持久化,绝对不允许出现重复,必须使用安全迭代器。
2、bgsave也需要遍历所有对象来持久化,同样不允许出现重复,必须使用安全迭代器。
3、遍历过程中需要处理元素过期、需要对字典进行修改,必须使用安全迭代器。
4、其他情况下,如果允许遍历过程中重负遍历个别元素,则不需要对字典进行结构性修改的情况下都会使用非安全迭代器。
4 ZipList和HashTable的选择
通过前面的学习,我们了解了Redis的hash数据类型。hash数据类型的对象编码有两种,分别是OBJ_ENCODING_ZIPLIST和OBJ_ENCODING_HT,也就是它的底层有两种数据结构实现:一种是ziplist,另一种是hashtable。Redis的hash数据类型之所有使用两种编码格式,是因为当一个hash对象的键值对数据量比较小时,使用紧凑的数组格式可以节省内存空间。
因此当一个hash对象的键值对数据量增加到一定数量时,就会触发编码转化,将该hash对象的键值对从ziplist编码转换为ht编码。其中,临界值的关键参数为hash_max_ziplist_entries和hash_max_ziplist_value,可以在配置文件中修改这两个参数的默认值。如下是redis.conf的相关配置:
hash_max_ziplist_entries 512
hash_max_ziplist_value 64hash_max_ziplist_entries的默认值是512,表示当hash对象的键值对数量大于该值时使用OBJ_ENCODING_HT编码,否则使用OBJ_ENCODING_ZIPLIST编码。
Hash底层数据结构切换类型的源码如下:
int hashTypeSet(robj *o, sds field, sds value, int flags) {
int update = 0;
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr, *vptr;
zl = o->ptr;
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
fptr = ziplistFind(fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {
/* Grab pointer to the value (fptr points to the field) */
vptr = ziplistNext(zl, fptr);
serverAssert(vptr != NULL);
update = 1;
/* Delete value */
zl = ziplistDelete(zl, &vptr);
/* Insert new value */
zl = ziplistInsert(zl, vptr, (unsigned char*)value,
sdslen(value));
}
}
if (!update) {
/* Push new field/value pair onto the tail of the ziplist */
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),
ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),
ZIPLIST_TAIL);
}
o->ptr = zl;
/* Check if the ziplist needs to be converted to a hash table */
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
} else if (o->encoding == OBJ_ENCODING_HT) {
dictEntry *de = dictFind(o->ptr,field);
if (de) {
sdsfree(dictGetVal(de));
if (flags & HASH_SET_TAKE_VALUE) {
dictGetVal(de) = value;
value = NULL;
} else {
dictGetVal(de) = sdsdup(value);
}
update = 1;
} else {
sds f,v;
if (flags & HASH_SET_TAKE_FIELD) {
f = field;
field = NULL;
} else {
f = sdsdup(field);
}
if (flags & HASH_SET_TAKE_VALUE) {
v = value;
value = NULL;
} else {
v = sdsdup(value);
}
dictAdd(o->ptr,f,v);
}
} else {
serverPanic("Unknown hash encoding");
}
/* Free SDS strings we did not referenced elsewhere if the flags
* want this function to be responsible. */
if (flags & HASH_SET_TAKE_FIELD && field) sdsfree(field);
if (flags & HASH_SET_TAKE_VALUE && value) sdsfree(value);
return update;
}hash_max_ziplist_value的默认值为64,表示hash对象中的键值对存在的长度或值的长度大于该值时使用OBJ_ENCODING_HT编码,否则使用OBJ_ENCODING_ZIPLIST编码。
redis的hash数据类型之所以这样设计,是因为当ziplist变得很大时会有下面几个缺点:
1、每次插入或修改引发的realloc(内存再分配)操作都会有更大的概率造成内存复制,从而降低性能。
2、一旦发生内存复制,成本也相应增加,因为要复制更大的一块内存空间。
3、当ziplist数据项过多时,在它里面查找指定的数据项就会使性能变得更低,因为在ziplist中查找数据项需要依次执行遍历操作。















 743
743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











