







Ceph IO流程及数据分布
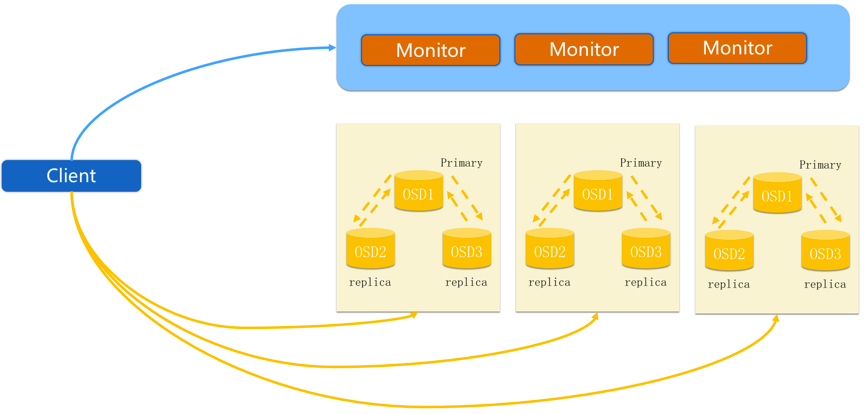
1.1 正常IO流程图
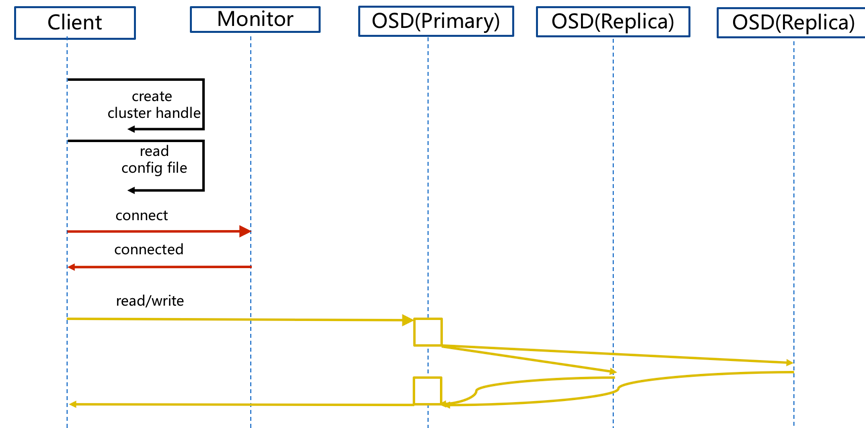
步骤:
- client创建cluster handler。
- client读取配置文件。
- client连接上monitor,获取集群map信息。
- client读写io根据crush算法请求对应的主osd数据节点。
- 主osd数据节点同时写入另外两个副本节点数据。
- 等待主节点以及另外两个副本节点写完数据状态。
- 主节点及副本节点写入状态都成功后,返回给client,io写入完成。
1.2 新主IO流程图
说明: 如果新加入的OSD1取代了原有的OSD4成为Primary OSD,由于OSD1上未创建 PG ,不存在数据,那么PG上的I/O无法进行,怎样工作的呢?
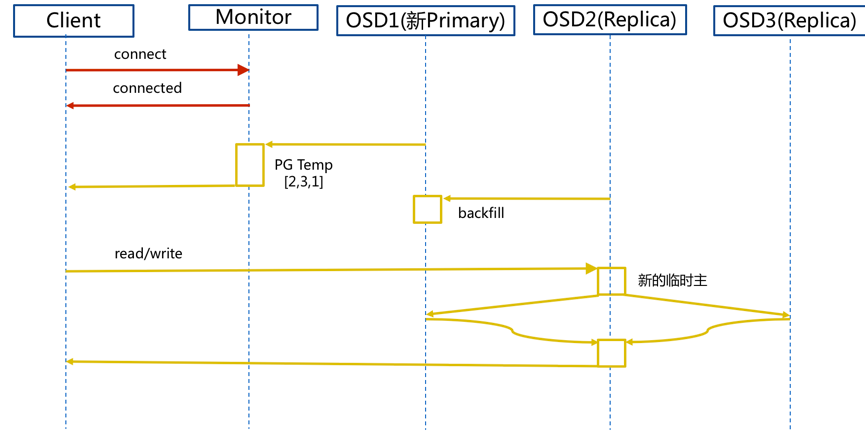
步骤:
- client连接monitor获取集群map信息。
- 同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。
- 临时主osd2会把数据全量同步给新主osd1。
- client IO读写直接连接临时主osd2进行读写。
- osd2收到读写io,同时写入另外两副本节点。
- 等待osd2以及另外两副本写入成功。
- osd2三份数据都写入成功返回给client,此时client io读写完毕。
- 如果osd1数据同步完毕,临时主osd2会交出主角色。
- osd1成为主节点,osd2变成副本。
1.3 Ceph IO算法流程
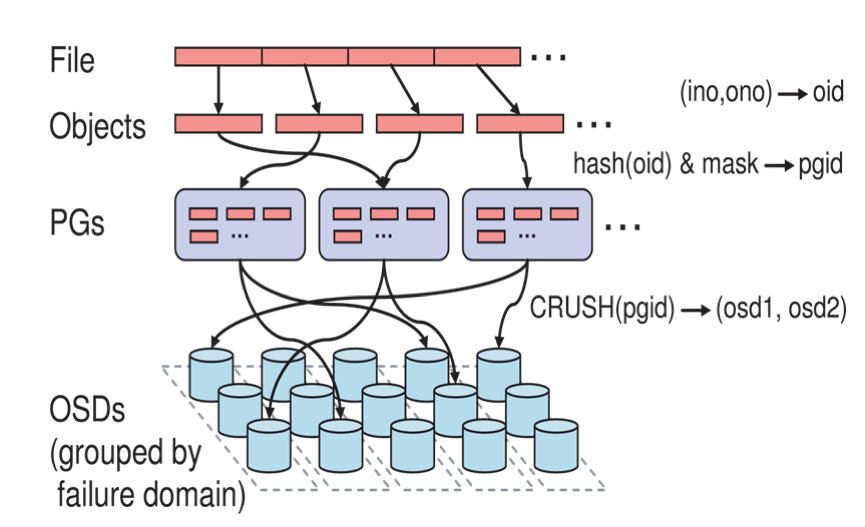
-
File用户需要读写的文件。File->Object映射:
- ino (File的元数据,File的唯一id)。
- ono(File切分产生的某个object的序号,默认以4M切分一个块大小)。
- oid(object id: ino + ono)。
-
Object是RADOS需要的对象。Ceph指定一个静态hash函数计算oid的值,将oid映射成一个近似均匀分布的伪随机值,然后和mask按位相与,得到pgid。Object->PG映射:
- hash(oid) & mask-> pgid 。
- mask = PG总数m(m为2的整数幂)-1 。
-
PG(Placement Group)用途是对object的存储进行组织和位置映射,(类似于redis cluster里面的slot的概念)一个PG里面会有很多object。采用CRUSH算法,将pgid代入其中,然后得到一组OSD。PG->OSD映射:
- CRUSH(pgid)->(osd1,osd2,osd3) 。
1.4 Ceph IO伪代码流程
locator = object_nameobj_hash = hash(locator)pg = obj_hash % num_pgosds_for_pg = crush(pg) # returns a list of osdsprimary = osds_for_pg[0]replicas = osds_for_pg[1:]
1.5 Ceph RBD IO流程
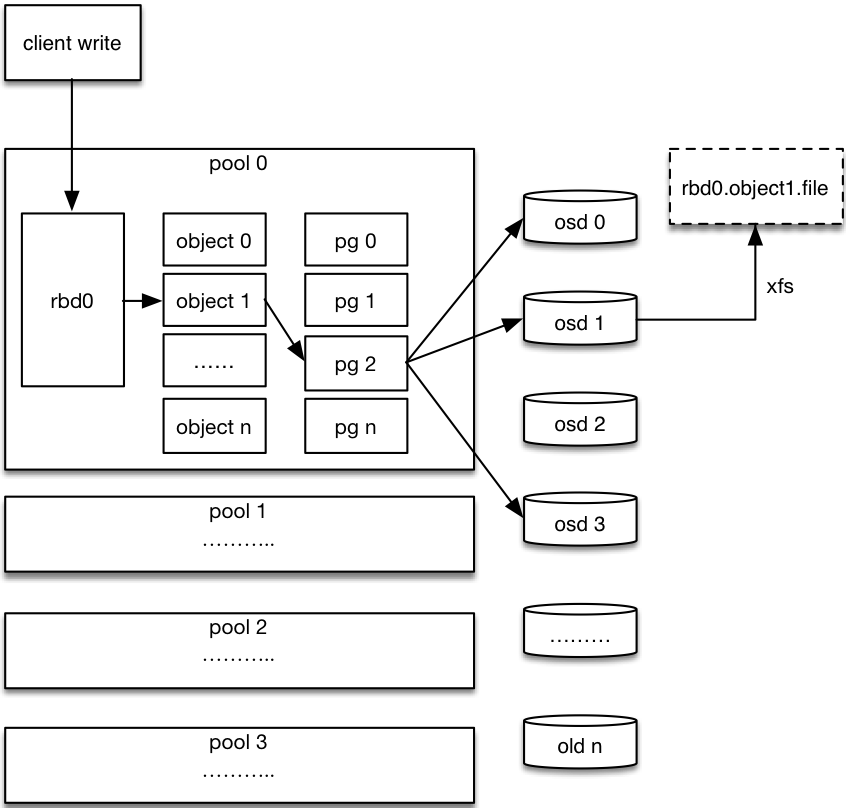
步骤:
- 客户端创建一个pool,需要为这个pool指定pg的数量。
- 创建pool/image rbd设备进行挂载。
- 用户写入的数据进行切块,每个块的大小默认为4M,并且每个块都有一个名字,名字就是object+序号。
- 将每个object通过pg进行副本位置的分配。
- pg根据cursh算法会寻找3个osd,把这个object分别保存在这三个osd上。
- osd上实际是把底层的disk进行了格式化操作,一般部署工具会将它格式化为xfs文件系统。
- object的存储就变成了存储一个文rbd0.object1.file。
1.6 Ceph RBD IO框架图
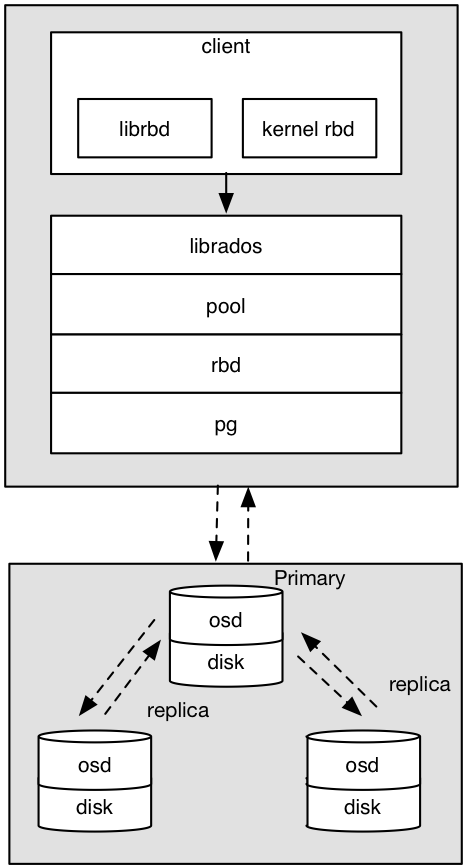
客户端写数据osd过程:
- 采用的是librbd的形式,使用librbd创建一个块设备,向这个块设备中写入数据。
- 在客户端本地同过调用librados接口,然后经过pool,rbd,object,pg进行层层映射,在PG这一层中,可以知道数据保存在哪3个OSD上,这3个OSD分为主从的关系。
- 客户端与primay OSD建立SOCKET通信,将要写入的数据传给primary OSD,由primary OSD再将数据发送给其他replica OSD数据节点。
1.7 Ceph Pool和PG分布情况
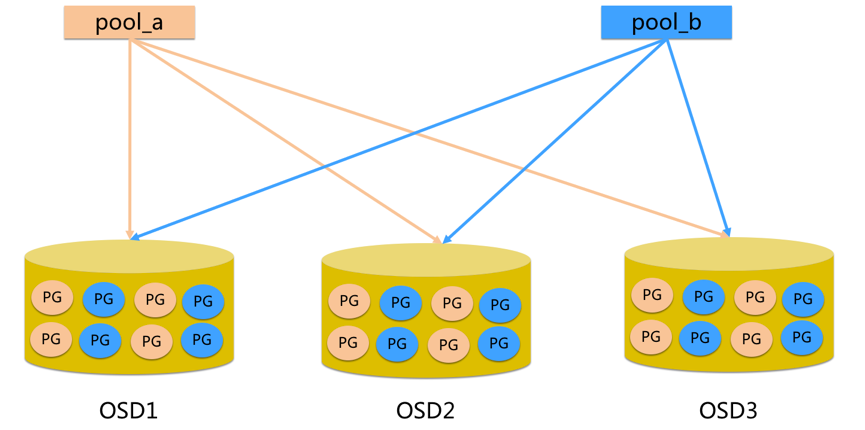
说明:
- pool是ceph存储数据时的逻辑分区,它起到namespace的作用。
- 每个pool包含一定数量(可配置)的PG。
- PG里的对象被映射到不同的Object上。
- pool是分布到整个集群的。
- pool可以做故障隔离域,根据不同的用户场景不一进行隔离。
1.8 Ceph 数据扩容PG分布
场景数据迁移流程:
- 现状3个OSD,4个PG
- 扩容到4个OSD,4个PG
现状:
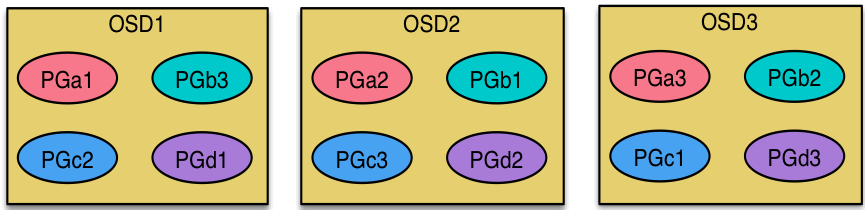
扩容后:

说明:每个OSD上分布很多PG,并且每个PG会自动散落在不同的OSD上。如果扩容那么相应的PG会进行迁移到新的OSD上,保证PG数量的均衡。















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









