







 本文深入探讨了KNN算法的原理,包括如何通过计算距离找到最近的邻居来进行分类预测。文章详细解释了KNN在图像分类中的应用,特别是在手写数字识别上的实现,并对比了KNeighborsClassifier和RadiusNeighborsClassifier两种策略。此外,还分析了KNN算法在高维数据上的局限性和性能特点。
本文深入探讨了KNN算法的原理,包括如何通过计算距离找到最近的邻居来进行分类预测。文章详细解释了KNN在图像分类中的应用,特别是在手写数字识别上的实现,并对比了KNeighborsClassifier和RadiusNeighborsClassifier两种策略。此外,还分析了KNN算法在高维数据上的局限性和性能特点。
1. KNN
KNN被翻译为最近邻算法,顾名思义,找到最近的k个邻居,在前k个最近样本(k近邻)中选择最近的占比最高的类别作为预测类别。
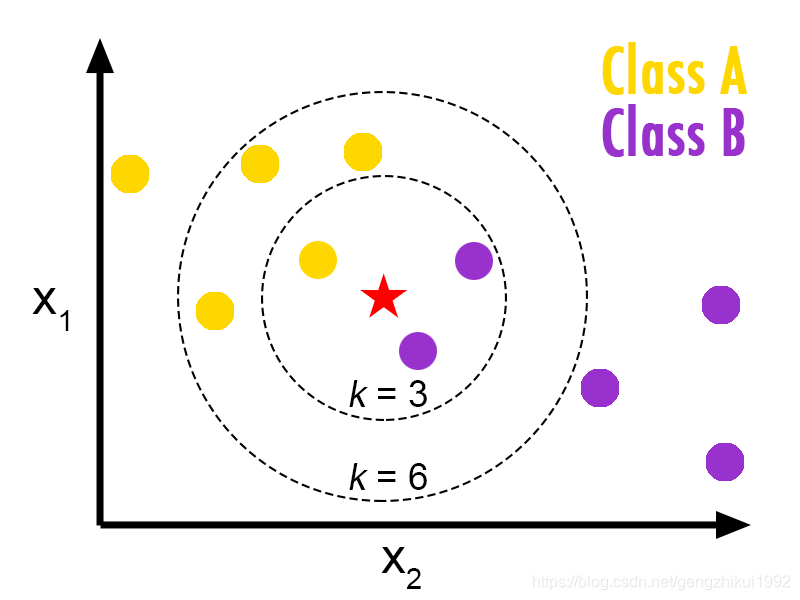
如上图所示:
五角星(待预测的)要被赋予哪个类,是紫色圆形还是黄色圆形?
1)如果k=3(实线所表示的圆),由于紫色圆形所占比例为2/3,大于黄色圆形所占的比例1/3,那么五角星将被赋予紫色圆形那个类。
2)如果k=5(虚线所表示的圆),由于黄色圆形的比例为3/5大于紫色圆形所占的比例2/5,那么五角星被赋予黄色圆形类。
通过上述这个例子,我们可以简单总结出KNN算法的计算逻辑。
1)给定测试对象,计算它与训练集中每个对象的距离。
2)圈定距离最近的k个训练对象,作为测试对象的邻居。
3)根据这k个近邻对象所属的类别,找到占比最高的那个类别作为测试对象的预测类别。
2. 图像分类
首先,我们来看一下什么是图像分类问题。
所谓的图像分类问题就是将已有的固定的分类标签集合中最合适的标签分配给输入的图像。
下面通过一个简单的小例子来解释下什么是图像分类模型
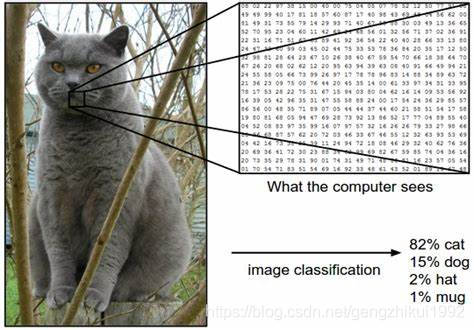
以猫的图片为例,图像分类模型读取该图片,并生成该图片属于集合{cat,dog,hat,mug}中各个标签的概率。
需要注意的是,对于计算机来说,图像是一个由数字组成的巨大的三维数组。在这个猫的例子中,图像的大小是宽248像素,高400像素,有3个颜色通道,分别是红、绿和蓝(简称RGB)。如此,该图像就包含了248×400×3=297600个数字,每个数字都是处于范围0~255之间的整型,其中0表示黑,255表示白。
我们的任务就是将上百万的数字解析成人类可以理解的标签,比如“猫”。
3. KNN实现MNIST数字分类
3.1 MIMIST数据集介绍

在MNIST数据集中,每张图片均由28×28个像素点构成,每个像素点使用一个灰度值表示。
训练集标签以及测试标签包含了相应的目标变量,也就是手写数字的类标签(整数0~9)。
训练数据集包含60000个样本,测试数据集包含10000个样本。
3.2 KNN实现手写数字识别思路
我们先来剖析一下思想,这里我们以MNIST的60000张图片作为训练集,我们希望对测试数据集的10000张图片全部打上标签。
KNN算法将会比较测试图片与训练集中每一张图片,然后将它认为最相似的那个训练集图片的标签赋给这张测试图片。
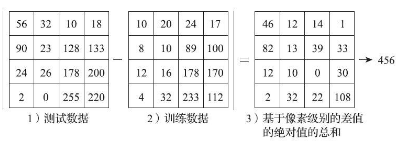
那么,具体应该如何比较这两张图片呢?在本例中,比较图片就是比较28×28的像素块。最简单的方法就是逐个像素进行比较,最后将差异值全部加起来。
3.3 sklearn代码
sklearn实现了两种不同策略的knn算法:
一种就是最普通的KNeighborsClassifier,这种分类器需要给出k值,默认为5,策略就是上面支持的k个近邻进行投票。
另一种为RadiusNeighborsClassifier是基于每个点固定半径内的元素进行投票的,在实现改模型是radius是必传,无默认值。
两种算法中KNeighborsClassifier更常用,但是k值的选择高度依赖数据,通常较大的k值会抑制噪声,但同样会导致分类边界不明显。
在数据未进行采样时,RadiusNeighborsClassifier可能会更合适,但算法不太适合高纬度的数据。
# -*- coding: utf-8 -*-
# !/usr/bin/env python
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
class KNN(object):
def __init__(self):
self.train_file = "./csv/train.csv"
def start(self):
train_df = pd.read_csv(self.train_file)
images = train_df.iloc[0:10000, 1:]
labels = train_df.iloc[0:10000, 0]
train_images, test_images, train_labels, test_labels = train_test_split(images, labels, train_size=0.8,
random_state=0)
model = KNeighborsClassifier()
model.fit(train_images, train_labels)
predict = model.predict(test_images)
scroe = accuracy_score(predict, test_labels)
print scroe
if __name__ == '__main__':
knn = KNN()
knn.start()
4. KNN性能、效果分析
KNN算法的训练不需要花费时间(训练过程只是将训练集数据存储起来),但由于每个测试图像需要与所存储的全部训练图像进行比较,因此测试需要花费大量时间,这显然是一个很大的缺点,因为在实际应用中,我们对测试效率的关注要远远高于训练效率。
在实际的图像分类中基本上是不会使用KNN算法的。因为图像都是高维度数据(它们通常包含很多像素),这些高维数据想要表达的主要是语义信息,而不是某个具体像素间的距离差值(在图像中,具体某个像素的值和差值基本上并不会包含有用的信息)。

如上图所示,右边三张图(遮挡、平移、颜色变换)与最左边原图的欧式距离是相等的。

















 8381
8381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









