









RNN图解:

上图中中间的箭头输出也是ht
公式是 ht=tanh(wih * xt + bih +whh * h(t-1) + bhh),这里可能不只一层

最后得出的yt = f(V*ht + c) 始终V是矩阵c是向量, 函数f的选取主要是看自己需要什么结果
pytorch 代码理解:
import torch
rnn=torch.nn.RNN(input_size=20, hidden_size=50, num_layers=2)
rnn.state_dict().keys()
输出
Out[15]: odict_keys([‘weight_ih_l0’, ‘weight_hh_l0’, ‘bias_ih_l0’, ‘bias_hh_l0’, ‘weight_ih_l1’, ‘weight_hh_l1’, ‘bias_ih_l1’, ‘bias_hh_l1’])
表明循环网络是共享参数的
rnn.state_dict()['weight_ih_l0'].shape
输出
Out[16]: torch.Size([50, 20])
LSTM图

LSTM图形分解及对应的公式:
(图片来自https://blog.csdn.net/xiaocao9903/article/details/78583953)




公式中 ![Wf [ xt, h(t-1)] 其实是 [Wfx, Wfh][](https://img-blog.csdnimg.cn/20190510161452743.png)
其他3个W以此类推
当我们用pytorch的时候:
lstm=torch.nn.LSTM(10, 13, 2)
lstm.state_dict().keys()
得到:
odict_keys(['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0', 'weight_ih_l1', 'weight_hh_l1', 'bias_ih_l1', 'bias_hh_l1'])
首先可以看到,每一层都在共享该层的参数
其次,为什么只有8个key呢?因为是两层,在上面的Wf = [Wfh, Wfx] 中可以看到,每一层有两个weight和两个bias,及第一层的参数是’weight_ih_l0’, ‘weight_hh_l0’, ‘bias_ih_l0’, ‘bias_hh_l0’。第二层的参数是 ‘weight_ih_l1’, ‘weight_hh_l1’, ‘bias_ih_l1’, ‘bias_hh_l1’。但上面的四个公式都有W和b,那么每一层就应该分别有4个’weight_ih_l1’, ‘weight_hh_l1’, ‘bias_ih_l1’, 'bias_hh_l1’吧,其实经过运行程序,就可以看到了,程序如下:
lstm.state_dict()['weight_ih_l0'].shape
结果:
torch.Size([52, 10])
同理
lstm.state_dict()['bias_ih_l0'].shape
结果:
torch.Size([52])
本来lstm.state_dict()[‘weight_ih_l0’].shape的值应该是torch.Size([13, 10]),在这里将4个权重按行叠加起来,就得到torch.Size([52, 10])。受教了!!!!!lstm.state_dict()[‘bias_ih_l0’].shape也是案列叠加后的结果。
今天想自己重写一遍LSTM的算法, 又发现一些小知识,

在我上面的例子里面,是这样的

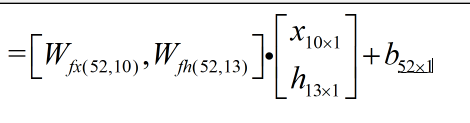
(上面x的下标不是3,而是10)刚好可以直接乘积,不用拆分,只有最后计算激活函数的时候,由于激活函数选择不一样,所以才需要分开。
最后的公式汇聚一下,在这里:

上面的激活函数,phai表示tanh,sigma表示sigmoid激活函数















 2244
2244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









