






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
CGAN相关基础知识在上一周已经详细介绍了,若有需要可查看上一周任务内容。
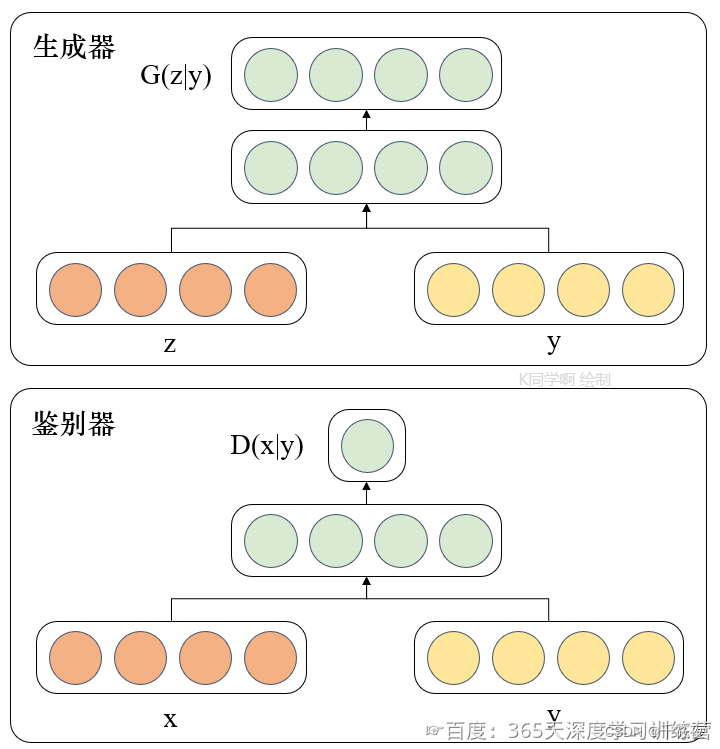
这里补充一张K同学制作的图片以便于理解。
一、前期准备
1.1 导入准备
导入这次工作所需要用到的库,并指定device。
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets,transforms
from torch.autograd import Variable
from torchvision.utils import save_image
from torchvision.utils import make_grid
from torchsummary import summary
import matplotlib.pyplot as plt
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
1.2 数据准备
将数据集进行预处理,定义图片存放路径。
train_transform = transforms.Compose([
transforms.Resize(int(128* 1.12)), ## 图片放大1.12倍
transforms.RandomCrop((128, 128)), ## 随机裁剪成原来的大小
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])
batch_size = 64
train_dataset = datasets.ImageFolder(root='E:/BaiduNetdiskDownload/GAN-Data/rps', transform=train_transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=6)
1.3 数据集可视化
将随机挑选数据集中的图片并进行可视化。
def show_images(dl):
for images,_ in dl:
fig,ax = plt.subplots(figsize=(10,10))
ax.set_xticks([]);ax.set_yticks([])
ax.imshow(make_grid(images.detach(),nrow=16).permute(1,2,0))
break
show_images(train_loader)
可视化结果如下:

二、模型搭建
2.1 权重初始化
latent_dim = 100
n_classes = 3
embedding_dim = 100
2.2 定义生成器架构
进行生成器的架构构建。
# 自定义权重初始化函数,用于初始化生成器和判别器的权重
def weights_init(m):
# 获取当前层的类名
classname = m.__class__.__name__
# 如果当前层是卷积层(类名中包含 'Conv' )
if classname.find('Conv') != -1:
# 使用正态分布随机初始化权重,均值为0,标准差为0.02
torch.nn.init.normal_(m.weight, 0.0, 0.02)
# 如果当前层是批归一化层(类名中包含 'BatchNorm' )
elif classname.find('BatchNorm') != -1:
# 使用正态分布随机初始化权重,均值为1,标准差为0.02
torch.nn.init.normal_(m.weight, 1.0, 0.02)
# 将偏置项初始化为全零
torch.nn.init.zeros_(m.bias)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 定义条件标签的生成器部分,用于将标签映射到嵌入空间中
# n_classes:条件标签的总数
# embedding_dim:嵌入空间的维度
self.label_conditioned_generator = nn.Sequential(
nn.Embedding(n_classes, embedding_dim), # 使用Embedding层将条件标签映射为稠密向量
nn.Linear(embedding_dim, 16) # 使用线性层将稠密向量转换为更高维度
)
# 定义潜在向量的生成器部分,用于将噪声向量映射到图像空间中
# latent_dim:潜在向量的维度
self.latent = nn.Sequential(
nn.Linear(latent_dim, 4*4*512), # 使用线性层将潜在向量转换为更高维度
nn.LeakyReLU(0.2, inplace=True) # 使用LeakyReLU激活函数进行非线性映射
)
# 定义生成器的主要结构,将条件标签和潜在向量合并成生成的图像
self.model = nn.Sequential(
# 反卷积层1:将合并后的向量映射为64x8x8的特征图
nn.ConvTranspose2d(513, 64*8, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8), # 批标准化
nn.ReLU(True), # ReLU激活函数
# 反卷积层2:将64x8x8的特征图映射为64x4x4的特征图
nn.ConvTranspose2d(64*8, 64*4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),
nn.ReLU(True),
# 反卷积层3:将64x4x4的特征图映射为64x2x2的特征图
nn.ConvTranspose2d(64*4, 64*2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8),
nn.ReLU(True),
# 反卷积层4:将64x2x2的特征图映射为64x1x1的特征图
nn.ConvTranspose2d(64*2, 64*1, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*1, momentum=0.1, eps=0.8),
nn.ReLU(True),
# 反卷积层5:将64x1x1的特征图映射为3x64x64的RGB图像
nn.ConvTranspose2d(64*1, 3, 4, 2, 1, bias=False),
nn.Tanh() # 使用Tanh激活函数将生成的图像像素值映射到[-1, 1]范围内
)
def forward(self, inputs):
noise_vector, label = inputs
# 通过条件标签生成器将标签映射为嵌入向量
label_output = self.label_conditioned_generator(label)
# 将嵌入向量的形状变为(batch_size, 1, 4, 4),以便与潜在向量进行合并
label_output = label_output.view(-1, 1, 4, 4)
# 通过潜在向量生成器将噪声向量映射为潜在向量
latent_output = self.latent(noise_vector)
# 将潜在向量的形状变为(batch_size, 512, 4, 4),以便与条件标签进行合并
latent_output = latent_output.view(-1, 512, 4, 4)
# 将条件标签和潜在向量在通道维度上进行合并,得到合并后的特征图
concat = torch.cat((latent_output, label_output), dim=1)
# 通过生成器的主要结构将合并后的特征图生成为RGB图像
image = self.model(concat)
return image
generator = Generator().to(device)
generator.apply(weights_init)
print(generator)
a = torch.ones(100)
b = torch.ones(1)
b = b.long()
a = a.to(device)
b = b.to(device)
架构打印如下:
Generator(
(label_conditioned_generator): Sequential(
(0): Embedding(3, 100)
(1): Linear(in_features=100, out_features=16, bias=True)
)
(latent): Sequential(
(0): Linear(in_features=100, out_features=8192, bias=True)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
)
(model): Sequential(
(0): ConvTranspose2d(513, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)
2.3 构建判别器架构
同上,下面是进行判别器架构构建。
import torch
import torch.nn as nn
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 定义一个条件标签的嵌入层,用于将类别标签转换为特征向量
self.label_condition_disc = nn.Sequential(
nn.Embedding(n_classes, embedding_dim), # 嵌入层将类别标签编码为固定长度的向量
nn.Linear(embedding_dim, 3*128*128) # 线性层将嵌入的向量转换为与图像尺寸相匹配的特征张量
)
# 定义主要的鉴别器模型
self.model = nn.Sequential(
nn.Conv2d(6, 64, 4, 2, 1, bias=False), # 输入通道为6(包含图像和标签的通道数),输出通道为64,4x4的卷积核,步长为2,padding为1
nn.LeakyReLU(0.2, inplace=True), # LeakyReLU激活函数,带有负斜率,增加模型对输入中的负值的感知能力
nn.Conv2d(64, 64*2, 4, 3, 2, bias=False), # 输入通道为64,输出通道为64*2,4x4的卷积核,步长为3,padding为2
nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8), # 批量归一化层,有利于训练稳定性和收敛速度
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64*2, 64*4, 4, 3, 2, bias=False), # 输入通道为64*2,输出通道为64*4,4x4的卷积核,步长为3,padding为2
nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64*4, 64*8, 4, 3, 2, bias=False), # 输入通道为64*4,输出通道为64*8,4x4的卷积核,步长为3,padding为2
nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Flatten(), # 将特征图展平为一维向量,用于后续全连接层处理
nn.Dropout(0.4), # 随机失活层,用于减少过拟合风险
nn.Linear(4608, 1), # 全连接层,将特征向量映射到输出维度为1的向量
nn.Sigmoid() # Sigmoid激活函数,用于输出范围限制在0到1之间的概率值
)
def forward(self, inputs):
img, label = inputs
# 将类别标签转换为特征向量
label_output = self.label_condition_disc(label)
# 重塑特征向量为与图像尺寸相匹配的特征张量
label_output = label_output.view(-1, 3, 128, 128)
# 将图像特征和标签特征拼接在一起作为鉴别器的输入
concat = torch.cat((img, label_output), dim=1)
# 将拼接后的输入通过鉴别器模型进行前向传播,得到输出结果
output = self.model(concat)
return output
discriminator = Discriminator().to(device)
discriminator.apply(weights_init)
print(discriminator)
架构打印如下:
Discriminator(
(label_condition_disc): Sequential(
(0): Embedding(3, 100)
(1): Linear(in_features=100, out_features=49152, bias=True)
)
(model): Sequential(
(0): Conv2d(6, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(3, 3), padding=(2, 2), bias=False)
(3): BatchNorm2d(128, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(3, 3), padding=(2, 2), bias=False)
(6): BatchNorm2d(256, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(3, 3), padding=(2, 2), bias=False)
(9): BatchNorm2d(512, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Flatten(start_dim=1, end_dim=-1)
(12): Dropout(p=0.4, inplace=False)
(13): Linear(in_features=4608, out_features=1, bias=True)
(14): Sigmoid()
)
)
三、模型训练
3.1 损失函数
adversarial_loss = nn.BCELoss()
def generator_loss(fake_output, label):
gen_loss = adversarial_loss(fake_output, label)
return gen_loss
def discriminator_loss(output, label):
disc_loss = adversarial_loss(output, label)
return disc_loss
3.2 优化器
learning_rate = 0.0002
G_optimizer = optim.Adam(generator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
D_optimizer = optim.Adam(discriminator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
3.3 开始训练
# 设置训练的总轮数
num_epochs = 100
# 初始化用于存储每轮训练中判别器和生成器损失的列表
D_loss_plot, G_loss_plot = [], []
# 循环进行训练
for epoch in range(1, num_epochs + 1):
# 初始化每轮训练中判别器和生成器损失的临时列表
D_loss_list, G_loss_list = [], []
# 遍历训练数据加载器中的数据
for index, (real_images, labels) in enumerate(train_loader):
# 清空判别器的梯度缓存
D_optimizer.zero_grad()
# 将真实图像数据和标签转移到GPU(如果可用)
real_images = real_images.to(device)
labels = labels.to(device)
# 将标签的形状从一维向量转换为二维张量(用于后续计算)
labels = labels.unsqueeze(1).long()
# 创建真实目标和虚假目标的张量(用于判别器损失函数)
real_target = Variable(torch.ones(real_images.size(0), 1).to(device))
fake_target = Variable(torch.zeros(real_images.size(0), 1).to(device))
# 计算判别器对真实图像的损失
D_real_loss = discriminator_loss(discriminator((real_images, labels)), real_target)
# 从噪声向量中生成假图像(生成器的输入)
noise_vector = torch.randn(real_images.size(0), latent_dim, device=device)
noise_vector = noise_vector.to(device)
generated_image = generator((noise_vector, labels))
# 计算判别器对假图像的损失(注意detach()函数用于分离生成器梯度计算图)
output = discriminator((generated_image.detach(), labels))
D_fake_loss = discriminator_loss(output, fake_target)
# 计算判别器总体损失(真实图像损失和假图像损失的平均值)
D_total_loss = (D_real_loss + D_fake_loss) / 2
D_loss_list.append(D_total_loss)
# 反向传播更新判别器的参数
D_total_loss.backward()
D_optimizer.step()
# 清空生成器的梯度缓存
G_optimizer.zero_grad()
# 计算生成器的损失
G_loss = generator_loss(discriminator((generated_image, labels)), real_target)
G_loss_list.append(G_loss)
# 反向传播更新生成器的参数
G_loss.backward()
G_optimizer.step()
# 打印当前轮次的判别器和生成器的平均损失
print('Epoch: [%d/%d]: D_loss: %.3f, G_loss: %.3f' % (
(epoch), num_epochs, torch.mean(torch.FloatTensor(D_loss_list)),
torch.mean(torch.FloatTensor(G_loss_list))))
# 将当前轮次的判别器和生成器的平均损失保存到列表中
D_loss_plot.append(torch.mean(torch.FloatTensor(D_loss_list)))
G_loss_plot.append(torch.mean(torch.FloatTensor(G_loss_list)))
if epoch%10 == 0:
# 将生成的假图像保存为图片文件
save_image(generated_image.data[:50], './sample_%d' % epoch + '.png', nrow=5, normalize=True)
# 将当前轮次的生成器和判别器的权重保存到文件
torch.save(generator.state_dict(), './generator_epoch_%d.pth' % (epoch))
torch.save(discriminator.state_dict(), './discriminator_epoch_%d.pth' % (epoch))
Epoch: [1/100]: D_loss: 0.282, G_loss: 1.860
Epoch: [2/100]: D_loss: 0.162, G_loss: 3.394
Epoch: [3/100]: D_loss: 0.233, G_loss: 3.330
Epoch: [4/100]: D_loss: 0.232, G_loss: 2.592
Epoch: [5/100]: D_loss: 0.254, G_loss: 2.471
Epoch: [6/100]: D_loss: 0.342, G_loss: 2.857
Epoch: [7/100]: D_loss: 0.400, G_loss: 1.995
Epoch: [8/100]: D_loss: 0.251, G_loss: 2.119
Epoch: [9/100]: D_loss: 0.402, G_loss: 2.091
Epoch: [10/100]: D_loss: 0.357, G_loss: 2.111
Epoch: [11/100]: D_loss: 0.563, G_loss: 1.845
Epoch: [12/100]: D_loss: 0.584, G_loss: 1.486
Epoch: [13/100]: D_loss: 0.591, G_loss: 1.420
Epoch: [14/100]: D_loss: 0.543, G_loss: 1.378
Epoch: [15/100]: D_loss: 0.568, G_loss: 1.304
Epoch: [16/100]: D_loss: 0.513, G_loss: 1.231
Epoch: [17/100]: D_loss: 0.550, G_loss: 1.393
Epoch: [18/100]: D_loss: 0.577, G_loss: 1.282
Epoch: [19/100]: D_loss: 0.549, G_loss: 1.245
Epoch: [20/100]: D_loss: 0.564, G_loss: 1.231
Epoch: [21/100]: D_loss: 0.543, G_loss: 1.382
Epoch: [22/100]: D_loss: 0.496, G_loss: 1.503
Epoch: [23/100]: D_loss: 0.502, G_loss: 1.451
Epoch: [24/100]: D_loss: 0.521, G_loss: 1.580
Epoch: [25/100]: D_loss: 0.476, G_loss: 1.565
Epoch: [26/100]: D_loss: 0.447, G_loss: 1.560
Epoch: [27/100]: D_loss: 0.494, G_loss: 1.677
Epoch: [28/100]: D_loss: 0.429, G_loss: 1.600
Epoch: [29/100]: D_loss: 0.466, G_loss: 1.709
Epoch: [30/100]: D_loss: 0.500, G_loss: 1.694
Epoch: [31/100]: D_loss: 0.479, G_loss: 1.549
Epoch: [32/100]: D_loss: 0.456, G_loss: 1.483
Epoch: [33/100]: D_loss: 0.513, G_loss: 1.393
Epoch: [34/100]: D_loss: 0.514, G_loss: 1.372
Epoch: [35/100]: D_loss: 0.475, G_loss: 1.332
Epoch: [36/100]: D_loss: 0.497, G_loss: 1.351
Epoch: [37/100]: D_loss: 0.477, G_loss: 1.337
Epoch: [38/100]: D_loss: 0.476, G_loss: 1.375
Epoch: [39/100]: D_loss: 0.488, G_loss: 1.435
Epoch: [40/100]: D_loss: 0.448, G_loss: 1.490
Epoch: [41/100]: D_loss: 0.455, G_loss: 1.494
Epoch: [42/100]: D_loss: 0.439, G_loss: 1.512
Epoch: [43/100]: D_loss: 0.445, G_loss: 1.540
Epoch: [44/100]: D_loss: 0.430, G_loss: 1.586
Epoch: [45/100]: D_loss: 0.442, G_loss: 1.692
Epoch: [46/100]: D_loss: 0.421, G_loss: 1.639
Epoch: [47/100]: D_loss: 0.422, G_loss: 1.734
Epoch: [48/100]: D_loss: 0.422, G_loss: 1.707
Epoch: [49/100]: D_loss: 0.401, G_loss: 1.792
Epoch: [50/100]: D_loss: 0.408, G_loss: 1.778
Epoch: [51/100]: D_loss: 0.406, G_loss: 1.813
Epoch: [52/100]: D_loss: 0.408, G_loss: 1.871
Epoch: [53/100]: D_loss: 0.373, G_loss: 1.796
Epoch: [54/100]: D_loss: 0.376, G_loss: 1.851
Epoch: [55/100]: D_loss: 0.416, G_loss: 1.939
Epoch: [56/100]: D_loss: 0.360, G_loss: 1.969
Epoch: [57/100]: D_loss: 0.372, G_loss: 1.910
Epoch: [58/100]: D_loss: 0.526, G_loss: 2.313
Epoch: [59/100]: D_loss: 0.318, G_loss: 1.960
Epoch: [60/100]: D_loss: 0.316, G_loss: 1.937
Epoch: [61/100]: D_loss: 0.306, G_loss: 1.928
Epoch: [62/100]: D_loss: 0.353, G_loss: 1.993
Epoch: [63/100]: D_loss: 0.326, G_loss: 2.079
Epoch: [64/100]: D_loss: 0.413, G_loss: 2.154
Epoch: [65/100]: D_loss: 0.312, G_loss: 2.047
Epoch: [66/100]: D_loss: 0.320, G_loss: 2.096
Epoch: [67/100]: D_loss: 0.360, G_loss: 2.244
Epoch: [68/100]: D_loss: 0.312, G_loss: 2.142
Epoch: [69/100]: D_loss: 0.326, G_loss: 2.135
Epoch: [70/100]: D_loss: 0.272, G_loss: 2.186
Epoch: [71/100]: D_loss: 0.290, G_loss: 2.232
Epoch: [72/100]: D_loss: 0.420, G_loss: 2.423
Epoch: [73/100]: D_loss: 0.422, G_loss: 2.347
Epoch: [74/100]: D_loss: 0.278, G_loss: 2.255
Epoch: [75/100]: D_loss: 0.262, G_loss: 2.262
Epoch: [76/100]: D_loss: 0.286, G_loss: 2.329
Epoch: [77/100]: D_loss: 0.289, G_loss: 2.416
Epoch: [78/100]: D_loss: 0.330, G_loss: 2.427
Epoch: [79/100]: D_loss: 0.337, G_loss: 2.522
Epoch: [80/100]: D_loss: 0.255, G_loss: 2.403
Epoch: [81/100]: D_loss: 0.289, G_loss: 2.468
Epoch: [82/100]: D_loss: 0.233, G_loss: 2.515
Epoch: [83/100]: D_loss: 0.274, G_loss: 2.547
Epoch: [84/100]: D_loss: 0.285, G_loss: 2.557
Epoch: [85/100]: D_loss: 0.244, G_loss: 2.536
Epoch: [86/100]: D_loss: 0.279, G_loss: 2.563
Epoch: [87/100]: D_loss: 0.394, G_loss: 2.705
Epoch: [88/100]: D_loss: 0.262, G_loss: 2.603
Epoch: [89/100]: D_loss: 0.254, G_loss: 2.613
Epoch: [90/100]: D_loss: 0.288, G_loss: 2.759
Epoch: [91/100]: D_loss: 0.275, G_loss: 2.576
Epoch: [92/100]: D_loss: 0.229, G_loss: 2.687
Epoch: [93/100]: D_loss: 0.232, G_loss: 2.682
Epoch: [94/100]: D_loss: 0.219, G_loss: 2.771
Epoch: [95/100]: D_loss: 0.588, G_loss: 3.084
Epoch: [96/100]: D_loss: 0.422, G_loss: 2.735
Epoch: [97/100]: D_loss: 0.254, G_loss: 2.705
Epoch: [98/100]: D_loss: 0.222, G_loss: 2.654
Epoch: [99/100]: D_loss: 0.229, G_loss: 2.757
Epoch: [100/100]: D_loss: 0.200, G_loss: 2.724
四、指定生成图像
from numpy.random import randint, randn
from numpy import linspace
from matplotlib import pyplot as plt, gridspec
import numpy as np
# Assuming 'generator' and 'device' are defined earlier in your code
generator.load_state_dict(torch.load('./generator_epoch_100.pth'), strict=False)
generator.eval()
interpolated = randn(100)
interpolated = torch.tensor(interpolated).to(device).type(torch.float32)
label = 0
labels = torch.ones(1) * label
labels = labels.to(device).unsqueeze(1).long()
predictions = generator((interpolated, labels))
predictions = predictions.permute(0, 2, 3, 1).detach().cpu()
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
plt.figure(figsize=(8, 3))
pred = (predictions[0, :, :, :] + 1) * 127.5
pred = np.array(pred)
plt.imshow(pred.astype(np.uint8))
plt.show()
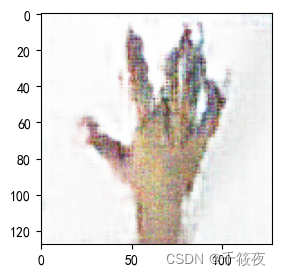
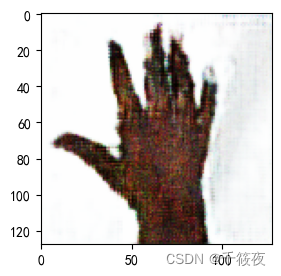
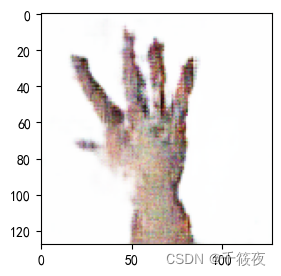















 1175
1175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









