







概述
ext4 write写入pagecache之后,再合适的时机会回写到磁盘,ext4文件系统中是通过ext4_writepages写入磁盘,本来将在源码角度分析该过程。建议先参照ext4 - delay allocation数据结构_nginux的博客-CSDN博客看下涉及的重要数据结构。
调用栈
#0 ext4_writepages (mapping=<optimized out>, wbc=0xffff888000a27a60) at fs/ext4/inode.c:2720
#1 0xffffffff8134255a in do_writepages (mapping=0xffff8880062459d0, wbc=0xffff888000a27a60) at mm/page-writeback.c:2352
#2 0xffffffff814697c5 in __writeback_single_inode (inode=0xffff888006245858, wbc=0xffff888000a27a60) at fs/fs-writeback.c:1461
#3 0xffffffff8146a06c in writeback_sb_inodes (sb=<optimized out>, wb=0xffff88800442e060, work=0xffff888000a27d50) at fs/fs-writeback.c:1721
#4 0xffffffff8146a4ff in __writeback_inodes_wb (wb=0xffff88800442e060, work=0xffff888000a27d50) at fs/fs-writeback.c:1790
#5 0xffffffff8146a9d9 in wb_writeback (wb=0xffff88800442e060, work=0xffff888000a27d50) at fs/fs-writeback.c:1896
#6 0xffffffff8146c865 in wb_check_background_flush (wb=<optimized out>) at fs/fs-writeback.c:1964
#7 wb_do_writeback (wb=<optimized out>) at fs/fs-writeback.c:2052
#8 wb_workfn (work=0xffff88800442e1f0) at fs/fs-writeback.c:2080
#9 0xffffffff81196a32 in process_one_work (worker=0xffff8880009f0400, work=0xffff88800442e1f0) at kernel/workqueue.c:2269
#10 0xffffffff81196de9 in worker_thread (__worker=0xffff8880009f0400) at kernel/workqueue.c:2415
#11 0xffffffff811a0a89 in kthread (_create=<optimized out>) at kernel/kthread.c:292
ext4_writepages
作用描述:用于将mapping指向的page cache缓存写回磁盘,这个中间很重要的过程是delay allcation特性要做一些合并逻辑,尽量合并连续的块请求。
static int ext4_writepages(struct address_space *mapping,
struct writeback_control *wbc)
{
pgoff_t writeback_index = 0;
long nr_to_write = wbc->nr_to_write;
int range_whole = 0;
int cycled = 1;
handle_t *handle = NULL;
struct mpage_da_data mpd;
struct inode *inode = mapping->host;
int needed_blocks, rsv_blocks = 0, ret = 0;
struct ext4_sb_info *sbi = EXT4_SB(mapping->host->i_sb);
struct blk_plug plug;
bool give_up_on_write = false;
if (unlikely(ext4_forced_shutdown(EXT4_SB(inode->i_sb))))
return -EIO;
percpu_down_read(&sbi->s_writepages_rwsem);
trace_ext4_writepages(inode, wbc);
/*
* No pages to write? This is mainly a kludge to avoid starting
* a transaction for special inodes like journal inode on last iput()
* because that could violate lock ordering on umount
*/
if (!mapping->nrpages || !mapping_tagged(mapping, PAGECACHE_TAG_DIRTY))
goto out_writepages;
if (ext4_should_journal_data(inode)) {
ret = generic_writepages(mapping, wbc);
goto out_writepages;
}
/*
* If the filesystem has aborted, it is read-only, so return
* right away instead of dumping stack traces later on that
* will obscure the real source of the problem. We test
* EXT4_MF_FS_ABORTED instead of sb->s_flag's SB_RDONLY because
* the latter could be true if the filesystem is mounted
* read-only, and in that case, ext4_writepages should
* *never* be called, so if that ever happens, we would want
* the stack trace.
*/
if (unlikely(ext4_forced_shutdown(EXT4_SB(mapping->host->i_sb)) ||
sbi->s_mount_flags & EXT4_MF_FS_ABORTED)) {
ret = -EROFS;
goto out_writepages;
}
/*
* If we have inline data and arrive here, it means that
* we will soon create the block for the 1st page, so
* we'd better clear the inline data here.
*/
if (ext4_has_inline_data(inode)) {
/* Just inode will be modified... */
handle = ext4_journal_start(inode, EXT4_HT_INODE, 1);
if (IS_ERR(handle)) {
ret = PTR_ERR(handle);
goto out_writepages;
}
BUG_ON(ext4_test_inode_state(inode,
EXT4_STATE_MAY_INLINE_DATA));
ext4_destroy_inline_data(handle, inode);
ext4_journal_stop(handle);
}
if (ext4_should_dioread_nolock(inode)) {
/*
* We may need to convert up to one extent per block in
* the page and we may dirty the inode.
*/
rsv_blocks = 1 + ext4_chunk_trans_blocks(inode,
PAGE_SIZE >> inode->i_blkbits);
}
if (wbc->range_start == 0 && wbc->range_end == LLONG_MAX)
range_whole = 1;
if (wbc->range_cyclic) {
writeback_index = mapping->writeback_index;
if (writeback_index)
cycled = 0;
mpd.first_page = writeback_index;
mpd.last_page = -1;
} else {
mpd.first_page = wbc->range_start >> PAGE_SHIFT;
mpd.last_page = wbc->range_end >> PAGE_SHIFT;
}
mpd.inode = inode;
mpd.wbc = wbc;
ext4_io_submit_init(&mpd.io_submit, wbc);
retry:
//如果是主动sync调用或者wbc设置了tagged_writepages,将first-last范围的cache
//页面修改成PAGECACHE_TAG_TOWRITE TAG,意味着需要回写(还没开始,开始会写中是PAGECACHE_TAG_WRITEBACK)
if (wbc->sync_mode == WB_SYNC_ALL || wbc->tagged_writepages)
tag_pages_for_writeback(mapping, mpd.first_page, mpd.last_page);
//涉及块设备层的知识,后面会有专门文章分析block layer,主要作用是将做bio合并,构造出request,提升io效率。
blk_start_plug(&plug);
/*
* First writeback pages that don't need mapping - we can avoid
* starting a transaction unnecessarily and also avoid being blocked
* in the block layer on device congestion while having transaction
* started.
*/
//内核一个io性能优化引入的修改,do_map因为这此时不能做block map动作,前面有文章介绍
mpd.do_map = 0;
mpd.scanned_until_end = 0;
mpd.io_submit.io_end = ext4_init_io_end(inode, GFP_KERNEL);
if (!mpd.io_submit.io_end) {
ret = -ENOMEM;
goto unplug;
}
//核心函数,作用是尝试准备extent,由于上面设置了do_map,这里只针对buffer_mapped的page
ret = mpage_prepare_extent_to_map(&mpd);
/* Unlock pages we didn't use */
mpage_release_unused_pages(&mpd, false);
/* Submit prepared bio */
//调用submit_bio向block layer提交请求
ext4_io_submit(&mpd.io_submit);
ext4_put_io_end_defer(mpd.io_submit.io_end);
mpd.io_submit.io_end = NULL;
if (ret < 0)
goto unplug;
//循环回写,直接达到文件末尾或者写完数据
while (!mpd.scanned_until_end && wbc->nr_to_write > 0) {
/* For each extent of pages we use new io_end */
mpd.io_submit.io_end = ext4_init_io_end(inode, GFP_KERNEL);
if (!mpd.io_submit.io_end) {
ret = -ENOMEM;
break;
}
/*
* We have two constraints: We find one extent to map and we
* must always write out whole page (makes a difference when
* blocksize < pagesize) so that we don't block on IO when we
* try to write out the rest of the page. Journalled mode is
* not supported by delalloc.
*/
BUG_ON(ext4_should_journal_data(inode));
needed_blocks = ext4_da_writepages_trans_blocks(inode);
/* start a new transaction */
handle = ext4_journal_start_with_reserve(inode,
EXT4_HT_WRITE_PAGE, needed_blocks, rsv_blocks);
if (IS_ERR(handle)) {
ret = PTR_ERR(handle);
ext4_msg(inode->i_sb, KERN_CRIT, "%s: jbd2_start: "
"%ld pages, ino %lu; err %d", __func__,
wbc->nr_to_write, inode->i_ino, ret);
/* Release allocated io_end */
ext4_put_io_end(mpd.io_submit.io_end);
mpd.io_submit.io_end = NULL;
break;
}
mpd.do_map = 1;
trace_ext4_da_write_pages(inode, mpd.first_page, mpd.wbc);
ret = mpage_prepare_extent_to_map(&mpd);
if (!ret && mpd.map.m_len)
ret = mpage_map_and_submit_extent(handle, &mpd,
&give_up_on_write);
/*
* Caution: If the handle is synchronous,
* ext4_journal_stop() can wait for transaction commit
* to finish which may depend on writeback of pages to
* complete or on page lock to be released. In that
* case, we have to wait until after after we have
* submitted all the IO, released page locks we hold,
* and dropped io_end reference (for extent conversion
* to be able to complete) before stopping the handle.
*/
if (!ext4_handle_valid(handle) || handle->h_sync == 0) {
ext4_journal_stop(handle);
handle = NULL;
mpd.do_map = 0;
}
/* Unlock pages we didn't use */
mpage_release_unused_pages(&mpd, give_up_on_write);
/* Submit prepared bio */
ext4_io_submit(&mpd.io_submit);
/*
* Drop our io_end reference we got from init. We have
* to be careful and use deferred io_end finishing if
* we are still holding the transaction as we can
* release the last reference to io_end which may end
* up doing unwritten extent conversion.
*/
if (handle) {
ext4_put_io_end_defer(mpd.io_submit.io_end);
ext4_journal_stop(handle);
} else
ext4_put_io_end(mpd.io_submit.io_end);
mpd.io_submit.io_end = NULL;
if (ret == -ENOSPC && sbi->s_journal) {
/*
* Commit the transaction which would
* free blocks released in the transaction
* and try again
*/
jbd2_journal_force_commit_nested(sbi->s_journal);
ret = 0;
continue;
}
/* Fatal error - ENOMEM, EIO... */
if (ret)
break;
}
unplug:
blk_finish_plug(&plug);
if (!ret && !cycled && wbc->nr_to_write > 0) {
cycled = 1;
mpd.last_page = writeback_index - 1;
mpd.first_page = 0;
goto retry;
}
/* Update index */
if (wbc->range_cyclic || (range_whole && wbc->nr_to_write > 0))
/*
* Set the writeback_index so that range_cyclic
* mode will write it back later
*/
mapping->writeback_index = mpd.first_page;
out_writepages:
trace_ext4_writepages_result(inode, wbc, ret,
nr_to_write - wbc->nr_to_write);
percpu_up_read(&sbi->s_writepages_rwsem);
return ret;
}核心逻辑:
- 如果是sync()或者wbc->tagged_writepage将调用tag_pages_for_writeback将first-last范围内的PAGECACHE_TAG_DIRTY的page cache tag修改成:PAGECACHE_TAG_TOWRITE,后面调用mpage_prepare_extent_to_map时候将只处理这部分的页面;
- 准备mpd数据结构
- 调用mpage_prepare_extent_to_map准备extent,在ext4中extent代表一块连续的block,这也是delay allocation的魅力,延迟分配就是要在ext4_writepages回写磁盘时尽量合并连续的block,连续的块就是extent。
- 可以看到mpage_prepare_extent_to_map连续调用了两次,这是由于一个优化patch,参考Linux pagecache writeback的一个性能优化patch分析_nginux的博客-CSDN博客,第一次调用该函数只针对覆盖写场景的buffer_mapped的page回写,这种场景下由于已经映射过物理块号,合完extent直接提交IO。第二次是针对buffer_delay延迟回写的场景,这种场景下没有映射物理block,还需要调用mpage_map_and_submit_extent完成块映射。
- 直接扫描到文件末尾或者会写完所需数据将退出循环。
mpage_prepare_extent_to_map
/*
* mpage_prepare_extent_to_map - find & lock contiguous range of dirty pages
* and underlying extent to map
*
* @mpd - where to look for pages
*
* Walk dirty pages in the mapping. If they are fully mapped, submit them for
* IO immediately. When we find a page which isn't mapped we start accumulating
* extent of buffers underlying these pages that needs mapping (formed by
* either delayed or unwritten buffers). We also lock the pages containing
* these buffers. The extent found is returned in @mpd structure (starting at
* mpd->lblk with length mpd->len blocks).
*
* Note that this function can attach bios to one io_end structure which are
* neither logically nor physically contiguous. Although it may seem as an
* unnecessary complication, it is actually inevitable in blocksize < pagesize
* case as we need to track IO to all buffers underlying a page in one io_end.
*/
static int mpage_prepare_extent_to_map(struct mpage_da_data *mpd)
{
struct address_space *mapping = mpd->inode->i_mapping;
struct pagevec pvec;
unsigned int nr_pages;
long left = mpd->wbc->nr_to_write;
pgoff_t index = mpd->first_page;
pgoff_t end = mpd->last_page;
xa_mark_t tag;
int i, err = 0;
int blkbits = mpd->inode->i_blkbits;
ext4_lblk_t lblk;
struct buffer_head *head;
if (mpd->wbc->sync_mode == WB_SYNC_ALL || mpd->wbc->tagged_writepages)
tag = PAGECACHE_TAG_TOWRITE;
else
tag = PAGECACHE_TAG_DIRTY;
pagevec_init(&pvec);
mpd->map.m_len = 0;
mpd->next_page = index;
while (index <= end) {
nr_pages = pagevec_lookup_range_tag(&pvec, mapping, &index, end,
tag);
if (nr_pages == 0)
break;
for (i = 0; i < nr_pages; i++) {
struct page *page = pvec.pages[i];
/*
* Accumulated enough dirty pages? This doesn't apply
* to WB_SYNC_ALL mode. For integrity sync we have to
* keep going because someone may be concurrently
* dirtying pages, and we might have synced a lot of
* newly appeared dirty pages, but have not synced all
* of the old dirty pages.
*/
if (mpd->wbc->sync_mode == WB_SYNC_NONE && left <= 0)
goto out;
/* If we can't merge this page, we are done. */
if (mpd->map.m_len > 0 && mpd->next_page != page->index)
goto out;
lock_page(page);
/*
* If the page is no longer dirty, or its mapping no
* longer corresponds to inode we are writing (which
* means it has been truncated or invalidated), or the
* page is already under writeback and we are not doing
* a data integrity writeback, skip the page
*/
if (!PageDirty(page) ||
(PageWriteback(page) &&
(mpd->wbc->sync_mode == WB_SYNC_NONE)) ||
unlikely(page->mapping != mapping)) {
unlock_page(page);
continue;
}
wait_on_page_writeback(page);
BUG_ON(PageWriteback(page));
if (mpd->map.m_len == 0)
mpd->first_page = page->index;
mpd->next_page = page->index + 1;
/* Add all dirty buffers to mpd */
lblk = ((ext4_lblk_t)page->index) <<
(PAGE_SHIFT - blkbits);
head = page_buffers(page);
err = mpage_process_page_bufs(mpd, head, head, lblk);
if (err <= 0)
goto out;
err = 0;
left--;
}
pagevec_release(&pvec);
cond_resched();
}
mpd->scanned_until_end = 1;
return 0;
out:
pagevec_release(&pvec);
return err;
}前面提到ext4_writepages会调用两次mpage_prepare_extent_to_map。
首次调用 mpage_prepare_extent_to_map处理覆盖写dirty page:
do_map = 0,会一直循环寻找可以合并的连续page cache,如果mpage_process_page_bufs返回0,代码停止将page cache继续向extent添加;返回1表示继续寻找后续的page cache看是否能添加到extent中。假设现在有覆盖写场景的dirty page,其状态会是:buffer_dirty和buffer_mapped, !buffer_delay和!buffer_unwritten。代码逻辑进入mpage_add_bh_to_extent中,会走到map->m_len ==0 返回true。
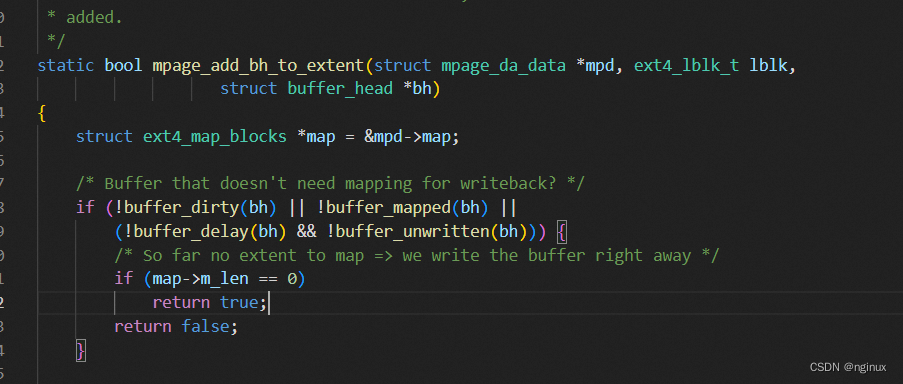
代码返回到 mpage_process_page_bufs进入mpd->map.m_len ==0,然后mpage_submit_page向块设备层提交io请求。

第二次调用mpage_prepare_extent_to_map:
我们重点看下对于delay allocation情况下怎么合并page cache到extent中的,重点其实是mpage_add_bh_to_extent函数的实现逻辑:
/*
* mpage_process_page_bufs - submit page buffers for IO or add them to extent
*
* @mpd - extent of blocks for mapping
* @head - the first buffer in the page
* @bh - buffer we should start processing from
* @lblk - logical number of the block in the file corresponding to @bh
*
* Walk through page buffers from @bh upto @head (exclusive) and either submit
* the page for IO if all buffers in this page were mapped and there's no
* accumulated extent of buffers to map or add buffers in the page to the
* extent of buffers to map. The function returns 1 if the caller can continue
* by processing the next page, 0 if it should stop adding buffers to the
* extent to map because we cannot extend it anymore. It can also return value
* < 0 in case of error during IO submission.
*/
static int mpage_process_page_bufs(struct mpage_da_data *mpd,
struct buffer_head *head,
struct buffer_head *bh,
ext4_lblk_t lblk)
{
struct inode *inode = mpd->inode;
int err;
ext4_lblk_t blocks = (i_size_read(inode) + i_blocksize(inode) - 1)
>> inode->i_blkbits;
if (ext4_verity_in_progress(inode))
blocks = EXT_MAX_BLOCKS;
do {
BUG_ON(buffer_locked(bh));
if (lblk >= blocks || !mpage_add_bh_to_extent(mpd, lblk, bh)) {
/* Found extent to map? */
if (mpd->map.m_len)
return 0;
/* Buffer needs mapping and handle is not started? */
if (!mpd->do_map)
return 0;
/* Everything mapped so far and we hit EOF */
break;
}
} while (lblk++, (bh = bh->b_this_page) != head);
/* So far everything mapped? Submit the page for IO. */
if (mpd->map.m_len == 0) {
err = mpage_submit_page(mpd, head->b_page);
if (err < 0)
return err;
}
if (lblk >= blocks) {
mpd->scanned_until_end = 1;
return 0;
}
return 1;
}
/*
* mpage_add_bh_to_extent - try to add bh to extent of blocks to map
*
* @mpd - extent of blocks
* @lblk - logical number of the block in the file
* @bh - buffer head we want to add to the extent
*
* The function is used to collect contig. blocks in the same state. If the
* buffer doesn't require mapping for writeback and we haven't started the
* extent of buffers to map yet, the function returns 'true' immediately - the
* caller can write the buffer right away. Otherwise the function returns true
* if the block has been added to the extent, false if the block couldn't be
* added.
*/
static bool mpage_add_bh_to_extent(struct mpage_da_data *mpd, ext4_lblk_t lblk,
struct buffer_head *bh)
{
struct ext4_map_blocks *map = &mpd->map;
/* Buffer that doesn't need mapping for writeback? */
//有些情况下page cache不需要向extent中添加了
if (!buffer_dirty(bh) || !buffer_mapped(bh) ||
(!buffer_delay(bh) && !buffer_unwritten(bh))) {
/* So far no extent to map => we write the buffer right away */
//覆盖写的场景触发
if (map->m_len == 0)
return true;
return false;
}
//extent中第一个block,设置一些map的字段
/* First block in the extent? */
if (map->m_len == 0) {
/* We cannot map unless handle is started... */
if (!mpd->do_map)
return false;
map->m_lblk = lblk;
map->m_len = 1;
map->m_flags = bh->b_state & BH_FLAGS;
return true;
}
//extent中包含的连续block不能超过2048个,超过之后就返回false,表示不继续添加extent了
/* Don't go larger than mballoc is willing to allocate */
if (map->m_len >= MAX_WRITEPAGES_EXTENT_LEN)
return false;
//如果当前page对应的逻辑块号和extent中的连续,且状态一致,map->m_len++,表示继续添加到了
//extent中。
/* Can we merge the block to our big extent? */
if (lblk == map->m_lblk + map->m_len &&
(bh->b_state & BH_FLAGS) == map->m_flags) {
map->m_len++;
return true;
}
return false;
}
mpage_map_and_submit_extent函数
前面mpage_prepare_extent_to_map准备了好了一个extent,接下来就要开始做map,所以mpage_prepare_extent_to_map这个函数的名字就是很形象,准备”extent" to “map",所谓的map就是将extent中的逻辑块号分配映射物理块号,mpage_map_and_submit_extent完成这个逻辑,在这里就不列代表,图示整体流程:
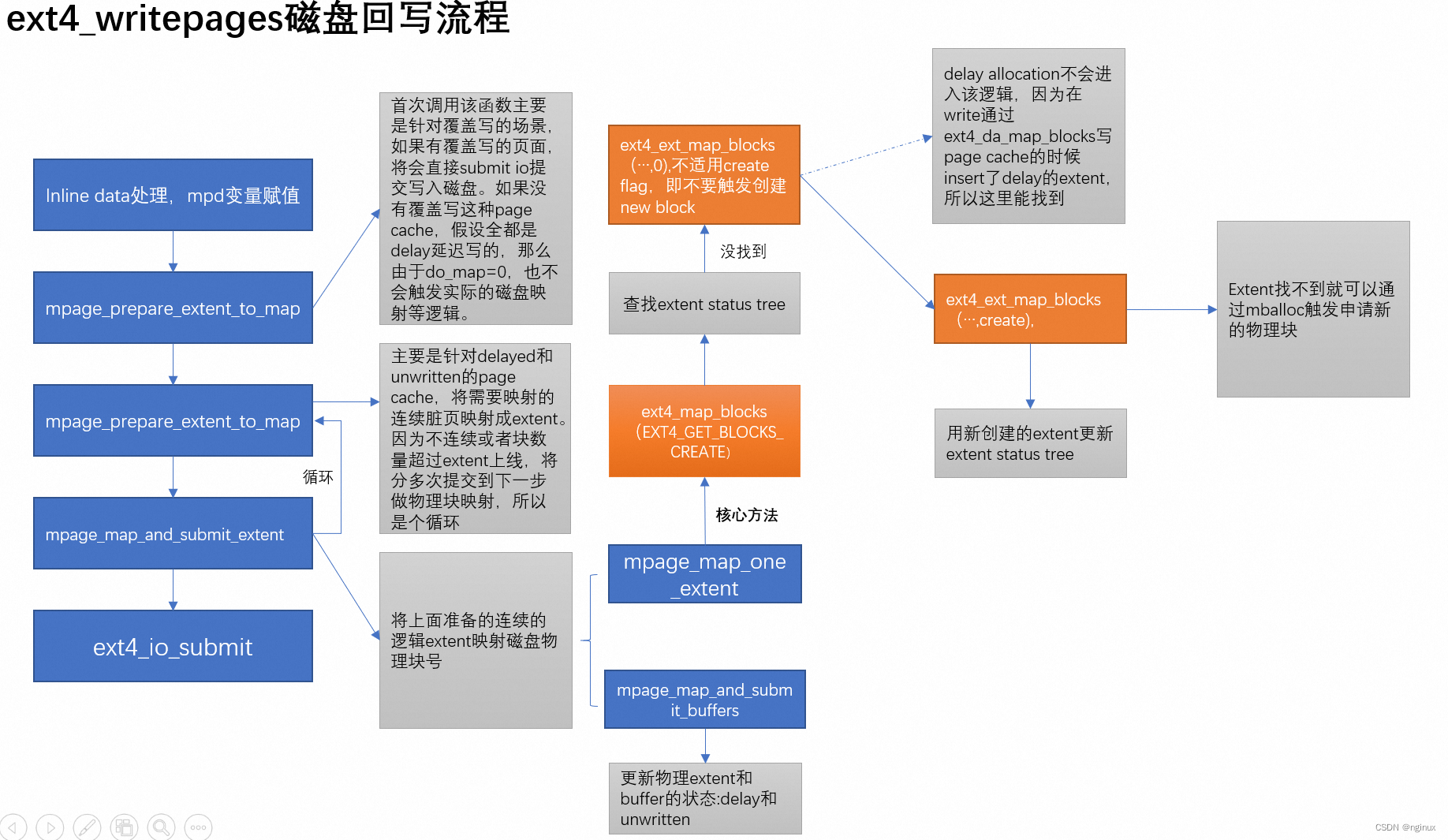
ext4_ext_map_blocks
/*
* Block allocation/map/preallocation routine for extents based files
*
*
* Need to be called with
* down_read(&EXT4_I(inode)->i_data_sem) if not allocating file system block
* (ie, create is zero). Otherwise down_write(&EXT4_I(inode)->i_data_sem)
*
* return > 0, number of of blocks already mapped/allocated
* if create == 0 and these are pre-allocated blocks
* buffer head is unmapped
* otherwise blocks are mapped
*
* return = 0, if plain look up failed (blocks have not been allocated)
* buffer head is unmapped
*
* return < 0, error case.
*/
int ext4_ext_map_blocks(handle_t *handle, struct inode *inode,
struct ext4_map_blocks *map, int flags)
{
struct ext4_ext_path *path = NULL;
struct ext4_extent newex, *ex, *ex2;
struct ext4_sb_info *sbi = EXT4_SB(inode->i_sb);
ext4_fsblk_t newblock = 0, pblk;
int err = 0, depth, ret;
unsigned int allocated = 0, offset = 0;
unsigned int allocated_clusters = 0;
struct ext4_allocation_request ar;
ext4_lblk_t cluster_offset;
ext_debug(inode, "blocks %u/%u requested\n", map->m_lblk, map->m_len);
trace_ext4_ext_map_blocks_enter(inode, map->m_lblk, map->m_len, flags);
/* find extent for this block */
path = ext4_find_extent(inode, map->m_lblk, NULL, 0);
if (IS_ERR(path)) {
err = PTR_ERR(path);
path = NULL;
goto out;
}
depth = ext_depth(inode);
...
ex = path[depth].p_ext;
if (ex) {
ext4_lblk_t ee_block = le32_to_cpu(ex->ee_block);
ext4_fsblk_t ee_start = ext4_ext_pblock(ex);
unsigned short ee_len;
/*
* unwritten extents are treated as holes, except that
* we split out initialized portions during a write.
*/
ee_len = ext4_ext_get_actual_len(ex);
trace_ext4_ext_show_extent(inode, ee_block, ee_start, ee_len);
/* if found extent covers block, simply return it */
if (in_range(map->m_lblk, ee_block, ee_len)) {
newblock = map->m_lblk - ee_block + ee_start;
/* number of remaining blocks in the extent */
allocated = ee_len - (map->m_lblk - ee_block);
ext_debug(inode, "%u fit into %u:%d -> %llu\n",
map->m_lblk, ee_block, ee_len, newblock);
/*
* If the extent is initialized check whether the
* caller wants to convert it to unwritten.
*/
if ((!ext4_ext_is_unwritten(ex)) &&
(flags & EXT4_GET_BLOCKS_CONVERT_UNWRITTEN)) {
err = convert_initialized_extent(handle,
inode, map, &path, &allocated);
goto out;
} else if (!ext4_ext_is_unwritten(ex)) {
map->m_flags |= EXT4_MAP_MAPPED;
map->m_pblk = newblock;
if (allocated > map->m_len)
allocated = map->m_len;
map->m_len = allocated;
ext4_ext_show_leaf(inode, path);
goto out;
}
ret = ext4_ext_handle_unwritten_extents(
handle, inode, map, &path, flags,
allocated, newblock);
if (ret < 0)
err = ret;
else
allocated = ret;
goto out;
}
}
...
/*
* Okay, we need to do block allocation.
*/
...
if (map->m_len > EXT_INIT_MAX_LEN &&
!(flags & EXT4_GET_BLOCKS_UNWRIT_EXT))
map->m_len = EXT_INIT_MAX_LEN;
else if (map->m_len > EXT_UNWRITTEN_MAX_LEN &&
(flags & EXT4_GET_BLOCKS_UNWRIT_EXT))
map->m_len = EXT_UNWRITTEN_MAX_LEN;
/* Check if we can really insert (m_lblk)::(m_lblk + m_len) extent */
newex.ee_len = cpu_to_le16(map->m_len);
err = ext4_ext_check_overlap(sbi, inode, &newex, path);
if (err)
allocated = ext4_ext_get_actual_len(&newex);
else
//正常都会走到该流程,map->m_len代表一个连续的extent的length
allocated = map->m_len;
/* allocate new block */
ar.inode = inode;
//确定申请的目标physical block,尽量保持连续性,避免碎片化。
ar.goal = ext4_ext_find_goal(inode, path, map->m_lblk);
ar.logical = map->m_lblk;
/*
* We calculate the offset from the beginning of the cluster
* for the logical block number, since when we allocate a
* physical cluster, the physical block should start at the
* same offset from the beginning of the cluster. This is
* needed so that future calls to get_implied_cluster_alloc()
* work correctly.
*/
offset = EXT4_LBLK_COFF(sbi, map->m_lblk);
ar.len = EXT4_NUM_B2C(sbi, offset+allocated);
ar.goal -= offset;
ar.logical -= offset;
if (S_ISREG(inode->i_mode))
ar.flags = EXT4_MB_HINT_DATA;
else
/* disable in-core preallocation for non-regular files */
ar.flags = 0;
if (flags & EXT4_GET_BLOCKS_NO_NORMALIZE)
ar.flags |= EXT4_MB_HINT_NOPREALLOC;
if (flags & EXT4_GET_BLOCKS_DELALLOC_RESERVE)
ar.flags |= EXT4_MB_DELALLOC_RESERVED;
if (flags & EXT4_GET_BLOCKS_METADATA_NOFAIL)
ar.flags |= EXT4_MB_USE_RESERVED;
//非常重要,执行分配physical block逻辑
newblock = ext4_mb_new_blocks(handle, &ar, &err);
if (!newblock)
goto out;
allocated_clusters = ar.len;
ar.len = EXT4_C2B(sbi, ar.len) - offset;
ext_debug(inode, "allocate new block: goal %llu, found %llu/%u, requested %u\n",
ar.goal, newblock, ar.len, allocated);
if (ar.len > allocated)
ar.len = allocated;
got_allocated_blocks:
/* try to insert new extent into found leaf and return */
pblk = newblock + offset;
ext4_ext_store_pblock(&newex, pblk);
newex.ee_len = cpu_to_le16(ar.len);
/* Mark unwritten */
if (flags & EXT4_GET_BLOCKS_UNWRIT_EXT) {
ext4_ext_mark_unwritten(&newex);
map->m_flags |= EXT4_MAP_UNWRITTEN;
}
//新创建的extent插入extent b+树
err = ext4_ext_insert_extent(handle, inode, &path, &newex, flags);
if (err) {
if (allocated_clusters) {
int fb_flags = 0;
/*
* free data blocks we just allocated.
* not a good idea to call discard here directly,
* but otherwise we'd need to call it every free().
*/
ext4_discard_preallocations(inode, 0);
if (flags & EXT4_GET_BLOCKS_DELALLOC_RESERVE)
fb_flags = EXT4_FREE_BLOCKS_NO_QUOT_UPDATE;
ext4_free_blocks(handle, inode, NULL, newblock,
EXT4_C2B(sbi, allocated_clusters),
fb_flags);
}
goto out;
}
...
map->m_flags |= (EXT4_MAP_NEW | EXT4_MAP_MAPPED);
map->m_pblk = pblk;
map->m_len = ar.len;
allocated = map->m_len;
ext4_ext_show_leaf(inode, path);
out:
ext4_ext_drop_refs(path);
kfree(path);
trace_ext4_ext_map_blocks_exit(inode, flags, map,
err ? err : allocated);
return err ? err : allocated;
}1. ext4_find_extent:
作用:读取inode在磁盘上的extent tree,查找block对应的extent,保存在返回值ext4_ext_path中。
struct ext4_ext_path *
ext4_find_extent(struct inode *inode, ext4_lblk_t block,
struct ext4_ext_path **orig_path, int flags);
在ext4 extent B+树每一层索引节点(包含根节点)中找到起始逻辑块地址最接近传入的起始逻辑块地址的extent,路径上的ext4_extent_idx保存到path[ppos]->p_idx。然后找到最后一层叶子节点最接近传入逻辑块地址map->m_lblk的ext4_extent结构,保存到path[ppos]->p_ext,这个ext4_entent有可能包含了map->m_lblk,也有可能不包含,不包含的情况path[ppos]->p_ext是小于map->lblk,且最接近map->lblk的extent,比如:

注意图中的数字是logical block number范围,而不是phsycial block number。
2. 如果ext4_find_extent查找结果中不包含block,可以进入block allocation逻辑(延迟写场景flag指定了create),要初始化一个ext4_allocation_request对象,其中很重要的是ar.goal,其计算逻辑:
static ext4_fsblk_t ext4_ext_find_goal(struct inode *inode,
struct ext4_ext_path *path,
ext4_lblk_t block)
{
if (path) {
int depth = path->p_depth;
struct ext4_extent *ex;
/*
* Try to predict block placement assuming that we are
* filling in a file which will eventually be
* non-sparse --- i.e., in the case of libbfd writing
* an ELF object sections out-of-order but in a way
* the eventually results in a contiguous object or
* executable file, or some database extending a table
* space file. However, this is actually somewhat
* non-ideal if we are writing a sparse file such as
* qemu or KVM writing a raw image file that is going
* to stay fairly sparse, since it will end up
* fragmenting the file system's free space. Maybe we
* should have some hueristics or some way to allow
* userspace to pass a hint to file system,
* especially if the latter case turns out to be
* common.
*/
ex = path[depth].p_ext;
if (ex) {
//比如上图中目标logical block number = 92,这个时候92 > 90,那么
//从ext_pblk + 2处能分配物理块号,尽量保持phsycial block连续性
ext4_fsblk_t ext_pblk = ext4_ext_pblock(ex);
ext4_lblk_t ext_block = le32_to_cpu(ex->ee_block);
if (block > ext_block)
return ext_pblk + (block - ext_block);
else
return ext_pblk - (ext_block - block);
}
/* it looks like index is empty;
* try to find starting block from index itself */
if (path[depth].p_bh)
return path[depth].p_bh->b_blocknr;
}
/* OK. use inode's group */
//inode刚创建没有path,使用inode's group分配一个phsycial block number
return ext4_inode_to_goal_block(inode);
}普通文件writeback完成的回调函数是哪里
ext4_end_bio:
remote Thread 1.1 In: end_page_writeback L1457 PC: 0xffffffff8132d1b3
#0 end_page_writeback (page=0xffffea00000e4540) at mm/filemap.c:1457
#1 0xffffffff815b07a1 in ext4_finish_bio (bio=0xffff888000b01600) at fs/ext4/page-io.c:146
#2 0xffffffff815b10ab in ext4_end_bio (bio=0xffff888000b01600) at fs/ext4/page-io.c:368
#3 0xffffffff817669f4 in bio_endio (bio=0xffff888000b01600) at block/bio.c:1449
#4 0xffffffff8176ebc0 in req_bio_endio (error=<optimized out>, nbytes=<optimized out>, bio=<optimized out>, rq=<optimized out>) at block/blk-core.c:259
#5 blk_update_request (req=0xffff88800005cf00, error=<optimized out>, nr_bytes=126976) at block/blk-core.c:1577
#6 0xffffffff817829c2 in blk_mq_end_request (rq=0xffff88800005cf00, error=<optimized out>) at ./include/linux/blkdev.h:976
#7 0xffffffff81cb5306 in virtblk_request_done (req=0xffff88800005cf00) at drivers/block/virtio_blk.c:171
#8 0xffffffff8177f53c in blk_done_softirq (h=<optimized out>) at block/blk-mq.c:586
#9 0xffffffff82800102 in __do_softirq () at kernel/softirq.c:298
#10 0xffffffff82600f82 in asm_call_on_stack () at arch/x86/entry/entry_64.S:708
参考文章:















 3381
3381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









