







printf是我们c语言中常用的打印输出函数,原型为int printf(const char *format,[argument]),需要包含头文件stdio.h
format 参数输出的格式,定义格式为:%[flags][width][.prec][F|N|h|l]type
format为一个字符串,定义了以后给出的参数的类型,但是printf并不对参数类型进行检验,只是按照format中给出的格式进行解读,这就好比我们用看一本书,英文的书籍应该按照英文格式来读才能读的正确,如果按照拼音来读的话,那么就要读成天书了,所以给printf一个正确参数类型就至关重要,否则会产生不确定输出。
来看一个例子:
#include<stdio.h>
void main()
{
double a=1;
int b=2;
printf("%d,%d\n",a,b);
float n1=3.0;
double n2=3.0;
long n3=2000000000;
long n4=1234567890;
printf("%d,%ld,%ld,%ld\n", n1, n2, n3, n4);
int i = 0;
printf("%d, %d, %d\n", i++, i++, i++);
}0,1072693248
0,1074266112,0,1074266112
2, 1, 0不按照参数类型来写参数格式列表的结果就是得不到我们想要的结果,现在我们来分析下这些结果是怎么来的
先来明确几个问题:
1.printf的入栈顺序和顺序点。
c语言中函数参数的入栈顺序是由编译器优化以及平台决定的,还可以用修饰符来修饰,这是与实现相关的,我们应尽量避免假设函数入栈顺序是自右向左的, 并无畏的加以应用.不管是编译器bug, 还是其它, 我们都要要考虑不同编译器/版本差异会引起的结果差异.一旦你的程序需要使用入栈顺序和顺序点等c语言中的未定义地带来分析,那么这种编程风格就该改一下了。
#include <stdio.h>
#include <stdlib.h>
int bar()
{
return 20;
}
int main()
{
int len = 3;
printf("%d, %d\n", len=bar(), len);
return 0;
}gcc 3.4.3, gcc 3.4.4 输出结果为: 20, 20
gcc 3.2.2 及以下输出结果为: 20, 3
VC++ 6.0 输出结果为: 20, 3
该程序在 windows, linux, cygwin (x86, arm, mips) 上均得到同上的结果.
char *Func(int n)
{
static char s[20];
sprintf(s, "number %d", n);
return s;
}
main()
{
printf("%s, %s\n", Func(1), Func(2));
}输出:number 1,number 1 解析:先入栈Func(2)得到s = number 2,然后是Func(1) s=number 1 由于是静态变量,到顺序点以后结 算s = number 1,所以都打印这个
这个程序又陷入了函数参数入栈顺序和顺序点的问题,我们要避免这种要入栈顺序和顺序点会造成副作用的函数用法
2.float和double的存储形式
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit,double数据占用64bit,不论是float还是double在存储方式上都是遵从IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。
无论是单精度还是双精度在存储中都分为三个部分:
- 符号位(Sign) : 0代表正,1代表为负
- 指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
- 尾数部分(Mantissa):尾数部分
其中float的存储方式如下图所示:
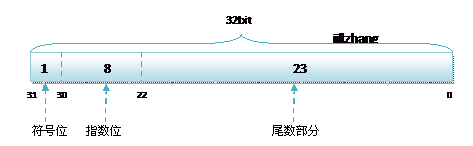
而双精度double的存储方式为:

我们举两个例子,比如8.5用十进制的科学计数法表示就为:8.5*![]() ,而118.5可以表示为:1.185*
,而118.5可以表示为:1.185*![]() ,而计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.5用二进制表示可表示为1000.1,118.5用二进制表示为:1110110.1。用二进制的科学计数法表示1000.1可以表示为1.0001*
,而计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.5用二进制表示可表示为1000.1,118.5用二进制表示为:1110110.1。用二进制的科学计数法表示1000.1可以表示为1.0001*![]() ,1110110.1可以表示为1.1101101*
,1110110.1可以表示为1.1101101*![]() ,任何一个数都的科学计数法表示都为1.xxx*
,任何一个数都的科学计数法表示都为1.xxx*![]() ,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据 127,下面就看看8.5和118.5在内存中真正的存储方式。
,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据 127,下面就看看8.5和118.5在内存中真正的存储方式。
首先看下8.5,用二进制的科学计数法表示为:1.0001*![]()
按照上面的存储方式,符号位为:0,表示为正,指数位为:3+127=130 ,位数部分为,故8.5的存储方式如下图所示:
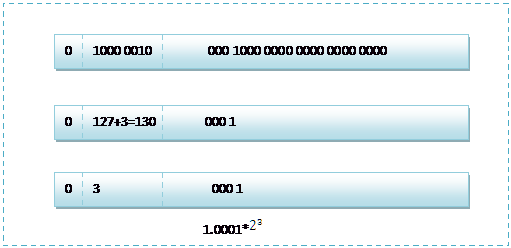
16进制为:0x41080000
而单精度浮点数118.5的存储方式如下图所示:
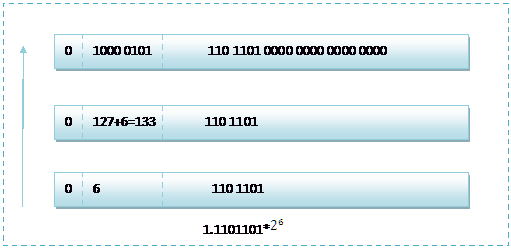
16进制为:0x42ED0000
而双精度浮点数的存储和单精度的存储大同小异,不同的是指数部分和尾数部分的位数,下面是118.5的双精度存储方式图

16进制为:0x405DA000 0000000
8.5的双精度表示为:
0 100 0000 0010 0001 0000 0000 0000 00000 0000 0000 0000 0000 0000 0000 0000 0000所以,同样一个数,精度互相转化有时候就会产生变化,float转化成为double,只是精度不会损失,但不保证数还是原来那个数,而double转化成为float连精度都会损失,同一个数值在内存中的表示float和double格式是不同的,所以printf选对参数是至关重要的(float和double之间都是用f没区别,但是和int混用不会的得到想要的结果)
看下面这个程序:
float f = 2.2f;
double d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
f = 2.25f;
d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));单精度的2.2转换为双精度后,精确到小数点后13位后变为了2.2000000476837,而单精度的2.25转换为双精度后,变为了2.2500000000000,为何2.2在转换后的数值更改了而2.25却没有更改呢?很奇怪吧?其实通过上面关于两种存储结果的介绍,我们已经大概能找到答案。首先我们看看2.25的单精度存储方式,很简单 0 1000 0000 001 0000 0000 0000 0000 0000,而2.25的双精度表示为:0 100 0000 0000 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000,这样2.25在进行强制转换的时候,数值是不会变的,而我们再看看2.2呢,2.2用科学计数法表示应该为:将十进制的小数转换为二进制的小数的方法为将小数*2,取整数部分,所以0.2*2=0.4,所以二进制小数第一位为0.4的整数部分0,0.4×2=0.8,第二位为0,0.8*2=1.6,第三位为1,0.6×2 = 1.2,第四位为1,0.2*2=0.4,第五位为0,这样永远也不可能乘到=1.0,得到的二进制是一个无限循环的排列 00110011001100110011... ,对于单精度数据来说,尾数只能表示24bit的精度,所以2.2的float存储为:0 1000 0000 000 1100 1100 1100 1100 1100 , double的存储为0 100 0000 0000 0001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001,16进制表示为:0x40019999 99999999,对于能用二进制表示的十进制数据,如2.25这个误差就不存在。
3.printf关于float和double的解析
printf函数中,%f可以用于float和double类型,%f是按照64位(8字节)进行读取的,在printf中使用%f参数是将float类型隐式转换成为double,然后再进行使用。
现在我们回到一开始的程序,分析第一个打印printf("%d,%d\n",a,b);,这里面b先入栈位于栈的最底层,然后是a入栈,由于a是个double的类型,在内存中占64位,但是当printf使用参数表分析参数类型时,使用%d来解析数据,先从栈顶开始数32位进行第一个打印,然后再取出32位进行第二次打印,这样就都是取出的a的数据,1的双精度浮点表示在内存中是:0 011 1111 1111 0000 0000……也就是0x3FF00000 00000000,分解成为两个32位分别为:1072693248和0,第一个打印的就是这两个数值, 在栈里的存储如下所示
| 00 00 00 00 |<--ESP
| 3F F0 00 00 |
| 00 00 00 02 | <-EBP
第二个打印,n1和n2在printf中都是以double存在的,3二进制位11,表示为:1.1×2^1 => 指数部分127+1=128 小数部分为1,所以double的表示为:0 100 0000 0000 1000 0000 0000 0000 0000……,也就是0x40800000,打印出的十进制就是1074266112。栈中的位置类似
第三个打印,是取决于入栈顺序,从右向左入栈就会得出结果。
另外,再说一下,printf中的\n,\r这两个转义字符。
CR(Carriage Return)是回车这个动作。---》\r
LF(Line Feed)才是走纸换行。--->\n
“一行结束了,新的一行开始了”的符号叫做EOL(end of line)。
DOS和Windows操作系统的EOL,是CR+LF
Mac操作系统的EOL,是CR
Unix和Linux操作系统的EOL,是LF
UNIX对换行只用LF,Windows用CR+LF。但是逻辑上是LF,\n就行了,由于Windows的EOL是CR+LF,所以printf("\n"),在Windows操作系统中会被调整为类似于putchar('\r');putchar('\n');的效果.但是使用printf("\r")就仅仅只有回车的作用,在linux和windows中都是如此,不能换行。
参考文章:http://bbs.chinaunix.net/forum.php?mod=viewthread&tid=984644
http://bbs.chinaunix.net/thread-1010016-3-1.html
http://www.cnblogs.com/Xiao_bird/archive/2010/03/26/1696908.html
http://bbs.csdn.net/topics/390321020
http://bbs.chinaunix.net/thread-473288-1-1.html















 5629
5629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









