






describe
比如:df一个dataframe
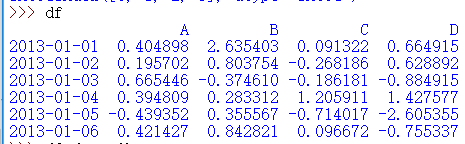
它的describe字段计算如下

其中
count:数出有该列有多少行数据
mean:该列的平均值
std:标准偏差值,即为方差开根号【√(Σ(x-E(x))²)/n】
min:最小值
25%:正好有25%的样本比这个值高
50%:正好有50%的样本比这个值高,即中位数
75%:正好有75%的样本比这个值高
max:最大值
而其中75百分位A列计算解释(25%同理)如下:

公式为:formula = percentile * n (n is number of values)
从小到大依次是
-0.439352、0.195702、0.394809
、0.404898、0.421427、0.665446
(6-1)/4×3=4.75
所以变为0.25×0.404898+0.75×0.421427
即75%×(0.421427-0.404898)+0.404898
=0.75×0.016529+0.404898
=0.41729475 即为所求
与显示0.417294省略后面两位不进行四舍五入。
首先确定四分位数的位置:
Q1的位置= (n+1) × 0.25
Q2的位置= (n+1) × 0.5
Q3的位置= (n+1) × 0.75
n表示项数
对于四分位数的确定,有不同的方法,另外一种方法基于N-1 基础。即
Q1的位置=1+(n-1)x 0.25
Q2的位置=1+(n-1)x 0.5
Q3的位置=1+(n-1)x 0.75
1、将数据从小到大排序,计为数组a(1 to n),n代表数据的长度
2、确定四分位数的位置:b= 1+(n-1) × 0.25= 2.25,b的整数部分计为c b的小数部分计为d
计算Q1:Q1=a©+[a(c+1)-a©]*d=a(2)+[a(3)-a(2)] *0.25 =15+(36-15)×(2.25-2)=20.25
3、计算如上 Q2与Q3的求法类似,四分位差=Q3-Q1















 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









