






本篇以我自己的网站为例来通俗易懂的讲述网站的常见漏洞,如何防止网站被入侵,如何让网站更安全。
要想足够安全,首先得知道其中的道理。
本文例子通俗易懂,主要讲述了 各种漏洞 的原理及防护,相比网上其它的web安全入门文章来说,本文更丰富,更加具有实战性和趣味性。
本文讲解目录大致如下,讲述什么是暴力破解、xss、csrf、挂马等原理及对应的防护。
对手机验证码登录方式进行暴力破解及防护
无视验证码而无限注册账号原理及防护
什么是XSS?通过留言板来了解XSS
什么是CSRF?如何应对?
DDOS的原理及防护
挂马的原理,如何防止网站被挂马?
什么是钓鱼网站,如何避免钓鱼网站
什么是安全渗透测试
这里提前做个部署概念讲解: 客户端,即当前的 浏览器 软件 。 服务端 , 如 我是.net , 那么如果我想让我的网站放到互联网上让你也能够在线浏览的话, 我需要对我的vs项目进行打包,然后选择一台电脑,这台电脑最好装着 windows server系列的系统(够专业) 来做服务器(也就是说服务器 就是 一台 和你平常用的电脑系统不一样,配置不一样,专门用于服务的电脑),然后我再在这台 电脑上(服务器) 装上一个 名叫 IIS Web服务器 的 一款软件,然后在这个软件上进行操作,把我的包给导入在这个软件中。这样,这个名叫 IIS Web服务器的软件就会 对包解析,然后再经过其它的相关配置,最终,你能够从互联网上点击浏览到我的网站。
所以,我下文的服务器,不要把这个名词想的太高大上,就是一款软件而已。
像搞JAVA的,无论是Linux还是Windows都可以当做服务器系统,还可以有众多web服务器软件可以选择,WebSphere 服务器、JBoss服务器等。
而.Net因为环境封闭,所以只能用微软的东西,windows+IIs,唯一区别就是版本了。
我的网站环境: windows server2008 R2 + IIS7.5
接下来我要简单的介绍下我网站的结构。
我的网站是一个轻博客网站,叫做1996v轻博客,用户可以注册账号后在我的网站上发布博客,也可以通过我发放的权限自由的更改页面结构。
我的网站分为 前台展示+后台设置 两部分组成 , 废话不说了,上图。
对手机验证码进行暴力破解及防护
前台页面的所有展示都是由后台控制的,接下来我们先从 登录页面 开始 , 看看 有什么漏洞。
下图就是登录页面,乍一看,这个页面挺干净的,就一个登录按钮的单击事件,和正常的网站的登录一样,漏洞,入侵,从哪去挖掘,又谈何说起呢?
别急,我们按F12打开开发者控制台(我的浏览器是谷歌浏览器)。
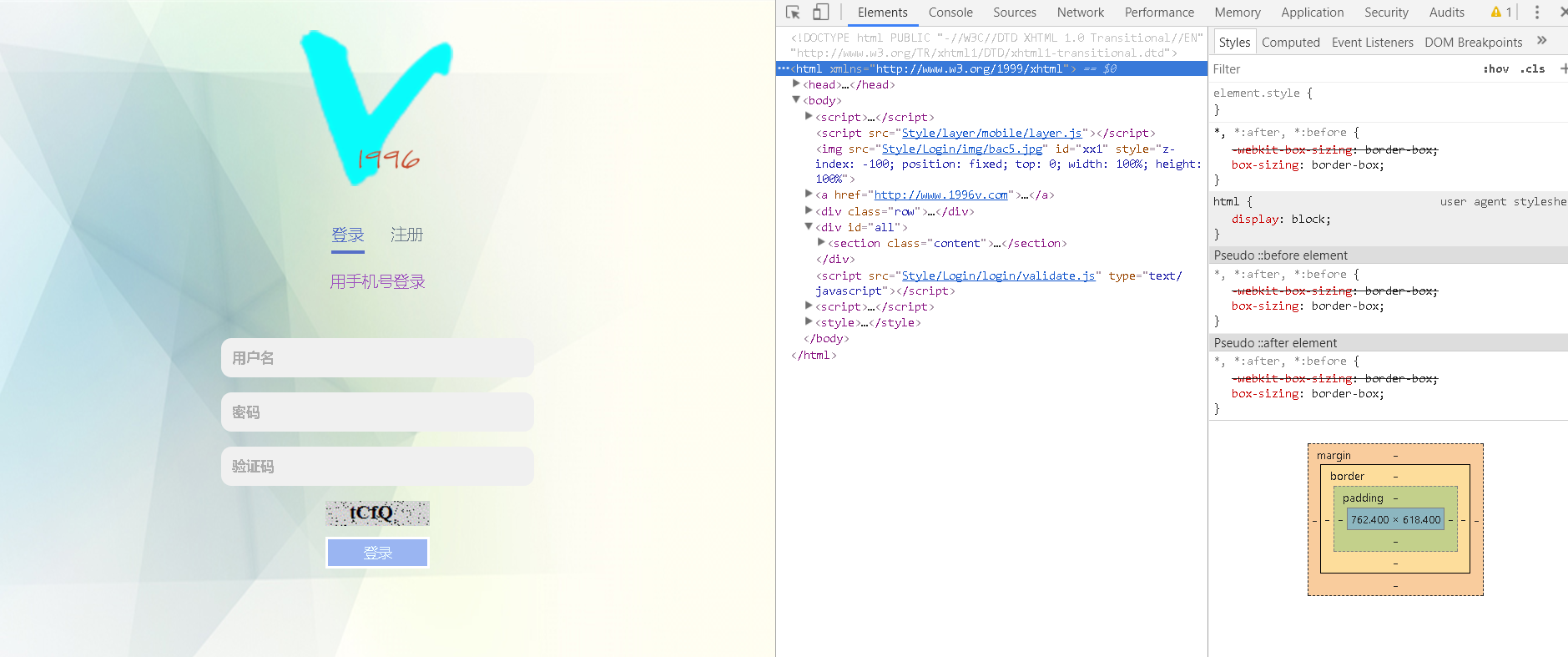
因为我不确定当前看我 文章的都是什么群体,所以我会尽可能的写的够详细,不要嫌我啰嗦,我现在要简单介绍下F12 开发者控制台是什么。
如图,当你按下F12后,右侧会弹出个框,这个就是开发者控制台。上面有一列选项卡,我这里尽对前四个做下说明。
1. Elements 查看当前文档的DOM信息, 也就是可以看到当前页面经过浏览器渲染后最终呈现出来的html。
2. Console 控制台,可以直接在这里面敲代码,可以得到即时响应。
3. Source 查看当前站点的资源文件,在这里面可以看到当前站点下(www.1996v.com)的当前页面加载的所需源文件。
4. Network 这个主要是用来查看当前的页面的一些网络请求。
开发者控制台主要是给前端或者全栈开发师用的,可以获取和分析被查看的页面,基本上主流浏览器都有这个功能,通常是按F12将其打开。
现在,我们先选择手机登录:
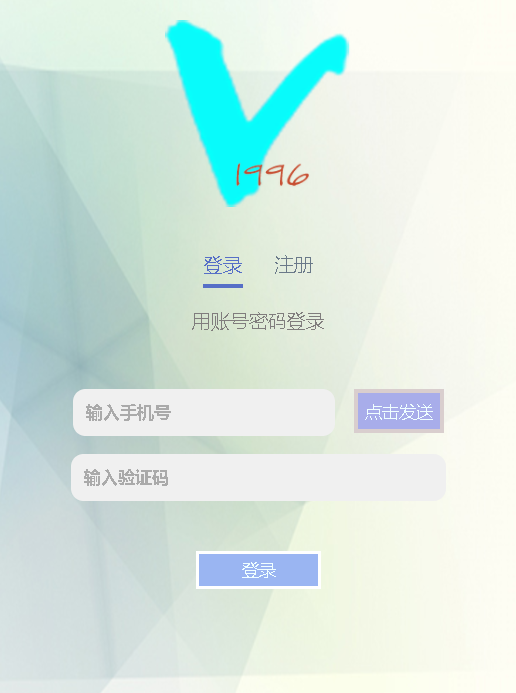
这是我的登录界面,可以看到,用户可以自由选择用手机号去登录,和用账号密码去登录这两种登录方式。
先说下手机号去登录:
下面是我网站的手机登录的大致实现逻辑,放图:
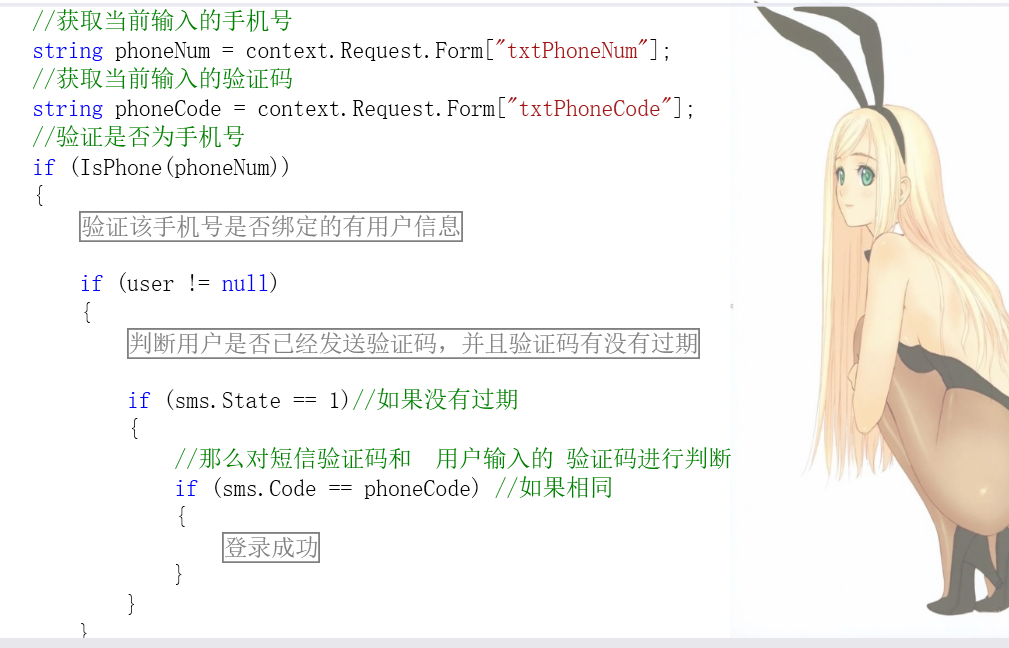
整体流程为,当用户输入手机号发送验证并填写验证码点击登录按钮的时候,我的后台,会接收到用户填写的 手机号 和 验证码 , 如果 验证码与运营商返回给我的验证码相同的话,那么就登录成功。
讲道理,这段代码没毛病,逻辑没毛病,总之,必须你输入对了正确的手机号和对应的正确的验证码你才能登录,否则,你怎么也登录不了。
但是,我还是能破解的!
首先,我经过多次测试,我知道 每次返回的验证码 是由4个数字组成,其次,验证码过期时间为1小时,而如果成功登录,会返回我一个状态码:1。
4个数字,无非就是0001~9999中间的一个!
也就是说,我只要在1个小时内,我一条条试,顶多9999次,肯定有一次能输入对!
而只要输对了,那就是一件很恐怖的事,我成功的登录了你的账号,去寻找我想要的东西。
那么,首先,我先从控制台中的Source来查看网页的源文件,进而知道登录的接口的地址以及参数名称,
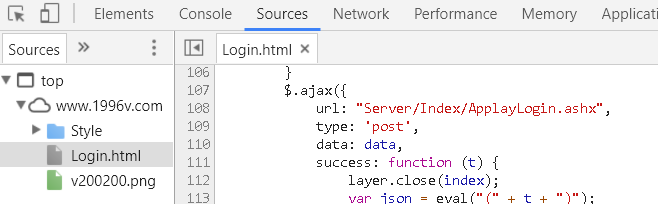
我知道了接口地址:Server/Index/ApplayLogin.ashx,也就是 http://www.1996v.com/Server/Index/ApplayLogin.ashx
我也知道了参数名称,txtPhoneNum,txtPhoneCode。
我可以在console控制台里自己写ajax来进行试验破解。如图:
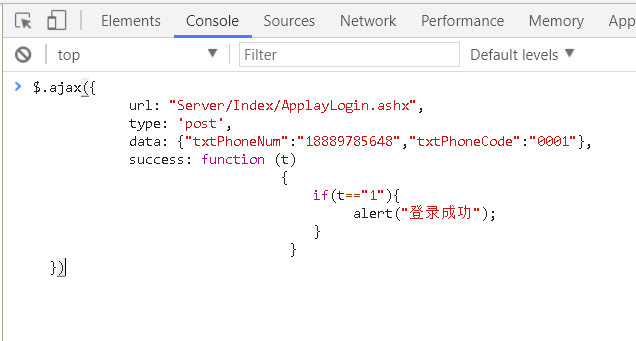
然后回车一下,则会触发当前console中写入的内容,一个ajax将会执行。如果ajax返回的是1则说明登录成功,如果不成功,那么我就再换一个txtPhoneCode,一个一个ajax来试。
那么这种方式,因为验证码为4位数字,为了保证能够成功破解,就必须把0001~9999的每一种情况都写出来,那么就要写9999个ajax,复制粘贴ajax太过于麻烦,
那么有没有更好的破解方式?
有!使用抓包工具,这里将展示fiddler2.0工具。
什么是抓包?我通俗点来说就是意思是说把 发往和接受网络的信息拦截下来。
就比如当你点击登录按钮的时候,会触发这个ajax,这个ajax最终会变成 一段 http协议 给发送到 http://www.1996v.com/这个地址下,虽然ajax是你写的,但是你是看不到这段http协议的,而抓包工具可以捕获到这段http协议,你可以修改这串http协议。
先学而后知,如果你不懂什么是抓包,没问题,你仍然看的懂我接下来的教程,你只需要先记住个概念就行了,我有一款软件,叫做,fiddler,这个软件的类型是抓包软件,它可以模拟和修改http协议,来实现不打开浏览器也可以对服务器进行交互的过程。
对于抓包工具及fiddler,我这里只是先做个概念,方便后文,如有兴趣者,请自行百度:什么是http协议、fiddler教程。
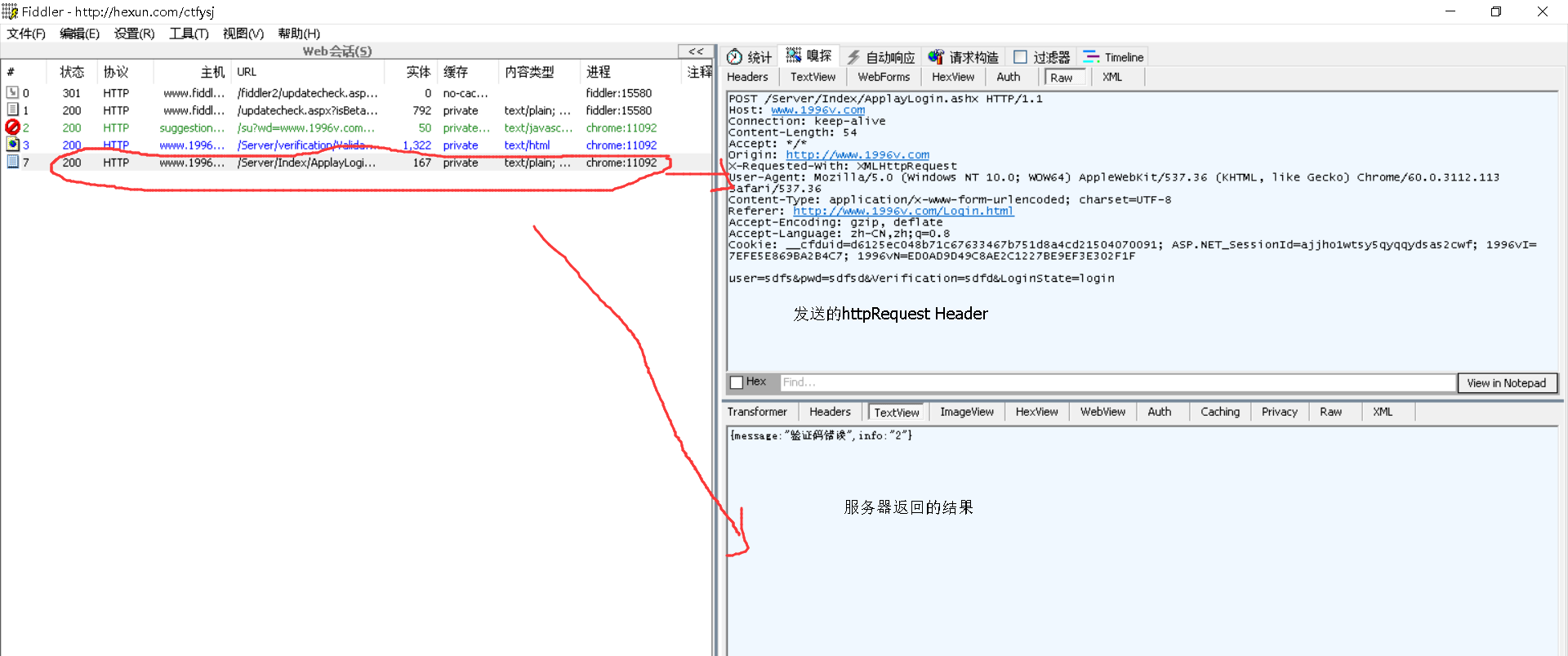
你点击页面登录按钮,然后就会有一个ajax请求发送的http协议,而fiddler则会捕获这个请求,如图,双击对应的请求,右侧上方raw选项卡下则是该请求的httpRequestHeader,就是发送的http协议头了,服务器收到这个协议后会返回HttpResponseHeader输出流,在textview选项卡下可以看到。
OK,我们把完整的 httpRequestHeader给复制下来,然后点击请求构造:
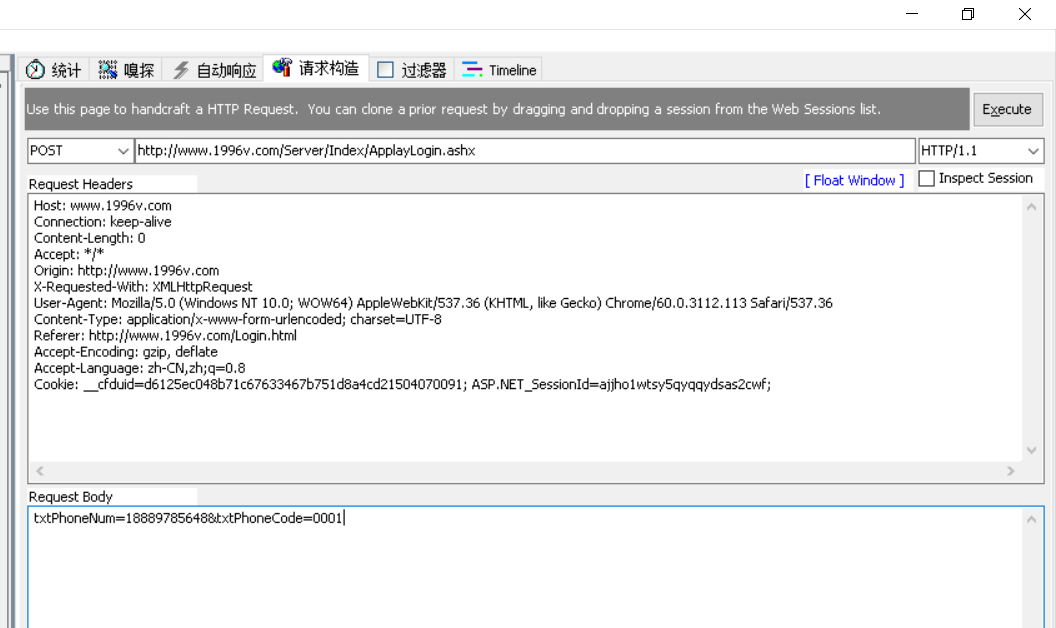
txtPhoneNum=18889785648&txtPhoneCode=0001 这就是发送的参数, 填写在Request Body里面,代表着ajax中 data的部分,最后点击Execute按钮 进行发送。
这样,只需要对Request Body中的txtPhoneCode进行修改就好了,不需要写9999个ajax那么麻烦。
不过,有没有更简单的方法?
当然有,我们还可以自己写个程序,填写一下参数规则,然后运行程序,程序自动帮我发送http协议,并且自动帮我换参数。
而网上,已经有现成的工具,不用您去自己写了。
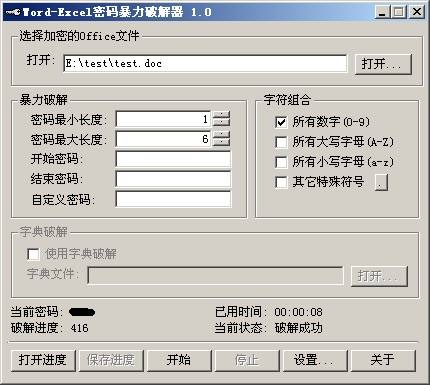
类似于这样的功能的软件,后面我会介绍几款专业点的web破解软件。
如上图,是对office办公文档进行密码破解,原理都一样,先输入密码的规则,然后软件会根据规则自动生成一个 密码列表集合 ,比如0001~9999,那么就会 生成 一个 List<string> 集合,这个集合里面包含了如上规则的所有密码,然后软件对密码进行一个一个尝试,直到尝试到正确的密码提示您破解成功,这种模式叫做:暴力破解
而密码列表集合,也有个专门的名词来描述,叫做:密码字典
好了,如上是一种破解手段,暴力破解,那么怎么防护呢?
就以本文案例来说,加长这个短信验证码的长度,本来是4位,我们可以变成6位。对IP进行限制,在该IP下出现错误在规定时间超过3次,则封停24小时。对手机号做限制,如果第一次输入错误,则延长10秒进行登录,第二次输入错误则延长1分钟才能进行登录,依次类推。
这样,就可以很好的防范暴力破解了。
绕过验证码验证从而无限注册
接下来,我们看看注册。
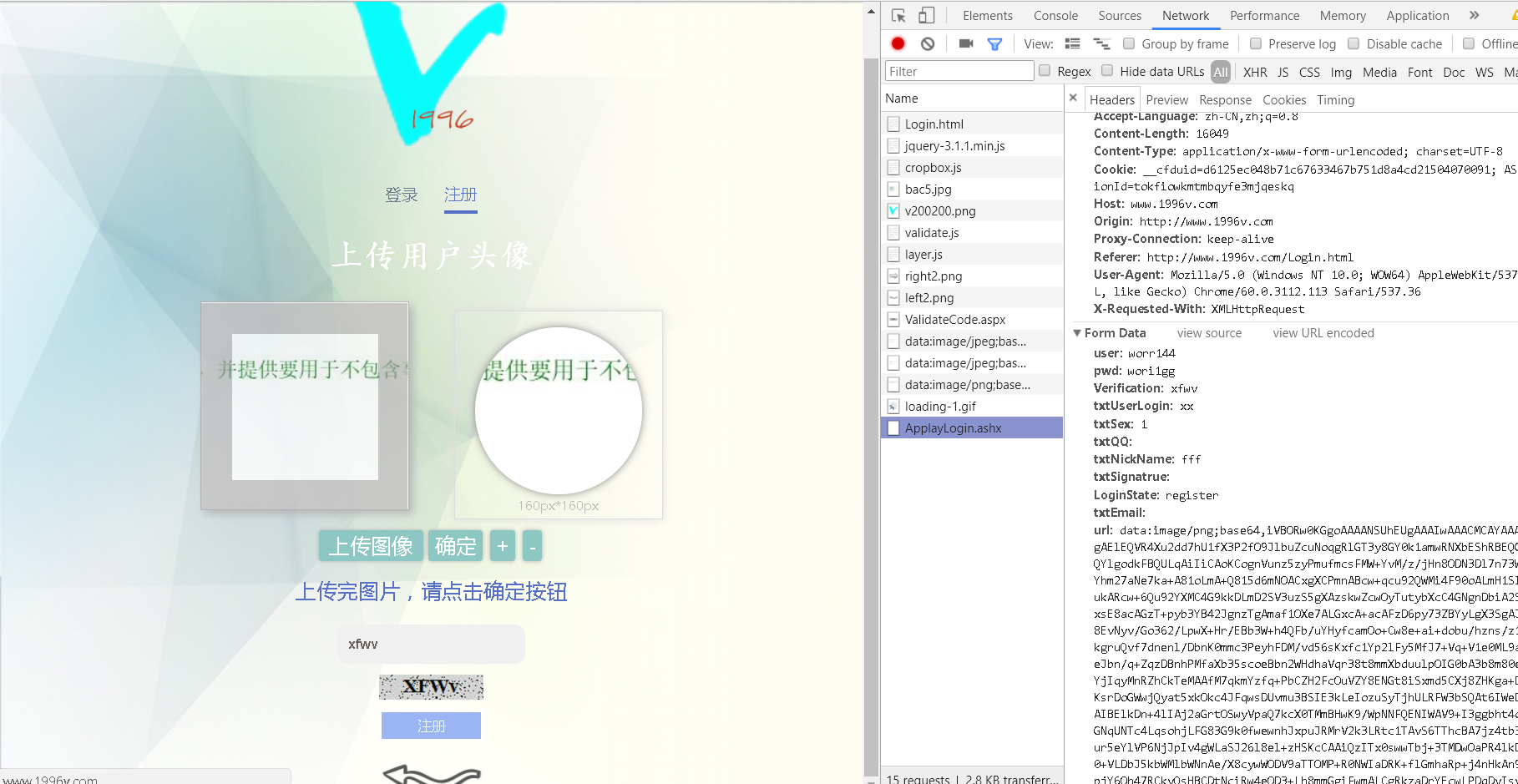
当我在注册页面填写完账号密码后,到了 上传头像这一步了。
在任何网站当中,上传文件,和验证码,都是两大主要破解对象,通过上传文件的漏洞,我甚至可以获得服务器的控制权,后面我会讲上传文件破解的思路,接下来要讲验证码这一块。
如图,要输入验证码,这个账号才能注册成功。在后台当中,验证码大多就是用session和服务器缓存来保存,默认配置session依赖于iis进程,容易丢失,我这里就是用session来保存验证码的。
当进入这个页面的时候,会调用一个验证码生成方法:
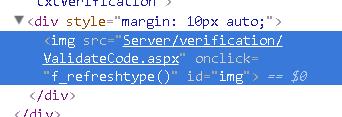
也就是这个接口 http://www.1996v.com/Server/verification/ValidateCode.aspx ,它会在我后台 产生一个 Session [" ValidateCode "] ,当我点击注册的时候,我会效验这个 Session [" ValidateCode "] 是否存在,如果存在就效验与浏览器传给我的 验证码值是否相等,如果相等则进行 接下来的注册代码逻辑。
我加了验证码验证这一环节,就能防止有人恶意注册了,如果不加,那么你通过上面的这些方法分分钟能注册一百个一万个。
什么是恶意注册?恶意注册有什么用?
我这个网站你是体验不出来恶意注册的好处的,但是我可以这样给你举个例子。你现在看到的不是我的网站,而是 新浪微博,你通过恶意注册100万个账号,然后这100万个账号同时关注一个账号,那么等于你就拥有了一个拥有百万粉丝的 新浪微博 账户, 管它死粉活粉,这玩意可就值钱了,你随便吹个牛逼卖一下,大几千上万肯定是有的。
那么,我加了验证码就可以防止恶意注册了吗?
当然不是,我上面的验证码就存在着2个漏洞,第一是 验证码 图片太过于简单,可以软件识别图片来进行破解, 第二是 逻辑漏洞。
先说第一个:用软件来识别,软件是怎么来识别的呢?
就是通过一系列的算法,通过图片的背景颜色等,来对图片进行分解,最终得出正确率高的验证码。
比如遍历所有像素点,然后得出数组,对点和线进行算法分析,删除干扰的点线,删除不规则的数组项,然后再对过滤出来的数据进行本地数据库的一个匹配,最终得出一个正确的验证码。而本地数据库是从哪冒出来的,它是对前面步骤的重复N次而筛选保留下来的数据。
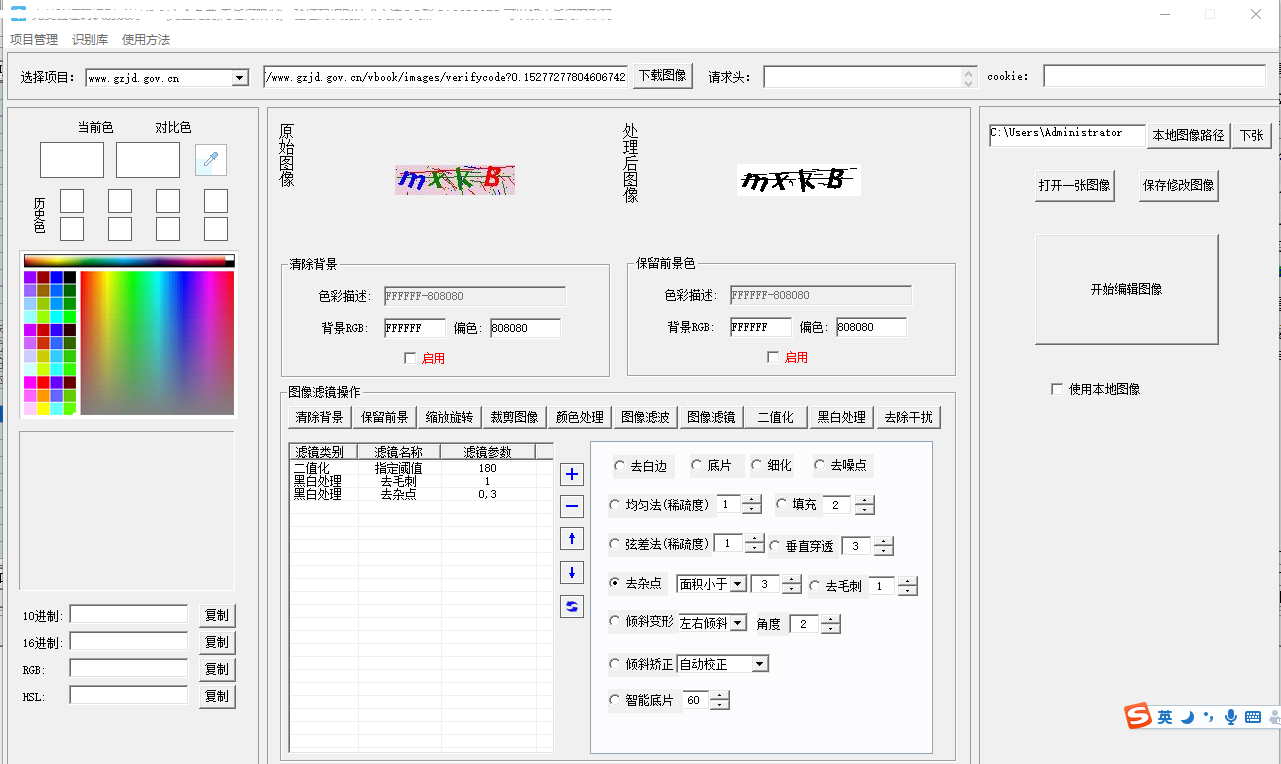
市面上这类软件很多,算法越高级的软件也就越高级, 而怎样防止这些软件破解验证码呢?那就是不走寻常路,放一些连人都无法轻易识别的验证码出来,或者猜个迷之类的...

好,接下来说第二种,逻辑漏洞。
讲道理,我的代码,浏览器点击注册按钮,如果验证码错误,则重新调用http://www.1996v.com/Server/verification/ValidateCode.aspx接口来对验证码进行刷新,如果验证码正确,并且注册成功,则跳转到新的页面。
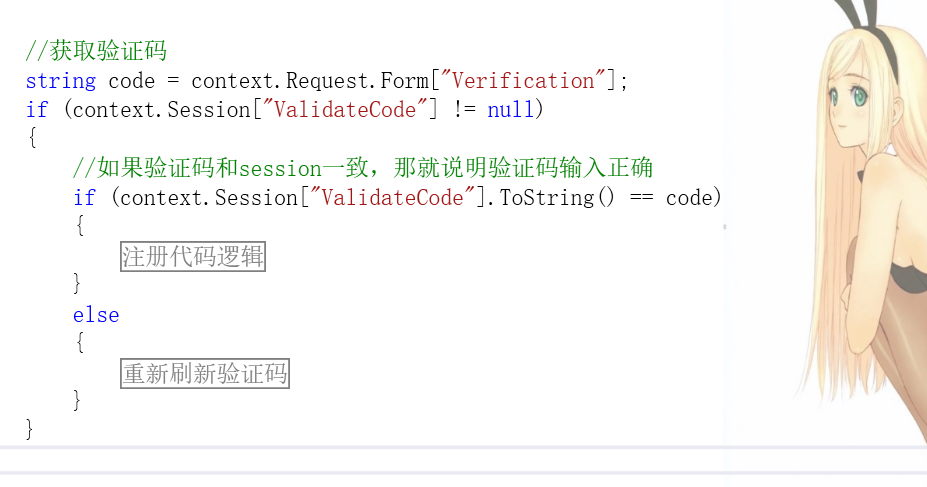
而服务端,则是判断了session不为null,以防止未将对象引用到对象实例,又判断了与浏览器接收过来的code是否相等,不相等则调用验证码刷新接口,那么,还有什么我没有考虑到的呢?
有,当然有,那就是当我验证码输入正确时,因为我后台没有刷新session,那么我就可以通过抓包等形式,无限次的进行注册!
只有浏览器传过来的参数和我现在的服务端的Session[ " ValidateCode " ] 相等,才能进行注册的逻辑。而是什么决定了 Session[ " ValidateCode " ] 的值?是Server/verification/ValidateCode.aspx这个接口,我只要不调用这个接口,那么我的 Session[" ValidateCode "] 就永远不会变,所以我只需要输入对一次,那么就可以通过抓包进行无限次的注册。
所以,代码应该变成这样:
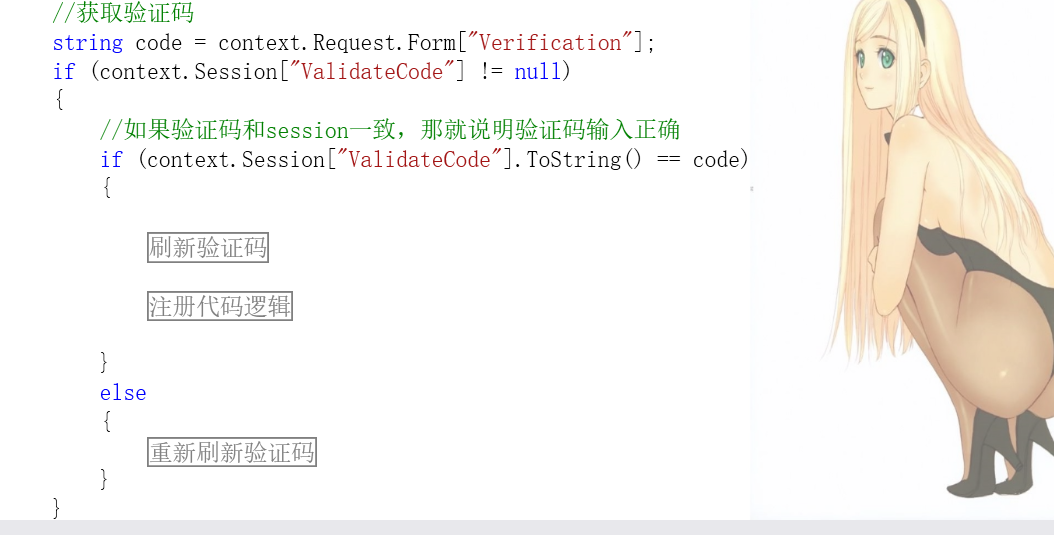
只要验证码输入正确,则立即调用刷新Session的接口。
什么是XSS?通过留言版来了解XSS
现在,成功注册账号,进入到当前账号的主页展示界面。
我们点击留言板进入留言板页面。
然后,在留言框中输入一段脚本,看看会不会执行。
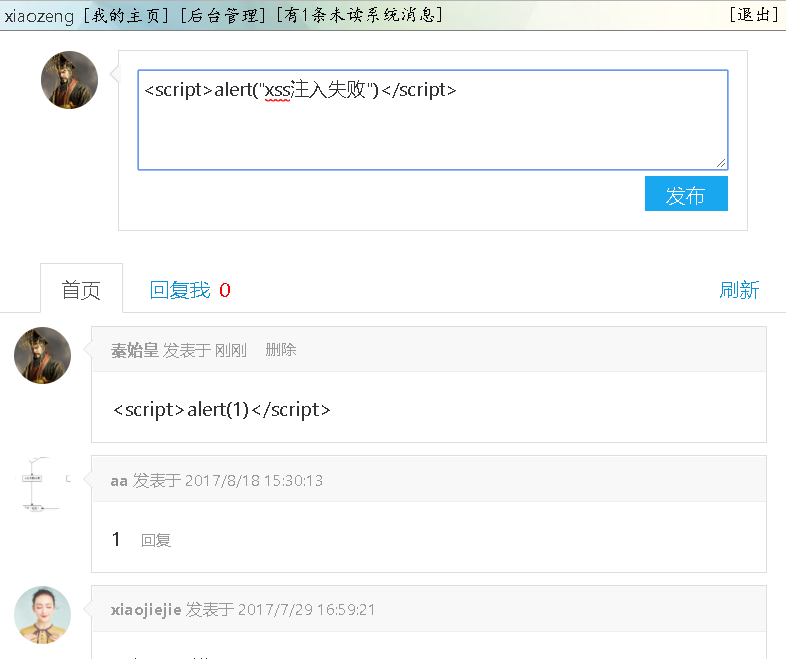
结果,这段脚本根本不会执行。
在这里,我将给大家普及下XSS注入攻击。
什么是Xss?
它指的是恶意攻击者往Web页面里插入恶意,当用户浏览该页之时,嵌入其中Web里面的html代码会被执行,从而达到恶意攻击用户的特殊目的
就如同我现在 向留言板里插入 <script>alert("小曾你好帅啊")</script> 这样一段话,如果网站没有对 这段话进行过滤的话 ,那么当你浏览这个留言板的时候,就会执行这串脚本,弹出个窗说 小曾你好帅啊 。可能你发现可以输入脚本对你并没有产生安全威胁。那么我可以输入<script>window.open( " xxxxx.com " )</script> 这样的 跳转网页之类的代码,或者 document.cookie 获取你的cookie等之类的代码,这样的威胁就很大了。
以cookie为例,为了保持登录的稳定状态,一般会把token令牌(也就是你的账号密码)保存在cookie设置个过期时间放在浏览器进行保存,网站效验你登录状态,其实最终是根据cookie来的,如果你的网站没有对ip进行限制(一般都没有进行限制),我可以把你的cookie复制粘贴然后发送到另一台电脑上,然后设置下cookie,和登录你账号密码 是没区别的。
所以,如果网站里有留言或者私信或者发表文章的这些功能的时候,一定要对这些特殊字符进行过滤。
像上面这段<script>alert("小曾你好帅啊")</script>最终在我数据库中保存的是<script>alert("小曾你好帅啊")</script>
function (str, reg) { return str ? str.replace(reg || /[&<">'](?:(amp|lt|quot|gt|#39|nbsp|#\d+);)?/g, function (a, b) { if (b) { return a; } else { return { '<':'<', '&':'&', '"':'"', '>':'>', "'":''' }[a] } }) : ''; }
不过,我当前的留言板是采用json格式进行解析的,所以还需要对\符号进行转义,否则,如果你在回复框中输入一个 \ 符号, 则照样会报错。
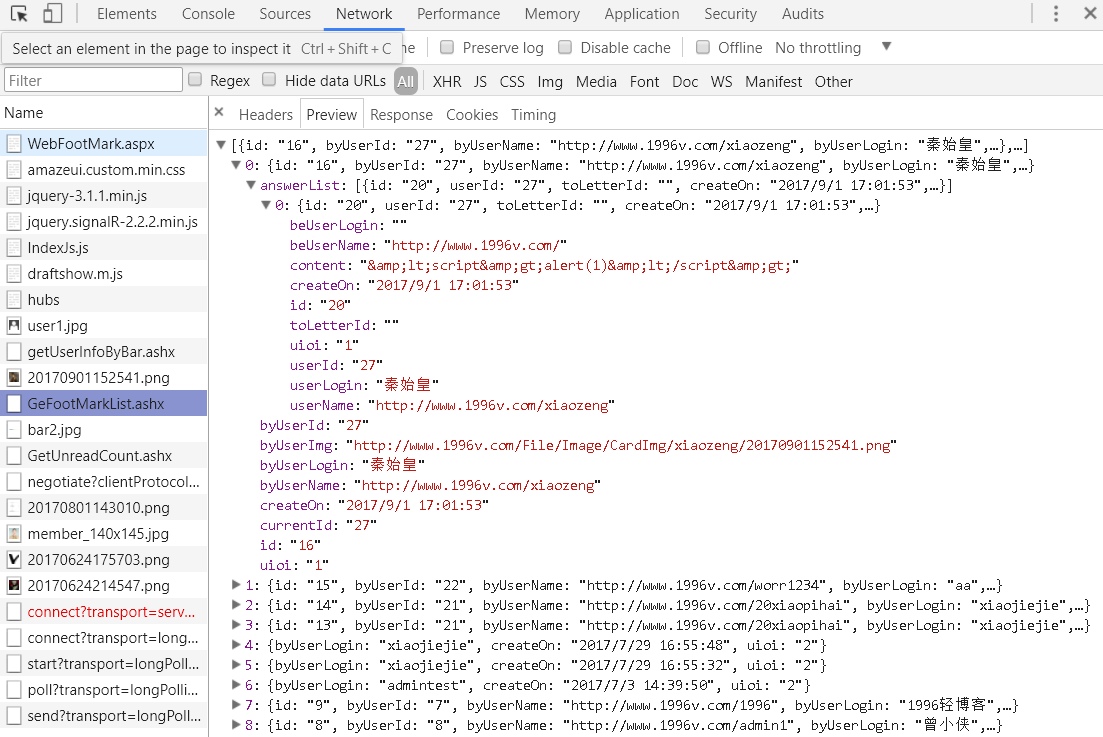
上面这是Xss,只要对入口处对字符串浏览器服务端都做好过滤就可以有效的防范。
这里插入一条例子,在2011年的BlackHat DC 2011黑客大会上,一名黑客Ryan Barnett给出了一段关于XSS的示例javascript代码:
($=[$=[]][(__=!$+$)[_=-~-~-~$]+({}+$)[_/_]+($$=($_=!''+$)[_/_]+$_[+$])])()[__[_/_]+__[_+~$]+$_[_]+$$](_/_)
这段代码,巧妙的躲过掉一些过滤函数的检查,最终,被浏览器解析成 alert(1)
空数组是一个非null值,因此![]的结果是false(布尔型)。在计算false + []时,由于数组对象无法与其他值相加,在加法之前会先做一个字符串的转换,空数组的toString就是"",也就是说false+[]的结果为"false",
而在js中,~符号是 按位取反运算符, ~[] 则会被解析成-1 ,~[1] 则会变成-2 等等等等,最终就以这种巧妙的思想来变成了windows['alert(1)']。
不过这其实也是和浏览器的解析有关,可以把它理解成一个漏洞,总之,现如今的浏览器大多不能再实现这段代码。
在我的网站上你可以发表文章,用的是ueditor,发表文章你可以自由的更改文章的html,但是我后台通过正则表达式对脚本进行了过滤,如果没有我给你的脚本权限,你所有的脚本代码都会自动过滤掉,有兴趣的朋友可以想想思路想想办法,看能不能找到可以xss的地方。可以加下.net/web交流群 166843154,一起讨论讨论。
CSRF的原理,如何防护?
接下来我们在留言框中发一条信息:
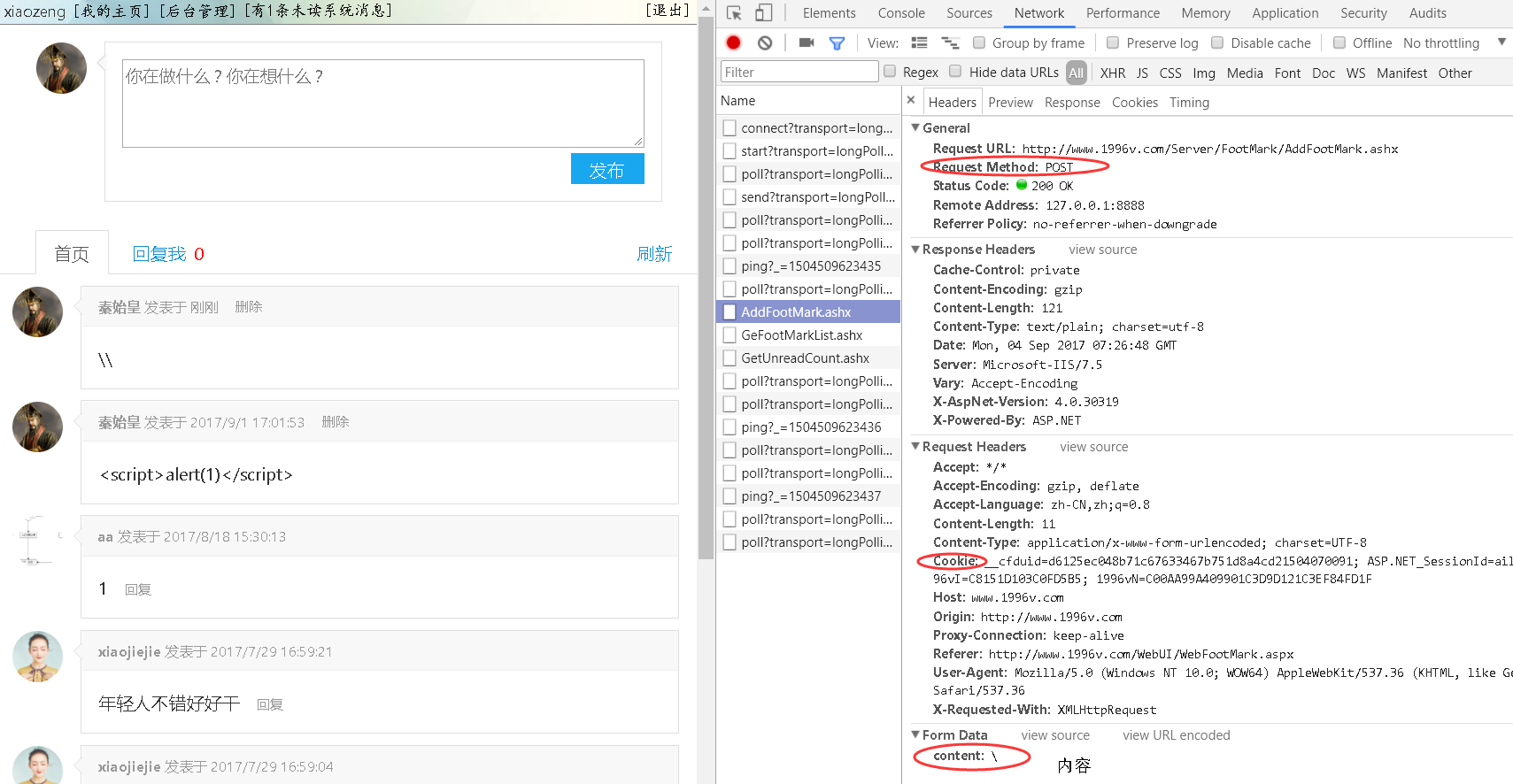
我们会发现,当点击【发布】按钮的时候,实际上是以Post的方式调用了 http://www.1996v.com/Server/FootMark/AddFootMark.ashx 这个接口。
现在,我要搞破坏,我写个页面,然后这个页面调用这个接口,只要是打开了我这个页面的人,如果他在1996v网站处于登录状态的话,他都会进行一段留言,留言内容为:CSRF。
接下来我们新建个页面,这个页面就写个ajax:
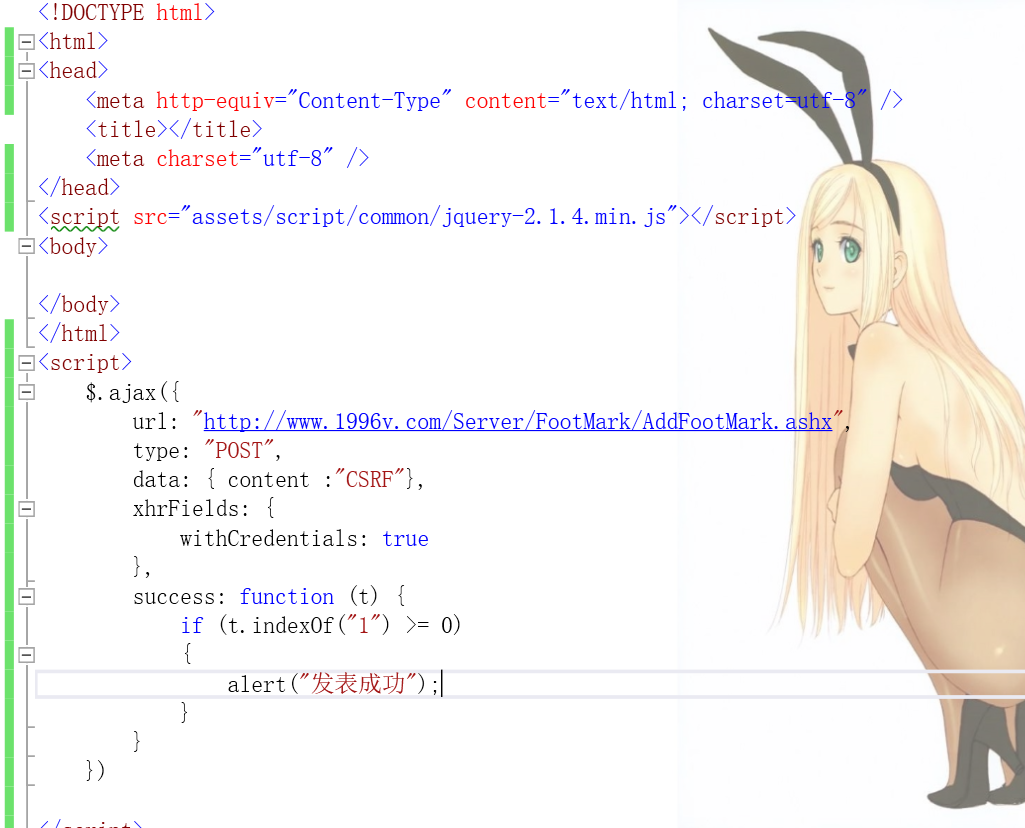
然后运行该页面
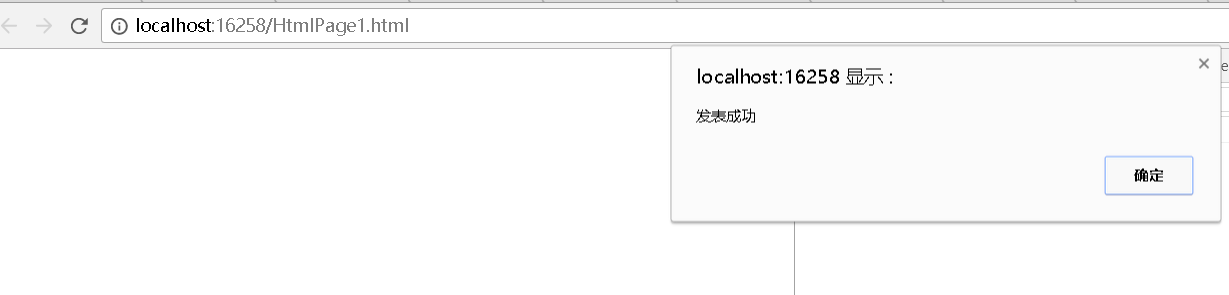
发现 发表成功,我们在转回留言页面,发现同样的是一行CSRF出现在留言板上。

所以这里给大家一个思想就是,浏览器上所有的一切,你的各种按钮,与服务端的交互无非都是一段http协议,说白了,就是一个个接口。
你调用什么样的接口就会发生什么样的事,就比如 我的网站 现在有一个 关注功能的 接口, 这个接口是 http://xxxxxxxxxxxxx.com?name=秦始皇,意思就是,只要访问了这个接口,那么 当前登陆者就会关注一个 名叫 秦始皇 的选手,像我的新浪微博账号,什么都没有发布,就莫名其妙的就有几十个粉丝,像有些人,明明什么都没做,点开空间却突然发现自己不知何时发了好多小广告。
等等例子,以上这种方式就属于CSRF(伪装跨站攻击)
所以,千万不要乱点击链接。
当然,浏览器 也针对这种情况 做了浏览器上的一个安全限制,叫做:同源策略
大致意思就是,但凡遵守 同源策略规则 的浏览器 ,在这个浏览器上 如果 a网站 想调用b网站 的接口 ,如果b网站的服务器不同意的话,a网站的调用就会报错。
所以,不遵守 同源策略 的浏览器 , 都是 不安全的 浏览器 ,不过现在大部分主流浏览器 都遵守 同源策略,放心用吧。
不过,因为同源策略是针对浏览器,所以如果你会抓包,你懂http协议,你直接在服务器上写一个http请求的话,同源策略就没用了。
目前很多网站,对于一些并没有涉及到利益或安全的接口上,大多都存在着CSRF的漏洞。
如果你搞的是商城之类的网站,那么你就必须要重视这块了。
比如交易的时候,我把你的支付接口进行各种包装,然后诱导其它人使用这个接口给我汇账...
那么怎样避免呢?除了要效验Referer主要还是靠Token,后端接口必须要有完善的鉴权机制, 当你进入交易页面的时候,根据有效时间、有效次数、当前用户等生成一条Token令牌,然后将令牌存到header中或者直接带过去,后台进行匹配,吻合即交易,不吻合就属于非法请求。
除非你也知道这条Token,那么请求都将被拦截。
DDOS原理及防护
在这里,我还要小小的提示下,http协议可不止get、post
还有危险的PUT、DELETE等,如果我用Delete方式进行请求,那么请求啥,服务器就会删啥。
我们可以用OPTIONS的请求方式来判断,服务器允许哪几种请求。

我们发现,我的网站服务器允许的请求类型有:OPTIONS(可以获取服务器允许的请求类型)、TRACE(用于远程诊断服务器)、GET、HEAD(类似于GET, 但是不返回body信息,用于检查对象是否存在,比如判断接口是否可以访问)、POST
一般服务器会自动关闭掉危险的请求方法,上图我所示的是IIS7.5默认的 服务器允许请求的类型。
而不管是哪种类型,在后台服务器上的处理模式都是统一的,服务器因为CPU等配置的不同,在同一时间能够请求的并发处理数是有限制的。
比如我这台云服务器,可以在同一时间请求50个并发量,如果你开500个线程来发送http请求同一时间访问我的服务器,那我的服务器会挂掉的。
对攻击网站发动大量的正常或非正常请求、耗尽目标主机资源或网络资源,从而使被攻击的主机不能为合法用户提供服务,这个就属于 DDOS 攻击
对于DDOS,建议买高防的DDOS服务器就可以了。
挂马的原理,如何防止网站被挂马?
上面的XSS,CSRF主要是动脑筋来找思路,无论技术高低,只要你能找到漏洞那就能造成很严重的后果,我现在要介绍的是危害很严重并且普遍存在的 上传漏洞。
我的网站的上传,也就是上传图片。我的做法是这样的,先在浏览器把文件转换为base64,然后传到浏览器,再效验一下,正确就直接按上传过来的后缀进行保存,否则就是非法请求。
那么,如何进行效验呢?
通过截取扩展名来做判断,或者通过ContentType (MIME) 判断,但是这两种都不安全。
ContentType我把包修改一下修改成image类型就可以绕过。
而扩展名验证这一块也有漏洞可寻,不过是存在于IIS6.0服务器上的。
如果你的服务器是IIS6.0,我现在上传一个文件名叫做 新建文本文档.txt%00.jpg 的文件, 这个文件在服务器上被辨别后缀是.jpg,但是保存在本地 却以 新建文本文档.txt 的形式保存,这样,就成功的绕过了你的后缀名的判断,这种方式叫做 %00文件名截断 。
如果人家上传的是一个关机指令的脚本,那么一旦运行成功的话就会关机。
那么这一块该怎么防范呢?我们可以把文件变成Byte[]来存储,然后在进行读取效验,或者不怕麻烦的可以直接在服务器再转一道类型,如果报错就是假的。这里就不贴代码了,请自行百度.net获取文件真实类型。
关于IIS6.0的上传漏洞还有一些,如在网站目录中如果存在名为*.asp、*.asa的目录,那该目录内的任何文件都会被IIS解析为asp文件并执行。
这种通过上传一段脚本木马的方式就叫做挂马。
这其中,有一款比较厉害的软件叫做 中国菜刀 ,俗称“ 一句话木马 ” ,意思是 ,你用这个软件特殊处理一个文件(如图片),然后上传到网站当中,只要执行了这个文件,那么攻击者就会拿到网站的控制权,有兴趣了解的可以百度下 中国菜刀。
好了,我们总结一下,像这种挂马形式上传文件的漏洞,主要还是 服务器上的漏洞, 也就是你现在用一款软件,这个软件本身有bug,而并不是你导致的问题,所以像这类东西,尽量用新点的,别用什么 老版本稳定 这种话来搪塞自己,无论是性能还是安全,版本升级自然有人家升级的意义。像sqlserver2008,就可以通过sql注入的形式故意输错从而获取到表的字段名称。又如 office软件 拥有读写本地文件的权利, 而刚好有个可以注入的office的漏洞,这样人家就可以通过office来对你的本地文件进行操作了,所以电脑上一些漏洞能更新的就更新。
什么是钓鱼网站?
比如我的网站地址是:www.1996v.com,而钓鱼网站的地址是:www.I996v.com
钓鱼网站的地址 和我的地址很相似, 不过我的是 1 而 它的是 英文 I,而网站的内容 也差不多和我网站的内容一样。
通过伪装url和网站内容用来欺骗行为的网站 就是钓鱼网站了。
什么是安全渗透测试?
安全渗透测试是对网站和服务器的全方位安全测试,通过模拟黑客攻击的手法,切近实战,提前检查网站的漏洞。
接下来我将介绍一些安全渗透的软件。
像 Burp Suite、WVS(AWVS),都是类似于Fiddler的软件,可以抓包之类的。
DirBuster目录渗透工具,专门用于探测Web服务器的目录和隐藏文件。
Nmap网络连接端软件,网络连接端扫描软件,用来扫描网上电脑开放的网络连接端。
Pangolin Sql注入工具
AppScan业界领先的web应用安全监测工具(软件界面可以选择中文,不过是收费的)
...还有很多,感兴趣请自行百度。
关于本文
嗯.....关于我这个网站,也就是当时利用业余时间做的。我接下来准备利用业余时间做一个非常优秀的 开源的CMS、CRM自定义模板生成系统,我是一个非常非常上进的年轻人,一个非常非常热爱技术的年轻人,如果你也是和我一样,或者你也是搞web的,想用好的环境来造就自己,不妨可以加下群 .net/web交流群 166843154,一起讨论讨论。
作者:小曾
出处:http://www.cnblogs.com/1996V/p/7458377.html 欢迎转载,但任何转载必须保留完整文章,在显要地方显示署名以及原文链接。如您有任何疑问或者授权方面的协商,请给我留言
.Net交流群, QQ群:166843154 欲望与挣扎















 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









