







 本文深入浅出地介绍了LDA主题模型,包括其背景、原理和实际应用。LDA旨在挖掘文本中的隐藏主题,通过贝叶斯公式和狄利克雷分布建立模型。文中还探讨了LDA在相似文档发现、推荐系统中的作用,并提供了gensim库的使用示例,以及简化的数学推导和Gibbs采样的概念。最后,给出了代码实现的概述。
本文深入浅出地介绍了LDA主题模型,包括其背景、原理和实际应用。LDA旨在挖掘文本中的隐藏主题,通过贝叶斯公式和狄利克雷分布建立模型。文中还探讨了LDA在相似文档发现、推荐系统中的作用,并提供了gensim库的使用示例,以及简化的数学推导和Gibbs采样的概念。最后,给出了代码实现的概述。
本文将从三个方面介绍LDA主题模型——整体概况、数学推导、动手实现。
关于LDA的文章网上已经有很多了,大多都是从经典的《LDA 数学八卦》中引出来的,原创性不太多。
本文将用尽量少的公式,跳过不需要的证明,将最核心需要学习的部分与大家分享,展示出直观的理解和基本的数学思想,避免数学八卦中过于详细的推导。最后用python 进行实现。
概况
第一部分,包括以下四部分。
- 为什么需要
- LDA是什么
- LDA的应用
- LDA的使用
为什么需要
挖掘隐含语义信息。一个经典的例子是
“乔布斯离我们而去了。”
“苹果价格会不会降?”
上面这两个句子没有共同出现的单词,但这两个句子是相似的,如果按传统的方法判断这两个句子肯定不相似。
所以在判断文档相关性的时候需要考虑到文档的语义,而语义挖掘的利器是主题模型,LDA就是其中一种比较有效的模型。
LDA是什么
LDA主题模型,首先是在文本分类领域提出来的,它的本意是挖掘文本中的隐藏主题。它将文本看作是词袋模型(文章中的词之间没有关联)产生的过程看成 先选一堆主题,再在主题中选择词,以此构建了一篇文章。
d 是文章
w 是单词
φkt 是主题选择词的概率。
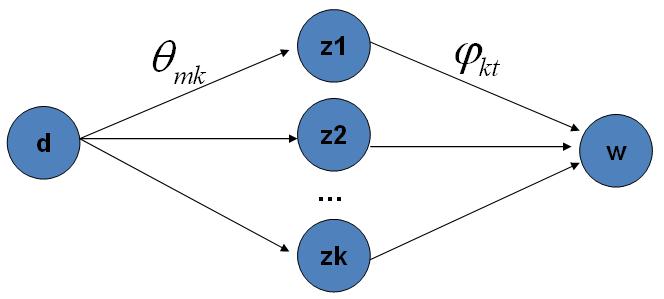
这里新手比较困惑的一点是选来选取,变量是什么?
你可以这样理解,先不要管狄利克雷分布,明确是从topic分布上选取topic,得到各topic的概率,然后再去另一个词的分布上选取刚才得到topic对应的词。


注意:此时不用想这两个分布怎么来的,只要把这个过程能想明白即可。LDA产生文档的过程。
选主题分布->选主题
LDA的应用
通过隐含语义找到关联项。
相似文档发现;
推荐商品;将该商品归属的主题下其他商品推荐给用户
主题评分;分析文档主题倾向,看哪个主题比重大
gensim应用
import jieba
import gensim
def load_stop_words(file_path):
stop_words = []
with open(file_path,encoding='utf8') as f:
for word in f:
stop_words.append(word.strip())
return stop_words
def pre_process(data):
# jieba 分词
cut_list = list(map(lambda x: '/'.join(jieba.cut(x,cut_all=True)).split('/'), data))
# 加载停用词 去除 "的 了 啊 "等
stop_words = load_stop_words('stop_words.txt')
final_word_list = []
for cut in cut_list:
# 去除掉空字符和停用词
final_word_list.append(list(filter(lambda x: x != '' and x not in stop_words, cut)))
print(final_word_list)
word_count_dict = gensim.corpora.Dictionary(final_word_list)
# 转成词袋模型 每篇文章由词字典中的序号构成
bag_of_words_corpus = [word_count_dict.doc2bow(pdoc) for pdoc in final_word_list]
print(bag_of_words_corpus)
#返回 词袋库 词典
return bag_of_words_corpus, word_count_dict
def train_lda(bag_of_words_corpus, word_count_dict):
# 生成lda model
lda_model = gensim.models.LdaModel(bag_of_words_corpus, num_topics=10, id2word=word_count_dict)
return lda_model
# 新闻地址 http://news.xinhuanet.com/world/2017-12/08/c_1122082791.htm
train_data = [u"中方对我们的建交国同台湾开展正常经贸和民间往来不持异议,但坚决反对我们的建交国同台湾发生任何形式的官方往来或签署任何带有主权意涵的协定或合作文件",
u"湾与菲律宾签署了投资保障协定等7项合作文件。菲律宾是台湾推动“新南向”政策中首个和台湾签署投资保障协定的国家。",
u"中方坚决反对建交国同台湾发生任何形式的官方往来或签署任何带有主权意涵的协定或合作文件,已就此向菲方提出交涉"]
processed_train_data = pre_process(train_data)
lda_model = train_lda(*processed_train_data)
lda_model.print_topics(10)数学原理
通过上节内容,在工程上基本可以用起来了。但是大家都是有追求的,不仅满足使用。这节简单介绍背后的数学原理。只会将核心部分的数学知识拿出来,不会面面俱到(我觉得这部分理解就足够了)
(详尽内容推荐去看《数学八卦》)
LDA认为各个主题的概率和各个主题下单词的概率不是固定不变的(比如通过设定3个主题的抽取概率为0.3 0.4 0.3 就一直这么用),而是由先验和样本共同通过贝叶斯计算得到的一个分布,同时还会依据不断新增加的样本进行调整。pLSA(LDA的前身) 看待分布情况就是固定的,求完就求完了,而LDA看待分布情况是 不断依据先验和样本调整。
预备知识
下面我们来介绍一下贝叶斯公式
P(θ|X)=P(X|θ)P(θ)P(X)
其中
后验概率 P(θ|X
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









