联邦学习/机器学习笔记(三)
多项式回归模型代码实现
首先给出我们想要拟合的方程: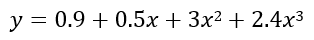
然后可以设置参数方程: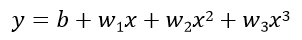
我们希望每一个参数都能够学习到和真是参数很接近的结果
首先需要进行预处理数据,即把数据变成一个矩阵的形式
"""多项式回归代码实现"""
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
#在pytorch中使用torch.cat()函数来实现tensor的拼接
def make_features(x):
"""Builds features i.e. a matrix with columns [x, x^2, x^3]."""
x = x.unsqueeze(1) #将原来的tensor大小由3变成(3,1)
return torch.cat([x ** i for i in range(1, 4)], 1)
def f(x):
"""Approximated function."""
return x.mm(W_target) + b_target[0] #x.mm()即矩阵乘法,f(x)是每次输入一个x的到一个y的真实函数
def get_batch(batch_size=32):
"""Builds a batch i.e. (x, f(x)) pair."""
random = torch.randn(batch_size)
random = np.sort(random)
random = torch.Tensor(random)
x = make_features(random)
y = f(x)
if torch.cuda.is_available():
return Variable(x).cuda(), Variable(y).cuda()
else:
return Variable(x), Variable(y)
# Define model
class poly_model(nn.Module):
def __init__(self):
super(poly_model, self).__init__()
self.poly = nn.Linear(3, 1)
def forward(self, x): #向前传播
out = self.poly(x)
return out
if __name__ == '__main__':
W_target = torch.FloatTensor([0.5, 3, 2.4]).unsqueeze(1)
b_target = torch.FloatTensor([0.9])
if torch.cuda.is_available():
model = poly_model().cuda()
else:
model = poly_model()
criterion = nn.MSELoss() #定义损失函数
optimizer = optim.SGD(model.parameters(), lr=1e-3) #定义优化器
'''
使用均方误差来衡量模型的好坏,使用随机梯度下降来优化模型,然后开始训练模型
'''
epoch = 0
while True:
# Get data
batch_x, batch_y = get_batch()
# Forward pass
output = model(batch_x)
loss = criterion(output, batch_y)
print_loss = loss.item()
# Reset gradients
optimizer.zero_grad()
# Backward pass
loss.backward()
# update parameters
optimizer.step()
epoch += 1
if print_loss < 1e-3:
break
print("Loss: {:.6f} after {} batches".format(loss.item(), epoch))
print(
"==> Learned function: y = {:.2f} + {:.2f}*x + {:.2f}*x^2 + {:.2f}*x^3".format(model.poly.bias[0], model.poly.weight[0][0],
model.poly.weight[0][1],
model.poly.weight[0][2]))
print("==> Actual function: y = {:.2f} + {:.2f}*x + {:.2f}*x^2 + {:.2f}*x^3".format(b_target[0], W_target[0][0],
W_target[1][0], W_target[2][0]))
predict = model(batch_x)
batch_x = batch_x.cpu()
batch_y = batch_y.cpu()
x = batch_x.numpy()[:, 0]
plt.plot(x, batch_y.numpy(), 'ro')
predict = predict.cpu()
predict = predict.data.numpy()
plt.plot(x, predict, 'b')
plt.show()























 1366
1366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









