






文章为翻译,仅供学习参考
论文地址:https://arxiv.org/abs/1904.08779
论文作者:Daniel S. Park∗ , William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D. Cubuk, Quoc V. Le
摘要
SpecAugment是一种简单的数据增强方法,用于语音识别。SpecAugment直接应用于神经网络的特征输入(即滤波器组系数)。增强策略包括对特征进行扭曲、屏蔽频率通道块和屏蔽时间步长块。我们在端到端语音识别任务的Listen, Attend and Spell网络上应用了SpecAugment。在LibriSpeech 960h和Swichboard 300h任务上,我们实现了最先进的性能,超越了所有先前的工作。在LibriSpeech上,我们在未使用语言模型的情况下,在test-other上实现了6.8%的字错率(Word Error Rate,WER),并在与语言模型浅层融合后达到了5.8%的WER。这与先前最先进的混合系统的7.5% WER相比。对于Switchboard,我们在Hub5'00测试集的Switchboard/CallHome部分上实现了不使用语言模型时的7.2%/14.6%,在使用浅层融合时为6.8%/14.1%,这与先前最先进的混合系统的8.3%/17.3% WER相比较好。
1.引言
深度学习已经成功应用于自动语音识别(ASR)[1],研究的主要焦点是设计更好的网络架构,例如DNNs [2]、CNNs [3]、RNNs [4]和端到端模型 [5, 6, 7]。然而,这些模型往往容易产生过拟合,并需要大量的训练数据[8]。
数据增强被提出作为ASR生成额外训练数据的一种方法。例如,在[9, 10]中,人造数据被用来增强低资源语音识别任务。声道长度归一化在[11]中被适应于数据增强。在[12]中,通过将清晰的音频与噪声音频信号叠加,合成了嘈杂的音频。在[13]中,对原始音频进行速度扰动用于LVSCR任务。在[14]中,探索了使用声学房间模拟器进行数据增强。在[15, 16]中研究了关键词检测的数据增强。在[17]中,采用特征随机删除训练多流ASR系统。更一般地,学习的数据增强技术探索了不同的增强转换序列,在图像领域取得了最先进的性能[18]。
SpecAugment是一种数据增强方法,受到语音和视觉领域增强技术的成功启发。它操作的对象是输入音频的log mel频谱图,而不是原始音频本身。这种方法简单且计算成本低,因为它直接作用于log mel频谱图,就像处理图像一样,并且不需要额外的数据。因此,我们能够在训练过程中在线应用SpecAugment。SpecAugment包括对log mel频谱图的三种变形。第一种是时间扭曲,即在时间方向上对时间序列进行变形。另外两种增强方法,灵感来自于计算机视觉领域提出的“Cutout”[19],分别是时间屏蔽和频率屏蔽,其中我们屏蔽连续的时间步长或mel频率通道的块。
这种方法虽然基础,但非常有效,使我们能够训练端到端的自动语音识别(ASR)网络,称为Listen Attend and Spell (LAS) [6],超越更复杂的混合系统,并在不使用语言模型(LMs)的情况下实现最先进的结果。在LibriSpeech [20]上,我们在测试干净集上实现了2.8%的词错误率(WER),在测试其他集上实现了6.8%的WER,而没有使用LM。通过与在LibriSpeech LM语料库上训练的LM进行浅层融合[21],我们能够改善性能(测试干净集上的WER为2.5%,测试其他集上的WER为5.8%),相对于测试其他集上的当前最先进水平提高了22%。在Switchboard 300h (LDC97S62) [22]上,我们在Hub5'00 (LDC2002S09, LDC2003T02)测试集的Switchboard部分获得了7.2%的WER,在CallHome部分获得了14.6%的WER,而没有使用LM。通过与在Switchboard和Fisher (LDC200f4,5gT19) [23]语料库的混合转录上训练的LM进行浅层融合,我们获得了Switchboard/Callhome部分的6.8%/14.1%的WER。
2.增强策略
我们的目标是构建一个作用于log mel频谱图的增强策略,帮助网络学习有用的特征。受到这些特征应该对时间方向的变形、部分频率信息的丢失以及语音小片段的部分丢失具有鲁棒性的目标的启发,我们选择了以下变形组成一个策略:
- 在这种方法中,时间扭曲是通过tensorflow的sparse image warp函数应用的。给定具有τ个时间步长的log mel频谱图,我们将其视为一幅图像,其中时间轴是水平的,频率轴是垂直的。沿着通过图像中心的水平线的随机点,在时间步长(W;τ− W)内的点将被选择,然后按照从0到时间扭曲参数W的均匀分布,在该线上向左或向右扭曲一定距离w。我们在边界上固定了六个锚点 — 四个角以及垂直边的中点。
- 频率掩蔽是这样应用的,使得连续的f个mel频率通道 [f0; f0 + f) 被屏蔽,其中f首先从0到频率遮罩参数F的均匀分布中选择,而f0则从[0; ν − f)中选择,其中ν是mel频率通道的数量。
- 时间掩蔽是这样应用的,使连续的t个时间步长[t0; t0 + t)被掩盖,其中t首先从0到时间掩码参数T的均匀分布中选择,而t0从[0; τ − t)中选择,τ表示总的时间步长数量。此外,我们引入了一个时间掩码的上限,确保时间掩码不会超过时间步长数量的p倍。
图1展示了对单个输入应用的各种增强示例。对数梅尔频谱图被规范化为零均值,因此将掩盖的数值设为零相当于将其设为均值。

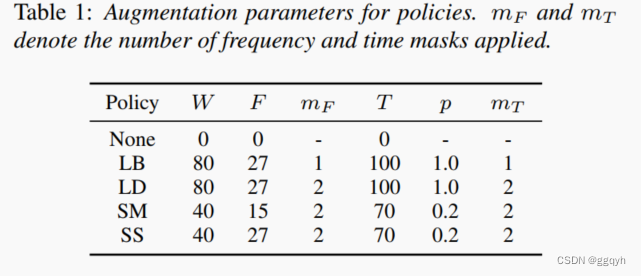
我们可以考虑应用多个频率和时间掩码的策略。这些多个掩码可以重叠。在本研究中,我们主要考虑一系列手工制作的策略,包括LibriSpeech基础策略(LB)、LibriSpeech双倍策略(LD)、Switchboard温和策略(SM)和Switchboard强策略(SS),其参数总结在表1中。在图2中,我们展示了一个使用LB和LD策略增强的对数梅尔频谱图示例。

3.模型
我们使用Listen, Attend and Spell (LAS)网络[6]进行自动语音识别任务。这些模型是端到端的,训练起来很简单,并且有着良好的文档基准[24,25],我们能够在此基础上得到我们的结果。在本节中,我们将回顾LAS网络并引入一些符号来参数化它们。我们还介绍了我们用于训练网络的学习率调度,因为它们事实证明是决定性能的重要因素。最后,我们回顾了浅层融合[21],我们已经使用它来进一步提高性能。
3.1 LAS网络架构
我们使用Listen, Attend and Spell (LAS)网络[6]进行端到端的自动语音识别,标记为LASd-w,这在[25]中有所研究。输入对数梅尔频谱图被传入一个具有最大池化和步长2的2层卷积神经网络(CNN)。CNN的输出通过一个包含d个堆叠的双向LSTM单元(cell)大小为w的编码器,得到一系列注意力向量。这些注意力向量被馈送到一个维度为w的2层RNN解码器中,产生转录文本的标记。文本使用词片段模型(Word Piece Model,WPM)[26]进行标记化,LibriSpeech使用大小为16k的词汇表,Switchboard使用大小为1k的词汇表。对于LibriSpeech 960h任务,WPM是使用训练集的转录构建的。对于Switchboard 300h任务,训练集的转录与Fisher语料库的转录结合以构建WPM。最终的转录通过束搜索(beam search)获得,束大小为8。为了与[25]进行比较,我们指出他们的“大模型”在我们的符号表示中是LAS-4-1024。
3.2. 学习率调度
学习率调度是确定ASR网络性能的重要因素,尤其是在存在数据增强的情况下。在这里,我们介绍了两种训练调度的目的。首先,我们使用这些调度来验证较长的调度是否能提高网络的最终性能,尤其是在使用数据增强时(表2)。其次,基于此,我们引入非常长的调度,以最大化网络的性能。
我们使用学习率调度,其中学习率从零逐渐增加,保持稳定,然后按指数衰减,直到达到其最大值的1/100。在此点之后,学习率保持不变。这个调度由三个时间戳()参数化——ramp-up完成的步骤
,在该步骤之后开始指数衰减的步骤si和指数衰减停止的步骤
。
在我们的实验中,还引入了另外两个因素来引入时间尺度。首先,我们在步骤snoise处启用标准差为0.075的变分权重噪声[27],并在整个训练过程中保持不变。权重噪声是在学习率的高平台期间()引入的。
其次,我们采用均匀标签平滑[28],不确定性为0.1,即正确的类别标签分配置信度0.9,而其他标签的置信度相应增加。正如稍后再次评论的那样,标签平滑可能会对较小的学习率造成不稳定,因此我们有时选择在训练开始时打开它,并在学习率开始衰减时关闭它。
我们使用的两个基本调度如下所示:
- B(asic):
=(0.5K, 10K, 20K, 80K)
- D(ouble):
如在第5节进一步讨论的那样,我们可以通过使用更长的调度来提高训练网络的性能。因此,我们引入以下调度:L(ong): ={1K, 20K, 140K, 320K}
我们使用调度L来训练最大的模型以提高性能。在LibriSpeech 960h中,对于step < = 140k,引入具有不确定性0:1的标签平滑,并在后续关闭。对于Switchboard 300h,标签平滑在整个训练过程中保持开启状态。
3.3. 与语言模型的浅层融合
虽然我们可以通过数据增强获得最先进的结果,但是使用语言模型可以进一步提高性能。因此,我们通过浅层融合将RNN语言模型用于两个任务。在浅层融合中,解码过程中的“下一个标记”y∗由以下公式确定:
换句话说,我们通过使用基本的语音识别模型和语言模型共同对词元进行评分来进行联合评分。我们还使用覆盖率惩罚c [29]。对于LibriSpeech,我们使用一个两层的RNN,嵌入维度为1024,这是用于LM的[25]中使用的模型,其在LibriSpeech LM语料库上进行训练。我们在整个过程中使用相同的融合参数(λ=0.35和c=0.05),这些参数在[25]中也被使用。对于Switchboard,我们使用一个两层的RNN,嵌入维度为256,它是在Fisher和Switchboard数据集的组合转录上进行训练的。我们通过在RT-03(LDC2007S10)上测量性能来通过网格搜索找到融合参数。我们在第4.2节中讨论了在个别实验中使用的融合参数。
4.实验
在这一部分中,我们描述了我们在LibriSpeech和Switchboard上使用SpecAugment进行的实验,并报告了优于重构的混合系统的最新成果。
4.1LibriSpeech 960h
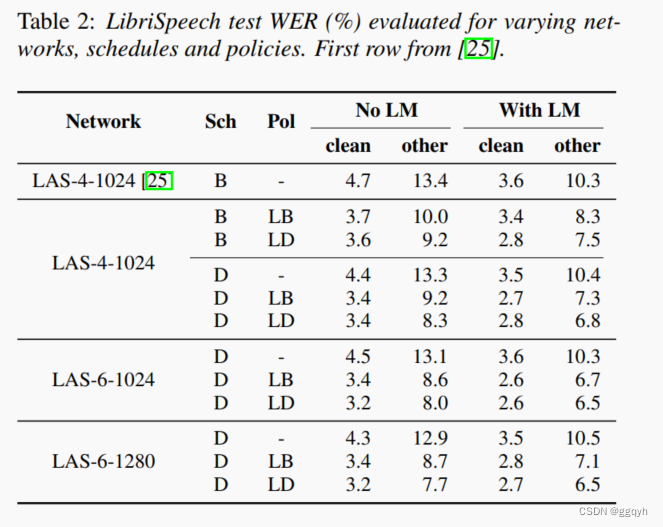
对于LibriSpeech 960h,我们使用与[25]相同的设置,其中我们使用80维度的滤波器组合,采用delta和delta-delta加速度,并使用16k字词片段模型[26]。我们使用三个网络LAS-4-1024、LAS-6-1024和LAS-6-1280在LibriSpeech 960h上进行训练,使用增强策略(无、LB、LD)和训练计划(B/D)的组合。在这些实验中没有应用标签平滑。我们在32个Google Cloud TPU芯片上,以批量大小为512和峰值学习率为0.001的条件下运行实验,持续7天。除了增强策略和学习率计划之外,所有其他超参数都固定,并且没有进行额外的调整。我们在表2中报告了由dev-other集验证的测试集结果。我们看到增强始终提高了训练网络的性能,并且较大的网络和更长的学习率计划的好处在更严格的增强下更为明显。
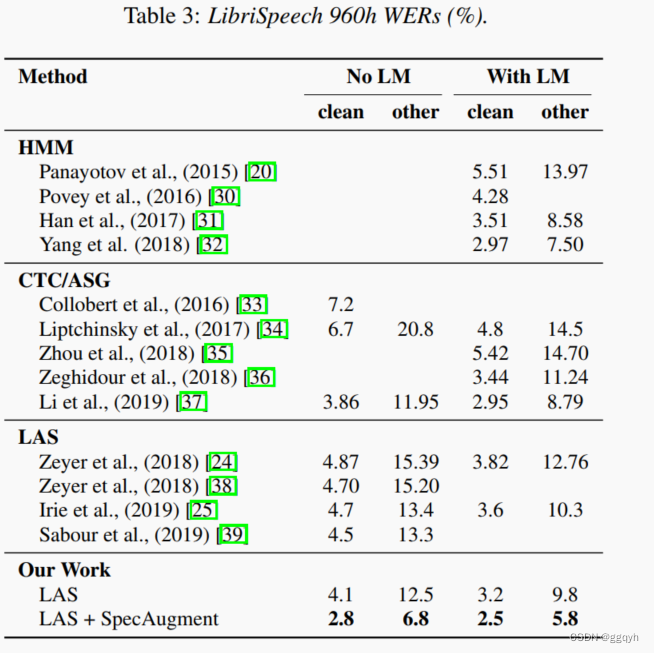
我们选择最大的网络LAS-6-1280,并使用L计划(训练时间约为24天)和策略LD来训练网络以最大化性能。我们在时间步骤<140k时打开标签平滑,如前所述。通过评估具有最佳dev-other性能的检查点,报告测试集性能。即使没有语言模型,LAS-6-1280模型也实现了最先进的性能。我们可以使用浅层融合来结合语言模型以进一步提高性能。结果如表3所示。
4.2 Switchboard 300h
对于Switchboard 300h,我们使用Kaldi [40]的"s5c"配方处理我们的数据,但我们改用80维度的滤波器组合和delta-delta加速度。我们使用1k WPM [26]来标记输出,该输出是使用Switchboard和Fisher语音转录的联合词汇表构建的。
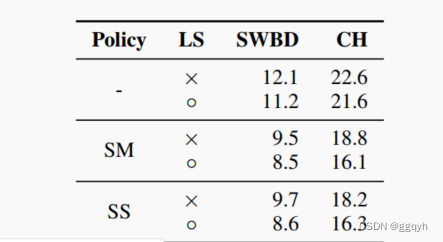
我们使用LAS-4-1024和策略(无、SM、SS)以及计划B进行训练。与之前一样,我们将峰值学习率设置为0.001,总批量大小为512,并使用32个Google Cloud TPU芯片进行训练。在这里,实验分别进行了有和没有标签平滑的情况。由于没有规范的开发集,我们选择在训练计划的结束点评估检查点,我们选择计划B的步骤数为100k。我们注意到,在衰减计划完成后(步骤),训练曲线放缓,网络的性能变化不大。表4展示了不同增强策略在Switchboard 300h上使用/不使用标签平滑的性能。我们可以看到,对于这个语料库,标签平滑和增强具有叠加效应。
与LibriSpeech 960h类似,我们使用Switchboard 300h训练集对LAS-6-1280进行L计划的训练(训练时间约为24天),以获得最先进的性能。在这种情况下,我们发现在整个训练过程中开启标签平滑有益于最终性能。我们在训练时间结束时(340k步)报告性能。我们将我们的结果与其他工作放在表5中进行对比。我们还在Fisher-Switchboard上训练了一个语言模型,并应用了浅层融合,其融合参数是通过在RT-03语料库上评估性能获得的。与LibriSpeech不同,融合参数在不同训练的网络之间并不很好地转移——表5中的三个条目分别使用融合参数(λ, c) = (0.3, 0.05), (0.2, 0.0125) 和 (0.1, 0.025)。
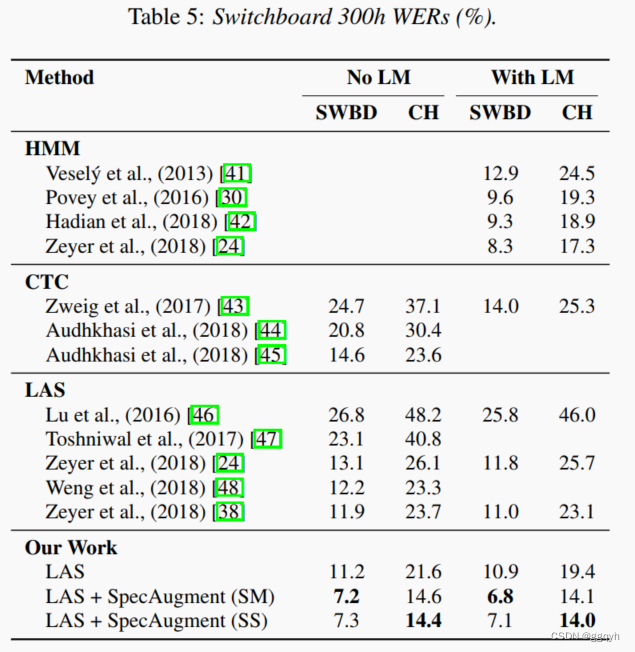
5.讨论
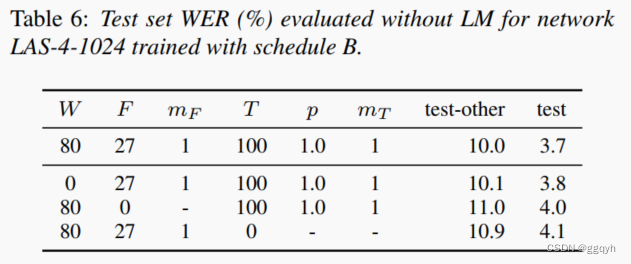
时间扭曲对提高性能有一定贡献,但并不是主要因素。在表6中,我们分别展示了关闭时间扭曲、时间遮蔽和频率遮蔽的三种训练结果。我们可以看到,时间扭曲的效果虽然小,但仍然存在。由于时间扭曲是本文讨论的增强方法中最昂贵且影响最小的方法,如果有预算限制,应首先放弃使用时间扭曲。
标签平滑会给训练引入不稳定性。我们注意到,在对LibriSpeech应用数据增强时,标签平滑会导致不稳定的训练次数增加。这在学习率衰减过程中变得更加明显,因此我们在LibriSpeech训练中引入了一个标签平滑计划,即仅在学习率计划的初始阶段对标签进行平滑处理。
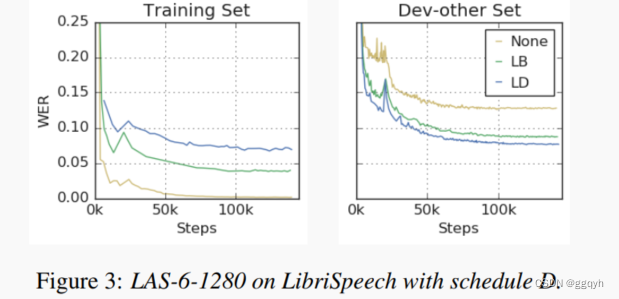
数据增强将过拟合问题转化为欠拟合问题。从图3中可以观察到网络的训练曲线,在训练过程中不仅对增强后的训练集上的损失和词错误率出现了欠拟合,而且在使用增强后的数据进行训练时,也在训练集本身上出现了欠拟合。这与通常情况下网络倾向于对训练数据进行过拟合的情况截然不同。这是使用增强训练的主要优势,如下所解释。
常用的解决欠拟合问题的方法能够带来改进。我们通过采用标准方法来缓解欠拟合问题——扩大网络规模并增加训练时间,取得了显著的性能提升。当前所报告的性能是通过递归过程获得的,首先应用严格的数据增强策略,然后扩展、加深网络,并使用更长的训练计划来解决欠拟合问题。
关于相关工作的评论。我们注意到,在CNN声学模型的背景下,已经研究了类似频率遮蔽的增强方法[49]。在那里,相邻频率块被预先分组成箱子,每个小批量中的箱子会被随机置零。另一方面,在SpecAugment中,频率遮罩的大小和位置都是随机选择的,并且对于每个小批量中的每个输入都不同。有关在谱图中结构上省略频率数据的更多想法已在文献中进行了讨论[50]。
6.结论
SpecAugment极大地提高了ASR网络的性能。通过使用简单的手工制定的策略对训练集进行增强,我们能够在端到端LAS网络上取得LibriSpeech 960h和Switchboard 300h任务的最新成果,甚至在没有语言模型的辅助下超越混合系统的性能。SpecAugment将ASR从过拟合问题转化为欠拟合问题,通过使用更大的网络和更长时间的训练,我们能够获得更好的性能。
致谢:我们要感谢Yuan Cao、Ciprian Chelba、Kazuki Irie、Ye Jia、Anjuli Kannan、Patrick Nguyen、Vijay Peddinti、Rohit Prabhavalkar、Yonghui Wu和Shuyuan Zhang进行有益的讨论。我们还要感谢Gyorgy Kovacs向我们介绍了文献[49, 50]的作品。

















 3093
3093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









