






摘要
2D卷积在声音事件检测(SED)中被广泛使用,用于识别声音事件的二维时频模式。然而,2D卷积在声音事件上施加了沿时间和频率轴的平移等变性,而频率不是平移不变的维度。为了改善2D卷积在SED中的物理一致性,我们提出了频率动态卷积,它应用于适应输入频率分量的核。在DESED验证数据集中,频率动态卷积的多音声音检测分数(PSDS)比基准提高了6.3%。它还在SED上明显优于其他现有的内容自适应方法。此外,通过比较基准和频率动态卷积的按类别F1分数,我们表明频率动态卷积对于检测具有复杂时频模式的非平稳声音事件特别有效。从这个结果中,我们验证了频率动态卷积在识别频率相关模式方面的优越性。
1.引言
声音事件检测(SED)旨在从音频信号中识别声音事件类别和对应的时间戳(起始和结束),自深度学习(DL)方法在各种模式识别领域取得成功以来,SED已经迅速发展[1, 2, 3, 4, 5]。SED已经采用了来自语音处理任务的各种DL方法,比如自动语音识别(ASR)和说话人验证,这些任务也是基于音频信号处理的[6, 7, 8, 9]。然而,并不能保证来自其他领域的DL方法与SED完全兼容。虽然Transformer在自然语言处理(NLP)和ASR中被广泛使用[10, 11],但它在SED上并不一定比现有的卷积递归神经网络(CRNN)表现更好[12, 13, 14]。此外,取得ASR最先进性能的Conformer在SED中表现不稳定[15, 16]。考虑到ASR和SED之间的相似性,即两个任务都将音频数据作为输入并产生顺序输出,Conformer在SED中似乎也是一个合理的选择,但事实证明并非如此。这强调了在将具有资格的DL方法应用于SED之前,必须对其进行彻底的审查。
2D卷积在语音和音频领域的深度学习任务中被广泛使用,用于识别2D时频模式。然而,2D卷积是为了识别2D图像数据而提出的,因此并不完全与音频数据兼容。最近,已经有几次尝试使2D卷积反映音频数据的领域知识,而不是图像数据。对于说话人识别任务,受到语音随时间迅速变化的领域知识的启发,由于语音单元的变化,一些临时适应的2D卷积方法被提出[9, 17, 18]。

同样地,我们应用于声音事件检测(SED)的领域知识,即声音事件呈现出频率相关模式。在SED中,2D卷积沿着时间和频率轴施加平移等变性。这是因为2D卷积是为了设计2D图像数据,而在图1(a)中所示的两个维度上都是平移不变的。然而,不应该沿着频率轴施加平移等变性,因为如图1(b)所示,2D音频数据在频率轴上并不是平移不变的。当时间频率模式沿着频率轴移动时,听起来会有所不同。因此,为了考虑声音事件的频率相关性,更为物理上一致的做法是释放2D卷积沿频率轴的平移等变性。此外,在先前的研究中已经显示SED具有很高的频率相关性,例如FilterAugment [19]。因此,我们提出了一种受领域知识启发的方法,称为频率动态卷积,而不是简单地应用预先存在的内容自适应方法,如使用输入自适应核的动态卷积[20]和使用时间自适应核的时间动态卷积[17]。这项工作的主要贡献如下:
- 我们提出了频率动态卷积,它应用频率自适应核,以释放2D卷积沿频率轴的平移等变性,从而与声音事件中的时频模式在物理上保持一致。
- 提出的频率动态卷积不仅优于基线(提高了6.3%),而且还优于为其他任务提出的其他现有内容自适应方法(动态卷积和时间动态卷积)。
- 通过与基线的按类别性能比较,我们展示了频率动态卷积在非平稳声音事件上特别有效,证明了频率动态卷积在频率相关模式识别上的优越性。
官方实现的代码已经在GitHub上提供。
2.提出的方法
2.1动机
动态卷积是为了增强普通卷积的表示能力而提出的,通过将卷积核适应于给定的输入[20]。动态卷积首先从卷积的输入中提取注意力权重,然后利用注意力权重对基础卷积核进行加权求和,以获得最适合输入的卷积核。类似地,为了进行说话者验证,提出了时间动态卷积,以应用适合每个时间帧的卷积核。它使用适应于输入时间帧的卷积核,以考虑沿时间轴组成口语的各种语音元音[17]。
同样地,我们受到了关于声音事件检测的领域知识的启发,即声音事件模式与频率相关:相同的时频模式在不同频率区域听起来是不同的。在时频域内,某些模式在沿时间轴移动时听起来相同,因为尽管它们发生在不同的时间点,但具有相同的频率成分。另一方面,如果沿频率轴移动,它会听起来不同,因为构成声音事件声学特性的频率成分会发生变化。这种时频模式的特征如图1(b)所示。在频率轴上的微小移动可能只被感知为轻微的音高变化,但大幅度的移动会使我们难以识别原始声音模式的信息。此外,先前的工作证明了频率依赖性在声音事件检测中是一个关键问题。FilterAugment是一种数据增强方法,它在随机频率区域应用不同的权重,证明了在更广泛的频率区域上正则化声音事件检测模型可以显著提高声音事件检测性能,以多声部音频检测分数(PSDS)为例提高了6.5% [19, 21]。这是因为声音事件在各种频率区域展现出独特的模式。这些观点启发我们为声音事件检测开发一种频率相关的模式识别方法。
基于CRNN架构[22]的绝大多数声音事件检测模型使用2D卷积,在输入的两个维度上强制执行平移等变性。计算机视觉领域利用2D卷积的平移等变性来识别图像模式,无论其在图像内的相对位置如何[23, 24]。同样,基于深度学习的音频任务使用2D卷积在时频模式上强制执行平移等变性,沿着时间和频率轴。虽然在声音事件检测中,沿时间轴的平移等变性是有帮助的,但沿频率轴可能没有帮助。2D卷积引入其频率等变性与声音事件的频率依赖性之间的不一致。因此,我们应该在时间维度上保持2D卷积的平移等变性,同时在频率维度上放松它,以提高模型与声音事件的时频模式的物理一致性,并提高声音事件检测性能。提出了频率动态卷积来解决这个问题,使用可以适应输入频率成分的动态卷积核。
2.2频率动态卷积
频率动态卷积使用频率自适应的卷积核,以在2D卷积中施加频率依赖性,从而改善声音事件的时频模式与SED模型的物理一致性。该操作如图2所示。它首先通过沿时间轴进行平均池化,然后沿通道轴施加两个1D卷积层来提取频率自适应的注意力权重。与动态卷积使用全连接(FC)层不同[20],我们使用1D卷积来考虑相邻的频率分量。在两个1D卷积层之间,应用批量归一化和ReLU。1D卷积层将通道维度压缩为基础卷积核的数量。然后,应用softmax函数,使频率自适应的注意力权重范围在零到一之间,并使不同基础卷积核的权重之和等于一。为了确保基础卷积核的统一学习和稳定训练,采用了温度为31的softmax函数[17, 20]。然后,通过使用频率自适应的注意力权重对基础卷积核进行加权求和来获得频率自适应的卷积核,其中基础卷积核也是可训练参数。获得的频率自适应卷积核用于频率动态卷积操作,就像普通的2D卷积一样。

图2:频率动态卷积操作示意图。x和y分别为频率动态卷积层的输入和输出。T、F和分别表示时间、频率和通道的输入维度大小,而
、
和
t则表示时间、频率和通道的输出维度大小。K表示基础卷积核的数量,
和
分别为第i个基础卷积核的权重和偏置,
表示第i个基础卷积核的频率自适应注意力权重。
需要注意的是,上述段落描述的过程是为了更好地解释和呈现频率动态卷积的概念,而官方实现代码中的频率动态卷积程序算法会略有不同,以降低计算成本[17]。虽然程序化算法以相同方式提取频率自适应的注意力权重,但它在应用卷积核时采用了不同的方法。在实际算法中,首先按照(1)得到每个基础卷积核的输出,然后按照(2)进行加权求和,如下所示:
其中,t代表时间,f代表频率,x和y分别是频率动态卷积层的输入和输出,和
分别是第i个基础卷积核的权重和偏置,
是第i个基础卷积核的输出,
是第i个基础卷积核的频率自适应注意力权重,K是基础卷积核的数量。这个过程相当于在上一段中展示的过程,但计算量更少。
3.实验
3.1实施细节
用于SED模型的输入特征是从采样率为16kHz的10秒音频数据中提取的具有128个Mel频率箱的对数Mel频谱图。SED模型使用国内环境声事件检测(DESED)数据集[3]进行训练,该数据集包括合成强标记数据、真实弱标记数据和真实未标记数据。基线模型基于CRNN架构[22]。在最后的全连接层添加了注意力池化模块,用于对弱标记数据进行联合训练,并且应用均值教师方法进行一致性训练,以实现半监督学习中的未标记数据[25]。对数据进行了帧移、mixup[26]、时间掩码[6]和FilterAugment[19]等数据增强操作。基线模型是基于来自[19]的最佳步长类型FilterAugment的模型,包括种子为21、mixup比例为1.0以及按类别不同的中位数滤波器的微小更新。有关基线模型的更多详细信息,请参阅GitHub存储库和相关文献[19, 3, 27, 4]。
3.2评估标准
SED模型被优化以最大化PSDS1和PSDS2的总和,这是用于检测和分类声学场景和事件(DCASE)2021和2022挑战任务4的排名分数。PSDS1偏向于具有准确时间戳的SED系统,而PSDS2偏向于具有较少交叉触发的SED系统。在表格中列出了基于0.5阈值的基于Collar的F1分数和基于交集的F1分数,标签为“CB-F1”和“IB-F1”供参考[2,28]。

表1中列出的指标值基于32个经过训练的模型中每个指标的最佳表现,其中包括16个独立训练运行的学生模型和教师模型。由于动态卷积相对不稳定,因此表现出较大的性能波动,相比之前的工作,进行了更多的训练运行。此外,为了比较动态模型的训练时间,表1列出了使用一块 NVIDIA RTX Titan 训练模型进行200轮迭代所需的时间。
4.结果和讨论
4.1 SED上的动态卷积
我们比较了基线模型与动态卷积[20]、时间动态卷积[17]和提出的频率动态卷积(分别简称为DY-CRNN、TDY-CRNN和FDY-CRNN)的性能。对于所有动态卷积模型,动态卷积层替换了基线模型[20]除第一层外的所有卷积层,使用了四个基础核和温度为31。
从表1的结果来看,FDY-CRNN明显优于其他模型。动态卷积应用于适应整个输入的核。时间动态卷积应用于适应输入的每个时间帧的核。频率动态卷积应用于适应输入的每个频率箱的核。由于适应于输入的每个频率箱的核在SED上表现明显优于其他内容自适应核,我们可以得出结论:SED是一个高度依赖频率的任务。
考虑到时间动态卷积通过提取快速变化的音素中的说话者信息,在文本无关说话者验证中优于动态卷积[17],它似乎在SED中也有优势,因为在时间帧上应用适应核可以帮助SED进行逐帧预测。然而,TDY-CRNN未能超越DY-CRNN,甚至在基线模型上略微领先。这是因为由于语音数据由短且快速变化的音素序列组成,时间依赖性对说话者验证更为关键。尽管时间依赖性在SED中也很重要,因为声音事件在时间轴上也会变化,但我们应该注意,用于SED的CRNN架构已经使用循环神经网络(RNN)层处理了随时间的顺序信息。因此,在性能和训练时间方面,TDY-CRNN比DY-CRNN不够有效。相反,应用频率自适应核的FDY-CRNN表现得更好,因为CRNN架构缺乏考虑频率区域依赖性的功能。
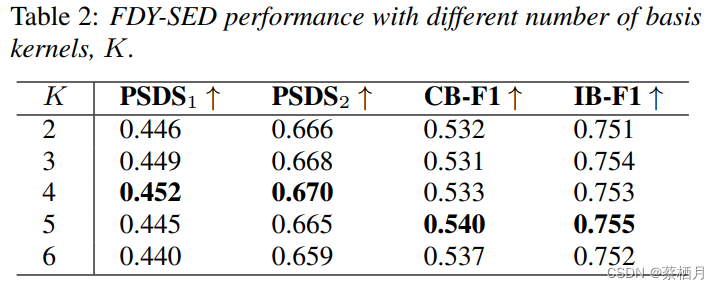
4.2 FDY-CRNN基础核数量
基础核数量 K 直接影响模型的表示能力和计算成本。K 越大,训练后的 SED 模型的表现能力就越强。然而,若 K 过大,不仅会增加计算成本,还可能导致模型过拟合或基础核训练不足。表2显示了在不同基础核数量下 FDY-CRNN 的 SED 性能。从表中可以看出,当 K=4 时,PSDS 值与 [20] 中一样较好,但当 K=5 时 F1 分数更好。由于 PSDS 是一种更全面的度量标准,不依赖于校准阈值,而 CB-F1 和 IB-F1 则依赖于阈值 [21, 2, 28],我们选择基于 PSDS 的最佳模型。
4.3 基线模型和FDY-CRNN的分类性能比较
基于基线模型和FDY-CRNN的分类性能比较,可以更详细地分析频率动态卷积如何影响声音事件检测(SED)性能。我们选择了以下性能代表模型进行比较:基线模型的PSDS1为0.412,PSDS2为0.634,CB-F1为0.515,FDY-CRNN的PSDS1为0.432,PSDS2为0.643,CB-F1为0.532。由于PSDS是一个全面考虑不同类别之间影响的指标,因此使用CB-F1来比较各类别的性能。
可以看到,在图3中,基线模型在搅拌机、油炸和吸尘器方面表现更好。这些准静止声音事件随时间几乎保持静止[29],因此在频谱-时间图中展示简单的时间频率模式,如图4(a)所示的吸尘器声音对数梅尔频谱图。搅拌机和吸尘器的声音主要由运转电机产生的显著周期性机械噪音引起[30]。这些声音事件可能包含其他次要的非静止噪音,比如搅拌机切硬块或吸尘器头部撞击或滚动到其他物体。然而,电机声音足够响亮以至于主导其他噪音,因此这些声音事件可以被视为准静止的。油炸声音是由食物表面水分子蒸发引起的。这种蒸发是随机而持续的,就像雨滴随机落在地面上一样,这是随机噪音的经典例子。因此,油炸声音也可以被归类为随机噪音,同样是准静止的[29]。准静止声音事件随时间几乎不变化,因此在对数梅尔频谱图上呈现出水平模式,就像图4(a)所示的那样。因为这种水平模式在不同频率区域上是简单且相似的,频率动态卷积应用不同核在不同频率区域上的优势在检测准静止声音事件时不太明显。

另一方面,在图3中可以看到,FDY-CRNN在其他声音事件类别上表现更好:警报/铃声、猫、碟子、狗、电动剃须刀/牙刷、流水和语音。这些类别是非静止声音事件,沿时间轴不断变化,因此在对数梅尔频谱图上呈现出复杂的时间频率模式,如图4(b)所示的语音声音对数梅尔频谱图。警报/铃声和碟子涉及短暂和突然的短声音。猫、狗和语音涉及不断变化的音调,带有停顿等冲击声音和摩擦音等瞬时湍流声音[31]。电动剃须刀/牙刷可以被视为类似搅拌机和吸尘器的准静止声音,因为它们也是由电机驱动的。然而,它们的电机声音并不足够响亮以至于主导刷牙或刮胡子时产生的其他冲击噪音。因此,这些声音事件相对是非静止的。流水声可能看起来像油炸声音一样是随机噪音,因为持续流动的水在撞击其他表面时涉及湍流声音[29]。但在家庭环境中,流水涉及与人的互动,因为人们不会让水无缘无故地流淌在家里。人类互动不断干扰着流水的声音,因此它被视为非静止声音事件。非静止声音事件随时间不断改变其频率成分,导致在对数梅尔频谱图的各个频率区域上呈现出更复杂的模式,如图4(b)所示。

通过以上讨论,可以推断出频率动态卷积通过应用频率自适应核极大地改善了声音事件检测性能,增强了对非静止声音事件展示的多样化和复杂模式的识别能力。这一结果再次证明了本研究的前提,即频率动态卷积有效识别声音事件的频率相关模式。
5.结论
频率动态卷积被提出用于识别声音事件数据的频率相关模式。传统的二维卷积在时间和频率轴上都施加平移等变性,但它在物理上与声音事件的频率相关模式不一致。因此,频率动态卷积被设计为通过应用频率自适应核来释放沿频率轴的平移等变性,并强化模型与声音事件中的时间频率模式的物理一致性。对DESED数据集的实验表明,频率动态卷积不仅优于基线模型,还优于动态卷积和时域动态卷积。此外,比较基线模型和FDY-CRNN之间按类别的F1分数显示,频率动态卷积特别有助于检测非静止声音事件,证明了频率动态卷积在频率相关模式上的有效性。















 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









