






探索声音的无限可能:VQ-VAE在声学单元发现与语音转换中的应用
在这个快速发展的AI时代,语音处理技术正以前所未有的速度变革着人机交互界面。今天,我们特别推荐一个令人兴奋的开源项目——VQ-VAE for Acoustic Unit Discovery and Voice Conversion,它利用前沿的深度学习技术,在无监督的环境下探索并转化声音的世界。
项目介绍
VQ-VAE(Vector Quantized Variational Autoencoder)项目,针对ZeroSpeech 2020挑战赛设计,旨在无需直接的语言标签就能自动发现和编码语音的底层单元,并实现高质量的语音转换。通过该项目,开发者可以训练模型以理解音频的基本构成,进而实现不同说话者之间的声音风格迁移。想要亲身体验这项科技的魅力吗?访问这里听一听转换后的语音示例。
技术剖析
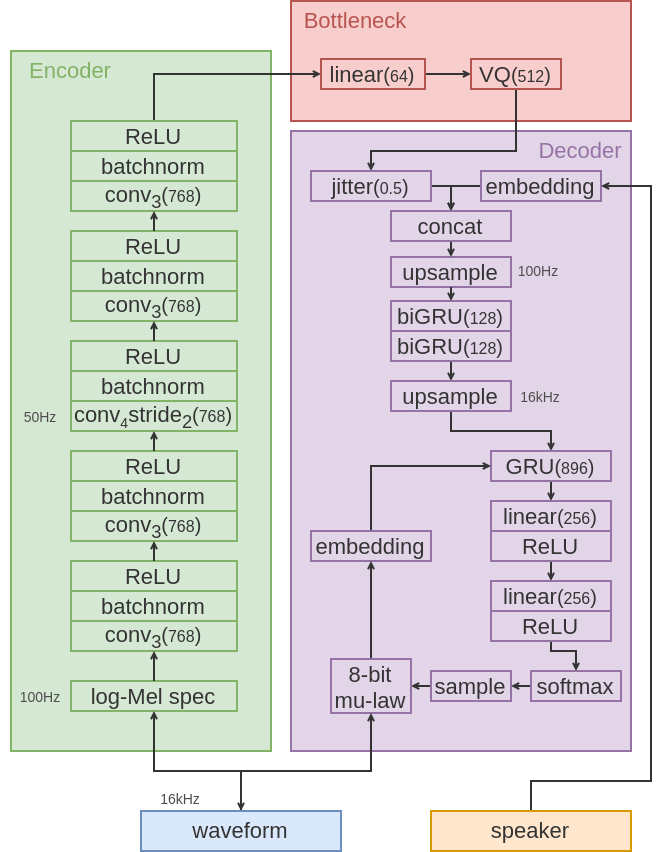
项目基于PyTorch框架,要求版本至少为1.4,支持混合精度训练,这大大加速了模型训练过程。其核心架构如图1所示,是VQ-VAE模型的精巧布局,它通过编码器捕获音频信号的复杂特征,然后通过向量量化层将连续的特征空间映射到离散的“词汇表”中,最后由解码器重构这些离散单元回声音信号。这种方法不仅提高了数据的有效表示,也为语音转换提供了灵活的中间层表示。
应用场景
声音单元发现
研究人员和开发人员可以通过这个工具探索语言的底层结构,用于语音识别系统的改进或新语言模型的构建。
语音转换
即刻变声不是梦!只需提供源音频和目标说话者的标识,项目能实现从一种说话风格到另一种的平滑过渡,适用于游戏配音、虚拟助手个性化定制等领域。
项目亮点
- 无监督学习:无需大量的标注数据,降低资源需求门槛。
- 高效编码:模型通过向量量化减少信息存储成本,提高计算效率。
- 跨语言适应:预训练模型涵盖英语和印尼语,未来将加入更多语言,展示了广泛的应用潜力。
- 透明流程:详细的文档与脚本,使得数据预处理到模型训练再到评估和应用的过程清晰可循,新手也能迅速上手。
无论你是语音技术的狂热爱好者还是致力于提升AI应用的开发者,VQ-VAE for Acoustic Unit Discovery and Voice Conversion都是不容错过的宝藏项目。现在就开始您的声音探索之旅,用代码解锁语音世界的新大门吧!
在探索未知的旅程中,让我们共同见证这一技术如何改变我们对声音的理解和创造方式。立即下载体验,让创新之声响彻耳边!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











