







语音信号处理之(一)动态时间规整(DTW)
这学期有《语音信号处理》这门课,快考试了,所以也要了解了解相关的知识点。呵呵,平时没怎么听课,现在只能抱佛脚了。顺便也总结总结,好让自己的知识架构清晰点,也和大家分享下。下面总结的是第一个知识点:DTW。因为花的时间不多,所以可能会有不少说的不妥的地方,还望大家指正。谢谢。
Dynamic Time Warping(DTW)诞生有一定的历史了(日本学者Itakura提出),它出现的目的也比较单纯,是一种衡量两个长度不同的时间序列的相似度的方法。应用也比较广,主要是在模板匹配中,比如说用在孤立词语音识别(识别两段语音是否表示同一个单词),手势识别,数据挖掘和信息检索等中。
一、概述
在大部分的学科中,时间序列是数据的一种常见表示形式。对于时间序列处理来说,一个普遍的任务就是比较两个序列的相似性。
在时间序列中,需要比较相似性的两段时间序列的长度可能并不相等,在语音识别领域表现为不同人的语速不同。因为语音信号具有相当大的随机性,即使同一个人在不同时刻发同一个音,也不可能具有完全的时间长度。而且同一个单词内的不同音素的发音速度也不同,比如有的人会把“A”这个音拖得很长,或者把“i”发的很短。在这些复杂情况下,使用传统的欧几里得距离无法有效地求的两个时间序列之间的距离(或者相似性)。
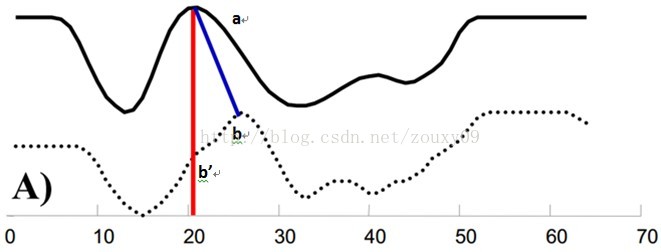
例如图A所示,实线和虚线分别是同一个词“pen”的两个语音波形(在y轴上拉开了,以便观察)。可以看到他们整体上的波形形状很相似,但在时间轴上却是不对齐的。例如在第20个时间点的时候,实线波形的a点会对应于虚线波形的b’点,这样传统的通过比较距离来计算相似性很明显不靠谱。因为很明显,实线的a点对应虚线的b点才是正确的。而在图B中,DTW就可以通过找到这两个波形对齐的点,这样计算它们的距离才是正确的。
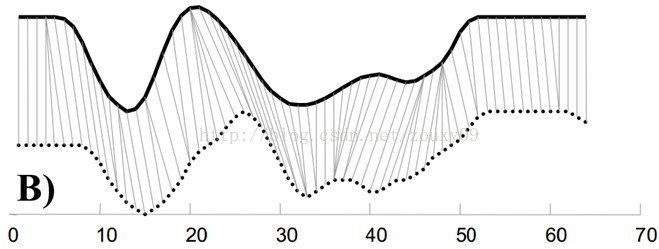
也就是说,大部分情况下,两个序列整体上具有非常相似的形状,但是这些形状在x轴上并不是对齐的。所以我们在比较他们的相似度之前,需要将其中一个(或者两个)序列在时间轴下warping扭曲,以达到更好的对齐。而DTW就是实现这种warping扭曲的一种有效方法。DTW通过把时间序列进行延伸和缩短,来计算两个时间序列性之间的相似性。
那如果才知道两个波形是对齐了呢?也就是说怎么样的warping才是正确的?直观上理解,当然是warping一个序列后可以与另一个序列重合recover。这个时候两个序列中所有对应点的距离之和是最小的。所以从直观上理解,warping的正确性一般指“feature to feature”的对齐。
二、动态时间规整DTW
动态时间规整DTW是一个典型的优化问题,它用满足一定条件的的时间规整函数W(n)描述测试模板和参考模板的时间对应关系,求解两模板匹配时累计距离最小所对应的规整函数。
假设我们有两个时间序列Q和C,他们的长度分别是n和m:(实际语音匹配运用中,一个序列为参考模板,一个序列为测试模板,序列中的每个点的值为语音序列中每一帧的特征值。例如语音序列Q共有n帧,第i帧的特征值(一个数或者一个向量)是qi。至于取什么特征,在这里不影响DTW的讨论。我们需要的是匹配这两个语音序列的相似性,以达到识别我们的测试语音是哪个词)
Q = q1, q2,…,qi,…, qn ;
C = c1, c2,…, cj,…, cm ;
如果n=m,那么就用不着折腾了,直接计算两个序列的距离就好了。但如果n不等于m我们就需要对齐。最简单的对齐方式就是线性缩放了。把短的序列线性放大到和长序列一样的长度再比较,或者把长的线性缩短到和短序列一样的长度再比较。但是这样的计算没有考虑到语音中各个段在不同情况下的持续时间会产生或长或短的变化,因此识别效果不可能最佳。因此更多的是采用动态规划(dynamic programming)的方法。
为了对齐这两个序列,我们需要构造一个n x m的矩阵网格,矩阵元素(i, j)表示qi和cj两个点的距离d(qi, cj)(也就是序列Q的每一个点和C的每一个点之间的相似度,距离越小则相似度越高。这里先不管顺序),一般采用欧式距离,d(qi, cj)= (qi-cj)2(也可以理解为失真度)。每一个矩阵元素(i, j)表示点qi和cj的对齐。DP算法可以归结为寻找一条通过此网格中若干格点的路径,路径通过的格点即为两个序列进行计算的对齐的点。
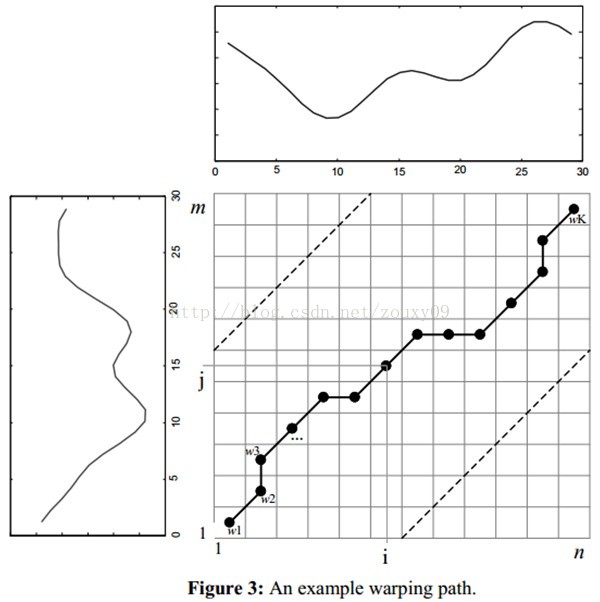
那么这条路径我们怎么找到呢?那条路径才是最好的呢?也就是刚才那个问题,怎么样的warping才是最好的。
我们把这条路径定义为warping path规整路径,并用W来表示, W的第k个元素定义为wk=(i,j)k,定义了序列Q和C的映射。这样我们有:

首先,这条路径不是随意选择的,需要满足以下几个约束:
1)边界条件:w1=(1, 1)和wK=(m, n)。任何一种语音的发音快慢都有可能变化,但是其各部分的先后次序不可能改变,因此所选的路径必定是从左下角出发,在右上角结束。
2)连续性:如果wk-1= (a’, b’),那么对于路径的下一个点wk=(a, b)需要满足 (a-a’) <=1和 (b-b’) <=1。也就是不可能跨过某个点去匹配,只能和自己相邻的点对齐。这样可以保证Q和C中的每个坐标都在W中出现。
3)单调性:如果wk-1= (a’, b’),那么对于路径的下一个点wk=(a, b)需要满足0<=(a-a’)和0<= (b-b’)。这限制W上面的点必须是随着时间单调进行的。以保证图B中的虚线不会相交。
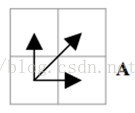
结合连续性和单调性约束,每一个格点的路径就只有三个方向了。例如如果路径已经通过了格点(i, j),那么下一个通过的格点只可能是下列三种情况之一:(i+1, j),(i, j+1)或者(i+1, j+1)。
满足上面这些约束条件的路径可以有指数个,然后我们感兴趣的是使得下面的规整代价最小的路径:
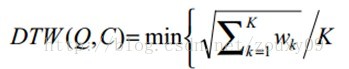
分母中的K主要是用来对不同的长度的规整路径做补偿。我们的目的是什么?或者说DTW的思想是什么?是把两个时间序列进行延伸和缩短,来得到两个时间序列性距离最短也就是最相似的那一个warping,这个最短的距离也就是这两个时间序列的最后的距离度量。在这里,我们要做的就是选择一个路径,使得最后得到的总的距离最小。
这里我们定义一个累加距离cumulative distances。从(0, 0)点开始匹配这两个序列Q和C,每到一个点,之前所有的点计算的距离都会累加。到达终点(n, m)后,这个累积距离就是我们上面说的最后的总的距离,也就是序列Q和C的相似度。
累积距离γ(i,j)可以按下面的方式表示,累积距离γ(i,j)为当前格点距离d(i,j),也就是点qi和cj的欧式距离(相似性)与可以到达该点的最小的邻近元素的累积距离之和:
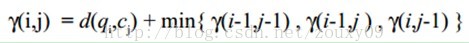
最佳路径是使得沿路径的积累距离达到最小值这条路径。这条路径可以通过动态规划(dynamic programming)算法得到。
具体搜索或者求解过程的直观例子解释可以参考:
http://www.cnblogs.com/tornadomeet/archive/2012/03/23/2413363.html
三、DTW在语音中的运用
假定一个孤立字(词)语音识别系统,利用模板匹配法进行识别。这时一般是把整个单词作为识别单元。在训练阶段,用户将词汇表中的每一个单词说一遍,提取特征后作为一个模板,存入模板库。在识别阶段,对一个新来的需要识别的词,也同样提取特征,然后采用DTW算法和模板库中的每一个模板进行匹配,计算距离。求出最短距离也就是最相似的那个就是识别出来的字了。
四、参考资料
[1] http://baike.baidu.com/view/1647336.htm
[2] http://www.cnblogs.com/tornadomeet/archive/2012/03/23/2413363.html
[3] http://www.cnblogs.com/luxiaoxun/archive/2013/05/09/3069036.html (有matlab/C++ code)
[4] Eamonn J. Keogh, Derivative Dynamic Time Warping
[5]赵立《语音信号处理》
语音信号处理之(二)基音周期估计(Pitch Detection)
这学期有《语音信号处理》这门课,快考试了,所以也要了解了解相关的知识点。呵呵,平时没怎么听课,现在只能抱佛脚了。顺便也总结总结,好让自己的知识架构清晰点,也和大家分享下。下面总结的是第二个知识点:基音周期估计。我们用C++实现了基于自相关函数法的基音周期检测,并且结合了OpenCV来显示语音波形。因为花的时间不多,所以可能会有不少说的不妥的地方,还望大家指正。谢谢。
一、概述
1.1、基音与基音周期估计
人在发音时,根据声带是否震动可以将语音信号分为清音跟浊音两种。浊音又称有声语言,携带者语言中大部分的能量,浊音在时域上呈现出明显的周期性;而清音类似于白噪声,没有明显的周期性。发浊音时,气流通过声门使声带产生张弛震荡式振动,产生准周期的激励脉冲串。这种声带振动的频率称为基音频率,相应的周期就成为基音周期。
通常,基音频率与个人声带的长短、薄厚、韧性、劲度和发音习惯等有关系,在很大程度上反应了个人的特征。此外,基音频率还跟随着人的性别、年龄不同而有所不同。一般来说,男性说话者的基音频率较低,而女性说话者和小孩的基音频率相对较高。
基音周期的估计称谓基音检测,基音检测的最终目的是为了找出和声带振动频率完全一致或尽可能相吻合的轨迹曲线。
基因周期作为语音信号处理中描述激励源的重要参数之一,在语音合成、语音压缩编码、语音识别和说话人确认等领域都有着广泛而重要的问题,尤其对汉语更是如此。汉语是一种有调语言,而基因周期的变化称为声调,声调对于汉语语音的理解极为重要。因为在汉语的相互交谈中,不但要凭借不同的元音、辅音来辨别这些字词的意义,还需要从不同的声调来区别它,也就是说声调具有辨义作用;另外,汉语中存在着多音字现象,同一个字的不同的语气或不同的词义下具有不同的声调。因此准确可靠地进行基音检测对汉语语音信号的处理显得尤为重要。
1.2、基音周期估计的现有方法
到目前为止,基音检测的方法大致上可以分为三类:
1)时域估计法,直接由语音波形来估计基音周期,常见的有:自相关法、并行处理法、平均幅度差法、数据减少法等;
2)变换法,它是一种将语音信号变换到频域或者时域来估计基音周期的方法,首先利用同态分析方法将声道的影响消除,得到属于激励部分的信息,然后求取基音周期,最常用的就是倒谱法,这种方法的缺点就是算法比较复杂,但是基音估计的效果却很好;
3)混合法,先提取信号声道模型参数,然后利用它对信号进行滤波,得到音源序列,最后再利用自相关法或者平均幅度差法求得基因音周期。
三、基于自相关的基音周期检测
3.1、自相关函数
能量有限的语音信号x(n)的短时自相关函数定义为:

此公式表示一个信号和延迟m点后该信号本身的相似性。如果信号x(n)具有周期性,那么它的自相关函数也具有周期性,而且周期与信号x(n)的周期性相同。自相关函数提供了一种获取周期信号周期的方法。在周期信号周期的整数倍上,它的自相关函数可以达到最大值,因此可以不考虑起始时间,而从自相关函数的第一个最大值的位置估计出信号的基音周期,这使自相关函数成为信号基音周期估计的一种工具。
3.2、短时自相关函数法
语音信号是非稳态信号它的特征是随时间变化的,但在一个很短的时间段内可以认为具有相对稳定的特征即短时平稳性。因此语音具有短时自相关性。这个时间段约5ms-50ms。为其统计特性和频谱特性都是对短时段而言的。这使得要对语音信号作数字处理必须先按短时段对语音信号分帧。这样每一帧信号都具有短时平稳性从而进行短时相关分析。
能量有限的语音信号s(n)的短时自相关函数定义为:

一般要求一帧至少包含2个以上的周期。一般,基频最低50Hz,故周期最长为20ms。而且相邻帧之间要有足够的重叠。具体应用时,窗口长度根据采样率确定帧长。

该帧的自相关函数中,除去第一个最大值后(0处),最大值Kmax= 114,那么该帧对应的基频16kHz/114=140Hz。
四、基于自相关的基音周期检测算法实现
这个实现课程要求是用C++来实现的。然后为了画波形,我用到了我比较熟悉的OpenCV。OpenCV画出来的波形还是不错的,而且如果是动态的波形平移,挺好看的,就像心电图那么动人。
实验采用一段男声读“播放”两个字的声音wav文件,其为16KHz采样率,16bit量化。整段语音长656.7ms,节点共10508个。

我们先要确定帧长。下面分别是帧长200,320和400个节点时所包含的周期数。200时只有一个周期,而400有三个周期,所以我们采用400的帧长。

通过计算短时能量区分voice和unvoice。语音信号{x(n)}的某帧信号的短时平均能量En的定义为:

语音中浊音段的短时平均能量远远大于清音段的短时平均能量。因此,短时平均能量的计算给出了区分清音段与浊音段的依据,即En(浊)>En(清)。

计算每一帧的过程中,会显示在原来波形中的位置,并且实时显示该帧得到的基音周期。另外还会在另一个窗口实时显示该帧的原始波形。

该帧的原始波形图(以下为不同时间的两帧,会动态变化):

下面左边的图是计算该语音的所有帧对应的基音周期的点,由图可以看出存在不少的野点。因为,需要对此进行进一步的处理,即去除野点。这里通过中值滤波来除去野点,滤波结果见右图。

C++程序如下:(每按一次空格进入下一个步骤)
- // Description : Pitch detection
- // Author : Zou Xiaoyi
- // HomePage : http://blog.csdn.net/zouxy09
- // Date : 2013/06/08
- // Rev. : 0.1
- #include <iostream>
- #include <fstream>
- #include "opencv2/opencv.hpp"
- #include "ReadWriteWav.h"
- #include <string>
- using namespace std;
- using namespace cv;
- #define MAXLENGTH 1000
- void wav2image(Mat &img, vector<short> wavData, int wav_start, int width, int max_amplitude)
- {
- short max(0), min(0);
- for (int i = 0; i < wavData.size(); i++)
- {
- if (wavData[i] > max)
- max = wavData[i];
- if (wavData[i] < min)
- min = wavData[i];
- }
- cout<<max<<'\t'<<min<<endl;
- max_amplitude = max_amplitude > 480 ? 480 : max_amplitude;
- // normalize
- for (int i = 0; i < wavData.size(); i++)
- {
- wavData[i] = (wavData[i] - min) * max_amplitude / (max - min);
- }
- int j = 0;
- Point prePoint, curPoint;
- if (width >= 400)
- {
- img.create(max_amplitude, width, CV_8UC3);
- img.setTo(Scalar(0, 0, 0));
- for (int i = wav_start; i < wav_start + width; i++)
- {
- prePoint = Point(j, img.rows - (int)wavData[i]);
- if (j)
- line(img, prePoint, curPoint, Scalar(0, 255, 0), 2);
- curPoint = prePoint;
- j++;
- }
- if (width > MAXLENGTH)
- {
- cout<<"The wav is too long to show, and it will be resized to 1200"<<endl;
- resize(img, img, Size(MAXLENGTH, img.rows));
- }
- }
- else
- {
- img.create(max_amplitude, 400, CV_8UC3);
- img.setTo(Scalar(0, 0, 0));
- for (int i = wav_start; i < wav_start + width; i++)
- {
- prePoint = Point(j*400/width, img.rows - (int)wavData[i]);
- circle(img, prePoint, 3, Scalar(0, 0, 255), CV_FILLED);
- j++;
- }
- cout<<"The wav is too small to show, and it will be resized to 400"<<endl;
- }
- }
- short calOneFrameACF(vector<short> wavFrame, int sampleRate)
- {
- vector<float> acf;
- acf.empty();
- // calculate ACF
- for (int k = 0; k < wavFrame.size(); k++)
- {
- float sum = 0.0;
- for (int i = 0; i < wavFrame.size() - k; i++)
- {
- sum = sum + wavFrame[i] * wavFrame[ i + k ];
- }
- acf.push_back(sum);
- }
- // find the max one
- float max(-999);
- int index = 0;
- for (int k = 0; k < wavFrame.size(); k++)
- {
- if (k > 25 && acf[k] > max)
- {
- max = acf[k];
- index = k;
- }
- }
- return (short)sampleRate / index;
- }
- int main()
- {
- const char *wavFile = "bofang.wav";
- vector<short> data;
- int nodesPerFrame = 400;
- /************* Write data to file part Start ***************/
- fstream writeFile;
- writeFile.open("statistics.txt", ios::out);
- /************* Write data to file part End ***************/
- /************* Read and show the input wave part Start ***************/
- int sampleRate;
- int dataLength = wav2allsample(wavFile, data, sampleRate);
- if (!dataLength)
- {
- cout <<"Reading wav file error!"<<endl;
- return -1;
- }
- Mat originalWave;
- wav2image(originalWave, data, 0, dataLength, 400);
- line(originalWave, Point(0, originalWave.rows * 0.5), Point(originalWave.cols, originalWave.rows * 0.5), Scalar(0, 0, 255), 2);
- imshow("originalWave", originalWave);
- // write data
- writeFile<<"Filename: "<<wavFile<<endl<<"SampleRate: "<<sampleRate<<"Hz"<<endl<<"dataLength: "<<dataLength<<endl;
- cout<<"Press space key to continue"<<endl;
- while (waitKey(30) != ' ');
- /************* Read and show the input wave part End ***************/
- /******** Calculate energy to separate voice and unvoice part Start *********/
- int nodeCount = 0;
- // The sum must be double type
- vector<double> energyTmp;
- double maxEnergy(0);
- while(nodeCount < (dataLength - nodesPerFrame))
- {
- double sum(0);
- for (int i = nodeCount; i < (nodeCount + nodesPerFrame); i++)
- {
- sum += (double)data[i] * data[i];
- }
- if (sum > maxEnergy)
- {
- maxEnergy = sum;
- }
- energyTmp.push_back(sum);
- nodeCount++;
- }
- // Transform to short type for show
- vector<short> energy;
- // Fill element of boundary
- short tmp = (short)(energyTmp[0] * 400 / maxEnergy);
- for (int i = 0; i < nodesPerFrame * 0.5; i++)
- {
- energy.push_back(tmp);
- }
- for (int i = 0; i < energyTmp.size(); i++)
- {
- energy.push_back((short)(energyTmp[i] * 400 / maxEnergy));
- }
- // Fill element of boundary
- tmp = (short)(energyTmp[energyTmp.size() - 1] * 400 / maxEnergy);
- for (int i = 0; i < nodesPerFrame * 0.5; i++)
- {
- energy.push_back(tmp);
- }
- // show
- Mat showEnergy;
- wav2image(showEnergy, energy, 0, energy.size(), 400);
- line(showEnergy, Point(0, showEnergy.rows - 1), Point(showEnergy.cols, showEnergy.rows - 1), Scalar(0, 0, 255), 2);
- imshow("showEnergy", showEnergy);
- while (waitKey(30) != ' ');
- // separate voice and unvoice
- float thresVoice = 400 * 0.15;
- line(showEnergy, Point(0, showEnergy.rows - thresVoice), Point(showEnergy.cols, showEnergy.rows - thresVoice), Scalar(0, 255, 255), 2);
- imshow("showEnergy", showEnergy);
- while (waitKey(30) != ' ');
- // Find the Transition point and draw them
- bool high = false;
- vector<int> separateNode;
- for (int i = 0; i < energy.size(); i++)
- {
- if ( !high && energy[i] > thresVoice)
- {
- separateNode.push_back(i);
- high = true;
- writeFile<<"UnVoice to Voice: "<<i<<endl;
- line(showEnergy, Point(i * MAXLENGTH / dataLength, 0), Point(i * MAXLENGTH / dataLength, showEnergy.rows), Scalar(255, 255, 255), 2);
- putText(showEnergy, "Voice", Point(i * MAXLENGTH / dataLength, showEnergy.rows * 0.5 + 40), FONT_HERSHEY_SIMPLEX, 1, Scalar(255, 255, 255), 2);
- imshow("showEnergy", showEnergy);
- while (waitKey(30) != ' ');
- }
- if ( high && energy[i] < thresVoice)
- {
- separateNode.push_back(i);
- high = false;
- writeFile<<"Voice to UnVoice: "<<i<<endl;
- line(showEnergy, Point(i * MAXLENGTH / dataLength, 0), Point(i * MAXLENGTH / dataLength, showEnergy.rows), Scalar(255, 0, 0), 2);
- putText(showEnergy, "UnVoice", Point(i * MAXLENGTH / dataLength, showEnergy.rows * 0.5 + 40), FONT_HERSHEY_SIMPLEX, 1, Scalar(255, 0, 0), 2);
- imshow("showEnergy", showEnergy);
- while (waitKey(30) != ' ');
- }
- }
- /******** Calculate energy to separate voice and unvoice part End ***********/
- /******************* Calculate all frame part Start ***************/
- int frames = 0;
- vector<short> allPitchFre;
- writeFile<<"The pitch frequency is:"<<endl;
- while(frames < 2 * dataLength / nodesPerFrame)
- {
- vector<short> wavFrame;
- wavFrame.empty();
- // get one frame, 400 nodes per frame, and shift 200 nodes, or overlap 200 nodes
- int start = frames * nodesPerFrame * 0.5;
- for (int i = start; i < start + nodesPerFrame; i++)
- wavFrame.push_back(data[i]);
- // calculate the ACF of this frame
- float pitchFreqency = calOneFrameACF(wavFrame, sampleRate);
- allPitchFre.push_back(pitchFreqency);
- cout<<"The pitch frequency is: "<<pitchFreqency <<" Hz"<<endl;
- writeFile<<pitchFreqency<<endl;
- // show current frame in the whole wave
- Mat originalWave;
- wav2image(originalWave, data, 0, dataLength, 400);
- line(originalWave, Point(0, originalWave.rows * 0.5), Point(originalWave.cols, originalWave.rows * 0.5), Scalar(0, 0, 255), 2);
- line(originalWave, Point(start * MAXLENGTH / dataLength, 0), Point(start * MAXLENGTH / dataLength, originalWave.rows), Scalar(0, 0, 255), 2);
- line(originalWave, Point((start + nodesPerFrame)* MAXLENGTH / dataLength, 0), Point((start + nodesPerFrame)* MAXLENGTH / dataLength, originalWave.rows), Scalar(0, 0, 255), 2);
- // put the pitchFreqency of this frame in the whole wave
- stringstream buf;
- buf << pitchFreqency;
- string num = buf.str();
- putText(originalWave, num, Point(start * MAXLENGTH / dataLength, 30), FONT_HERSHEY_SIMPLEX, 0.7, Scalar(0, 0, 255), 2);
- imshow("originalWave", originalWave);
- // show current frame in zoom out model
- Mat oneSelectFrame;
- wav2image(oneSelectFrame, wavFrame, 0, wavFrame.size(), 400);
- imshow("oneSelectFrame", oneSelectFrame);
- if (!frames)
- while (waitKey(30) != ' ');
- frames++;
- waitKey(50);
- }
- cout<<"Num of frames is: "<<frames<<endl;
- /******************* Calculate all frame part End ***************/
- // show all pitch frequency before smooth
- Mat showAllPitchFre;
- wav2image(showAllPitchFre, allPitchFre, 0, allPitchFre.size(), 400);
- putText(showAllPitchFre, "Before smooth", Point(10, showAllPitchFre.rows - 20), FONT_HERSHEY_SIMPLEX, 1, Scalar(60, 200, 255), 1);
- imshow("showAllPitchFre", showAllPitchFre);
- /******************* Smooth by medium filter part Start **************/
- int kernelSize = 5;
- vector<short> afterMedFilter;
- short sum(0);
- afterMedFilter.assign(allPitchFre.size(), allPitchFre[0]);
- for (int k = cvFloor(kernelSize/2); k < allPitchFre.size(); k++)
- {
- vector<short> kernelData;
- for (int i = -cvFloor(kernelSize/2); i < cvCeil (kernelSize/2); i++)
- kernelData.push_back(allPitchFre[k+i]);
- nth_element(kernelData.begin(), kernelData.begin() + cvCeil (kernelSize/2), kernelData.end());
- afterMedFilter[k] = kernelData[cvCeil (kernelSize/2)];
- sum += afterMedFilter[k];
- cout<<afterMedFilter[k]<<endl;
- }
- // show all pitch frequency and mean pitch frequency after smooth
- Mat showAfterMedFilter;
- wav2image(showAfterMedFilter, afterMedFilter, 0, afterMedFilter.size(), 400);
- putText(showAfterMedFilter, "After smooth", Point(10, showAfterMedFilter.rows - 20), FONT_HERSHEY_SIMPLEX, 1, Scalar(60, 200, 255), 1);
- short mean = sum / (afterMedFilter.size() - cvFloor(kernelSize/2));
- writeFile<<"The mean pitch frequency is: "<<mean<<endl;
- stringstream buf;
- buf << mean;
- string num = "Mean: " + buf.str() + "Hz";
- putText(showAfterMedFilter, num, Point(10, 40), FONT_HERSHEY_SIMPLEX, 1, Scalar(255, 200, 255), 2);
- imshow("showAfterMedFilter", showAfterMedFilter);
- /******************* Smooth by medium filter part End ***************/
- while (waitKey(30) != 27);
- return 0;
- }
语音信号处理之(三)矢量量化(Vector Quantization)
这学期有《语音信号处理》这门课,快考试了,所以也要了解了解相关的知识点。呵呵,平时没怎么听课,现在只能抱佛脚了。顺便也总结总结,好让自己的知识架构清晰点,也和大家分享下。下面总结的是第三个知识点:VQ。因为花的时间不多,所以可能会有不少说的不妥的地方,还望大家指正。谢谢。
矢量量化(VQ,Vector Quantization)是一种极其重要的信号压缩方法。VQ在语音信号处理中占十分重要的地位。广泛应用于语音编码、语音识别和语音合成等领域。
一、概述
VectorQuantization (VQ)是一种基于块编码规则的有损数据压缩方法。事实上,在 JPEG 和 MPEG-4 等多媒体压缩格式里都有 VQ 这一步。它的基本思想是:将若干个标量数据组构成一个矢量,然后在矢量空间给以整体量化,从而压缩了数据而不损失多少信息。
在以前,VQ运用的一个难点在于它要要解决一个多维积分(multi-dimensional integration)的问题。后来,在1980年,Linde, Buzo和Gray(LBG,这个缩写也是LBG算法的命名)提出一种基于训练序列的VQ设计算法,对训练序列的运用绕开了多维积分的求解,使得世上又诞生了一种经典的被世人称为LBG-VQ的算法!它一直延绵至今,经典永不褪色。
二、知识准备
VQ实际上就是一种逼近。它的思想和“四舍五入”有异曲同工之妙,都是用一个和一个数最接近的整数来近似表示这个数。我们先来看看一个一维VQ的例子:

这里,小于-2的数都近似为-3,在-2和0之间的数都近似为-1,在0和2之间的数都近似为1,大于2的数都近似为3。这样任意的一个数都会被近似为-3、-1、1或者3这四个数中的其中一个。而我们编码这四个数只需要两个二进制位就行了。所以这是1-dimensional,2-bit VQ,它的rate(量化速率?)为2bits/dimension。
我们再看一个二维的例子:
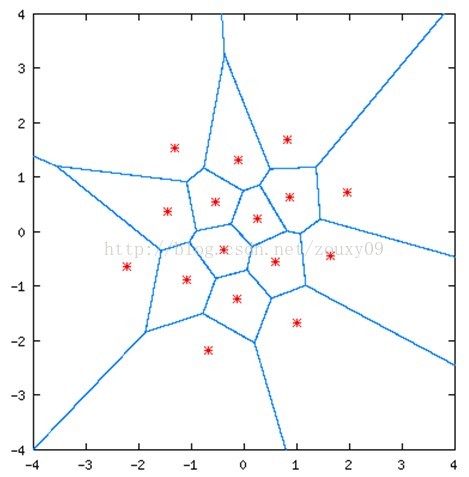
在这里,我们用蓝色实线将这张图划分为16个区域。任意的一对数(也就是横轴x和纵轴y组成的任意的一个坐标点(x, y))都会落到上面这张图中的某一特定区域。然后它就会被该区域的红星的点近似。这里有16块不同区域,就是16个红星点。然后这16个值就可以用4位的二进制码来编码表示(2^4=16)。因此,这是个2-dimensional, 4-bit VQ,它的速率同样是2bits/dimension。上面这些红星点就是量化矢量,表示图中的任意一个点都可以量化为这16个矢量中的其中一个。
对于二维,我们还可以用图像压缩来说明。类似于将图像的每个像素点当作一个数据,跑一下 K-means 聚类,假设将图像聚为k类,就会得到每类的质心centroids,共k个,然后用这些质心的像素值来代替对应的类里的所有点的像素值。这样就起到压缩的目的了,因为只需要编码k个像素值(和图像每个像素点的对这k个值得索引)就可以表示整张图像了。当然,这会存在失真了,失真的程度就是k的个数了。最偏激的就是原图像每个像素就是一个类,那就没有失真了,当然这也没有了压缩。
以上的两个例子,红星被称为码矢(codevectors)。而由蓝色边定义的区域叫做编码区域(encoding regions)。所有码矢的集合称为码书(codebook),所有编码区域的集合称为空间的划分(partition of thespace)。
三、VQ设计问题
VQ问题可以这样描述:给定一个已知统计属性的矢量源(也就是训练样本集,每一个样本是一个矢量)和一个失真测度。还给定了码矢的数量(也就是我们要把这个矢量空间划分为多少部分,或者说量化为多少种值),然后寻找一个具有最小平均失真度(数据压缩,肯定是失真越小越好)的码书(所有码矢的集合,也就是上面的那些所有红色星星点)和空间的划分(图中所有蓝色线的集合)。
假定我们有一个有M个矢量源(训练样本)的训练序列(训练集):T={x1, x2,…, xM};
这个训练序列可以通过一些大数据库得到。例如如果这个矢量源是语音的话,那么我们就可以对一些电话录音裁剪得到。我们假设M足够大(训练样本足够多),这样才可以保证这个训练序列包含了源的所有统计特性。我们假设源矢量是k维的:
xm=(xm,1,xm,2, …, xm,k), m=1,2,…,M
假设码矢的数目是N(也就是我们要把这个矢量空间划分为N个部分,或者说量化为N种值),码书(所有码矢的集合)表示为:C={c1, c2,…, cN};
每一个码矢是个k维向量:cn=(cn,1, cn,2, …, cn,k),n=1,2,…,N;
与码矢cn对应的编码区域表示为Sn,然后将空间的划分表示为:P={S1, S2,…,SN};
如果源矢量xm在Sn内,那么它的近似(用Q(xm)表示)就是cn,
Q(xm)=cn, 如果xm 属于Sn
假设我们采用均分误差失真度量,那么平均失真度表示如下:
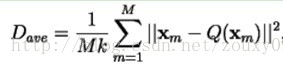
这里||e||2为欧式距离。
那么设计问题就可以简单的描述为:给定T(训练集)和N(码矢数目),找到能使Dave(平均失真度)最小的C(码书)和P(空间划分)。
四、优化准则
如果C和P是上面这个最小化问题的一个解,那么这个解需要满足以下两个条件:
1)Nearest NeighborCondition 最近邻条件:
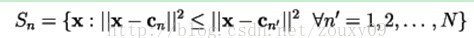
这个条件的意思是编码区域Sn应该包含所有与cn最接近的矢量(相比于与其他码矢的距离)。对于在边界(蓝色线)上面的矢量,需要采用一些决策方法(any tie-breaking procedure)。
2)Centroid Condition质心条件:

这个条件要求码矢cn是编码区域Sn内所有的训练样本向量的平均向量。在实现中,需要保证每个编码区域至少要有一个训练样本向量,这样上面这条式的分母才不为0。
五、LBG算法
LBG-VQ算法是一个迭代算法,它交替地调整P和C(解上面这两个优化准则),使失真度不断地趋向于它的局部最小值(有点EM的思想哦)。这个算法需要一个初始的码书C(0)。这个初始码书可以通过分裂(splitting)方法得到。这个方法主要是把一个初始码矢设置为所有训练样本的平均值。然后把这个码矢分裂成两个(分裂的方式见下面的LBG算法的第3步的公式,只要是乘以一个扰乱系数)。把这两个码矢作为初始的码书,然后迭代算法就在这个初始的码书上面跑。它每一次都将每个码矢分裂为2个,重复这个过程,直到获得要求的码矢个数。1个分裂为2个,2个分裂为4个,4个分裂为8个……
LBG算法:
1、给定训练集T。固定ɛ(失真阈值)为一个很小的正数。
2、让N=1(码矢数量),将这一个码矢设置为所有训练样本的平均值:
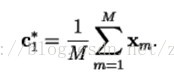
计算总失真度(这时候的总失真很明显是最大的):
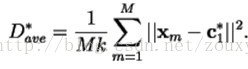
3、分裂:对i=1,2,…,N,他们的码矢分别为:
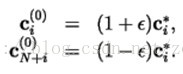
让N=2N,就是每个码矢分裂(乘以扰乱系数1+ɛ和1-ɛ)为两个,这种每一次分裂后的码矢数量就是前一次的两倍。
4、迭代:让初始失真度为: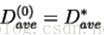
1)对于训练集T中的每一个训练样本m=1,2,…,M。在所有码矢中寻找的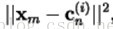
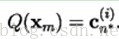
2)对于n=1,2,…,N,通过以下方式更新所有码矢:
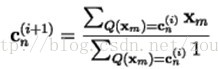
也就是将所有属于cn所在的编码区域Sn的训练样本取平均作为这个编码区域的新的码矢。
3)迭代计数器加1:i=i+1.
4)计算在现阶段的C和P基础上的总失真度:
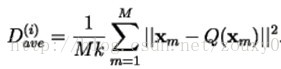
5)如果失真度相比上一次的失真度(相对失真改进量)还大于可以接受的失真阈值ɛ(如果是小于就表明再进行迭代运算失真得减小是有限的以停止迭代运算了),那么继续迭代,返回步骤1)。
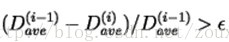
6)否则最终失真度为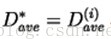
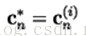
5、重复步骤3和4至到码矢的数目达到要求的个数。
六、二维模拟
二维模拟动画点击这里http://www.data-compression.com/vqanim.shtml(这里吐槽一下,为什么CSDN不支持gif动画的插入呢?)
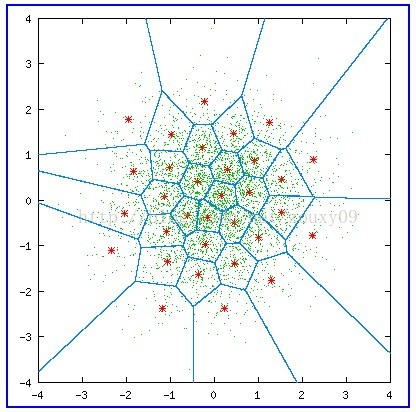
1)训练样本集是由零均值和单位方差的高斯分布产生。
2)小的绿色的点就是这些训练样本。有4096个。
3)我们把阈值设置为ɛ=0.001。
4)这个算法会保证得到一个局部最小解。
5)训练序列需要足够的大,建议M>=1000N。
七、参考资料:
[1]http://www.data-compression.com/vq.html
[2]漫谈Clustering (番外篇): Vector Quantization: http://blog.pluskid.org/?p=57
[3] lbgvq.c --- C program forLBG VQ design
语音信号处理之(四)梅尔频率倒谱系数(MFCC)
这学期有《语音信号处理》这门课,快考试了,所以也要了解了解相关的知识点。呵呵,平时没怎么听课,现在只能抱佛脚了。顺便也总结总结,好让自己的知识架构清晰点,也和大家分享下。下面总结的是第四个知识点:MFCC。因为花的时间不多,所以可能会有不少说的不妥的地方,还望大家指正。谢谢。
在任意一个Automatic speech recognition 系统中,第一步就是提取特征。换句话说,我们需要把音频信号中具有辨识性的成分提取出来,然后把其他的乱七八糟的信息扔掉,例如背景噪声啊,情绪啊等等。
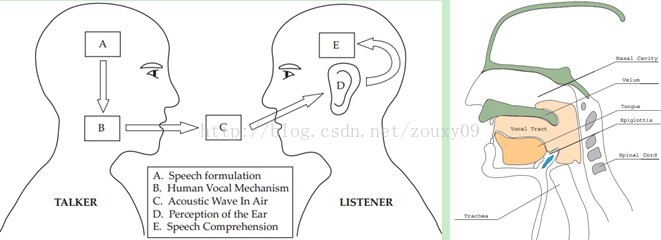
搞清语音是怎么产生的对于我们理解语音有很大帮助。人通过声道产生声音,声道的shape(形状?)决定了发出怎样的声音。声道的shape包括舌头,牙齿等。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素phoneme进行准确的描述。声道的形状在语音短时功率谱的包络中显示出来。而MFCCs就是一种准确描述这个包络的一种特征。
MFCCs(Mel Frequency Cepstral Coefficents)是一种在自动语音和说话人识别中广泛使用的特征。它是在1980年由Davis和Mermelstein搞出来的。从那时起。在语音识别领域,MFCCs在人工特征方面可谓是鹤立鸡群,一枝独秀,从未被超越啊(至于说Deep Learning的特征学习那是后话了)。
好,到这里,我们提到了一个很重要的关键词:声道的形状,然后知道它很重要,还知道它可以在语音短时功率谱的包络中显示出来。哎,那什么是功率谱?什么是包络?什么是MFCCs?它为什么有效?如何得到?下面咱们慢慢道来。
一、声谱图(Spectrogram)
我们处理的是语音信号,那么如何去描述它很重要。因为不同的描述方式放映它不同的信息。那怎样的描述方式才利于我们观测,利于我们理解呢?这里我们先来了解一个叫声谱图的东西。
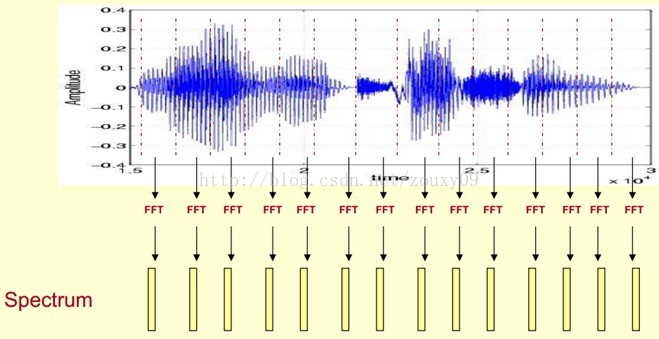
这里,这段语音被分为很多帧,每帧语音都对应于一个频谱(通过短时FFT计算),频谱表示频率与能量的关系。在实际使用中,频谱图有三种,即线性振幅谱、对数振幅谱、自功率谱(对数振幅谱中各谱线的振幅都作了对数计算,所以其纵坐标的单位是dB(分贝)。这个变换的目的是使那些振幅较低的成分相对高振幅成分得以拉高,以便观察掩盖在低幅噪声中的周期信号)。
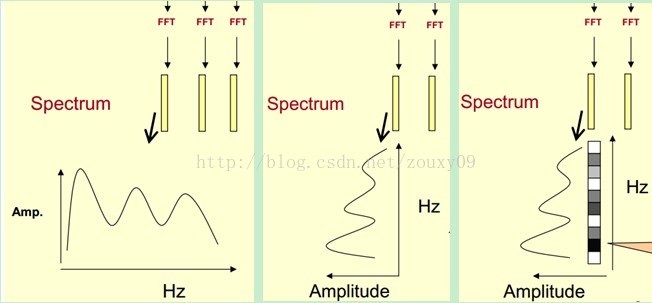
我们先将其中一帧语音的频谱通过坐标表示出来,如上图左。现在我们将左边的频谱旋转90度。得到中间的图。然后把这些幅度映射到一个灰度级表示(也可以理解为将连续的幅度量化为256个量化值?),0表示黑,255表示白色。幅度值越大,相应的区域越黑。这样就得到了最右边的图。那为什么要这样呢?为的是增加时间这个维度,这样就可以显示一段语音而不是一帧语音的频谱,而且可以直观的看到静态和动态的信息。优点稍后呈上。
这样我们会得到一个随着时间变化的频谱图,这个就是描述语音信号的spectrogram声谱图。
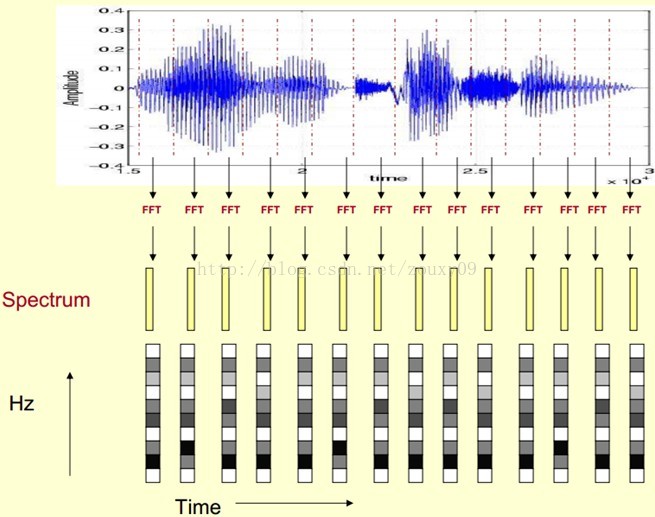
下图是一段语音的声谱图,很黑的地方就是频谱图中的峰值(共振峰formants)。
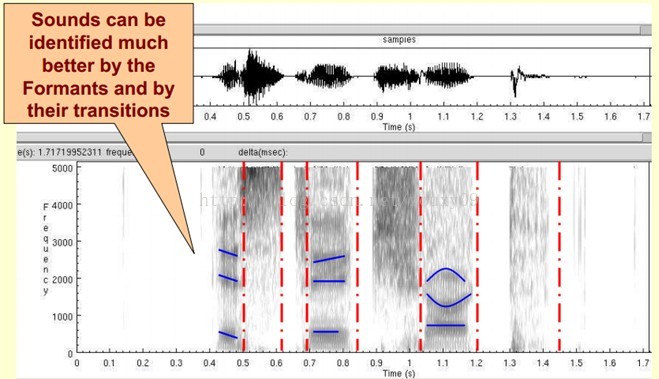
那我们为什么要在声谱图中表示语音呢?
首先,音素(Phones)的属性可以更好的在这里面观察出来。另外,通过观察共振峰和它们的转变可以更好的识别声音。隐马尔科夫模型(Hidden Markov Models)就是隐含地对声谱图进行建模以达到好的识别性能。还有一个作用就是它可以直观的评估TTS系统(text to speech)的好坏,直接对比合成的语音和自然的语音声谱图的匹配度即可。
二、倒谱分析(Cepstrum Analysis)
下面是一个语音的频谱图。峰值就表示语音的主要频率成分,我们把这些峰值称为共振峰(formants),而共振峰就是携带了声音的辨识属性(就是个人身份证一样)。所以它特别重要。用它就可以识别不同的声音。
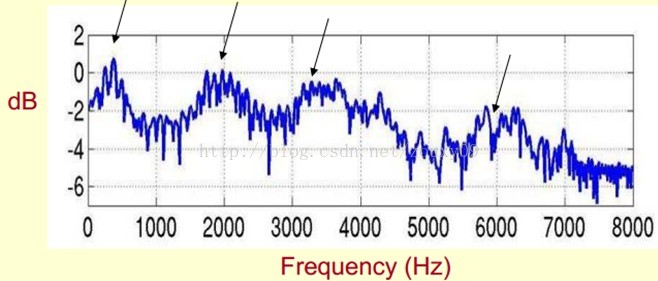
既然它那么重要,那我们就是需要把它提取出来!我们要提取的不仅仅是共振峰的位置,还得提取它们转变的过程。所以我们提取的是频谱的包络(Spectral Envelope)。这包络就是一条连接这些共振峰点的平滑曲线。
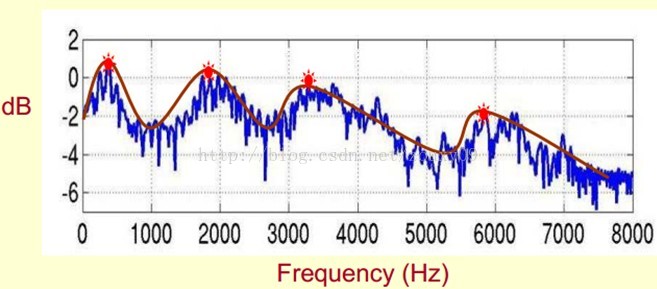
我们可以这么理解,将原始的频谱由两部分组成:包络和频谱的细节。这里用到的是对数频谱,所以单位是dB。那现在我们需要把这两部分分离开,这样我们就可以得到包络了。
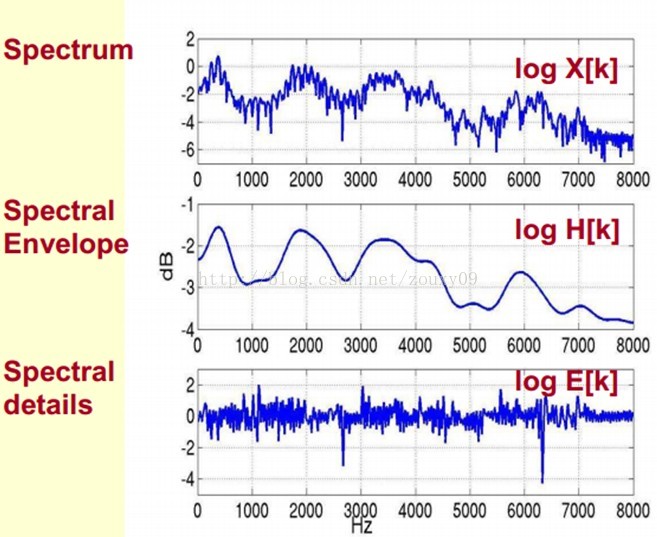
那怎么把他们分离开呢?也就是,怎么在给定log X[k]的基础上,求得log H[k] 和 log E[k]以满足log X[k] = log H[k] + log E[k]呢?
为了达到这个目标,我们需要Play a Mathematical Trick。这个Trick是什么呢?就是对频谱做FFT。在频谱上做傅里叶变换就相当于逆傅里叶变换Inverse FFT (IFFT)。需要注意的一点是,我们是在频谱的对数域上面处理的,这也属于Trick的一部分。这时候,在对数频谱上面做IFFT就相当于在一个伪频率(pseudo-frequency)坐标轴上面描述信号。
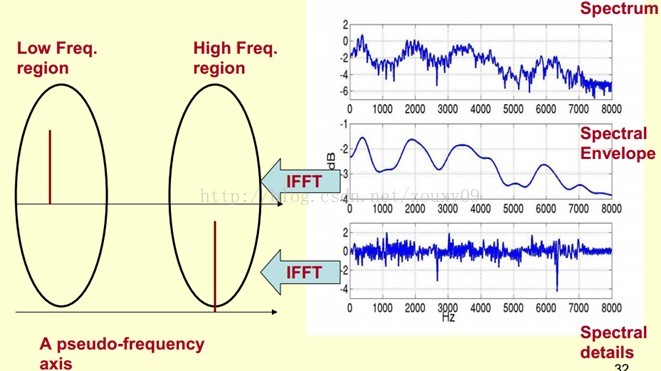
由上面这个图我们可以看到,包络是主要是低频成分(这时候需要转变思维,这时候的横轴就不要看成是频率了,咱们可以看成时间),我们把它看成是一个每秒4个周期的正弦信号。这样我们在伪坐标轴上面的4Hz的地方给它一个峰值。而频谱的细节部分主要是高频。我们把它看成是一个每秒100个周期的正弦信号。这样我们在伪坐标轴上面的100Hz的地方给它一个峰值。
把它俩叠加起来就是原来的频谱信号了。
在实际中咱们已经知道log X[k],所以我们可以得到了x[k]。那么由图可以知道,h[k]是x[k]的低频部分,那么我们将x[k]通过一个低通滤波器就可以得到h[k]了!没错,到这里咱们就可以将它们分离开了,得到了我们想要的h[k],也就是频谱的包络。
x[k]实际上就是倒谱Cepstrum(这个是一个新造出来的词,把频谱的单词spectrum的前面四个字母顺序倒过来就是倒谱的单词了)。而我们所关心的h[k]就是倒谱的低频部分。h[k]描述了频谱的包络,它在语音识别中被广泛用于描述特征。
那现在总结下倒谱分析,它实际上是这样一个过程:
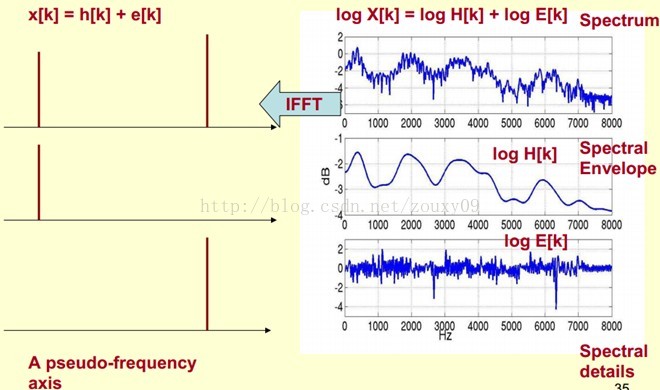
1)将原语音信号经过傅里叶变换得到频谱:X[k]=H[k]E[k];
只考虑幅度就是:|X[k] |=|H[k]||E[k] |;
2)我们在两边取对数:log||X[k] ||= log ||H[k] ||+ log ||E[k] ||。
3)再在两边取逆傅里叶变换得到:x[k]=h[k]+e[k]。
这实际上有个专业的名字叫做同态信号处理。它的目的是将非线性问题转化为线性问题的处理方法。对应上面,原来的语音信号实际上是一个卷性信号(声道相当于一个线性时不变系统,声音的产生可以理解为一个激励通过这个系统),第一步通过卷积将其变成了乘性信号(时域的卷积相当于频域的乘积)。第二步通过取对数将乘性信号转化为加性信号,第三步进行逆变换,使其恢复为卷性信号。这时候,虽然前后均是时域序列,但它们所处的离散时域显然不同,所以后者称为倒谱频域。
总结下,倒谱(cepstrum)就是一种信号的傅里叶变换经对数运算后再进行傅里叶反变换得到的谱。它的计算过程如下:

三、Mel频率分析(Mel-Frequency Analysis)
好了,到这里,我们先看看我们刚才做了什么?给我们一段语音,我们可以得到了它的频谱包络(连接所有共振峰值点的平滑曲线)了。但是,对于人类听觉感知的实验表明,人类听觉的感知只聚焦在某些特定的区域,而不是整个频谱包络。
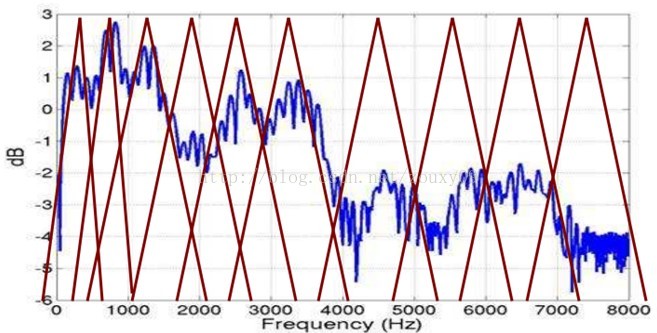
而Mel频率分析就是基于人类听觉感知实验的。实验观测发现人耳就像一个滤波器组一样,它只关注某些特定的频率分量(人的听觉对频率是有选择性的)。也就说,它只让某些频率的信号通过,而压根就直接无视它不想感知的某些频率信号。但是这些滤波器在频率坐标轴上却不是统一分布的,在低频区域有很多的滤波器,他们分布比较密集,但在高频区域,滤波器的数目就变得比较少,分布很稀疏。
人的听觉系统是一个特殊的非线性系统,它响应不同频率信号的灵敏度是不同的。在语音特征的提取上,人类听觉系统做得非常好,它不仅能提取出语义信息, 而且能提取出说话人的个人特征,这些都是现有的语音识别系统所望尘莫及的。如果在语音识别系统中能模拟人类听觉感知处理特点,就有可能提高语音的识别率。
梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)考虑到了人类的听觉特征,先将线性频谱映射到基于听觉感知的Mel非线性频谱中,然后转换到倒谱上。
将普通频率转化到Mel频率的公式是:
由下图可以看到,它可以将不统一的频率转化为统一的频率,也就是统一的滤波器组。
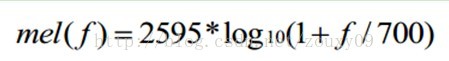
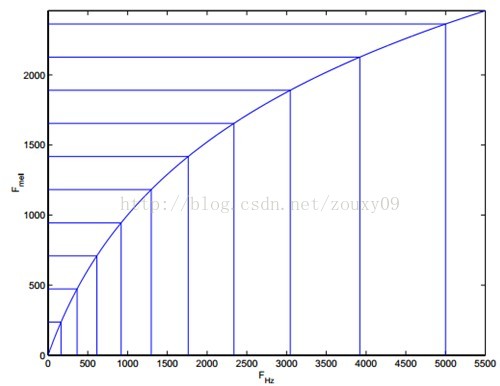
在Mel频域内,人对音调的感知度为线性关系。举例来说,如果两段语音的Mel频率相差两倍,则人耳听起来两者的音调也相差两倍。
四、Mel频率倒谱系数(Mel-Frequency Cepstral Coefficients)
我们将频谱通过一组Mel滤波器就得到Mel频谱。公式表述就是:log X[k] = log (Mel-Spectrum)。这时候我们在log X[k]上进行倒谱分析:
1)取对数:log X[k] = log H[k] + log E[k]。
2)进行逆变换:x[k] = h[k] + e[k]。
在Mel频谱上面获得的倒谱系数h[k]就称为Mel频率倒谱系数,简称MFCC。
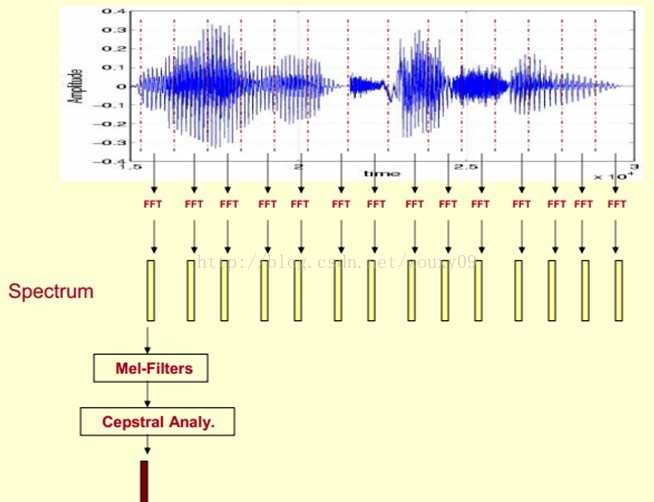
现在咱们来总结下提取MFCC特征的过程:(具体的数学过程网上太多了,这里就不想贴了)
1)先对语音进行预加重、分帧和加窗;
2)对每一个短时分析窗,通过FFT得到对应的频谱;
3)将上面的频谱通过Mel滤波器组得到Mel频谱;
4)在Mel频谱上面进行倒谱分析(取对数,做逆变换,实际逆变换一般是通过DCT离散余弦变换来实现,取DCT后的第2个到第13个系数作为MFCC系数),获得Mel频率倒谱系数MFCC,这个MFCC就是这帧语音的特征;
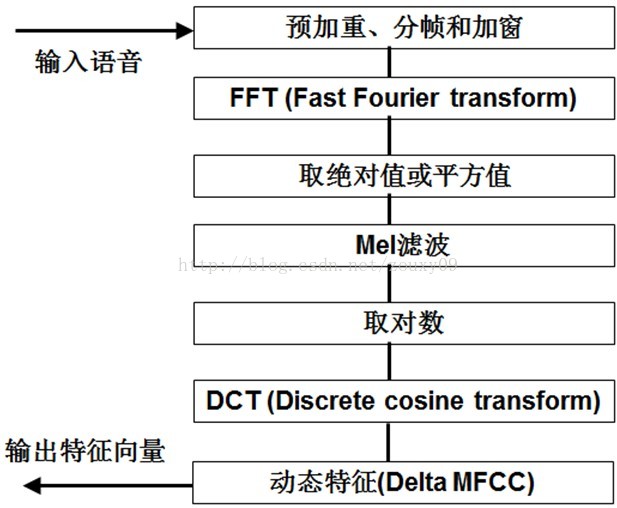
这时候,语音就可以通过一系列的倒谱向量来描述了,每个向量就是每帧的MFCC特征向量。
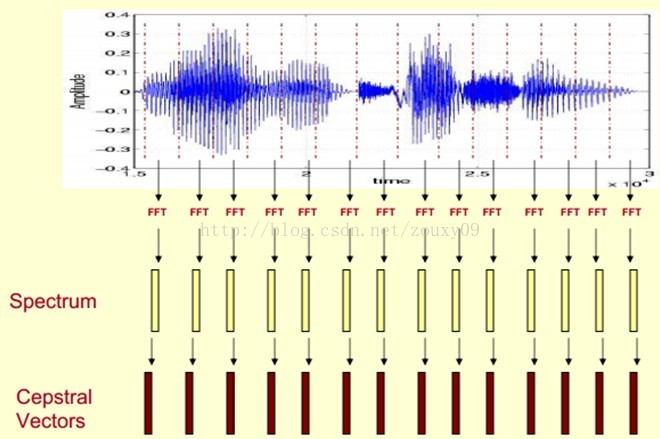
这样就可以通过这些倒谱向量对语音分类器进行训练和识别了。
五、参考文献
[1]这里面还有一个比较好的教程:
[2]本文主要参考:cmu的教程:
http://www.speech.cs.cmu.edu/15-492/slides/03_mfcc.pdf
[3] C library for computing Mel Frequency Cepstral Coefficients (MFCC)















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









