









----------------------------------🔊 语音合成 相关系列直达 🔊 -------------------------------------
✨NaturalSpeech:正在更新中~
✨NaturalSpeech2:TTS | NaturalSpeech2语音合成论文详解及项目实现
本文主要是 讲解了NaturalSpeech论文及项目~
论文题目:202205_NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
论文地址:[2205.04421] NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality (arxiv.org)
1.论文详解
(本博客主要讲解系统实现部分,介绍和背景省略,主要讲解论文第三章)
1.1.设计原理
受图像/视频生成的启发,使用VQ-VAE将高维图像压缩为低维表示以方便生成,该模型利用变分自编码器(Variational Auto-Encoder, VAE),将高维语音x压缩为z表示,相应的先验(记作 p(z|y))则从文本序列 y 中获取。

考虑到来自语音的后验比来自文本的先验更加复杂,研究员们设计了几个模块,尽可能近似地对后验和先验进行匹配,从而通过y→p(z|y)→p(x|z)→x实现文本到语音的合成。
- 在音素编码器上利用大规模音素预训练(phoneme pre-training),从音素序列中提取更好的表达。
- 利用由时长预测器和上采样层组成的完全可微分的时长模块(durator),来改进音素的时长建模。
- 基于流模型(flow)的双向先验/后验模块(bidirectional prior/posterior),可以进一步增强先验 p(z|y) 以及降低后验 q(z|x) 的复杂性。
- 基于记忆的变分自编码器(Memory VAE),可降低重建波形所需的后验复杂性。
1.2.音素编码
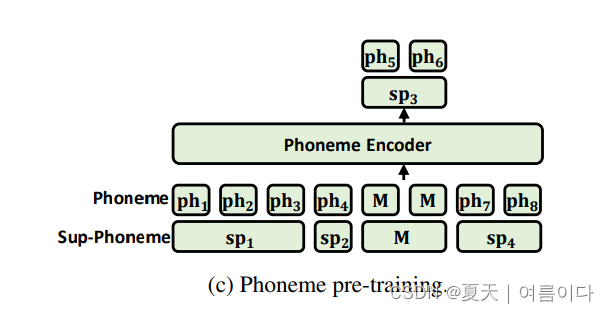
音素编码器θpho和音素序列y和作为输入,并输出音素隐藏序列,进行大规模音素词典学习,提高音素编码器的表达能力。之前的研究表明,在字母/单词级别进行预学习并将预训练模型应用于音素编码器会导致不一致,并且直接使用音素词典学习具有容量限制,因为音素词汇量太小。为了避免这个问题,使用混合音素预学习,它使用音素和上音素(相邻音素合并在一起)作为模型的输入,如图(c)所示。使用掩码语言建模时,会随机屏蔽一些高音素标记及其对应的音素标记,同时预测掩码音素和高音素。混合音素预训练后,使用预训练模型对TTS系统的音素编码器进行初始化。
1.3.可微分的 Durator
可微分的θdur将音素隐藏序列作为输入,并在帧级输出先前的分布序列,如图(a)所示。事先分发给
用于可微分的由几个模块组成
- 基于音素编码器的持续时间预测器,用于预测每个音素的持续时间
- 一个可训练的上采样层,它利用预测的持续时间来训练投影矩阵,以音素隐藏序列的可微分方式将音素级别缩放到帧级别
- 两个附加线性层,用于计算隐藏的均值和方差。
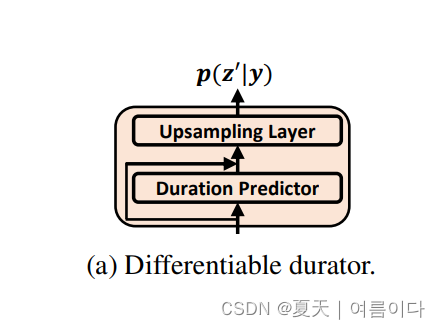
与TTS模型一起,可以以完全可微的方式优化持续时间预测、可训练的上采样层和均值/方差线性层,以减少与先前持续时间预测的学习推理差异。真实持续时间用于训练,预测持续时间用于推理。它以软灵活的方式更好地利用持续时间,而不是硬缩放,从而减轻了持续时间预测不准确的副作用。
1.4.双向先/后验
如图(b)
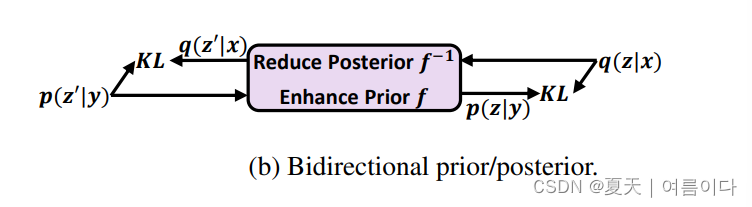
双向前/后验模块是降低后验复杂性。选择流模型作为双向先/后验模型,目标函数是使用 KL 散度损失的简化后验函数,
1.5.带内存的VAE
原始VAE模型的后部用于重建语音波形,因此它比音素序列中的先验波形更复杂。为了进一步减轻先验预测的负担,设计了一种基于记忆的VAE模型来简化后验。
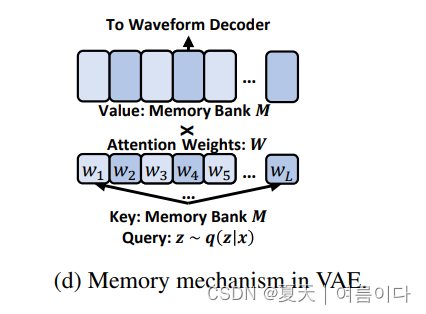
这种设计背后的想法是重建波形∼
作为查询来处理内存库,而不是直接使用它。跟以及波形重建的注意力结果(见上图)。这样就大大简化了,因为它只用于确定记忆库的注意力权重。基于存储器VAE的波形重建损耗如下:
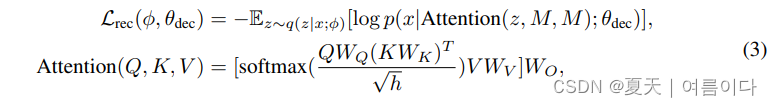
波形解码器不仅包含原始波形也覆盖了模型参数相关的内存机制,包含与存储器机制相关的模型参数,以及存储区M和注意参数等等。这里
和L是存储区的大小,并且ℎ是一个隐藏的维度。
1.6.训练和推理
除了波形重建损失和双向前/后损失外,它还执行完全端到端的优化,以在学习中执行整个推理过程,以获得更好的语音质量。损失函数如下:
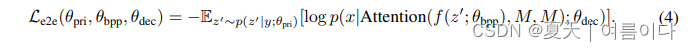
整体损失函数如下
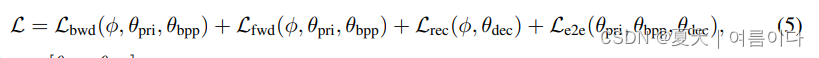
具体实现可参考Appendix E

1.7.实验
数据
- LJSpeech:13,100 音频 (采样率22050) 共 24 小时
- News-Crawl:2亿个句子
- 使用音素器将文本/字母序列转换为音素序列
- 使用线性频谱图作为后验编码器的输入
- 使用STFT获得的线性频谱图(FFT大小=1024,窗口大小=1024,跳跃大小=256)
- 通过将80维mel滤波器组应用于线性频谱图,获得了波形解码器的mel-spectrogram。
模型配置
- 音素编码器
- 6 个前馈变压器 (FFT) 模块的堆栈
- 1个多注意力层 ,1个一维卷积前馈层 ,隐藏大小 192
- 可微分的耐磨器
- 持续时间预测器配置为 3 层卷积
- 双向前/后验模块使用四个连续的仿射耦合层
- 删除了仿射变换中的缩放操作,以稳定双向学习
- 仿射变换的位移由4层WaveNet预测(膨胀率 = 1)
- 后编码器
- 基于 16 层 WaveNet(内核大小=5,膨胀率=1)
- 波形解码器
- 由 4 个残余卷积块组成
- 每个块都是一个 3 层 1D 卷积
训练详情
- 使用 8 个 NVIDIA V100 GPU,32GB
- 动态批处理大小:每个 GPU 8,000 个语音帧(跃点大小 256)
- 学习周期:共 15,000 个
- 学习率: Early2×10−42×10−4、衰减因子 0.999875
- 前 1,000 个 epoch 处于预热阶段,后 2,000 个 epoch 处于调整阶段。
对比实验
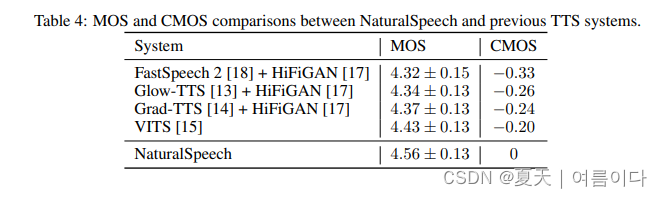
消融实验

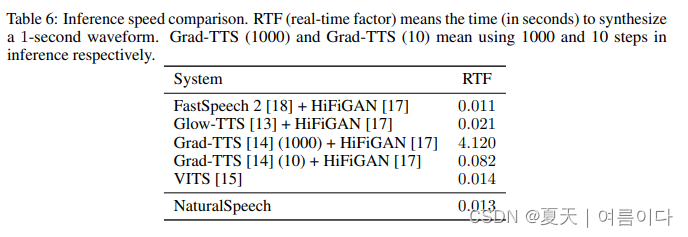
推理延迟
对比了模型模块
2.项目实现
2.0.环境设置
git clone https://github.com/heatz123/naturalspeech
cd naturalspeech
pip install -r requirements.txt
apt-get install espeak
# 准备数据集
# 数据预处理
python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt2.1.数据预处理
2.1.1.LJS数据集
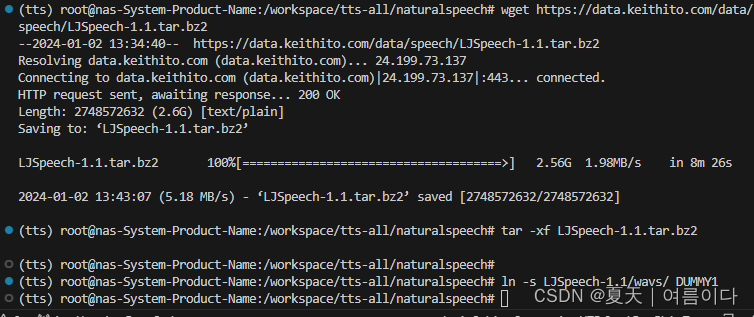
在本项目中,包含了ljs数据集的预处理文件,所以不用单独处理,下载数据集命令
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xf LJSpeech-1.1.tar.bz2
ln -s LJSpeech-1.1/wavs/ DUMMY1
下载数据集后,要将数据集改为以下格式(也就是将文件夹重命名为DUMMY1)
cd durations
tar -xf durations.tar.bz2
将文件夹改为如下格式
2.1.2.自己的数据集
2.1.2.1.修改语言文本代码
首先确认语言,如果是中文就需要将vits中对于中文的处理代码复制到text文件夹下
mandarin.py【附录1】
在text/cleaners.py中添加数据预处理
①添加所需要引用的包:例如
- from text.mandarin import number_to_chinese, chinese_to_bopomofo, latin_to_bopomofo, chinese_to_romaji, chinese_to_lazy_ipa, chinese_to_ipa, chinese_to_ipa2
②添加数据处理代码,例如
- chinese_cleaners【附录2】
- korean_cleaners
-
cjke_cleaners(中日韩英)【附录3】
复制ljs.json文件,重命名为自己的文件(自定义名称),对数据进行处理
python preprocess_texts.py --text_index 1 --filelists filelists/自己数据_train_filelist.txt filelists/自己数据_val_filelist.txt
# python preprocess_texts.py --text_index 1 --filelists filelists/cjke_history_train_filelist.txt filelists/cjke_history_val_filelist.txt --text_cleaners cjke_cleaners2且数据与数据名称相对应
2.1.2.2.获取数据持续时间标签
使用Montreal Forced Aligner(MFA),可参考我的这篇实用工具 | 语音文本对齐MFA的安装及使用_mandarin_pinyin_g2p-CSDN博客
并确保数据集与 LJSpeech 数据集的格式相同,或者修改“TextAudioLoaderWithDuration”来加载自己的数据集。
将MFA生成的npy文件存放到naturalspeech/durations位置下
2.2.训练
2.2.1.训练LJS数据集
python train.py -c configs/ljs.json -m [run_name] --warmup
# python train.py -c configs/ljs.json -m ljs_ns --warmup 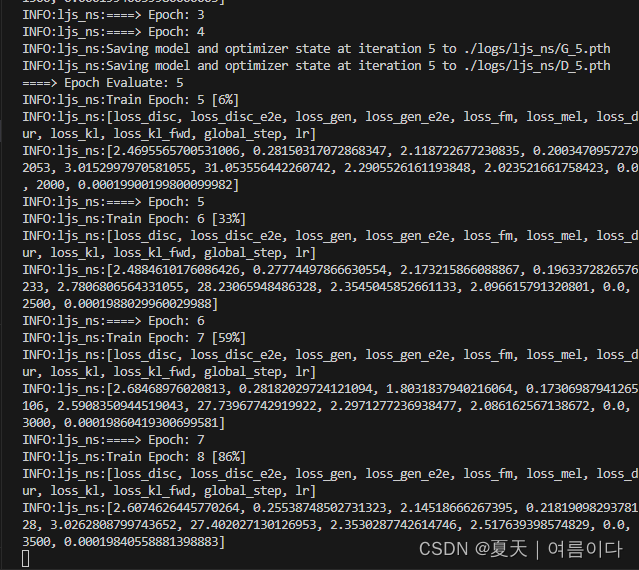
查看训练日志
tensorboard --logdir logs/ljs_ns
python attach_memory_bank.py -c configs/ljs.json --weights_path logs/ljs_ns/G_200.pth
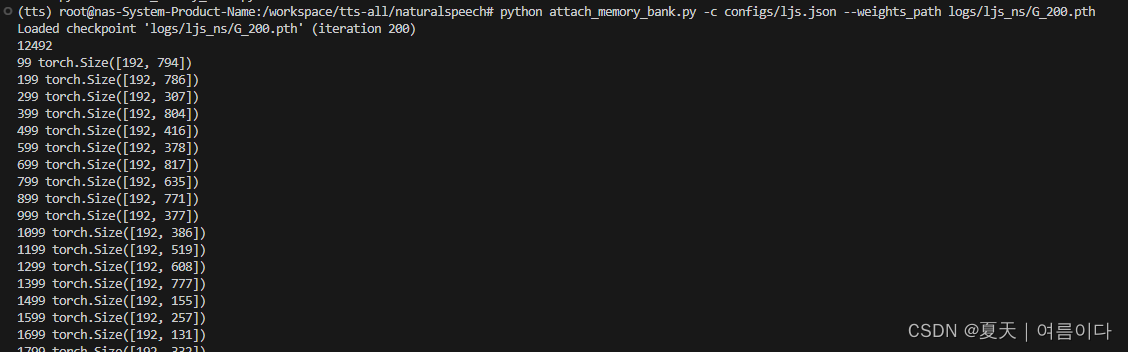
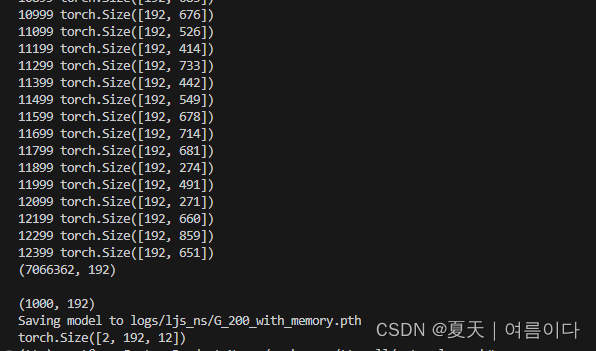
python train.py -c configs/ljs.json -m ljs_ns
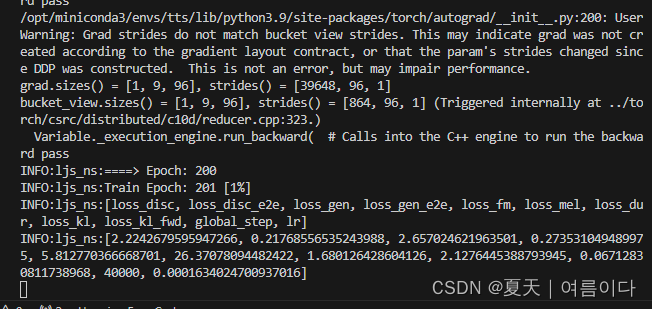
2.2.2.训练自己的数据集
将之前的vits的预训练模型保存到
python train.py -c configs/history.json -m his_ns2.3.推理
LJS数据集
作者原项目没有推理文件
在这里新建一个infer.py
from models.models import (
SynthesizerTrn,
)
from text.symbols import symbols
from utils import utils
from text import text_to_sequence, cleaned_text_to_sequence
from utils import commons
import torch
import scipy
def get_text(text, hps):
text_norm = text_to_sequence(text, hps.data.text_cleaners)
if hps.data.add_blank:
text_norm = commons.intersperse(text_norm, 0)
text_norm = torch.LongTensor(text_norm)
return text_norm
hps = utils.get_hparams_from_file('configs/ljs.json')
model_path = './logs/ljs_ns/G_200.pth'
text = 'test text in text-to-speech with naturalspeech ! '
net_g = SynthesizerTrn(
len(symbols),
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
hps.models,
).cuda(0)
net_g.attach_memory_bank(hps.models)
_, _, _, epoch_str = utils.load_checkpoint(
model_path, net_g, None
)
net_g.eval()
x = get_text(text, hps).cuda().unsqueeze(0)
x_lengths = torch.LongTensor([x.size(1)]).cuda()
with torch.no_grad():
y_hat, mask, *_ = net_g.infer(x, x_lengths, noise_scale=0.667, length_scale=1.1, max_len=1200)
audio = y_hat[0, 0, :].cpu().numpy()
scipy.io.wavfile.write(
filename="ljs_np_result.wav",
rate=hps.data.sampling_rate,
data=audio,
)
3.Naturalspeech与VITS的区别
Naturalspeech 是一种基于 VAE 的模型,它采用多种技术来改进先验并简化后验。它与 VITS 在几个方面不同,包括:
- 音素预训练:Naturalspeech 在大型文本语料库上使用预训练的音素编码器,该编码器是通过对音素序列进行掩码语言建模获得的。
- 可微的后验器:后验在帧级别操作,而前验在音素级别操作。Naturalspeech 使用可微分的 durator 来弥合长度差异,从而扩展柔软而灵活的功能。
- 双向前/后:自然语音通过归一化流来减少后部并增强先验,这在两个方向上映射,具有向前和向后损失。
- 基于记忆的VAE:通过使用Q-K-V注意力的记忆库进一步增强了先验。
错误与解决
【PS1】ValueError: too many values to unpack (expected 2)
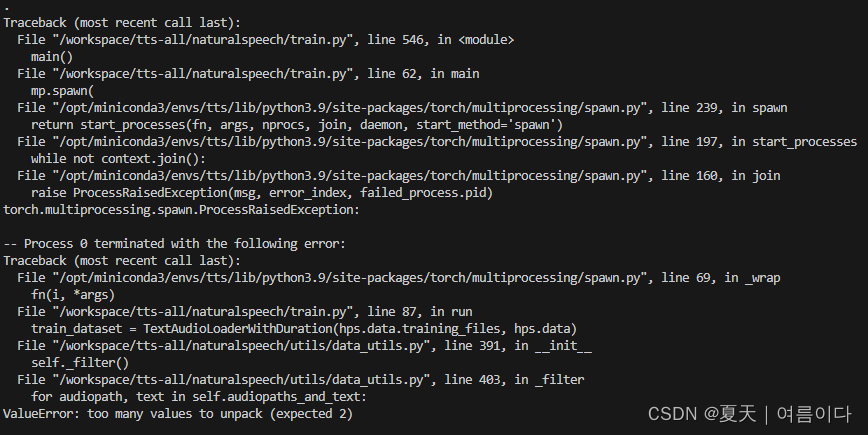
数据预处理格式不对
【PS2】KeyError: '`'
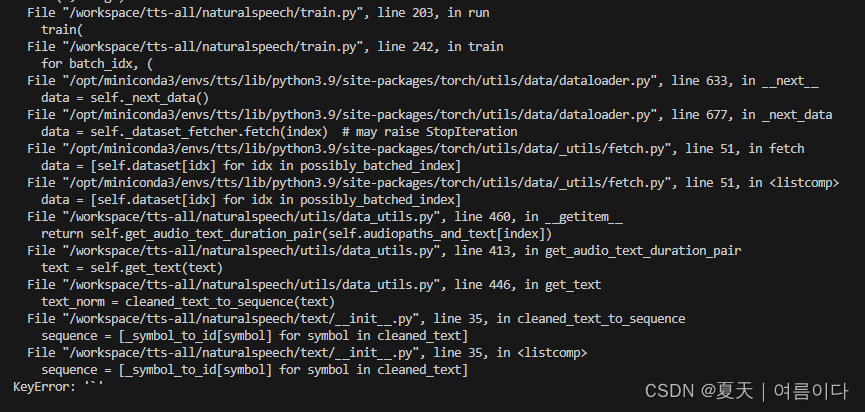
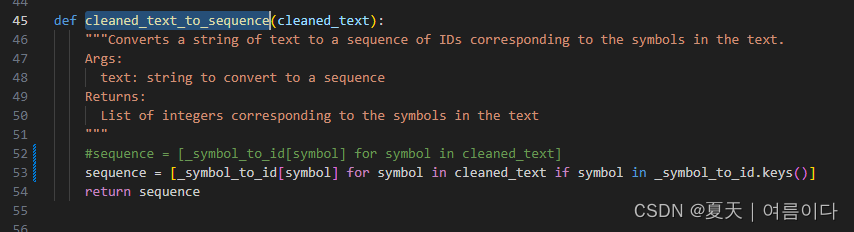
将naturalspeech/text/__init__.py中的cleaned_text_to_sequence改为
sequence = [_symbol_to_id[symbol] for symbol in cleaned_text if symbol in _symbol_to_id.keys()]
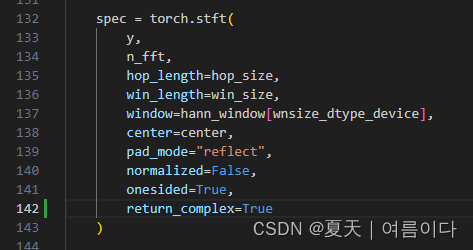
【PS3】RuntimeError: stft requires the return_complex parameter be given for real inputs, and will further require that return_complex=True in a future PyTorch release.
/naturalspeech/utils/mel_processing.py
return_complex=True
【PS4】TypeError: mel() takes 0 positional arguments but 5 were given
库版本问题,此时 librosa版本是0.10.0改为0.9.1或者0.8.0
pip install librosa==0.9.1
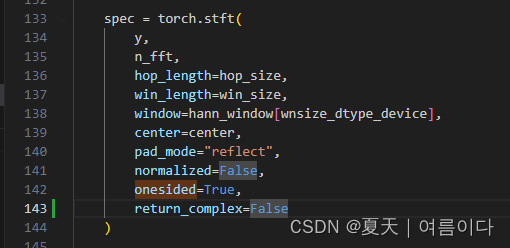
【PS5】RuntimeError: mat1 and mat2 shapes cannot be multiplied (80x513 and 1x513)
pytorch包太新了导致的修改mel_processing.py,
83行【onesided=True后增加,return_complex=False】
143行【onesided=True后增加,return_complex=False】
【PS 6】推理时回升但是没有声音
错误总结
出现【PS345】问题的根本原因是torch版本是2.0.1,如果是1.13.1版本不会出现相关问题。
代码解析
attach_memory_bank.py结合论文第
import os
import argparse
from pathlib import Path
import numpy as np
import torch
from torch.cuda.amp import autocast
from torch.utils.data import DataLoader
from text.symbols import symbols
from models.models import SynthesizerTrn
from models.models import VAEMemoryBank
from utils import utils
from utils.data_utils import (
TextAudioLoaderWithDuration,
TextAudioCollateWithDuration,
)
from sklearn.cluster import KMeans
# 定义下载生成网络
def load_net_g(hps, weights_path):
net_g = SynthesizerTrn(
len(symbols),
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
hps.models,
).cuda()
optim_g = torch.optim.AdamW(
net_g.parameters(),
hps.train.learning_rate,
betas=hps.train.betas,
eps=hps.train.eps,
)
# 定义下载生成网络权重
def load_checkpoint(checkpoint_path, model, optimizer=None):
assert os.path.isfile(checkpoint_path)
checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
# 定义权重iter
iteration = checkpoint_dict["iteration"]
# 定义权重学习率
learning_rate = checkpoint_dict["learning_rate"]
if optimizer is not None:
optimizer.load_state_dict(checkpoint_dict["optimizer"])
# 定义权重模型
saved_state_dict = checkpoint_dict["model"]
state_dict = model.state_dict()
# 建立一个新的静态文件
new_state_dict = {}
# 对于之前权重中的k,v进行保存
for k, v in state_dict.items():
try:
new_state_dict[k] = saved_state_dict[k]
except:
print("%s is not in the checkpoint" % k)
new_state_dict[k] = v
# 加载模型
model.load_state_dict(new_state_dict)
print(
"Loaded checkpoint '{}' (iteration {})".format(checkpoint_path, iteration)
)
return model, optimizer, learning_rate, iteration
model, optimizer, learning_rate, iteration = load_checkpoint(
weights_path, net_g, optim_g
)
return model, optimizer, learning_rate, iteration
def get_dataloader(hps):
train_dataset = TextAudioLoaderWithDuration(hps.data.training_files, hps.data)
collate_fn = TextAudioCollateWithDuration()
train_loader = DataLoader(
train_dataset,
num_workers=1,
shuffle=False,
pin_memory=False,
collate_fn=collate_fn,
batch_size=1,
)
return train_loader
def get_zs(net_g, dataloader, num_samples=0):
net_g.eval()
print(len(dataloader))
zs = []
with torch.no_grad():
for batch_idx, (
x,
x_lengths,
spec,
spec_lengths,
y,
y_lengths,
duration,
) in enumerate(dataloader):
rank = 0
x, x_lengths = x.cuda(rank, non_blocking=True), x_lengths.cuda(
rank, non_blocking=True
)
spec, spec_lengths = spec.cuda(rank, non_blocking=True), spec_lengths.cuda(
rank, non_blocking=True
)
y, y_lengths = y.cuda(rank, non_blocking=True), y_lengths.cuda(
rank, non_blocking=True
)
duration = duration.cuda()
with autocast(enabled=hps.train.fp16_run):
(
y_hat,
l_length,
ids_slice,
x_mask,
z_mask,
(z, z_p, m_p, logs_p, m_q, logs_q, p_mask),
*_,
) = net_g(x, x_lengths, spec, spec_lengths, duration)
zs.append(z.squeeze(0).cpu())
if batch_idx % 100 == 99:
print(batch_idx, zs[batch_idx].shape)
if num_samples and batch_idx >= num_samples:
break
return zs
def k_means(zs):
X = torch.cat(zs, dim=1).transpose(0, 1).numpy()
print(X.shape)
kmeans = KMeans(n_clusters=1000, random_state=0, n_init="auto").fit(X)
print(kmeans.cluster_centers_.shape)
return kmeans.cluster_centers_
def save_memory_bank(bank):
state_dict = bank.state_dict()
torch.save(state_dict, "./bank_init.pth")
def save_checkpoint(model, optimizer, learning_rate, iteration, checkpoint_path):
state_dict = model.state_dict()
torch.save(
{
"model": state_dict,
"iteration": iteration,
"optimizer": optimizer.state_dict(),
"learning_rate": learning_rate,
},
checkpoint_path,
)
print("Saving model to " + checkpoint_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-c", "--config", type=str, default="configs/ljs.json")
parser.add_argument("--weights_path", type=str)
parser.add_argument(
"--num_samples",
type=int,
default=0,
help="samples to use for k-means clustering, 0 for use all samples in dataset",
)
args = parser.parse_args()
hps = utils.get_hparams_from_file(args.config)
net_g, optimizer, lr, iterations = load_net_g(hps, weights_path=args.weights_path)
dataloader = get_dataloader(hps)
zs = get_zs(net_g, dataloader, num_samples=args.num_samples)
centers = k_means(zs)
memory_bank = VAEMemoryBank(
**hps.models.memory_bank,
init_values=torch.from_numpy(centers).cuda().transpose(0, 1)
)
save_memory_bank(memory_bank)
net_g.memory_bank = memory_bank
optimizer.add_param_group(
{
"params": list(memory_bank.parameters()),
"initial_lr": optimizer.param_groups[0]["initial_lr"],
}
)
p = Path(args.weights_path)
save_path = p.with_stem(p.stem + "_with_memory").__str__()
save_checkpoint(net_g, optimizer, lr, iterations, save_path)
# test
print(memory_bank(torch.randn((2, 192, 12))).shape)
附录
【附录1】中文普通话处理代码
import os
import sys
import re
from pypinyin import lazy_pinyin, BOPOMOFO
import jieba
import cn2an
import logging
# List of (Latin alphabet, bopomofo) pairs:
_latin_to_bopomofo = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
('a', 'ㄟˉ'),
('b', 'ㄅㄧˋ'),
('c', 'ㄙㄧˉ'),
('d', 'ㄉㄧˋ'),
('e', 'ㄧˋ'),
('f', 'ㄝˊㄈㄨˋ'),
('g', 'ㄐㄧˋ'),
('h', 'ㄝˇㄑㄩˋ'),
('i', 'ㄞˋ'),
('j', 'ㄐㄟˋ'),
('k', 'ㄎㄟˋ'),
('l', 'ㄝˊㄛˋ'),
('m', 'ㄝˊㄇㄨˋ'),
('n', 'ㄣˉ'),
('o', 'ㄡˉ'),
('p', 'ㄆㄧˉ'),
('q', 'ㄎㄧㄡˉ'),
('r', 'ㄚˋ'),
('s', 'ㄝˊㄙˋ'),
('t', 'ㄊㄧˋ'),
('u', 'ㄧㄡˉ'),
('v', 'ㄨㄧˉ'),
('w', 'ㄉㄚˋㄅㄨˋㄌㄧㄡˋ'),
('x', 'ㄝˉㄎㄨˋㄙˋ'),
('y', 'ㄨㄞˋ'),
('z', 'ㄗㄟˋ')
]]
# List of (bopomofo, romaji) pairs:
_bopomofo_to_romaji = [(re.compile('%s' % x[0]), x[1]) for x in [
('ㄅㄛ', 'p⁼wo'),
('ㄆㄛ', 'pʰwo'),
('ㄇㄛ', 'mwo'),
('ㄈㄛ', 'fwo'),
('ㄅ', 'p⁼'),
('ㄆ', 'pʰ'),
('ㄇ', 'm'),
('ㄈ', 'f'),
('ㄉ', 't⁼'),
('ㄊ', 'tʰ'),
('ㄋ', 'n'),
('ㄌ', 'l'),
('ㄍ', 'k⁼'),
('ㄎ', 'kʰ'),
('ㄏ', 'h'),
('ㄐ', 'ʧ⁼'),
('ㄑ', 'ʧʰ'),
('ㄒ', 'ʃ'),
('ㄓ', 'ʦ`⁼'),
('ㄔ', 'ʦ`ʰ'),
('ㄕ', 's`'),
('ㄖ', 'ɹ`'),
('ㄗ', 'ʦ⁼'),
('ㄘ', 'ʦʰ'),
('ㄙ', 's'),
('ㄚ', 'a'),
('ㄛ', 'o'),
('ㄜ', 'ə'),
('ㄝ', 'e'),
('ㄞ', 'ai'),
('ㄟ', 'ei'),
('ㄠ', 'au'),
('ㄡ', 'ou'),
('ㄧㄢ', 'yeNN'),
('ㄢ', 'aNN'),
('ㄧㄣ', 'iNN'),
('ㄣ', 'əNN'),
('ㄤ', 'aNg'),
('ㄧㄥ', 'iNg'),
('ㄨㄥ', 'uNg'),
('ㄩㄥ', 'yuNg'),
('ㄥ', 'əNg'),
('ㄦ', 'əɻ'),
('ㄧ', 'i'),
('ㄨ', 'u'),
('ㄩ', 'ɥ'),
('ˉ', '→'),
('ˊ', '↑'),
('ˇ', '↓↑'),
('ˋ', '↓'),
('˙', ''),
(',', ','),
('。', '.'),
('!', '!'),
('?', '?'),
('—', '-')
]]
# List of (romaji, ipa) pairs:
_romaji_to_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
('ʃy', 'ʃ'),
('ʧʰy', 'ʧʰ'),
('ʧ⁼y', 'ʧ⁼'),
('NN', 'n'),
('Ng', 'ŋ'),
('y', 'j'),
('h', 'x')
]]
# List of (bopomofo, ipa) pairs:
_bopomofo_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
('ㄅㄛ', 'p⁼wo'),
('ㄆㄛ', 'pʰwo'),
('ㄇㄛ', 'mwo'),
('ㄈㄛ', 'fwo'),
('ㄅ', 'p⁼'),
('ㄆ', 'pʰ'),
('ㄇ', 'm'),
('ㄈ', 'f'),
('ㄉ', 't⁼'),
('ㄊ', 'tʰ'),
('ㄋ', 'n'),
('ㄌ', 'l'),
('ㄍ', 'k⁼'),
('ㄎ', 'kʰ'),
('ㄏ', 'x'),
('ㄐ', 'tʃ⁼'),
('ㄑ', 'tʃʰ'),
('ㄒ', 'ʃ'),
('ㄓ', 'ts`⁼'),
('ㄔ', 'ts`ʰ'),
('ㄕ', 's`'),
('ㄖ', 'ɹ`'),
('ㄗ', 'ts⁼'),
('ㄘ', 'tsʰ'),
('ㄙ', 's'),
('ㄚ', 'a'),
('ㄛ', 'o'),
('ㄜ', 'ə'),
('ㄝ', 'ɛ'),
('ㄞ', 'aɪ'),
('ㄟ', 'eɪ'),
('ㄠ', 'ɑʊ'),
('ㄡ', 'oʊ'),
('ㄧㄢ', 'jɛn'),
('ㄩㄢ', 'ɥæn'),
('ㄢ', 'an'),
('ㄧㄣ', 'in'),
('ㄩㄣ', 'ɥn'),
('ㄣ', 'ən'),
('ㄤ', 'ɑŋ'),
('ㄧㄥ', 'iŋ'),
('ㄨㄥ', 'ʊŋ'),
('ㄩㄥ', 'jʊŋ'),
('ㄥ', 'əŋ'),
('ㄦ', 'əɻ'),
('ㄧ', 'i'),
('ㄨ', 'u'),
('ㄩ', 'ɥ'),
('ˉ', '→'),
('ˊ', '↑'),
('ˇ', '↓↑'),
('ˋ', '↓'),
('˙', ''),
(',', ','),
('。', '.'),
('!', '!'),
('?', '?'),
('—', '-')
]]
# List of (bopomofo, ipa2) pairs:
_bopomofo_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
('ㄅㄛ', 'pwo'),
('ㄆㄛ', 'pʰwo'),
('ㄇㄛ', 'mwo'),
('ㄈㄛ', 'fwo'),
('ㄅ', 'p'),
('ㄆ', 'pʰ'),
('ㄇ', 'm'),
('ㄈ', 'f'),
('ㄉ', 't'),
('ㄊ', 'tʰ'),
('ㄋ', 'n'),
('ㄌ', 'l'),
('ㄍ', 'k'),
('ㄎ', 'kʰ'),
('ㄏ', 'h'),
('ㄐ', 'tɕ'),
('ㄑ', 'tɕʰ'),
('ㄒ', 'ɕ'),
('ㄓ', 'tʂ'),
('ㄔ', 'tʂʰ'),
('ㄕ', 'ʂ'),
('ㄖ', 'ɻ'),
('ㄗ', 'ts'),
('ㄘ', 'tsʰ'),
('ㄙ', 's'),
('ㄚ', 'a'),
('ㄛ', 'o'),
('ㄜ', 'ɤ'),
('ㄝ', 'ɛ'),
('ㄞ', 'aɪ'),
('ㄟ', 'eɪ'),
('ㄠ', 'ɑʊ'),
('ㄡ', 'oʊ'),
('ㄧㄢ', 'jɛn'),
('ㄩㄢ', 'yæn'),
('ㄢ', 'an'),
('ㄧㄣ', 'in'),
('ㄩㄣ', 'yn'),
('ㄣ', 'ən'),
('ㄤ', 'ɑŋ'),
('ㄧㄥ', 'iŋ'),
('ㄨㄥ', 'ʊŋ'),
('ㄩㄥ', 'jʊŋ'),
('ㄥ', 'ɤŋ'),
('ㄦ', 'əɻ'),
('ㄧ', 'i'),
('ㄨ', 'u'),
('ㄩ', 'y'),
('ˉ', '˥'),
('ˊ', '˧˥'),
('ˇ', '˨˩˦'),
('ˋ', '˥˩'),
('˙', ''),
(',', ','),
('。', '.'),
('!', '!'),
('?', '?'),
('—', '-')
]]
def number_to_chinese(text):
numbers = re.findall(r'\d+(?:\.?\d+)?', text)
for number in numbers:
text = text.replace(number, cn2an.an2cn(number), 1)
return text
def chinese_to_bopomofo(text):
text = text.replace('、', ',').replace(';', ',').replace(':', ',')
words = jieba.lcut(text, cut_all=False)
text = ''
for word in words:
bopomofos = lazy_pinyin(word, BOPOMOFO)
if not re.search('[\u4e00-\u9fff]', word):
text += word
continue
for i in range(len(bopomofos)):
bopomofos[i] = re.sub(r'([\u3105-\u3129])$', r'\1ˉ', bopomofos[i])
if text != '':
text += ' '
text += ''.join(bopomofos)
return text
def latin_to_bopomofo(text):
for regex, replacement in _latin_to_bopomofo:
text = re.sub(regex, replacement, text)
return text
def bopomofo_to_romaji(text):
for regex, replacement in _bopomofo_to_romaji:
text = re.sub(regex, replacement, text)
return text
def bopomofo_to_ipa(text):
for regex, replacement in _bopomofo_to_ipa:
text = re.sub(regex, replacement, text)
return text
def bopomofo_to_ipa2(text):
for regex, replacement in _bopomofo_to_ipa2:
text = re.sub(regex, replacement, text)
return text
def chinese_to_romaji(text):
text = number_to_chinese(text)
text = chinese_to_bopomofo(text)
text = latin_to_bopomofo(text)
text = bopomofo_to_romaji(text)
text = re.sub('i([aoe])', r'y\1', text)
text = re.sub('u([aoəe])', r'w\1', text)
text = re.sub('([ʦsɹ]`[⁼ʰ]?)([→↓↑ ]+|$)',
r'\1ɹ`\2', text).replace('ɻ', 'ɹ`')
text = re.sub('([ʦs][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text)
return text
def chinese_to_lazy_ipa(text):
text = chinese_to_romaji(text)
for regex, replacement in _romaji_to_ipa:
text = re.sub(regex, replacement, text)
return text
def chinese_to_ipa(text):
text = number_to_chinese(text)
text = chinese_to_bopomofo(text)
text = latin_to_bopomofo(text)
text = bopomofo_to_ipa(text)
text = re.sub('i([aoe])', r'j\1', text)
text = re.sub('u([aoəe])', r'w\1', text)
text = re.sub('([sɹ]`[⁼ʰ]?)([→↓↑ ]+|$)',
r'\1ɹ`\2', text).replace('ɻ', 'ɹ`')
text = re.sub('([s][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text)
return text
def chinese_to_ipa2(text):
text = number_to_chinese(text)
text = chinese_to_bopomofo(text)
text = latin_to_bopomofo(text)
text = bopomofo_to_ipa2(text)
text = re.sub(r'i([aoe])', r'j\1', text)
text = re.sub(r'u([aoəe])', r'w\1', text)
text = re.sub(r'([ʂɹ]ʰ?)([˩˨˧˦˥ ]+|$)', r'\1ʅ\2', text)
text = re.sub(r'(sʰ?)([˩˨˧˦˥ ]+|$)', r'\1ɿ\2', text)
return text
附录2 中文
def chinese_cleaners(text):
'''Pipeline for Chinese text'''
text = number_to_chinese(text)
text = chinese_to_bopomofo(text)
text = latin_to_bopomofo(text)
text = re.sub(r'([ˉˊˇˋ˙])$', r'\1。', text)
return text附录3 多语言处理
def cjke_cleaners(text):
text = re.sub(r'\[ZH\](.*?)\[ZH\]', lambda x: chinese_to_lazy_ipa(x.group(1)).replace(
'ʧ', 'tʃ').replace('ʦ', 'ts').replace('ɥan', 'ɥæn')+' ', text)
text = re.sub(r'\[JA\](.*?)\[JA\]', lambda x: japanese_to_ipa(x.group(1)).replace('ʧ', 'tʃ').replace(
'ʦ', 'ts').replace('ɥan', 'ɥæn').replace('ʥ', 'dz')+' ', text)
text = re.sub(r'\[KO\](.*?)\[KO\]',
lambda x: korean_to_ipa(x.group(1))+' ', text)
text = re.sub(r'\[EN\](.*?)\[EN\]', lambda x: english_to_ipa2(x.group(1)).replace('ɑ', 'a').replace(
'ɔ', 'o').replace('ɛ', 'e').replace('ɪ', 'i').replace('ʊ', 'u')+' ', text)
text = re.sub(r'\s+$', '', text)
text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
return text
def cjke_cleaners2(text):
text = re.sub(r'\[ZH\](.*?)\[ZH\]',
lambda x: chinese_to_ipa(x.group(1))+' ', text)
text = re.sub(r'\[JA\](.*?)\[JA\]',
lambda x: japanese_to_ipa2(x.group(1))+' ', text)
text = re.sub(r'\[KO\](.*?)\[KO\]',
lambda x: korean_to_ipa(x.group(1))+' ', text)
text = re.sub(r'\[EN\](.*?)\[EN\]',
lambda x: english_to_ipa2(x.group(1))+' ', text)
text = re.sub(r'\s+$', '', text)
text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
return text附录4 自定义requirements.txt
Cython>=0.29.21
librosa>=0.8.0
matplotlib>=3.3.1
numpy>=1.18.5
phonemizer>=2.2.1
scipy>=1.5.2
tensorboard>=2.3.0
torch>=1.6.0
torchvision>=0.7.0
Unidecode>=1.1.1
pysoundfile==0.9.0.post1
jamo==0.4.1
ko_pron==1.3
g2pk2
mecab
python-mecab-ko
附录5 错误记录
20240104 将G_200_with_memory.pth修改为G_200pth,并进行训练。



















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











