






探索形状识别的新境界:Multi-view CNN(MVCNN)
在这个数字化时代,理解和识别物体的三维形状是许多应用程序的核心,从虚拟现实到自动驾驶汽车。为此,我们向您推荐一个创新的开源项目——Multi-view Convolutional Neural Networks (MVCNN),一个专为形状识别设计的强大工具。
1、项目介绍
MVCNN 是由 Hang Su 等人开发的一个深度学习模型,其目标是通过使用基于视图的形状表示来训练判别模型,从而实现形状的通用描述符学习。该项目不仅支持线描图、去色的剪贴画图像和缺乏纹理信息的3D模型渲染,还提供了多个开源实现,包括PyTorch、Caffe、Tensorflow和Torch版本,以适应不同的开发环境需求。
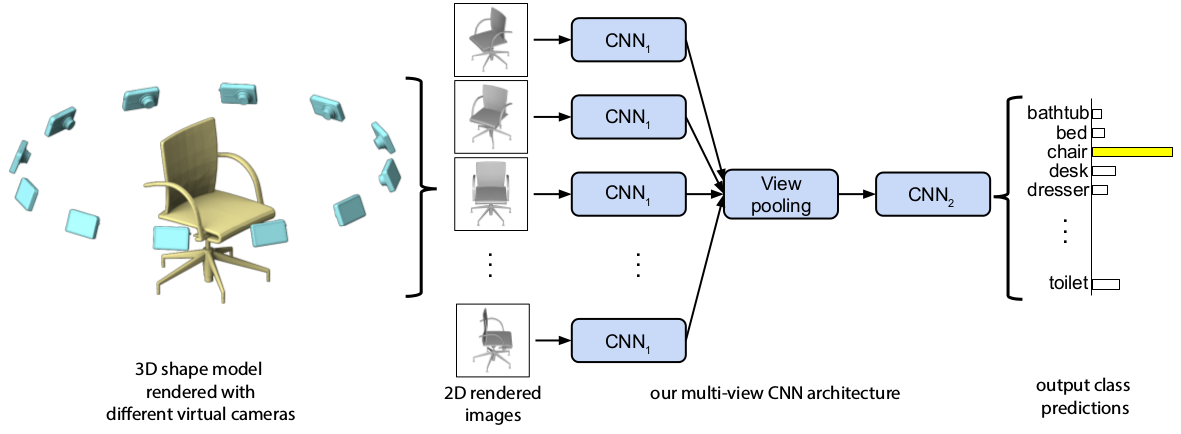
2、项目技术分析
MVCNN 的核心在于其多视图卷积神经网络架构。它利用了不同视角下的图像信息,通过联合处理来捕捉形状的全局特性,而非仅仅依赖单一视点。在训练过程中,网络会学习如何将来自各个视点的特征进行整合,形成对形状的全面理解。此外,为了提高性能,项目还提供了一种学习后的度量方法来进一步优化描述符。
3、项目及技术应用场景
MVCNN 可广泛应用于以下场景:
- 3D对象识别:在机器人领域,它可以用于增强设备对周围环境的理解。
- 虚拟现实与游戏:帮助创建更真实感的交互体验。
- 计算机视觉:在图像检索或物体检测任务中提升性能。
- 工业设计:用于验证产品设计的可视化效果一致性。
4、项目特点
- 多视图融合:通过集成多个视点的特征,MVCNN 提供了更全面的形状表示。
- 可扩展性:兼容多种深度学习框架,易于与其他系统集成。
- 预训练模型:提供预训练模型,可以快速应用到新数据集上。
- 高度自定义:用户可以根据自己的需求调整网络结构、视图数量等参数。
开始使用
安装 MVCNN 非常简单,只需克隆仓库并编译相应的依赖项即可开始探索。项目提供了详细的使用示例,如提取单个形状的描述符,批量处理文件夹中的形状,以及应用预训练的模型进行训练和评估。
如果您在使用过程中有任何问题,参考提供的其他实现或社区资源,这将是一个很好的起点。
让我们一起踏上这段深度学习与形状识别的旅程,发掘更多可能!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











