







dict.get(key, default=None)
2.
http://www.pythonchallenge.com/pc/def/ocr.html
查看源码,就是找一堆码里出现次数最少的字符
import urllib2
def get_challenge(s):
return urllib2.urlopen('http://www.pythonchallenge.com/pc/' + s).read()
src = get_challenge('def/ocr.html')
import re
text = re.compile('<!--((?:[^-]+|-[^-]|--[^>])*)-->', re.S).findall(src)[-1]
counts = {}
for c in text: counts[c] = counts.get(c, 0) + 1
print counts
------------------------------
> {'\n': 1221, '!': 6079, '#': 6115, '%': 6104, '$': 6046, '&': 6043, ')': 6186, '(': 6154, '+': 6066, '*': 6034, '@': 6157, '[': 6108, ']': 6152, '_': 6112, '^': 6030, 'a': 1, 'e': 1, 'i': 1, 'l': 1, 'q': 1, 'u': 1, 't': 1, 'y': 1, '{': 6046, '}': 6105}
------------------------------
print ''.join(re.findall('[a-z]', text))
草泥马
妈的看个正则看了一晚上
分享个网址:
https://jex.im/regulex/#!embed=false&flags=&re=希望大家少走弯路
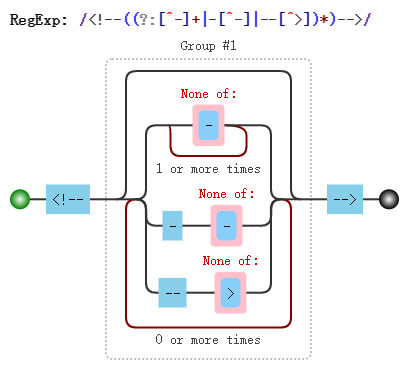
(?:exp) 匹配exp,不捕获匹配的文本
再分享个网址:
http://deerchao.net/tutorials/regex/regex.htm














 789
789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









