







 数据挖掘概念汇总及数据预处理
数据挖掘概念汇总及数据预处理
数据挖掘简介
数据挖掘,顾名思义,就是在大量的数据中发现有用的信息,随着信息技术发展,每天都会产生大量的数据,可以说我们正处于一个大数据的时代。面对如此多的数据,传统的分析方法不再适用,这就需要我们用新的技术工具来从数据中找到隐藏的信息。
数据挖掘的应用相当广泛,比如最“超市出售商品间的关联分析”(数据分析课上必然提到的“啤酒尿布”的例子),“根据历史数据做气候观测”、“生物学生的基因序列分析”等等等等。说到“啤酒尿布”这个例子(虽然后面被证明可能是杜撰的,但不失为一个精彩的事例),在我刚学习数据挖掘的时候,有一个疑问是为什么明明面包牛奶的关联性更强,但是我们从来不去讲面包和牛奶之间的关联分析,而是单单要说啤酒和尿布。其实这恰好说明了数据挖掘本身的意义,发现“隐藏的”,不易被发现的知识。面包和牛奶的搭配是我们的生活常识,如果大家都知道的东西,再去发现也就没有什么意义了,正是这种看似毫不相关实则息息相关的问题才是我们做挖掘的过程中应该关注的。
数据挖掘与数据库技术的发展和成熟时分不开的,其完整名字是数据库中的知识发现(Knowledge discovery in database, KDD),也就是将数据库中的 raw data 经过一系列的加工计算分析,得出有用信息的这个过程。该过程通常用如下几个步骤来描述:
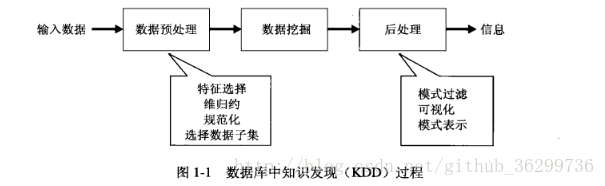
@(图片来源:数据挖掘导论)
数据预处理即将未加工数据转换成适合分析的形式,包括多数据源的数据融合、数据清洗、维规约等等。数据预处理还没有很好的自动化工程化的方法,所以通常会耗费很多时间和精力,且需要加入人为经验的干预。
在数据挖掘的过程中我们也会遇到很多的问题,比如特征值过多导致的维度灾难,静态模型不够灵活,数据中包含的一些特征偏见等等,我们需要不断探索合适的方法来解决这些问题。
数据挖掘的目标
数据挖掘通常有两大目的:
描述 和 预测
描述就是找出数据中潜在的模式/关联,比如我们上面说过的啤酒尿布的例子,而预测是根据其他的属性值来对某一特定属性值来进行预测,例如根据一个顾客的购买历史预测他是否会购买一种新产品等等。
数据挖掘中的基本概念
首先第一个概念就是数据集了,也就是我们拿到的数据。数据集是数据对象的集合。
名字:李雷,性别:男,年龄:21,身高:170;
名字:韩梅梅,性别:女,年龄:23,身高:160;
名字:阿花,性别:女,年龄:20,身高:165;
...
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6560
6560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









