



 本文详细解释了numactl命令如何通过系统调用进行内存绑定和CPU亲和性设置,介绍了内核中相关的函数实现,如sched_setaffinity和set_mempolicy,并探讨了内存分配策略,包括缺省、绑定、交叉和优先。还举例展示了mbind和taskset在实际应用中的用法。
本文详细解释了numactl命令如何通过系统调用进行内存绑定和CPU亲和性设置,介绍了内核中相关的函数实现,如sched_setaffinity和set_mempolicy,并探讨了内存分配策略,包括缺省、绑定、交叉和优先。还举例展示了mbind和taskset在实际应用中的用法。
numactl:
numactl命令的主要功能用来绑核和绑numa内存,比如:
运行如下命令,通过strace来系统调用:
strace numactl --membind=0,1 --cpunodebind=0,1 pwd
输出:
.....
设置进程的亲和性。
sched_setaffinity(0, 512, [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, ...]) = 0
省略
设置内存的分配规则
set_mempolicy(MPOL_BIND, [0x0000000000000003, 000000000000000000, 000000000000000000, 000000000000000000], 257) = 0
....
上面对应了内核中具体的系统调用实现函数:
sched_setaffinity:sched_setaffinity //kernel/sched/core.c
set_mempolicy:do_set_mempolicy //mm/mempolicy.c
int sched_setaffinity(pid_t pid, size_t cpusetsize,
const cpu_set_t *mask);
cpu_set_t:
typedef struct
{
__cpu_mask __bits[__CPU_SETSIZE / __NCPUBITS];
} cpu_set_t;
=>
typedef struct
{
unsigned long int __bits[1024 / sizeof(unsigned long int )* 8]; //默认16个数组
} cpu_set_t;
内核:
typedef struct cpumask { DECLARE_BITMAP(bits, NR_CPUS); } cpumask_t;
long sched_setaffinity(pid_t pid, const struct cpumask *in_mask);
gdb:
(gdb) b do_taskset
Breakpoint 1 at 0x402154: file schedutils/taskset.c, line 118.
(gdb) set args -c 1,2,3 pwd
(gdb) b do_taskset
(gdb) p {cpu_set_t}set
$9 = {__bits = {14, 0 <repeats 15 times>}} //第一个long值为14: 二进制1110 。刚好是1,2,3 这几个cpu
strace打印:
sched_setaffinity(0, 128, [1, 2, 3]) = 0
内存绑定:
long set_mempolicy(int mode, const unsigned long *nodemask,
unsigned long maxnode);
内核:
typedef struct { DECLARE_BITMAP(bits, MAX_NUMNODES); } nodemask_t;
static long do_set_mempolicy(unsigned short mode, unsigned short flags,
nodemask_t *nodes)
//根据bits数量,确定多少long类型数组,内核long 8字节。向上取整。
#define DECLARE_BITMAP(name,bits) \
unsigned long name[BITS_TO_LONGS(bits)]
numactl分配的内存策略,
1. 缺省(default):总是在本地节点分配(分配在当前进程运行的节点上);
2. 绑定(bind):强制分配到指定节点上;
3. 交叉(interleave):在所有节点或者指定的节点上交织分配;
4. 优先(preferred):在指定节点上分配,失败则在其他节点上分配。
numactl 设置内存策略的参数,互相冲突,只能选择一个
[ --interleave nodes ] [ --preferred node ] [ --membind nodes ]
内核也有对应的枚举类型,include/uapi/linux/mempolicy.h
enum {
MPOL_DEFAULT,
MPOL_PREFERRED,
MPOL_BIND,
MPOL_INTERLEAVE,
MPOL_LOCAL,
MPOL_MAX, /* always last member of enum */
};
内核do_set_mempolicy函数:
static long do_set_mempolicy(unsigned short mode, unsigned short flags,
nodemask_t *nodes)
{
struct mempolicy *new, *old;
NODEMASK_SCRATCH(scratch);
int ret;
if (!scratch)
return -ENOMEM;
new = mpol_new(mode, flags, nodes);
if (IS_ERR(new)) {
ret = PTR_ERR(new);
goto out;
}
ret = mpol_set_nodemask(new, nodes, scratch);
if (ret) {
mpol_put(new);
goto out;
}
task_lock(current);
old = current->mempolicy; //设置当面进程的mempolicy
current->mempolicy = new;
if (new && new->mode == MPOL_INTERLEAVE)
current->il_prev = MAX_NUMNODES-1; //interleave模型,记录上一次分配的node节点,在后面分配的时候会看到怎么用的
task_unlock(current);
mpol_put(old);
ret = 0;
out:
NODEMASK_SCRATCH_FREE(scratch);
return ret;
}
get_mempolicy函数使用:
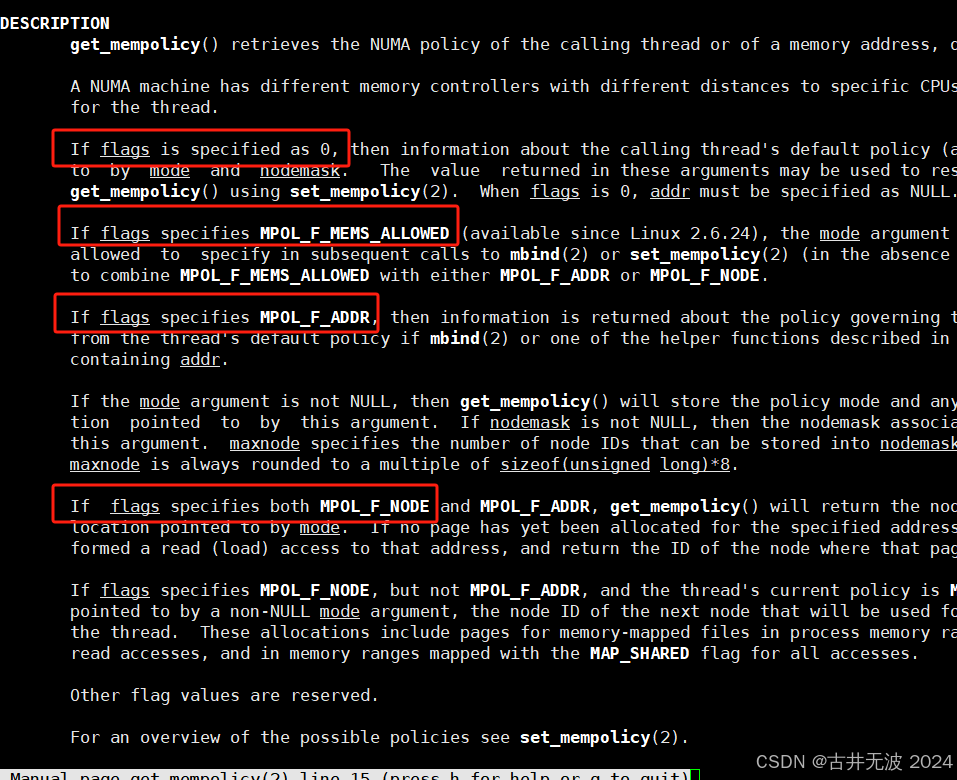
根据参数的不同来获取不同的结果:
flags为NULL 获取进程的task_struct->mempolicy,通常为了获取当前进程的内存mempolicy。
flags为MPOL_F_NODE,获取进程在MPOL_INTERLEAVE模式下,下一个分配内存的node。
flags为MPOL_F_MEMS_ALLOWED获取的是task_struct->mems_allowed,是cgroup限制的。通常是所有的。
参考内核do_set_mempolcy
分配内存的时候根据mempolciy来分配:
先来一张用户用户空间页错误异常:参考资料。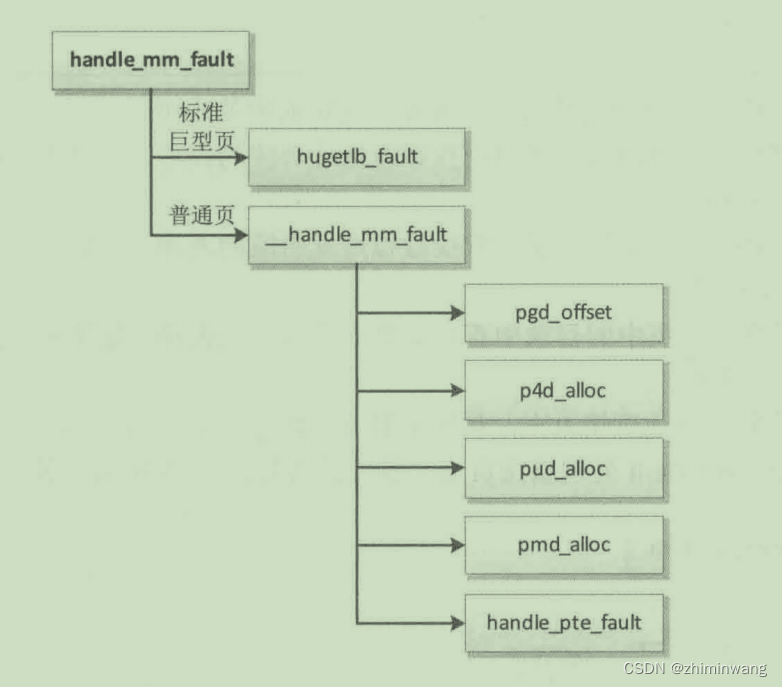
do_anonymous_page的分配物理页:
page = __alloc_pages_nodemask(gfp, order, preferred_nid, nmask); //在nodemask节点分配页表
pol = get_vma_policy(vma, addr); //获取mempolicy,如果没有就是要进程的current->policy
=> alloc_pages_vma
=>alloc_page_vma
=>page = alloc_zeroed_user_highpage_movable(vma, vmf->address); //
=> do_anonymous_page
=> handle_pte_fault
=> __handle_mm_fault
=> handle_mm_fault
=> do_page_fault
=> do_translation_fault
=> do_mem_abort
=> el0_da
=> el0_sync_handler
=> el0_sync
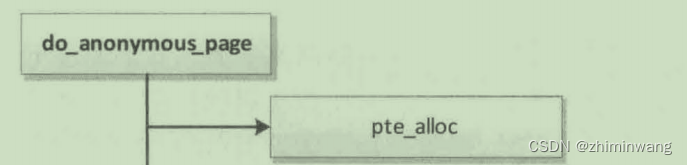
pte_alloc的调用流程:
pte_alloc
__pte_alloc
pte_alloc_one
__pte_alloc_one
alloc_page(gfp);
alloc_pages
alloc_pages_current //mm/mempolicy.c ,根据memopolicy规则,分为alloc_page_interleave和__alloc_pages_nodemask
alloc_page_interleave
__alloc_pages
__alloc_pages_nodemask //最终也是__alloc_pages_nodemask
__alloc_pages_nodemask //mm/alloc_page.c
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);
/*
* No reference counting needed for current->mempolicy
* nor system default_policy
*/
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));
else
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;
}
EXPORT_SYMBOL(alloc_pages_current);
上面根据当前进程的mempolicy的mode来区分,如果是MPOL_INTERLEAVE,也就是在numactl使用--interleave参数。则调用alloc_page_interleave。第三参数intrleave_nodes(pol):
/* Do dynamic interleaving for a process */
static unsigned interleave_nodes(struct mempolicy *policy)
{
unsigned next;
struct task_struct *me = current;
next = next_node_in(me->il_prev, policy->v.nodes); //选出下一个node
if (next < MAX_NUMNODES)
me->il_prev = next; //设置当前使用的node。
return next;
}
static struct page *alloc_page_interleave(gfp_t gfp, unsigned order,
unsigned nid)
{
struct page *page;
page = __alloc_pages(gfp, order, nid);
/* skip NUMA_INTERLEAVE_HIT counter update if numa stats is disabled */
if (!static_branch_likely(&vm_numa_stat_key))
return page;
if (page && page_to_nid(page) == nid) {
preempt_disable();
__inc_numa_state(page_zone(page), NUMA_INTERLEAVE_HIT);
preempt_enable();
}
return page;
}
mbind:
mbind 是 Linux 中的一个系统调用,用于绑定内存页面到指定的 NUMA 节点或 CPU 核心上。mbind 可以用于优化多核系统中的内存访问,提高性能,尤其是在 NUMA(Non-Uniform Memory Access)体系结构下。
SYSCALL_DEFINE6(mbind, unsigned long, start, unsigned long, len,
unsigned long, mode, const unsigned long __user *, nmask,
unsigned long, maxnode, unsigned int, flags)
{
return kernel_mbind(start, len, mode, nmask, maxnode, flags);
}
kernel_mbind
do_mbind
mbind_range
vma_replace_policy //替换vm_area_struct的mempolicy
使用:
page = __alloc_pages_nodemask(gfp, order, preferred_nid, nmask); //在nodemask节点分配页表
pol = get_vma_policy(vma, addr); //获取mempolicy
=> alloc_pages_vma
=>alloc_page_vma
=>page = alloc_zeroed_user_highpage_movable(vma, vmf->address); //
=> do_anonymous_page
=> handle_pte_fault
=> __handle_mm_fault
=> handle_mm_fault
=> do_page_fault
=> do_translation_fault
=> do_mem_abort
=> el0_da
=> el0_sync_handler
=> el0_sync
下面是 mbind 的基本用法和一些相关的参数:
c
#define _GNU_SOURCE
#include <numaif.h>
#include <numa.h>
int mbind(void *addr, unsigned long len, int mode, const unsigned long *nodemask,
unsigned long maxnode, unsigned flags);
参数说明:
addr:指向要操作的内存区域的起始地址。
len:指定要操作的内存区域的长度。
mode:指定操作的模式,常见的有 MPOL_BIND(绑定内存) 和 MPOL_DEFAULT(使用默认策略)。
nodemask:一个位掩码数组,指定可以使用的 NUMA 节点。
maxnode:指定 nodemask 的长度(即节点的总数)。
flags:指定其他标志,通常可以设置为 0。
example1(来自gpt,结果不供参考):
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/mman.h>
#include <numaif.h>
#define SIZE (1024 * 1024 * 1024) // 1 GB
int main(void) {
// 创建一个匿名映射的内存范围
void *addr = mmap(NULL, SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (addr == MAP_FAILED) {
perror("mmap");
exit(1);
}
// 设置内存策略为 MPOL_INTERLEAVE,涉及节点 0 和 1
unsigned long nodemask[2] = {0x3, 0x0}; // 位掩码,表示节点 0 和 1
int mode = MPOL_INTERLEAVE; // 模式
int flags = 0; // 标志
if (mbind(addr, SIZE, mode, nodemask, 2 * 8 * sizeof(unsigned long), flags) == -1) {
perror("mbind");
exit(1);
}
// 写入数据,触发页面分配
char *p = (char *)addr;
for (int i = 0; i < SIZE; i++) {
p[i] = 'a';
}
// 打印每个页面所在的节点 下面的定有问题 ??????
int *status = malloc(SIZE / getpagesize() * sizeof(int));
if (get_mempolicy(NULL, status, SIZE / getpagesize(), addr, MPOL_F_ADDR) == -1) {
perror("get_mempolicy");
exit(1);
}
for (int i = 0; i < SIZE / getpagesize(); i++) {
printf("Page %d is on node %d\n", i, status[i]);
}
// 释放资源
free(status);
munmap(addr, SIZE);
return 0;
}
运行结果如下(部分省略):
Page 0 is on node 0
Page 1 is on node 1
Page 2 is on node 0
Page 3 is on node 1
Page 4 is on node 0
Page 5 is on node 1
Page 6 is on node 0
Page 7 is on node 1
...
Page 262136 is on node 0
Page 262137 is on node 1
Page 262138 is on node 0
Page 262139 is on node 1
Page 262140 is on node 0
Page 262141 is on node 1
Page 262142 is on node 0
Page 262143 is on node 1
example2:
#define _GNU_SOURCE
#include <numaif.h>
#include <numa.h>
#include <stdio.h>
int main() {
// 分配一块内存
size_t size = 1024 * 1024 * 100; // 100 MB
void *mem = numa_alloc_onnode(size, 0); //numactl提供的接口。内部也调用mbind
// 获取当前系统的 NUMA 节点数量
int numNodes = numa_num_configured_nodes();
// 创建节点掩码,这里使用第一个 NUMA 节点
unsigned long nodemask = 1 << 0;
// 绑定内存到指定节点
if (mbind(mem, size, MPOL_BIND, &nodemask, numNodes, 0) == 0) {
printf("Memory bound to NUMA node 0 successfully.\n");
} else {
perror("mbind");
return 1;
}
// 使用绑定的内存进行其他操作
// 释放内存
numa_free(mem, size);
return 0;
}
请注意,使用 mbind 需要确保系统支持 NUMA,并且在编译时需要链接 numa 库。在上面的例子中,使用 numa_alloc_onnode 分配内存,然后使用 mbind 将其绑定到第一个 NUMA 节点。如果 mbind 成功,可以在这块内存上执行其他操作。最后,使用 numa_free 释放内存。
taskset:
参考util-linux源码。


















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











