







文章目录
1.定义
WITH RECURSIVE是 SQL 中的一种高级查询结构,用于执行递归查询。递归查询是一种特殊的查询方式,它能够通过反复应用一个规则或算法,逐步构建出一个结果集,常用于解决层次化或树状数据结构的遍历问题。
WITH RECURSIVE 结构通常包含以下几个关键部分:
1. CTE(Common Table Expression,公用表表达式):
语法:
WITH RECURSIVE cte_name (column_list) AS (
SELECT
initial_query_result
UNION [ALL]
SELECT
recursive_query
FROM
cte_name
WHERE
condition
)SELECT
*
FROM
cte_name;
WITH关键字引入一个或多个CTE。RECURSIVE关键字表明至少有一个CTE是递归的。CTE名称(cte_name)用于标识递归查询的临时结果集。- 列名列表(
column_list)定义了CTE结果集中包含的列及其名称。 - 初始查询(
initial_query_result)提供递归过程的起点,即第一次迭代时使用的数据。 - 递归部分(递归子查询)定义了如何将前一次迭代的结果作为输入,计算出下一次迭代的数据。
recursive_query:表示递归查询语句,应当与column_list中的列名对应。condition:表示递归查询的终止条件,需要使用cte_name中的列进行判断。SELECT * FROM cte_name:表示最终返回的查询结果集,可以通过cte_name查询表中的列名进行指定。
2.递归查询的结构
递归查询通常由两部分构成:初始化查询(非递归部分)和递归子查询(递归部分)。
- 初始化查询:定义递归开始时的基础数据集,通常是与递归逻辑相关的最顶层数据或边界条件。
- 递归子查询:定义如何根据前一次迭代的结果生成下一次迭代的数据。递归子查询通常包含对自身
CTE名称的引用,以递归地应用相同的操作。
3.连接操作符:
递归查询的初始化查询和递归子查询通常通过 UNION 或 UNION ALL 连接起来,形成一个完整的递归查询表达式。
UNION 会去除结果集中的重复行,而 UNION ALL 不会去除重复,根据实际需求选择合适的连接操作符。
4.终止条件
递归查询必须有一个明确的终止条件,否则会无限循环下去。终止条件通常隐含在递归子查询的 WHERE 子句或其他逻辑中,当满足特定条件时,不再产生新的结果。
2.示例1
假设有一个员工表 employees,其中包含 id(员工ID)、name(员工姓名)、manager_id(上级经理ID),结构如下:
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
manager_id INT,
FOREIGN KEY (manager_id) REFERENCES employees(id)
);
现在我们想查询出一个员工及其所有下属的完整层级关系。可以使用 WITH RECURSIVE 构建如下查询:
WITH RECURSIVE employee_hierarchy AS (
-- 初始化查询:选取根节点(顶级经理,没有上级经理)
SELECT id, name, manager_id, 1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 递归子查询:根据上一层级结果,查找下一级员工
SELECT e.id, e.name, e.manager_id, eh.level + 1
FROM employees e
JOIN employee_hierarchy eh ON e.manager_id = eh.id
)
SELECT * FROM employee_hierarchy;
在这个例子中:
employee_hierarchy是CTE的名称。- 列名列表为 id, name, manager_id, level。
初始化查询选择了所有没有上级经理(manager_id IS NULL)的员工作为递归的起点。递归子查询通过JOIN语句将employee_hierarchy与employees表连接起来,根据manager_id匹配关系找到下一层级的员工。同时,level列每次递归时增加 1,表示员工在层级结构中的深度。- 最后,通过
SELECT * FROM employee_hierarchy查询出最终的递归结果集。
总结起来,WITH RECURSIVE 的用法主要包括以下几个步骤:
- 定义
CTE,指定RECURSIVE关键字。 - 编写
初始化查询和递归子查询,通过UNION或UNION ALL连接。 - 确保
递归子查询中包含终止条件,以避免无限递归。 - 在主查询中引用
CTE名称,获取递归查询的结果。
这种结构适用于解决各种层次化数据的遍历问题,如组织架构、目录结构、路径搜索、数列生成等。通过递归查询,可以简化复杂查询逻辑,提高代码可读性,并且在某些情况下比使用循环或其他编程语言结构更高效。
EXPLAIN
1.执行 EXPLAIN 命令:
将 WITH RECURSIVE 查询语句包裹在 EXPLAIN 关键字之后,运行该命令以获取查询执行计划。由于 WITH RECURSIVE 查询包含两个部分(初始化查询和递归子查询),您需要分别分析这两个部分。
EXPLAIN WITH RECURSIVE employee_hierarchy AS (
SELECT id, name, manager_id, 1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name, e.manager_id, eh.level + 1
FROM employees e
JOIN employee_hierarchy eh ON e.manager_id = eh.id
)
SELECT * FROM employee_hierarchy;
然而,MySQL 直接对包含 WITH 子句的查询使用EXPLAIN会有语法错误。为了分析递归查询,可以将递归查询转换为临时表(或者视图),然后对临时表进行 EXPLAIN 分析:
CREATE TEMPORARY TABLE temp_employee_hierarchy AS
WITH RECURSIVE employee_hierarchy AS (
SELECT id, name, manager_id, 1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name, e.manager_id, eh.level + 1
FROM employees e
JOIN employee_hierarchy eh ON e.manager_id = eh.id
)
SELECT * FROM employee_hierarchy;
EXPLAIN SELECT * FROM temp_employee_hierarchy;
请注意,这种方法仅能分析递归查询的最终结果集,无法直接分析递归过程中的各个步骤。若要详细了解递归过程中的索引使用情况,可能需要手动分解递归查询并分别进行 EXPLAIN 分析。
2.解读 EXPLAIN 输出:
EXPLAIN 命令的输出会显示查询的执行计划,重点关注以下几个关键列:
type:表示访问类型,从最好到最差的类型为system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>ALL。理想情况下,应至少达到range级别,最好达到ref级别。如果为ALL,表示全表扫描,没有使用索引。key:显示实际使用的键或索引。如果为NULL,表示未使用任何索引,需要优化。extra:包含额外的信息,如Using index表示覆盖索引(无需回表),Using where表示在索引检索后还需要过滤,Using filesort和Using temporary表示需要额外排序或创建临时表,这些都是不太友好的值
对于上述示例,主要关注 employees 表的查询是否使用了索引,特别是 manager_id 字段上的索引。如果表上有适当的索引(如 manager_id 上的单列索引或复合索引),期望在 EXPLAIN 输出中看到 type 列显示为 ref 或更好的访问类型,并且 key 列显示实际使用的索引名。
3.优化建议:
如果发现查询未有效使用索引,可以尝试以下优化措施:
-
检查索引:确认
employees表上是否存在针对manager_id字段的索引。如果没有,应创建相应的索引。 -
调整查询:确保查询条件和连接条件能够充分利用现有索引。例如,确保
WHERE子句和JOIN条件中涉及的列都已建立索引。 -
分析数据分布:如果表数据分布不均匀,即使存在索引,也可能导致查询优化器选择全表扫描。在这种情况下,可能需要重新评估索引设计或调整查询语句。
-
调整查询:确保查询条件和连接条件能够充分利用现有索引。例如,确保
WHERE子句和JOIN条件中涉及的列都已建立索引。 -
分析数据分布:如果表数据分布不均匀,即使存在索引,也可能导致查询优化器选择全表扫描。在这种情况下,可能需要重新评估索引设计或调整查询语句。
综上所述,分析 WITH RECURSIVE 查询是否走索引,需通过 EXPLAIN 命令获取查询执行计划,并关注 type、key 和 extra 列。根据输出结果判断索引使用情况,并据此进行相应的优化。由于直接对递归查询使用 EXPLAIN 有局限性,可能需要采用变通方法(如创建临时表)或手动分解查询进行分析。
3.示例2
1.准备工作
① 首先准备一张递归表:这里使用用户邀请记录表,A可以邀请B,B可以邀请C,C可以…依次随意邀请。

--推广记录表
CREATE TABLE `sz_promotion_tree` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_id` bigint DEFAULT NULL COMMENT '用户id',
`parent_id` bigint DEFAULT NULL COMMENT '推荐者id',
`create_time` datetime DEFAULT NULL COMMENT '推广时间',
PRIMARY KEY (`id`),
KEY `user_id` (`user_id`)
USING BTREE,
KEY `parent_id` (`parent_id`)
USING BTREE) ENGINE = InnoDB AUTO_INCREMENT = 2 DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '推广记录表';
② 随便准备一张用户表 比如
--用户表
CREATE TABLE `sz_user` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`nickname` varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '昵称',
PRIMARY KEY (`id`)) ENGINE = InnoDB AUTO_INCREMENT = 111 DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户表';
③ 造数据
INSERT
INTO
sz_user(id,
nickname)
VALUES (99,
'S');
INSERT
INTO
sz_user(id,
nickname)
VALUES (100,
'A');
INSERT
INTO
sz_user(id,
nickname)
VALUES (101,
'B');
INSERT
INTO
sz_user(id,
nickname)
VALUES (102,
'C');
INSERT
INTO
sz_user(id,
nickname)
VALUES (103,
'D');
INSERT
INTO
sz_user(id,
nickname)
VALUES (104,
'E');
INSERT
INTO
sz_user(id,
nickname)
VALUES (105,
'F');
INSERT
INTO
sz_user(id,
nickname)
VALUES (106,
'G');
INSERT
INTO
sz_user(id,
nickname)
VALUES (107,
'H');
INSERT
INTO
sz_user(id,
nickname)
VALUES (108,
'I');
INSERT
INTO
sz_user(id,
nickname)
VALUES (109,
'J');
--------------------------------
INSERT
INTO
sz_promotion_tree(id,
user_id,
parent_id,
create_time)
VALUES (1,
100,
99,
NULL);
INSERT
INTO
sz_promotion_tree(id,
user_id,
parent_id,
create_time)
VALUES (2,
101,
100,
NULL);
INSERT
INTO
sz_promotion_tree(id,
user_id,
parent_id,
create_time)
VALUES (3,
102,
100,
NULL);
INSERT
INTO
sz_promotion_tree(id,
user_id,
parent_id,
create_time)
VALUES (4,
103,
101,
NULL);
INSERT
INTO
sz_promotion_tree(id,
user_id,
parent_id,
create_time)
VALUES (5,
104,
101,
NULL);
INSERT
INTO
sz_promotion_tree(id,
user_id,
parent_id,
create_time)
VALUES (6,
105,
102,
NULL);
INSERT
INTO
sz_promotion_tree(id,
user_id,
parent_id,
create_time)
VALUES (7,
106,
102,
NULL);
INSERT
INTO
sz_promotion_tree(id,
user_id,
parent_id,
create_time)
VALUES (8,
107,
103,
NULL);
INSERT
INTO
sz_promotion_tree(id,
user_id,
parent_id,
create_time)
VALUES (9,
108,
103,
NULL);
INSERT
INTO
sz_promotion_tree(id,
user_id,
parent_id,
create_time)
VALUES (10,
109,
104,
NULL);
造出来一份这样结构的关系:
- S邀请了A,
- A邀请了B、C,
- B邀请了D、E,
- D邀请了H、I,
- E邀请了J
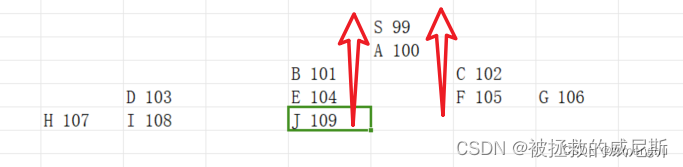
2. 向上递归
比如现在查询 J 109 的所有上级,并且还要查出,这些上级和 J 109 的关系是几级
WITH RECURSIVE promotion_tree AS (
SELECT
id,
user_id,
parent_id,
1 AS level
FROM
sz_promotion_tree
WHERE
user_id = 109
UNION ALL
SELECT
pt.id,
pt.user_id,
pt.parent_id,
pt2.level + 1
FROM
sz_promotion_tree pt
JOIN promotion_tree pt2 ON
pt.user_id = pt2.parent_id
WHERE
pt.parent_id IS NOT NULL
)SELECT
*
FROM promotion_tree;
查询结果:
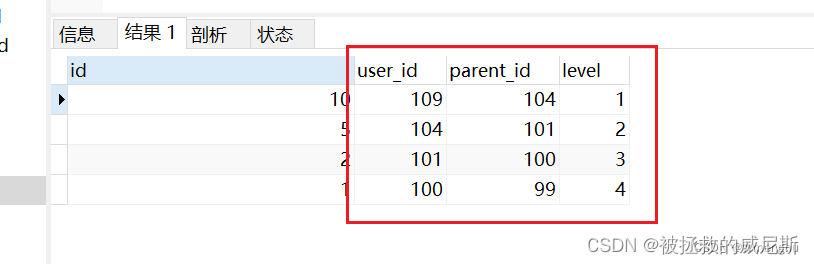
解析:
- ① 首先,使用
WITH RECURSIVE关键字声明了一个递归查询公共表表达式(CTE),命名为promotion_tree。 - ②在初始查询中,从
sz_promotion_tree表中选择符合条件user_id = 109的记录,并为它们分配一个初始级别 1。这些记录作为递归查询的起始点。 - ③ 使用
UNION ALL运算符,将初始查询的结果与递归查询的结果连接起来。 - ④ 在递归查询中,选择
sz_promotion_tree表中的记录,连接到前一级的递归结果(promotion_tree),并通过条件pt.user_id = pt2.parent_id进行连接。这样可以构建一个向上层级递归的结构。 - ⑤ 在递归查询的每一次迭代中,将前一级的层级
pt2.level加上 1,并将结果作为当前级别 level。 - ⑥ 递归查询继续迭代,直到不再满足条件
pt.parent_id IS NOT NULL,即没有上级用户时停止递归。 - ⑦ 最后,从递归查询公共表表达式
promotion_tree中选择所有列,并返回结果。
3.向下递归
如果再加一张消费记录表,每个人在平台的消费都会给记录到消费记录表中,比如A,A下面有B、C,A邀请的第一级有几个人,就算几个分支,现在需要查询出A下面有多少个分支,并且,每个分支的消费额(比如B分支,包含B和B的所有子节点)有多少。
准备数据:给刚才的A-I,每人插入一条1w的购物记录
CREATE TABLE `sz_order` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_id` bigint DEFAULT NULL COMMENT '用户id',
`recharge_amount` decimal(10,
2) DEFAULT NULL COMMENT '花费金额',
PRIMARY KEY (`id`)) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '购买记录';
INSERT
INTO
sz_order(id,
user_id,
recharge_amount)
VALUES (8,
99,
10000);
INSERT
INTO
sz_order(id,
user_id,
recharge_amount)
VALUES (9,
100,
10000);
INSERT
INTO
sz_order(id,
user_id,
recharge_amount)
VALUES (10,
101,
10000);
INSERT
INTO
sz_order(id,
user_id,
recharge_amount)
VALUES (11,
102,
10000);
INSERT
INTO
sz_order(id,
user_id,
recharge_amount)
VALUES (12,
103,
10000);
INSERT
INTO
sz_order(id,
user_id,
recharge_amount)
VALUES (13,
104,
10000);
INSERT
INTO
sz_order(id,
user_id,
recharge_amount)
VALUES (14,
105,
10000);
INSERT
INTO
sz_order(id,
user_id,
recharge_amount)
VALUES (15,
106,
10000);
INSERT
INTO
sz_order(id,
user_id,
recharge_amount)
VALUES (16,
107,
10000);
INSERT
INTO
sz_order(id,
user_id,
recharge_amount)
VALUES (17,
108,
10000);
INSERT
INTO
sz_order(id,
user_id,
recharge_amount)
VALUES (18,
109,
10000);
解决:拿A100举例,他下面俩链路,B和C,分别对应6w和3w
WITH RECURSIVE promotion_tree AS (
SELECT
id,
user_id,
parent_id,
CAST(user_id AS CHAR(200)) AS chain
FROM
sz_promotion_tree
WHERE
parent_id = (
SELECT
user_id
FROM
sz_promotion_tree
WHERE
user_id = 100)
UNION ALL
SELECT
pt.id,
pt.user_id,
pt.parent_id,
CONCAT(pt2.chain, '->', pt.user_id)
FROM
sz_promotion_tree pt
JOIN promotion_tree pt2 ON
pt.parent_id = pt2.user_id),
chain_summary AS (
SELECT
pt.chain,
SUM(so.recharge_amount) AS total_amount
FROM
promotion_tree pt
LEFT JOIN sz_order so ON
pt.user_id = so.user_id
GROUP BY
pt.chain
)SELECT
pt.user_id,
sum(cs.total_amount) as total_amountFROM promotion_tree ptleft
JOIN chain_summary cs ON
cs.chain LIKE CONCAT(pt.chain, '%')
WHERE pt.parent_id = (
SELECT
user_id
FROM
sz_promotion_tree
WHERE
user_id = 100)
group by pt.user_id;
结果:
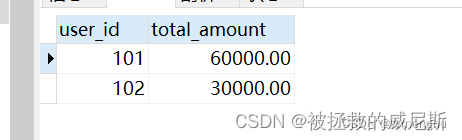
分析:
第一个递归的临时表promotion_tree结果:
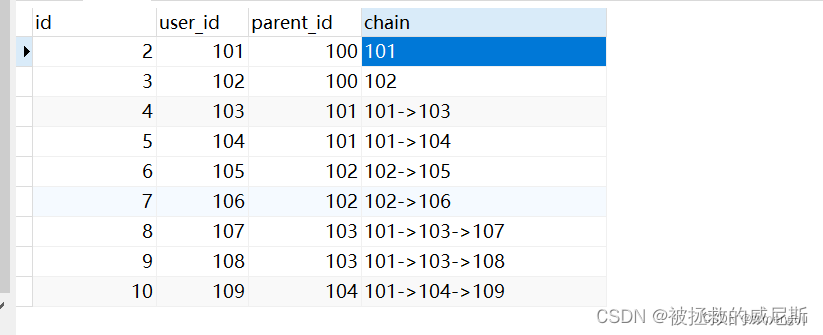
第二个临时表chain_summary结果:
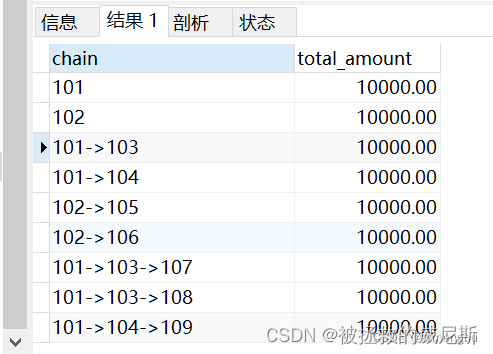
这两将两个表 使用关联查询,用chain 进行左模糊匹配来确定下级有哪些,最后再通过 user_id限定和分组,即可查询每个链路的金额。
4.注意事项
-
1、递归的层数应该尽可能的少,过多的递归层数可能导致查询效率低下或者程序崩溃。
-
2、MySQL
with Recursive功能在MySQL 8.0版本中才被正式引入,使用该功能建议使用该版本或者以上版本。 -
3、使用时需要考虑数据量的大小,如果数据量过大可能会影响递归查询的效率。
5.总结
MySQL with Recursive是一种基于递归思想的MySQL查询方式,可以实现对数据的递归查询和处理,应用广泛。在使用时需要注意递归的层数和数据量大小等因素。通过学习本文,相信大家已经对MySQL with Recursive有了深入的理解,并能够熟练运用该功能。















 3183
3183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









