






 本文介绍了YOLO目标检测算法,包括其核心理念、整体架构流程(数据集收集、标注、整理和模型训练),以及实验结果和优化策略。YOLO以其高效实时性和准确性在安防监控、自动驾驶等领域展现出色性能。
本文介绍了YOLO目标检测算法,包括其核心理念、整体架构流程(数据集收集、标注、整理和模型训练),以及实验结果和优化策略。YOLO以其高效实时性和准确性在安防监控、自动驾驶等领域展现出色性能。
概要
YOLO(You Only Look Once)是一种在目标检测领域引领潮流的深度学习算法。其核心理念在于将目标检测任务转化为一次性的回归问题,从而大幅提升了检测速度并保证了准确性。通过训练一个卷积神经网络,YOLO能够在一次前向传播中直接预测出图像中所有目标的位置和类别,无需进行多次滑动窗口或候选区域生成等操作。这种简洁而高效的特性使得YOLO在实时性要求较高的应用场景中表现出色,如安防监控、自动驾驶等领域。同时,随着YOLO系列算法的不断演进,其在检测精度和性能上也不断得到优化和提升。简而言之,YOLO以其出色的实时性和准确性,成为了目标检测领域的一项重要技术突破。
整体架构流程
一、数据集收集
- 公开数据集:从互联网上获取公开的目标检测数据集,如VOC、COCO等。这些数据集通常包含大量的标注图像和对应的标签信息,可以直接用于训练和测试目标检测模型。
- 自定义数据集:如果公开数据集不满足需求,可以收集自定义数据集。通过搜索引擎、社交媒体、专业网站等途径,收集与目标检测任务相关的图像。
二、数据标注
标注图像是目标检测任务中的关键步骤,它涉及到为图像中的目标物体添加标签和边界框。这里介绍使用LabelImg进行标注的方法:
- 安装LabelImg:
- 打开命令提示符窗口(Win+R,输入“cmd”)。
- 使用pip安装LabelImg。在命令提示符中输入以下命令:
pip install labelimg。 - 安装完成后,可以在命令行中输入
labelimg来启动标注工具。
- 使用LabelImg进行标注:
- 打开LabelImg软件,选择“Open Dir”加载待标注的图像文件夹。
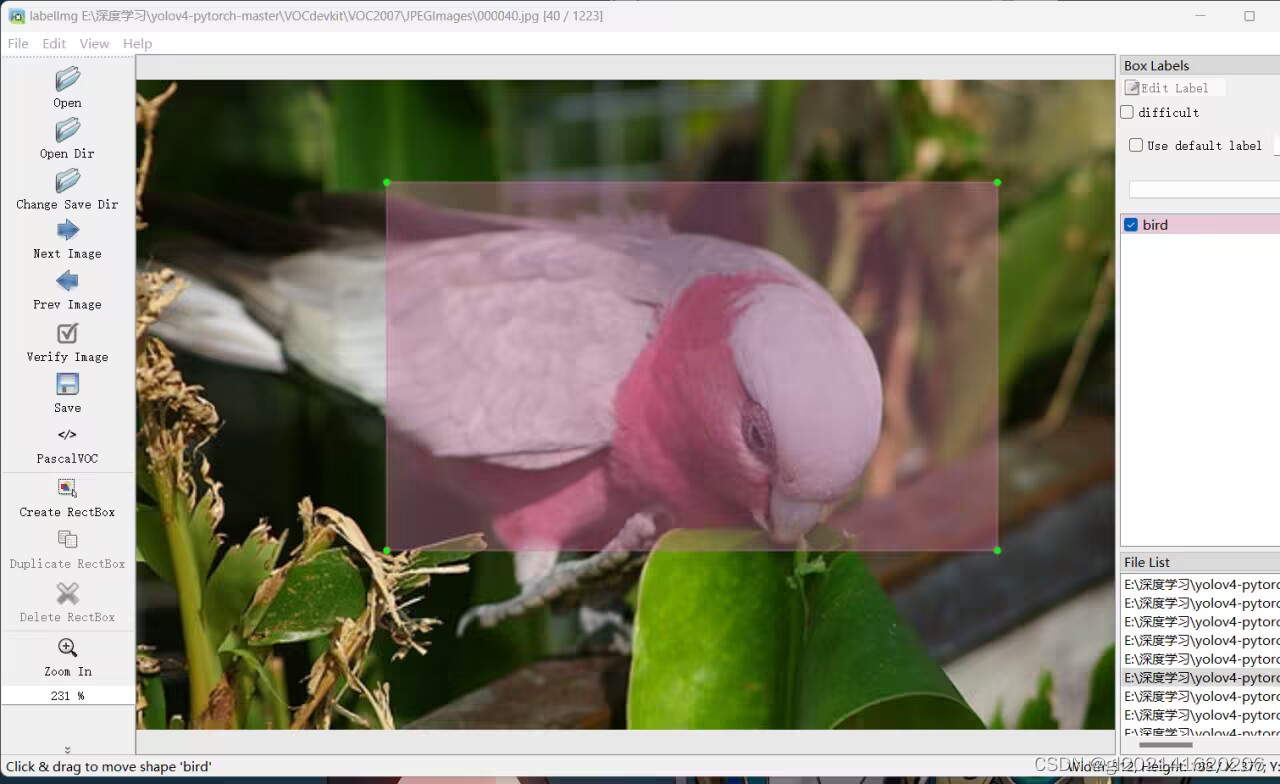
- 在界面中,使用鼠标绘制目标物体的边界框,并选择相应的标签。
- 标注完成后,保存标签信息。LabelImg会自动生成与图像对应的XML文件,其中包含了边界框的坐标和标签信息。
三、数据集整理
- 整理标注文件:将生成的XML文件整理到相应的文件夹中,确保每个图像文件与其对应的XML文件在同一目录下,且文件名相同。
- 划分数据集:将整理好的数据集划分为训练集、验证集和测试集。通常,训练集用于训练模型,验证集用于调整超参数和选择最佳模型,测试集用于评估模型的性能。
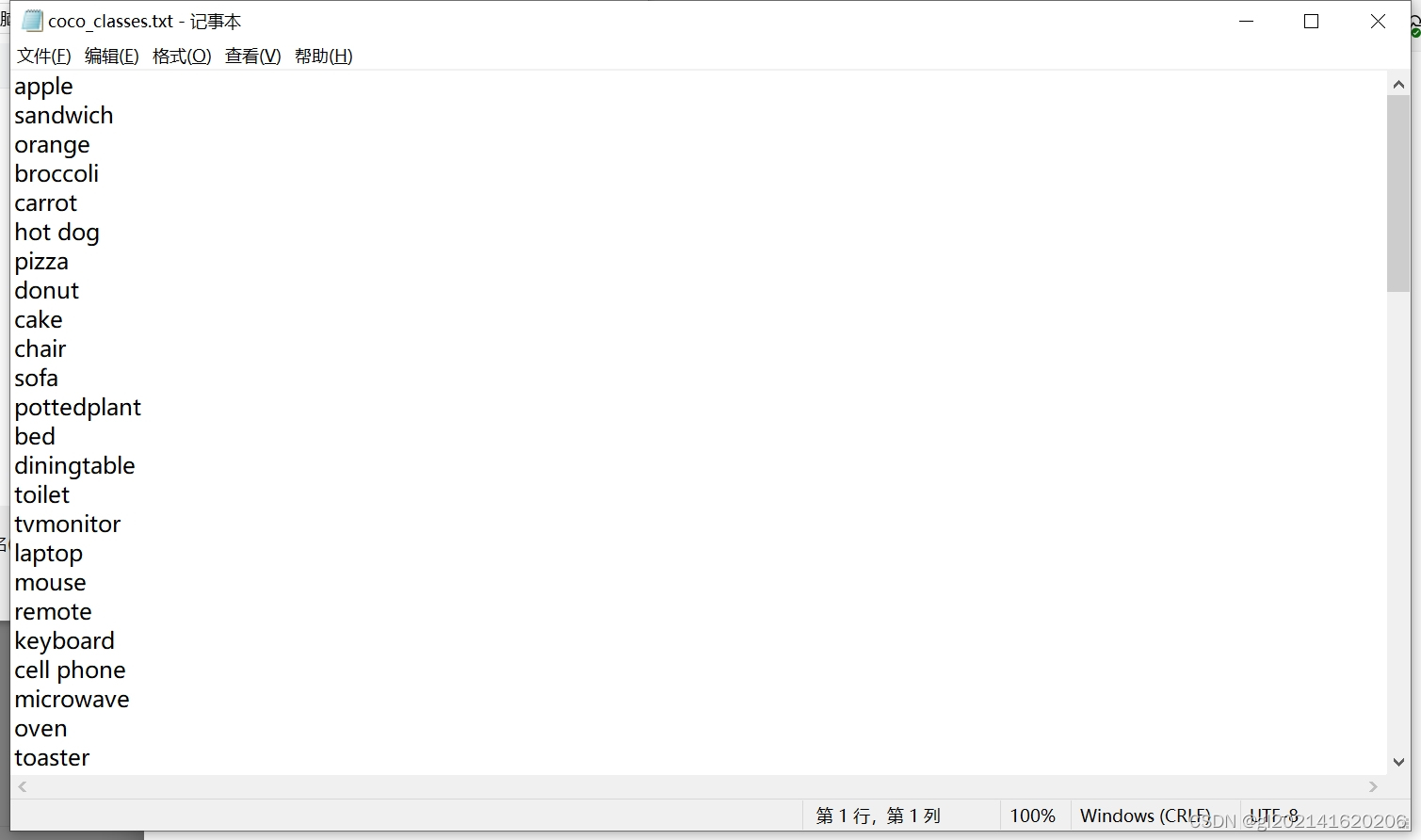
- 创建标签文件:如果数据集包含多个类别,需要创建一个标签文件(如classes.txt),列出所有类别的名称,以便在训练和测试模型时使用。
模型训练与优化
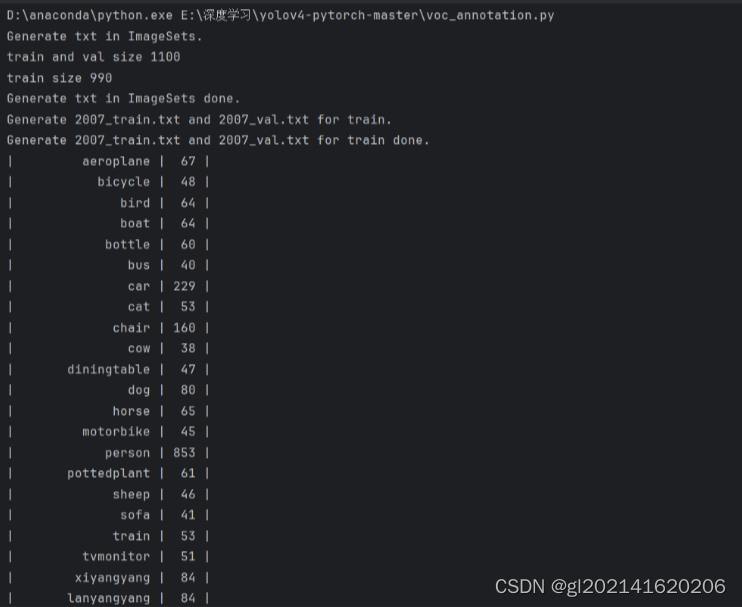
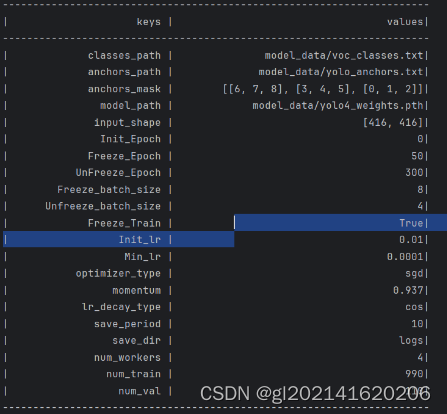
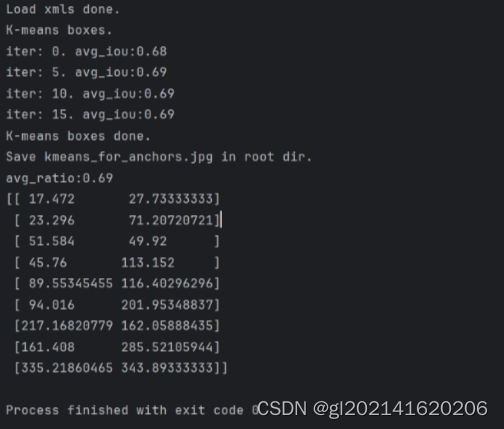
实验结果
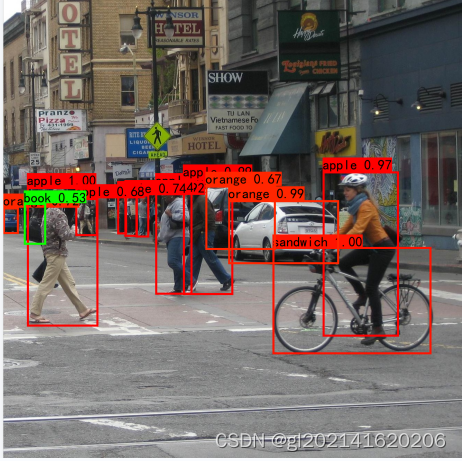
小结
YOLO目标检测项目实验小结
在本实验中,我们成功地应用了YOLO算法进行目标检测任务,并取得了一定的成果。通过这一项目,我们深入了解了YOLO算法的原理、实现过程以及优化方法,并在实践中积累了宝贵的经验。
首先,在数据准备阶段,我们收集并整理了标注好的图像和对应的标签信息,形成了适合YOLO算法训练的数据集。这一步骤虽然繁琐,但对于后续模型的训练和性能至关重要。
接下来,我们进行了模型的训练和优化。在训练过程中,我们根据数据集的特点和任务需求,选择了合适的网络结构和参数设置。通过调整学习率、优化算法等超参数,我们逐步提升了模型的性能。同时,我们还采用了数据增强技术,增加了模型的泛化能力。
在优化方面,我们尝试了多种方法,如模型剪枝、量化等,以减小模型大小并提高推理速度。这些优化措施在一定程度上提高了模型的实时性,使其更适用于实际应用场景。
通过实验,我们验证了YOLO算法在目标检测任务中的有效性。模型在测试集上展现出了较高的准确率和实时性,能够满足大多数应用场景的需求。同时,我们也发现了一些需要改进的地方,如对于某些特定类别的检测效果还有待提升。
综上所述,本实验成功地将YOLO算法应用于目标检测任务,并取得了一定的成果。通过这一项目,我们加深了对目标检测技术的理解,并积累了宝贵的实践经验。未来,我们将继续探索更多的优化方法和技术,以提高模型的性能和泛化能力,为实际应用场景提供更准确、更快速的目标检测服务。

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









