







Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization 阅读笔记
这是网络可视化的第三篇,其余两篇分别是:
①《Visualizing and Understanding Convolutional Networks》阅读笔记-网络可视化NO.1
②《Learning Deep Features for Discriminative Localization》阅读笔记-网络可视化NO.2
欢迎大家批评指正,留下宝贵意见
- 综述:
1)paper中提出了一种新的可视化CNN的方法-Gradient-weighted Class Activation Mapping (Grad-CAM),可以说是CAM的升级版
2)Grad-CAM可适用于任何网络结构,省去了修改网络结构并训练的烦恼,一定程度上是对CAM的泛化
3)使用此种结构,可以应用到以下几个问题中:
3.1)之前的CAM必须对包含多层的FC进行修改(使用GAP进行替换),而Grad-CAM则不必修改网络,从而避免了一些麻烦
3.2)可用于结构化输出,such as captioning(这一块还不是很了解)
3.3)可用于视觉问题解答或者增强学习中
4)有关CAM的介绍,可以参阅《Learning Deep Features for Discriminative Localization》这篇论文的阅读笔记 - 对于网络可视化,我们可以采用两种方式:
1)deconvnet(反卷积)
2)guided-backpropagation(导向反向传播)
这两种方式在一定程度上帮助我们理解在CNN中
反向传播(backpropagation)/反卷积(deconvnet)/导向反向传播(guided-backpropagation)这三者究竟有什么区别???
反卷积和导向反向传播的基础是反向传播,就是对梯度进行求导,然后更新我们的参数,就是学习的过程,具体见paper,论文中有一张图十分清楚的对比了正向传播/反向传播/反卷积/导向反向传播,4者不同之处主要体现在经过ReLU时对梯度的选择性,见下图:
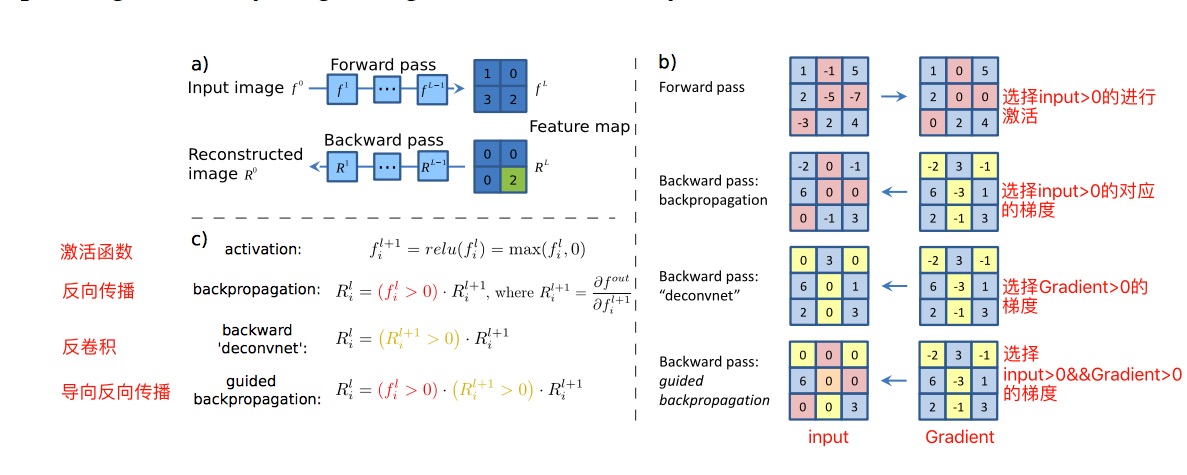
注:图中粗略解释了几者的区别,虽说区别并不大,只是经过ReLU时对梯度的取舍方式不同,但这微小的改变却使得可视化的效果大有不同 - paper中举了一个小demo,使用Grad-CAM的效果如下:

注:这样的结果十分符合我们人眼的观测效果,当我们说一张图中有一条狗狗的时候,也主要依靠狗狗的头部进行判别,猫咪也是如此。 - 实现方法:
1)在CAM中,我们根据最后一层的FC学到的权重作为对应feature map的权重,而后upsampling到原像素空间,看起来利索应当,但当我们在最后一次适用conv之后,得到对应的feature map,之后多次使用FC,我们如何计算feature map对应的权重呢?
这里有一个小问题,我们为什么使用conv阶段最后一次得到的feature map呢?因为最后一次conv得到的feature map是前面多次conv+ReLU+pooling的结果,具有最强的空间信息和语义信息,随后的FC和softmax所提取的信息已经很难理解,所以我们若想实现CNN的可视化,必须好好利用最后一次conv得到的feature map。
下面开始我们的计算过程:
> 接下来我们言归正传,如何计算我们经过FC之后的feature map权重呢?计算公式如下: α k c = 1 Z ∑ i ∈ w ∑ j ∈ h ∂ y c ∂ A i j k \alpha_k^c=\frac{1}{Z}\sum\limits_{i∈w}\sum\limits_{j∈h}\frac{\partial y^c}{\partial A_{ij}^k} αkc=Z1i∈w∑j∈h∑∂Aijk∂yc
其中 α k c \alpha_k^c αkc代表针对类C,第k个feature map的权重, Z Z Z代表feature map的大小, w , h w,h w,h分别代表feature map的宽度和高度, y c y^c yc代表未经过softmax之前时类C的得分, A i j k A_{ij}^k Aijk代表第k个feature map中位置(i,j)的激活值。
> 由此我们得到了类C的Grad-CAM,如下: L G r a d − C A M c = R e L U ( α k c ∗ A k ) L_{Grad-CAM}^c=ReLU(\alpha_k^c * A^k) LGrad−CAMc=ReLU(αkc∗Ak)
此处我们为何进行ReLU运算呢?因为在我们的Grad-CAM中,我们只关注那些对预测结果起到positive influence on the class,倘若出现了negative则直接将其过滤掉。由此我们得到了类C的得分,如下: S c = ∑ k ∈ K α k c ∗ 1 Z ∑ i ∈ w ∑ j ∈ h A i , j k S_c=\sum\limits_{k∈K}\alpha_k^c * \frac{1}{Z}\sum\limits_{i∈w}\sum\limits_{j∈h}A_{i,j}^k Sc=k∈K∑αkc∗Z1i∈w∑j∈h∑Ai,jk
其中$\alpha_k^c 代 表 第 k 个 f e a t u r e m a p 对 类 C 的 权 重 , 代表第k个feature map对类C的权重, 代表第k个featuremap对类C的权重,\sum\limits_{i∈w}\sum\limits_{j∈h}A_{i,j}^k$代表第k个feature map
整体结构如下所示:
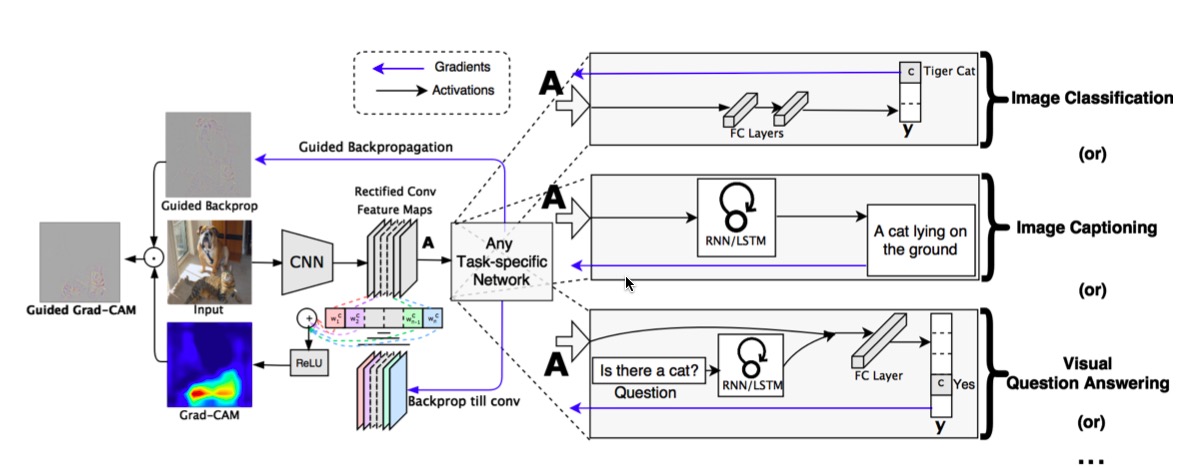
注:paper中还强调Grad-CAM可视化方法不仅仅可用于一般的图像分类网络的可视化、输出结构化网络的可视化还可用于视觉问答网络的可视化等等
- Guided Grad-CAM(导向反向传播和Grad-CAM的结合)
1)问题:虽然Grad-CAM可以很好的类别判别能力,也可以将相关区域定位出来,但是其不具备像素空间梯度可视化(比如导向反向传播和反卷积这种细粒度重要性可视化)的方法
2)解决问题:
2.1)首先对图像使用插值法进行上采样
2.2)然后将导向反向传播和Grad-CAM结合起来,实现可视化 - 实验
1)首先进行了定位实验
我们首先在ImageNet数据集上进行预测,然后获取对应的Grad-CAM,选择最大激活值得15%作为threshold,画出bounding box,结果如下:

注:paper中解释到,在物体定位实验中,Grad-CAM取得了较好的实验效果;但在分类实验中,由于修改了网络结构,致使分类性能下降了2.98%
2)之外还做了一些其他实验,有时间了会补充上,再和大家一起交流
作者:gengmiao 时间:2018.02.19,原创文章,转载请保留原文地址、作者等信息















 2975
2975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









