







目 录
0 引 言
Oozie在执行过程中如果有多个fork产生并行任务的时候,这时会占用很多内存,如果机器的内存不够则会产生调度阻塞。或者是同时提交了多个Oozie任务,也会产生调度阻塞。本文针对上述问题,首先分析研究了Oozie的工作原理及Yarn的运行机制,并基于这两种机制原理的基础上,定位问题所在,实现了上述问题的优化,给出了具体的解决方案,最后对结果进行了验证。
1 Oozie的任务调度原理
1.1 Oozie总体架构
Oozie的总体架构图如下图所示:
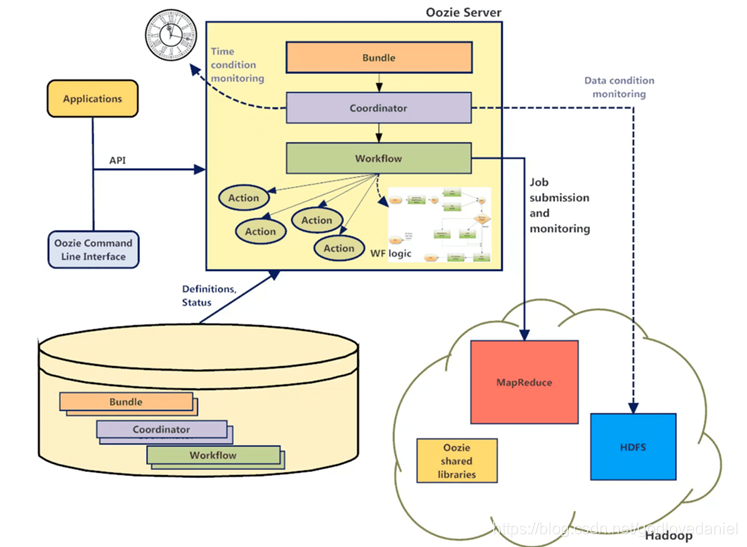
由架构图可以看出Ooz

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 4344
4344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









