







目录
引言:为什么每个企业都需要一本“数据词典”?
在一家大型零售企业的会议室里,数据分析师张琳正为一份报表焦头烂额:
-
市场部问:“‘用户活跃度’为啥和上个月数据差了30%?”
-
开发组答:“我们用的是
usr_active_flag字段,但下游系统调用的是cust_login_status……” -
张琳苦笑:“这两个字段,压根不是一回事啊!”
这是无数企业的缩影:
-
技术侧:表名五花八门(
user_table、client_info),字段注释缺失; -
业务侧:指标定义模糊(“GMV”是否含退款?“活跃用户”是30天登录还是7天?);
-
治理侧:血缘分析耗时数天,一个小改动可能引发下游10个报表崩溃。
而答案藏在一本“数据词典”中——它不仅是技术文档,更是业务与技术的通用语言库,让“数据世界”从此说“普通话”。 通过将词根词库深度融入数仓中,企业可实现“字段名即业务语言”,例如:
-
字段
usr_active_d_cnt直接表达“日活跃用户数” -
指标
gmv_amt_m明确为“月累计交易金额(含税)”
这种语义化的数据资产体系,能显著降低沟通成本,支撑业务敏捷迭代。本文将讲解如何优雅的构建数仓字段建设?
一、词根:数据世界的“基因片段”
1. 什么是词根?
词根(Data Root)是数据语义的最小单元,像DNA一样决定数据的“遗传密码”:
-
普通词根:
usr(用户)、ord(订单)、amt(金额)——跨业务通用; -
专有词根:
cvr(转化率)、nft(非同质化代币)、aml(反洗钱)——行业专属术语; -
修饰词根:
d(日粒度)、sum(求和)、active(活跃状态)。
案例:
原字段名:customer_last_order_time
词根化命名:usr_ord_last_time_d
(usr=用户,ord=订单,last_time=末次时间,d=日粒度) 1.2. 词根的核心价值
-
统一语言:通过词根词库连接技术字段与业务术语(如
usr_login_cnt对应“用户登录次数”)。 -
消除歧义:解决“用户ID(user_id)”与“客户编号(cust_no)”混用问题,确保同一语义单元全局唯一。
-
支撑治理:基于词根关联数据血缘(如修改
pay_amt字段定义时,自动定位依赖的报表与API)。 -
加速协作:如企业通过词根标准化,促使新员工快速理解表结构
-
血缘追溯:通过词根快速定位异常(如修改
amt字段类型时,自动预警下游个聚合指标)
二、数据字典的核心维度
2.1 词根词库的本质
-
定义:词根是数仓的"业务最小语义单元",例如
usr(用户)、amt(金额)、cvr(转化率) -
词根分类体系
类别 定义 示例 命名规则 实体词根 核心业务对象 usr(用户)、ord(订单)、prod(商品)全小写,3-5字母缩写 属性词根 实体特征或状态 amt(金额)、status(状态)、type(类型)实体词根+属性(如 usr_age)操作词根 数据加工操作 cnt(计数)、sum(求和)、avg(平均)动词缩写,全小写(如 calc_avg)时间词根 时间维度与粒度 d(日)、m(月)、y(年)单字母或缩写(如 daily→d)业务专有词根 行业或企业特定术语 cvr(转化率)、roi(投资回报率)行业通用缩写(如金融用 apr年利率)
2.2 词根词库的分层分类
| 分类类型 | 示例词根 | 用途 |
|---|---|---|
| 普通词根 | usr(用户)、ord(订单) | 跨业务域通用 |
| 时间粒度 | d(日)、m(月) | 表分区/聚合周期标识 |
| 聚合操作 | cnt(计数)、sum(求和) | 指标命名规范 |
| 专有词根 | cvr(转化率)、aml(反洗钱) | 行业/场景特定术语 |
2.3 词根命名规范
-
组合规则
| 场景 | 格式 | 示例 | 说明 |
|---|---|---|---|
| 单实体+属性 | 实体词根_属性词根 | usr_age(用户年龄) | 禁止使用user_age非标缩写 |
| 复合操作 | 操作词根_实体词根 | cnt_order(订单数) | 操作在前,实体在后 |
| 时间范围聚合 | 实体词根_操作词根_时间 | usr_active_cnt_d(日活用户数) | 时间粒度放在末尾 |
| 业务专有指标 | 业务域_词根组合 | ads_cvr(广告转化率) | 业务域缩写+标准词根 |
-
禁止项
-
❌ 使用拼音缩写(如
yh代替usr) -
❌ 混用大小写(如
UserID应改为usr_id) -
❌ 冗余描述(如
total_amount_of_money→amt_total)
2.4 冲突解决机制
-
同义词合并规则
| 冲突类型 | 处理方案 | 案例 |
|---|---|---|
| 业务与技术命名差异 | 以业务术语优先,技术适配 | 业务方称“客户”,技术合并cust/client为cst |
| 跨系统字段重复 | 增加数据源标识 | erp_ord_no(ERP订单号) vs crm_ord_no |
| 一词多义 | 拆分词根并增加业务域前缀 | rate→loan_intr_rate(贷款利率) / ads_cvr_rate(广告转化率) |
-
自动化冲突检测(示例)
# 使用正则表达式检测非标命名
import re
def validate_naming(name):
pattern = r"^(usr|ord|amt)_[a-z0-9_]+$" # 允许的词根前缀
if not re.match(pattern, name):
raise ValueError(f"非标准命名: {name},建议使用词根库组合!")
# 测试案例
validate_naming("user_age") # 报错,应为`usr_age`
validate_naming("amt_total") # 通过示例:
-
结构:
层级_业务域_实体_属性_粒度_操作示例:dws_trade_ord_pay_amt_d_sum(DWS层交易域订单支付金额日汇总) -
冲突消解:
-
同义词合并(
cust→usr) -
多义词拆分(
rate→cvr、roi)
-
三、建设方法论
3.1 业务调研与术语收编
-
跨部门共创:联合业务专家、数据分析师、产品经理梳理核心流程(如电商的“交易域”包含下单、支付、履约);
-
逆向工程:通过元数据工具(如DataWorks、Apache Atlas)扫描现有表结构,提取高频字段名;
-
开放提报:建立在线平台,允许业务方提交新词根。
词根变更流程机制如下:
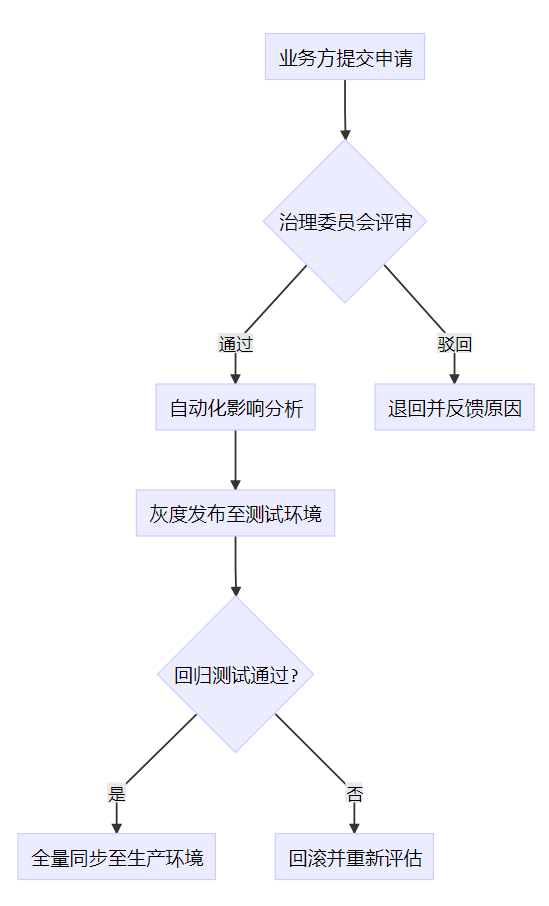
3.2 标准化处理四步法
-
冲突消解:合并同义词(
cust→usr)、拆分多义词(rate→cvr、roi); -
分类管理:按实体类、操作类、状态类、时间类划分词根(见下表);
-
组合规则:定义字段命名模板(层级业务域实体属性粒度_操作);
-
评审发布:治理委员会审核后,通过Git进行版本管理(如v2.1.3)。
| 分类类型 | 示例词根 | 用途 |
|---|---|---|
| 实体类 | usr、ord | 标识核心业务对象 |
| 操作类 | sum、cnt | 聚合逻辑标准化 |
| 状态类 | active、del | 数据生命周期标识 |
| 时间类 | d(日)、m(月) | 分区/聚合周期标识 |
3.3 自动化工具链增强
-
智能推荐:根据表主题域推荐词根组合(如交易域自动提示
pay_amt、refund_cnt) -
影响分析:当词根定义变更时,自动扫描依赖该词根的表、报表、API(如修改
gmv计算口径影响下游8个模型) -
版本控制:采用语义化版本管理词根库(如
v2.1.3新增nft词根)
四、 运营推广:长效治理与组织级渗透
4.1 分层培训体系
| 受众 | 培训内容 | 案例效果 |
|---|---|---|
| 开发人员 | 词根规范+工具使用(2小时实操) | 需求交付周期缩短40% |
| 业务分析师 | 词根与指标映射(1小时案例) | 减少60%术语解释工单 |
4.2 激励机制
-
量化考核:公示团队合规率排名;
-
资源倾斜:对词根覆盖率>95%的团队给予优先算力支持。
4.3 动态迭代机制
-
季度评审会:吸收新业务术语;
-
收益量化:统计因词根冲突减少的数据修复工单量。
五、工具链整合方案
| 场景 | 开源方案 | 商业方案 |
|---|---|---|
| 词根库管理 | Apache Atlas词根实体 + 血缘图谱 | Collibra业务术语库 |
| 开发阶段校验 | VSCode词根合规插件 | Alation数据目录 |
| 智能推荐 | 基于Elasticsearch的上下文推荐引擎 | Informatica语义层 |
| 变更影响分析 | DataHub血缘分析API | Manta血缘追踪 |
六、数据字典模板
数据仓库字典 - dws_trade_ord_pay_amt_d_sum
表基础信息
| 属性 | 内容 |
|---|---|
| 表名 | dws_trade_ord_pay_amt_d_sum |
| 中文名 | 交易域订单支付金额日汇总表 |
| 层级 | DWS (数据服务层) |
| 词根依赖 | trade(交易域), ord(订单), pay(支付), amt(金额), d(日), sum(汇总) |
| 更新频率 | 每日增量 |
| 负责人 | 张三 (zhangsan@company.com) |
字段定义
| 字段名 | 词根组合 | 数据类型 | 描述 | 业务规则说明 |
|---|---|---|---|---|
ord_id | ord_id | STRING | 订单唯一标识符 | 对接ERP系统的订单编号,全局唯一 |
pay_amt_sum_d | pay_amt_d_sum | DECIMAL | 当日支付金额汇总值(含税) | 统计当日所有订单的含税交易总额 |
数据血缘分析
| 方向 | 对象名称 | 关联类型 | 说明 |
|---|---|---|---|
| 上游依赖 | dwd_trade_ord_detail | 数据源表 | 订单明细表,提供订单基础支付数据 |
| 下游应用 | ads_report_gmv | 报表应用 | 用于GMV报表的日粒度统计 |
| 下游应用 | 风控API接口 | 数据服务接口 | 提供支付金额数据用于风控规则计算 |
安全与合规
| 属性 | 内容 |
|---|---|
| 敏感等级 | L2 (需脱敏) |
| 脱敏规则 | ord_id 需模糊化后3位,pay_amt_sum_d 允许明文展示 |
七、小结
关键成功要素
-
试点优先:从交易、用户等核心域切入,快速展现价值(某电商3个月覆盖80%核心模型)
-
工具闭环:词根库必须嵌入开发工具链(IDE/ETL/BI),而非独立文档
-
权责明确:数据架构师拥有词根终审权,业务方承担术语定义责任
-
度量驱动:定期公布词根覆盖率、命名冲突率、需求交付周期等指标
常见误区与优化建议
-
误区1:过度依赖人工维护 → 通过工具自动化提取元数据。
-
误区2:只写技术定义 → 需补充业务场景(如“GMV字段需排除退款订单”)。
-
误区3:忽略敏感数据标记 → 在字典中标注字段敏感等级。
未来展望
-
NLP驱动的词根生成:通过自然语言处理(NLP)解析业务文档,自动生成候选词根;
-
语义知识图谱:将词根与指标、报表、API关联,构建企业级数据语义网络;
-
跨企业词根联盟:行业共建通用词根库(如金融行业共享
aml、loan等标准术语)。
数据仓库字典建设将成为团队协作的“数据百科全书”,既能支撑日常开发,又能为数据治理提供基础能力。关键在于工具链闭环(采集→存储→更新→应用)和文化共识(全员参与维护)。
往期精彩
流量曝光归因SQL优化实战:如何将曝光事件精准关联到最近一次启动?
经典问题争议:数仓分层建设中,DWD、DWS、ADS哪一层最难?
球球 vs 懂车帝数仓岗位:数据资产沉淀主要是指DWS和ADS层的表吗?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









