







原文转载于:http://blog.csdn.net/shichaog/article/details/74143427 非常感谢。
波束形成
beamforming 体现的是声源信号的空域选择性,许多传统波束形成方法具有线性处理结构;波束形成需要考虑三个方面:
1.麦克风阵列个数;2.性能; 3.鲁棒性
在麦克风较少时,波束形成的空域选择性差,当麦克风数量较多时,其波束3dB带宽较为窄,如果估计的目标声源方向有稍有偏差,带来的影响也更大,鲁棒性不好。通常鲁棒性和性能是对矛盾体,需要均衡来看。
webrtc使用了如下几个点以提高鲁棒性和性能(其算法性能优先):
1.可以使用多个后置滤波器而非一个,2.每个后置滤波使用新的结构。
每个后置滤波器为每个声学场景的时频域bin在均方误意义上提供了最优实增益。在webrtc中后置滤波器根据声源的空域协方差矩阵,干扰源协方差矩阵,绕射场(零阶贝塞尔函数计算)以及临近麦克风的时频信号信息求得。
这样的话就可以为每个声源和干扰场景计算出不同的最优后置滤波器,也可以使用级联的方式灵活使用多个不同选择性的后置滤波器。
当前现存的波束形成算法的鲁棒性成为它们使用的一道门槛,如MVDR和多通道维纳滤波。
webrtc为了增强鲁棒性,在求最优矩阵时,对声源信号添加了限制条件,使用Gabor frame将声源变成时频bin的系数,对这些bin按照目标声源和干扰声源附加了条件,如果满足条件,则门操作让目标声源通过,而让干扰源乘以零以实现选择最优目标信号。
在webrtc中这些增益系数称为自适应标量(上面的实)乘法增益,均方误差准则被用来做为计算的准则。由于阵列方向响应随频率是变换的,而语音信号又是宽带信号,所以webrtc中使用了gabor变换来表示声音信号。增益源于目标信号和干扰的比例。
波动方程常有波数这个参数,相位的信息是通过实部和虚部表示出来的,列两个重要的参数。
波束形成类别
- 固定波束形成
滤波器权值固定,方法简单,运算量低,能够抑制背景噪声,对可变噪声场,效果一般。
delay-sum
算是最简单的波束形成方法,一般用在电话会议场景,对非相干噪声效果较好,如空间白噪声,然而,如果噪声源是相干的,降噪的程度依赖于噪声的方向,在室内混响场景下,并不能获得很好的效果。

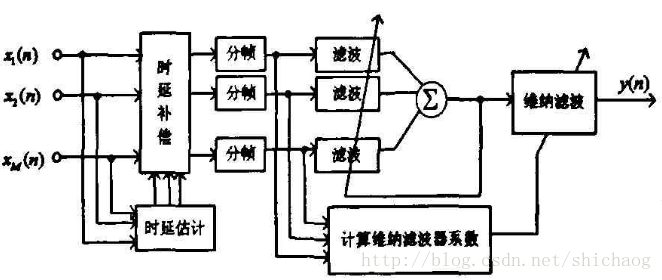
如Frost/mvdr等,在相干噪声场,可以得到较高的信噪比改善,但是在弱想干噪声场火灾散射噪声场中,性能不如固定波束形成。其一种结构可以如下:

可以用来去除非相干噪声,但是在相干噪声情况下性能退化,甚至不可用。zelinski后置滤波器的结构体如下:
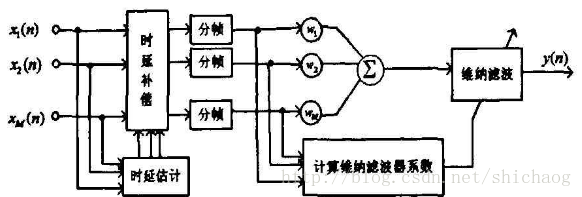

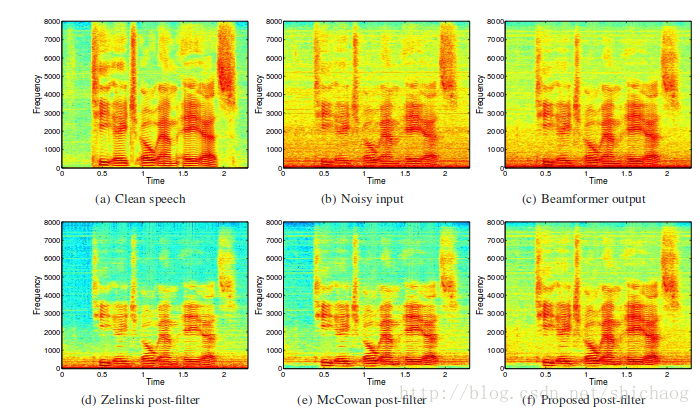
一张频谱图,可以反映它们之间的对比关系
相干和非相干噪声
相干噪声
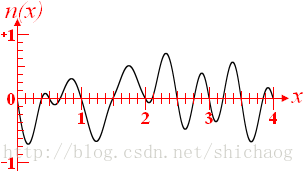
非相干噪声
波动方程
-
波数(k)
沿着波的传播方向单位长度内波的全周期数。 k=1/波长=fc ,也可定义成k=2pi/波长,这样可以理解成相位随距离的变化率。 -
空域混叠
对于时域有奈奎斯特定理 fs=1Ts≥2fmax(3.1)
在空间上,类似:
fxa=1d≥2fxmax
在波数方向图上,就是麦克风阵列旁瓣幅度可能大于主瓣幅度。 -
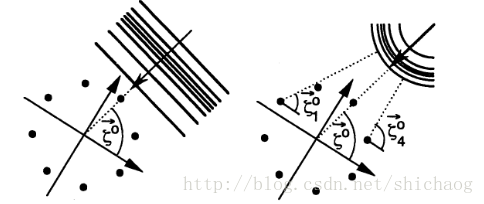
延迟和(delay-and-sum)
- filter-sum
- 分数delay
- 空时(space-time)滤波
- 相位变换法
- 小波变换法
- 滤波和
- 频域
- 分辨率
- 自适应波束形成
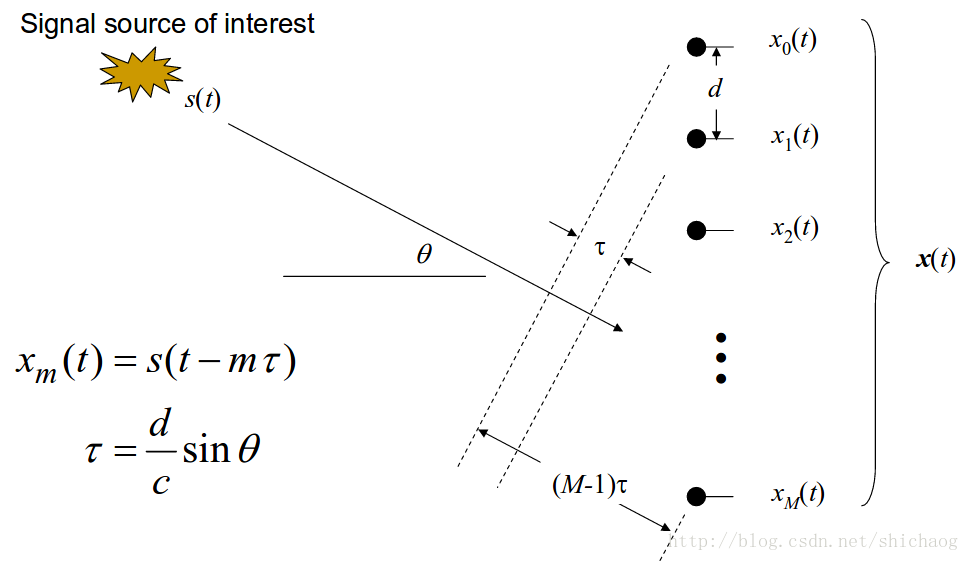
近场和远场

延迟和
设输入信号是
s(t)
,叠加噪声是加性的
n(t)
,则第m个麦克风观测到的信号是:
xm(t)=s(t)+nm(t)
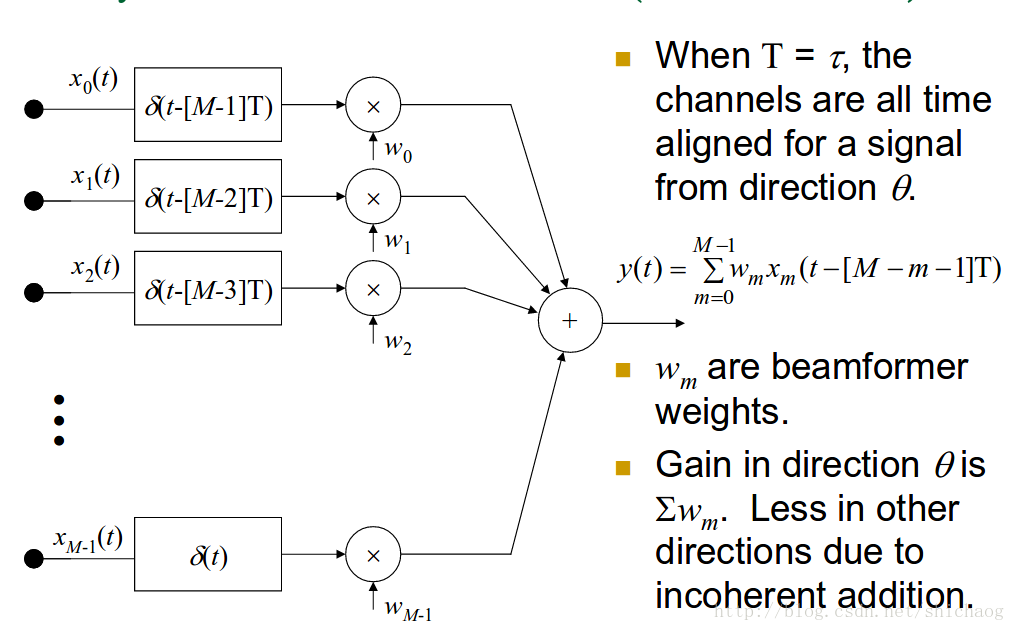
则延迟和输出是:
y(t)=∑m=0M−1wmxm(t−[M−m−1]T)
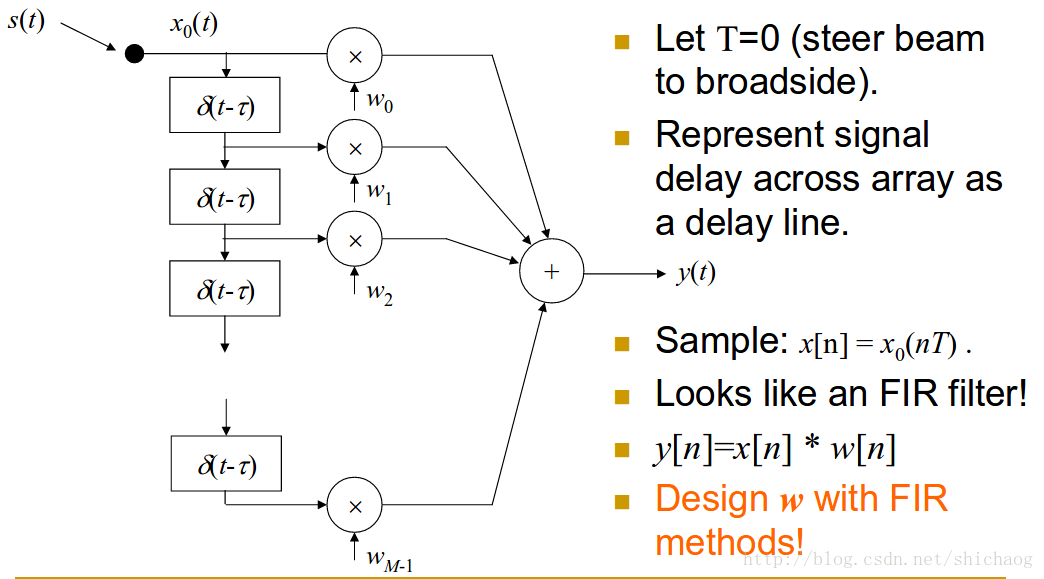
filter-and-sum
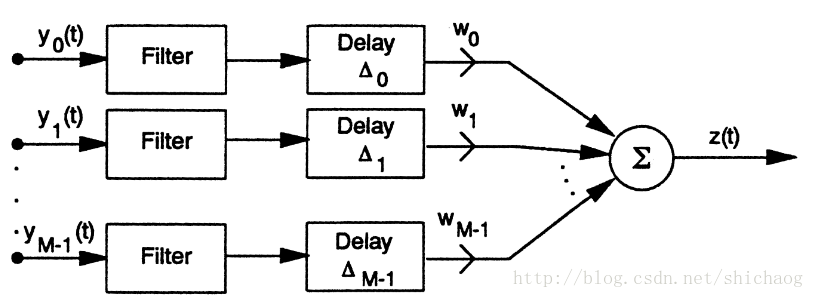
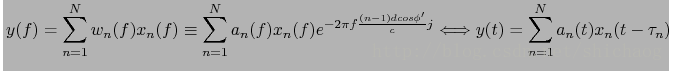
自适应波束形成算法
当噪声场在空间上是非相干的,仅仅降噪还是不够的,还需要后置滤波,
* 最小方差(Capon)波束形成
* 特征向量法(Eigenvector),
* GSC/TFGSC(Transfer function GSC)
* SVD
在降维,推荐系统等,信号盲源分离中用。
- NTT
方法复杂,但是和传统MVDR相比计算量并没特别大的增加。 - 线性预测法
- LVCM
- MVDR
为了鲁棒性,通常加对角阵扩大主瓣。
上述beamforming算法通常还会加后处理,以减小语音失真度。















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









