









1 串的基本概念
1.1 串的定义
串:( string)(或字符串)是由零个或多个字符组成的有限序列,一般记为s='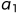
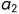 ...
...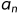 ',其中,s是串的名,用单引号括起来的字符序列是串的值;
',其中,s是串的名,用单引号括起来的字符序列是串的值;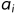 (1<i≤n)可以是字母、数字或其他字符;串中字符的数目n称为串的长度。零个字符的串称为空串(null string),它的长度为零。
(1<i≤n)可以是字母、数字或其他字符;串中字符的数目n称为串的长度。零个字符的串称为空串(null string),它的长度为零。
子串:串中任意个连续的字符组成的子序列称为该串的子串。包含子串的串相应地称为主串。通常称字符在序列中的序号为该字符在串中的位置。子串在主串中的位置则以子串的第一个字符在主串中的位置来表示。
说明∶串通常用一个字符数组来表示。从这个角度来讲,数组 str内存储的字特为'a'、'b'、'e'、 'd'、'e'、'f'、"\0',其中"\0'作为编译器识别串结来的标记。而串内字符为'a'、'b'、'c'、'd'、'e'、 'r'。因此数组 str的长度为7,而串 str的长度为6。
称两个串是相等的,当且仅当这两个串的值相等。也就是说,只有当两个串的长度相等,并且各个对应位置的字符都相等时才相等。比如'Nan Chang'与'NanChang'就不是两个相等的串,前者中间还有空格。
在各种应用中,空格常常是串的字符集合中的一个元素,因而可以出现在其他字符中间。由--个或多个空格组成的串′‘称为空格串(blank string,请注意;此处不是空串)。它的长度为串中空格字符的个数。为了清楚起见,以后我们用符号“"来表示“空串”。
1.2 串的存储结构
串的逻辑结构和线性表极为相似,区别仅在于串的数据对象约束为字符集。然而,串的基本操作和线性表有很大差别。在线性表的基本操作中,大多以“单个元素”作为操作对象,例如在线性表中查找某个元素、求取某个元素、在某个位置上插入一个元素和删除一个元素等;而在串的基本操作中,通常以“串的整体”作为操作对象,例如在串中查找某个子串、求取一个子串、在串的某个位置上插人一个子串以及删除一个子串等。
1.2.1 定长顺序存储表示
类似于线性表的顺序结构存储,用一组地址连续的存储单元存储串值的字符序列。在串定长顺序存储结构中,为每个串变量分配一个固定长度的存储区,即定长数组。
#define MAXSIZE 100 //字符串最长大小
typdef struct{
char ch[MAXSIEZ]; //每个字符存储
int length; //串的实际长度
}SString;注意∶不同的参考书对于串的结构体定义有所不同。有的用'\0'作为结束标记;有的不用'\0',而用 额外定义的length 变量来表示事长以及标记串的结束。本文的定义是,给串尾加上"\0'结柬标记,同时 也设定 length,这样做虽然多用了一个单位的存储空间,但这是代码中用起来最方便的形式。
1.2.2 变长分配存储表示
变长分配存储表示(又叫动态分配存储表示)方法的特点是,在程序执行过程中根据需要动态分配。 其结构体定义如下∶
typedef struct{
char *ch; //指向动态分配存储区首地址的字符指针
int length; //长度
}Str;变长分配页称为堆分配,在C语言中,存在一个称之为“堆”的自t存储区,并川 malloc ()和 free ( ) 函数来完成动态存储管理。利用malloc ()为每个浙产生的串分配一块实际串长所需的存储空间,若分配成功,则返回一个指向起始地址的指针,作为串的基地址,这个串由 ch 指针来指示:若分配失败.则返画NULL。己分配的空间可用f ee ()释放掉。
1.2.3 块链存储表示
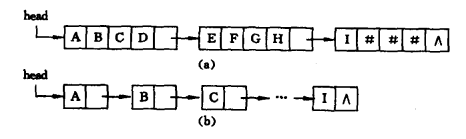
类似于线性表的链式存储结构,也可采用链表方式存储串值。由于串的特殊性(每个元素只有一个字符),在具体实现时,每个结点既可以存放一个字符,也可以存放多个字符。每个结点称为块,整个链长称为块链结构。图(a)是结点大小为4(即每个结点存放4个字符)的链表,最后一个结点古不满时通常用“#”补上:图(b)是结点大小为1的链表。
2 串的基本操作
对于串的基本操作集可以有不同的定义方法,读者在使用高级程序设计语言中的串类型时,应以该语言的参考手册为准。在上述抽象数据类型定义的13种操作中,串赋值StrAssign,串比较StrCompare,求串长StrLength、串联接Concat以及求子串SubString5种操作构成串类型的最小操作子集。即这些操作不可能利用其他串操作来实现,反之.其他串操作(除串清除ClearString和串销毁DestroyString外)均可在这个最小操作子集上实现。
(1)串赋值StrAssign()
与普通变量赋值操作不同,串的赋值操作不能直接用"="来实现。因为串是一个数组,如果将一个数组的值赋给另一个数组,则直接用"="是不可行的,必须对数组中的每个元素进行逐一赋值操作。串赋值操作函数 strassign()具体实现的代码如下所示,其功能是将一个常量字符串赋值给 str,赋值操作成功返回1.否则返回0。
int Btrasslgn(Str& str,char* ch){
if(str.ch)
free(str.ch); //释放原串空间
int len=0;
char *c=ch;
whfle(*c){ //求ch 串的长度
++len;
=+c;
}
if(len==0){ //如果 ch为空串,则直接返回空串
str.ch=NULL;
str.length=0:
return 1;
}
else{
str.ch=(char*)malloc(sizeof(char)*(len+1));
//取len+1是为了多分配一个空间存放"\0"字符
if(str.ch==NULL)
return 0;
else{
c=ch;
for(int i=0;i<=len;++i,++c){
str.ch[i]=*c;
/*注意∶循环条件中之所以用"<=",是为了将ch最后的'\0'复制到新串中作为结束标记*/
str.length=len;
return 1;
}
}
}数 strassign()使用时格式如下∶
strassign(str,"apple banana")(2)取串长操作strlength()
int strlength(Str str){
return str.length;
}如果在没有给出串长度信息的情况下,求串长度的操作可以借鉴函数 strassign()中的求输入串长度部分的代码来实现,也是非常简单的。
(3)串比较操作strcompare()
串的比较操作是串排序应用中的核心操作。例如,在单词的字典排序中,需要通过患比较操作来确定一个单词在字典中的位置,规则如下∶设两串 A和B中的待比较字符分别为a和b,如果a的ASCII 码小于b的 ASCII码,则返回A小于B标记;如果a的ASCII码大于b的 ASCII码,则返回A大于B 标记;如果a的 ASCII码等于b的 ASCII码,则按照之前的规则继续比较两串中的下一对字符。经过上述步骤,在没有比较出A 和B 大小的情况下,先结束的串为较小串,两串同时结束则返回两串相等标记。
int strcompare(Str s1,Str s2){
for(int i=0;i<s1.length;i++){
if(s1.ch[i]!=s2.ch[i])
return s1.ch[i]-s2.ch[i];
return s1.length-s2.length;
}(4)串连接操作
将两个串首尾相接,合并成一个字符串的操作称为串连接操作。
int concat(Str &str,Str str1,Str str2){
if(str.ch){
free(str.ch)
str,ch=NULL;
}
str.ch=(char*)malloc(sizeof(char)*(str1.length+str2.length));
if(str.ch==NULL)
return 0;
int i=0;
while(i<str1.length){
str.ch[i]==str.ch[i];
i++;
}
int j=0;
while(j<=str2.length){//注意,之所以用"<="是为了连同str2.ch最后的'\0'一起复制
str,ch[i+j]=str2.ch[j];
j++;
}
str.length=str1.length+str2.length;
return 1;
}(5)求子串操作 substring()
求从给定串中某一位置开始到某一位置结束的串的操作称为求子串操作(规定开始位置总在结束位置前面),如下面的代码实现了求 str 串中从pos 位置开始,长度为len 的子串,子串由 substr返回给用户。
int substring(Str& substr,Str str,int pos,int len){
if(pos<0||pos>=str,length||len<0||str>str.length-pos)
return 0;
if(substr.ch){
free(substr.ch);
substr.ch=NULL;
}
if(len==0){
substr.ch=NULL;
substr.length=0;
return 1;
}
else{
substr.ch=(char*)malloc(sizeof(char)*(len+1));
int i=pos;
int j=0;
while(i<pos+len){
subsr.ch[j]=str.ch[i];
i++;
j++;
}
substr.ch[j]='\0';
subtstr.length=len;
return 1;
}
}(6)串清除操作
int clearstring(Str &str){
if(str.ch){
free(str.ch);
str.ch=NULL;
}
str.length=0;
return 1;
}3 串的相关应用
3.1 求子串位置的定位
子串的定位操作通常称做串的模式匹配(其中T称为模式串),是各种串处理系统中最重要的操作之一。采用定长顺序存储结构,可以写出不依赖于其他串操作的匹配算法,如下列算法所示。
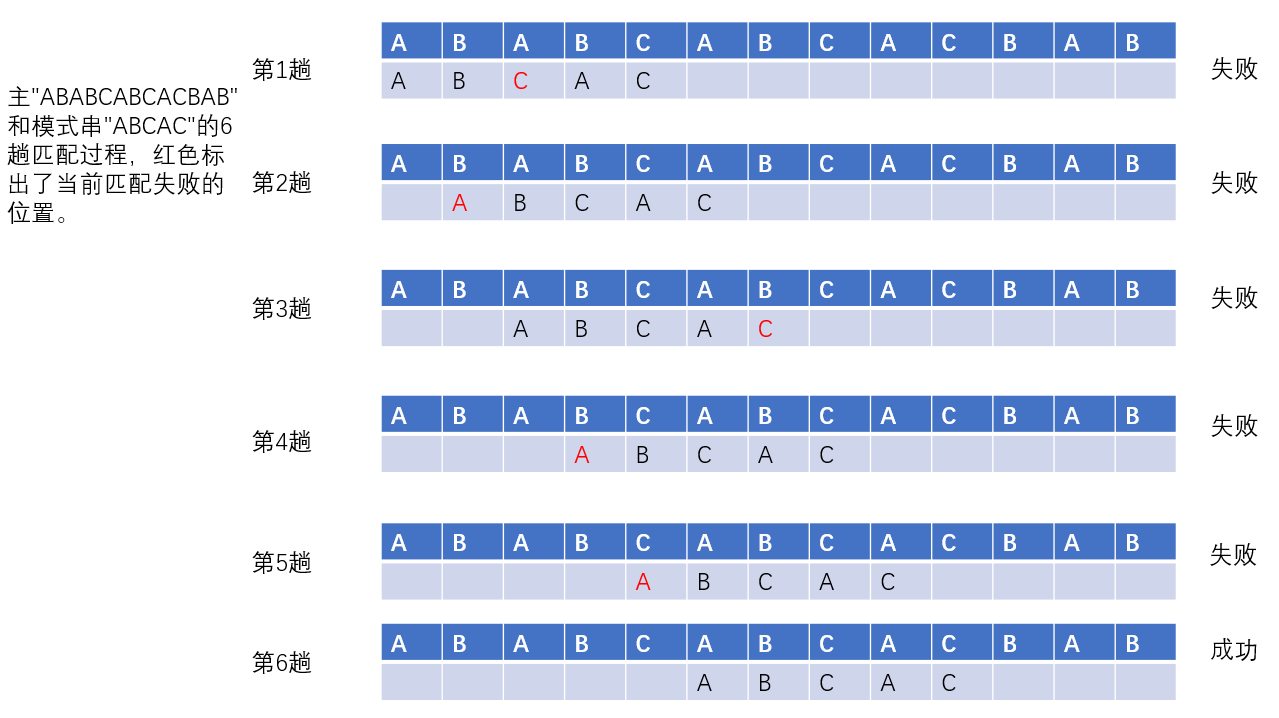
算法主要思想:在Index函数过程中,分别利用计数指针i和j指示主串S和模式串T中当前正待比较的字符位置。算法的基本思想是:从主串S的第pos个字符起和模式的第一个字符比较之,若相等,则继续逐个比较后续字符﹔否则从主串的下一个字符起再重新和模式的字符比较之。依次类推,直至模式T中的每个字符依次和主串S中的一个连续的字符序列相等,则称匹配成功,函数值为和模式T中第一个字符相等的字符在主串S中的序号,否则称匹配不成功,函数值为零。下图展示了模式T='abcac'和主串S的匹配过程(pos=1)。
主串"ABABCABCACBAB"和模式串"ABCAC"的6趟匹配过程,红色标出了当前匹配失败的位置。
实现代码如下:
int Index(SString S,SString T,int pos){
//返回子串T在主串s中第pos个字符之后的位置。若不存在,则函数值为0。
//其中,T非空,1≤pos≤StrLength(S)。
i=pos; j=1;
while(i<=S[0]&&j<=T[0]{
if(S[i]==T[j]){
i++;
j++;
}
}
if(j>T[0]) return i-T[0];
else return 0;
}最坏时间复杂度:O(nm),n,m分别为主串和模式串长度。
例如,当模式串为0000001',而主串'0000000000000000000000000000000000000000000001',由于模式中前6个字符均为“0"”,主串中前45个字符均为“0”,每趟[匹配都是比较到模式的最后一个字符时才发现不等,指针i需回溯40 次、总比较次数为40x7=280 次。
3.2 串的模式匹配算法——KMP
3.2.1 字符串的前缀、后缀和部分匹配值
要了解子串的结构,首先要弄清楚几个概念:前缀、后缀和部分匹配值。前缀指除最后一个字符以外,字符串的所有头部子串:后缀指除第一个字符外,字符串的所有尾部子串:部分匹配值则为字符串的前缀和后缀的最长相等前后缀长度。下面以'ababa '为例进行说明:
'a'的前缀和后缀都为空集,最长相等前后缀长度为0。
'ab'的前缀为{a},后缀为{b},{a}∩{b}=∅,最长相等前后缀长度为0。
'aba'的前缀为{a,ab},后缀为{a,ba},{a,ab}∩{a,ba}={a},最长相等前后缀长度为1。
'abab'的前缀为{a,ab,aba},后缀为{b,ab,bab},{a,ab,aba}∩{b,ab,bab}={ab},最长相等前后缀长度为2。
'ababa'的前缀为{a,ab,aba,abab},后缀为{a,ba,aba,baba},{a,ab,aba,abab}∩{a,ba,aba,baba}={a,aba},最长相等前后缀长度为3。
所以字符串'ababa'的部分匹配值为00123。
3.2.2 Next数组求法
由于上述3.1所采用的暴力求解方法,有一些不必要的遍历过程可以进行舍去,就比如第二趟中,在第一趟就已经知道了第二趟开头是B,于是我们就可以尝试着。所以可以用一个数组在遍历之前就进行存储相关移动的数据,也就是Next数组。(详细可以去看严蔚敏,吴伟民. 数据结构[M]. 北京:清华大学出版社.书中介绍)
next数组的求解方法:首先第一位的next值直接给0,第二位的next值直接给1,后面求解每一位的next值时,都要前一位进行比较。首先将前一位与其next值的对应位进行比较,若相等,则该位的next值就是前一位的next值加上1;若不等,继续重复这个过程,直到找到相等某一位,将其next值加1即可,如果找到第一位都没有找到,那么该位的next值即为1。
步骤如下:
(1)前两位固定为0,1
手动计算方法:前两位固定0,1不变
序号 | 1 | 2 | 3 | 4 | 5 | 6 |
模式串 | a | b | a | a | b | c |
next数组 | 0 | 1 |
(2)计算第三位的时候,看第二位b的next值为1,则把b和1对应的a进行比较,不同,则第三位a的next的值为1,因为一直比到最前一位,都没有发生比较相同的现象。
手动计算方法:看前两位字符的最大公共前后缀长度,ab最大公共前后缀长度位0,所以第三位Next数值为0+1=1
序号 | 1 | 2 | 3 | 4 | 5 | 6 |
模式串 | a | b | a | a | b | c |
next数组 | 0 | 1 | 1 |
(3)计算第四位的时候,看第三位a的next值为1,则把a和1对应的a进行比较,相同则第四位a的next的值为第三位a的next值加上1为2。因为是在第三位实现了其next值对应的值与第三位的值相同。
手动计算方法:看前三位字符的最大公共前后缀长度,aba最大公共前后缀长度位1,公共前后缀为a,所以第四位Next数值为1+1=1
序号 | 1 | 2 | 3 | 4 | 5 | 6 |
模式串 | a | b | a | a | b | c |
next数组 | 0 | 1 | 1 | 2 |
(4)计算第五位的时候,看第四位a的next值为2,则把a和2对应的b进行比较,不同则再将b对应的next值1对应的a与第四位的a进行比较,相同则第五位的next值为第二位b的next值加上1为2。因为是在第二位实现了其next值对应的值与第四位的值相同。
手动计算方法:看前四位字符的最大公共前后缀长度,abaa最大公共前后缀长度位1,公共前后缀为a,所以第五位Next数值为1+1=1
序号 | 1 | 2 | 3 | 4 | 5 | 6 |
模式串 | a | b | a | a | b | c |
next数组 | 0 | 1 | 1 | 2 | 2 |
(5)计算第六位的时候,看第五位b的next值为2,则把b和2对应的b进行比较,相同则第六位c的next值为第五位b的next值加上1为3,因为是在第五位实现了其next值对应的值与第五位相同。
手动计算方法:看前五位字符的最大公共前后缀长度,abaab最大公共前后缀长度位2,公共前后缀为ab,所以第四位Next数值为2+1=3
序号 | 1 | 2 | 3 | 4 | 5 | 6 |
模式串 | a | b | a | a | b | c |
next数组 | 0 | 1 | 1 | 2 | 2 | 3 |
代码实现:
void get_next(String T,int next[]){
int i=1,j=0;
next[i]=0;
while(i<T.length){
if(j==0||T.ch[i]==T.ch[i]{
i++,j++;
next[i]=j; //若pi=pj,则next[j+i]=next[j]+1;
}
else
j=next[j]; //否则令j=next[j],循环继续
}
}运用next数组构建的模式匹配算法KMP
int Index_KMP(String S,String T,int next[]){
int i=1,j=1;
while(i<=S.length&&j<=T.length[j]){
if(j==0||S.ch]i]==T.ch[j]){
i++,j++; //继续比较后面字符
}
else
j=next[j]; //模式串向后移动
}
if(j>T.length)
return i-T.length; //匹配成功
else
return 0;时间复杂度:O(m+n),n,m分别为主串和模式串长度。
尽管普通模式匹配的时间复杂度是O(mn),KMP算法的时间复杂度是O(m+n),但在一般情况下,普通模式匹配的实际执行时间近似为O(m + n),因此至今仍被采用。KMP算法仅在主串与子串有很多“部分匹配”时才显得比普通算法快得多,其主要优点是主串不回溯。
3.2.3 NextVal数组求法
求解nextval数组是基于next数组的,模式串每一个位置的字符和其next数组值给出的下标的对应位置的数作比较,相等就取nextval中对应的next数组值作为当前位置字符的nextval值,不等就直接取当前位置字符的next数组的值作为nextval的值。
(1)next-val数组第一个数直接为0。
序号 | 1 | 2 | 3 | 4 | 5 | 6 |
模式串 | a | b | a | a | b | c |
next数组 | 0 | 1 | 1 | 2 | 2 | 3 |
nextval数组 | 0 |
(2)next-val第二数:模式串第二个字符为b,对应的下标数组第二个数是1,那就是将模式串的第1个字符和b相比较,a!=b,所以直接将下标数组第二个数1作为nextval数组第二个数的值1
序号 | 1 | 2 | 3 | 4 | 5 | 6 |
模式串 | a | b | a | a | b | c |
next数组 | 0 | 1 | 1 | 2 | 2 | 3 |
nextval数组 | 0 | 1 |
(3)第三个数:模式串第三个字符为a,对应下标数组第三个数为1,取其作为下标,找到模式串第1个字符为a,a=a,那取next-val的第一个数做为nextval第三个数的值,也就是0
序号 | 1 | 2 | 3 | 4 | 5 | 6 |
模式串 | a | b | a | a | b | c |
next数组 | 0 | 1 | 1 | 2 | 2 | 3 |
nextval数组 | 0 | 1 | 0 |
(4)第四个数:模式串第四个字符为a,对应下标数组第四个数为2,取其作为下标,找到模式串第2个字符为b,a!=b,所以直接将下标数组第四个数2作为nextval数组第二个数的值2
序号 | 1 | 2 | 3 | 4 | 5 | 6 |
模式串 | a | b | a | a | b | c |
next数组 | 0 | 1 | 1 | 2 | 2 | 3 |
nextval数组 | 0 | 1 | 0 | 2 |
(5)第五个数:模式串第五个字符为b,对应下标数组第三个数为2,取其作为下标,找到模式串第2个字符为b,b=b,那取nextval的第二个数做为nextval第五个数的值,也就是1
序号 | 1 | 2 | 3 | 4 | 5 | 6 |
模式串 | a | b | a | a | b | c |
next数组 | 0 | 1 | 1 | 2 | 2 | 3 |
nextval数组 | 0 | 1 | 0 | 2 | 1 |
(6)第六个数:模式串第六个字符为c,对应下标数组第六个数为3,取其作为下标,找到模式串第3个字符为a,c!=a,所以直接将下标数组第六个数3作为nextval数组第二个数的值3
序号 | 1 | 2 | 3 | 4 | 5 | 6 |
模式串 | a | b | a | a | b | c |
next数组 | 0 | 1 | 1 | 2 | 2 | 3 |
nextval数组 | 0 | 1 | 0 | 2 | 1 | 3 |
nextval代码求解:
void get_nextval(String T,int nextval[]){
int i=1,j=0;
nextval[1]=0;
while(i<T.length){
if(j==0||T.ch[i]==T.ch[j]){
i++,j++;
if(T.ch[i]!=T.ch[j]) //如果前面字符与当前字符相等,则nextval值为前面字符的nextval值
nextval[i]=j;
else
nextval[i]=nextval[j];//不等就直接是当前的next数值的值
}
else
j=nextval[j];
}
}下面是实验平台模拟出来的结果:

3.2.4 next数组与nextval数组对比
next数组的缺陷举例如下:比如主串是"aabXXXXXXXXXXXXXX",模式串"aac"。通过计算 "aac" 的next数组为012,当模式串在字符c上失配时,会跳到第2个字符,然后再和主串当前失配的字符重新比较,即此处用模式串的第二个a和主串的b比较,即 "aabXXXXXXXXXXXXXX"vs"aac",显然a也不等于b。然后会跳到1接着比,直到匹配成功或者匹配失败主串后移一位。而"aac"的nextval数组为002 当在c失配时会跳到2,若还失配就直接跳到0,比next数组少比较了1次。在如果模式串很长的话,那可以省去很多比较,因此使用nextval数组比next数组高效。
3.3 字符串哈希
算法问题:
每个女孩都喜欢购物,蒲公英也是。现在,她发现这家店每天都在涨价,因为春节快到了。她很喜欢一家叫“memory”的店。现在她想知道这个商店的价格在每天变化后的排名。
输入:一行包含一个数字n (n<=10000),代表商店的数量。然后是n行,每行包含一个字符串(长度小于31,且只包含小写字母和大写字母),表示商店的名称。然后一行包含一个数字m (1<=m<=50),代表天数。然后m部分,每个部分包含n行,每一行包含一个数字s和一个字符串p,代表这一天,商店p的价格增加了s。
输出包含m行,在第i行打印商店“memory”的第i天后的排名的数字。我们将排名定义为:如果有t个商店的价格高于“memory”,那么它的排名为t+1。
算法思想:
(1)把字符串改成数字的形式存储起来,也就是把字符串的ASSIC值进行转化,然后再用这个ASSIC值将其转化成其他进制,进制转化也有特定的要求,需转化成13,31,1331,13331 ......等进制,因为有学者统计过,用这些进制转化之后,哈希冲突远比其他进制转化小。
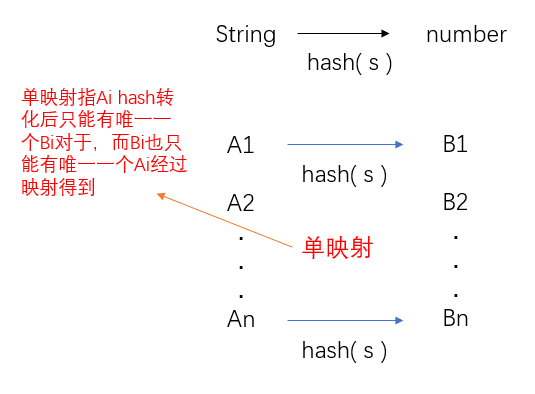

(2)解决哈希冲突,有三种方法,第一就是上述所讲的进制转化数字的选取;第二就是在发生冲突时候,寻找其他空闲位置进行存储;第三就是再哈希法,创建另外一个哈希转化进行存储。
实现代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 10005;
struct node{
char name[35];
int price;
};
vector<node>List[N]; // 用来解决冲突
unsigned int BKDRHash(char*str){ // 哈希函数
unsigned int seed = 31,key = 0;
while(*str)
key = key * seed + (*str++);
return key & 0x7fffffff;
}
int main()
{
int n,m,key,add,memory_price,rank,len;
int p[N];
char s[35];
node t;
while(cin >> n){
for(int i = 0; i < N;i++)
List[i].clear();
for(int i = 0; i < n; i++){
cin >> t.name;
key = BKDRHash(t.name) % N; //计算hash值并取余
List[key].push_back(t); //hash值可能冲突,把冲突的哈希值都存起来
}
cin >> m;
while(m--){
rank = len = 0;
for(int i = 0; i < n; i++){
cin >> add >> s;
key = BKDRHash(s) % N; //计算哈希值
for(int j = 0; j < List[key].size();j++){ //冲突问题处理
if(strcmp(List[key][j].name,s) == 0){
List[key][j].price += add;
if(strcmp(s,"memory") == 0){
memory_price = List[key][j].price;
}else{
p[len++] = List[key][j].price;
}
break;
}
}
}
for(int i = 0; i < len; i++){
if(memory_price < p[i])rank++;
}
cout << rank + 1 << endl;
}
}
return 0;
}
输入:
3
memory
kfc
wind
2
49 memory
49 kfc
48 wind
80 kfc
85 wind
83 memory
输出:
1
2
3.4 最长公共前缀
算法问题:编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入: ["flower","flow","flight"]
输出: "fl"
示例 2:
输入: ["dog","racecar","car"]
输出: ""
算法思想:
(1)当字符串数组长度为 0 时则公共前缀为空,直接返回
(2)令最长公共前缀 cp 的值为第一个字符串,进行初始化
(3)遍历后面的字符串,依次将其与 cp 进行比较,两两找出公共前缀,最终结果即为最长公共前缀
(4)如果查找过程中出现了 cp为空的情况,则公共前缀不存在直接返回
char * longestCommonPrefix(char ** strs, int strsSize){
int i,j,k;
char *cp = NULL ;
//char *cp1="";
if(!strsSize) //空数组情况
return "";
for(j=0; *(*strs+j) != '\0'; j++)
{
for(i=1; i<strsSize ;i++)
{
if( *(*(strs+i)+j) != *(*strs+j) ){
if(j==0)
return "";
else
{ cp = (char *)malloc(sizeof(char)*(j+1));
for(k=0;k<j;k++)
{
cp[k]=*(*strs+k);
}
cp[k]='\0';
return cp;
}
}
}
}
cp = (char *)malloc(sizeof(char)*(j+1));
for(k=0;k<j;k++)
{
cp[k]=*(*strs+k);
}
cp[k]='\0';
return cp;
}下面是实验平台运行结果:

3.5 最长公共子序列LCS
所谓的最长公共子序列,就说在两个字符串str1='ABCBDAB',str2='BDCABA',红色部分 'BCBA' 就是两个字符串的最长公共子序列。在这里,公共子序列的字符之间可以不是连续,所以公共最长子序列不唯一。
字符子串指的是字符串中连续的n个字符,如abcdefg中,ab,cde,fg等都属于它的字串。
字符子序列指的是字符串中不一定连续但先后顺序一致的n个字符,即可以去掉字符串中的部分字符,但不可改变其前后顺序。如abcdefg中,acdg,bdf属于它的子序列,而bac,dbfg则不是,因为它们与字符串的字符顺序不一致。
3.5.1 最长公共子数列长度
算法思想:采用动态规划的思想,先设一个二维数组,行代表字符串str1,列代表字符串str2。第一列和第一行都设置为0。0代表该行字符与列字符不相同。如果在行列字符比较不相同的时候,取上方数字作为当前数字;如果行、列相同,则从左上角数字加1。
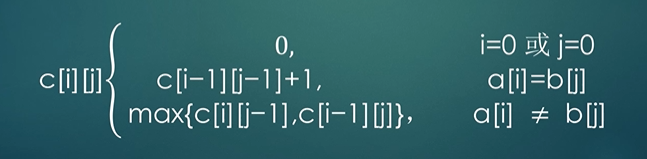
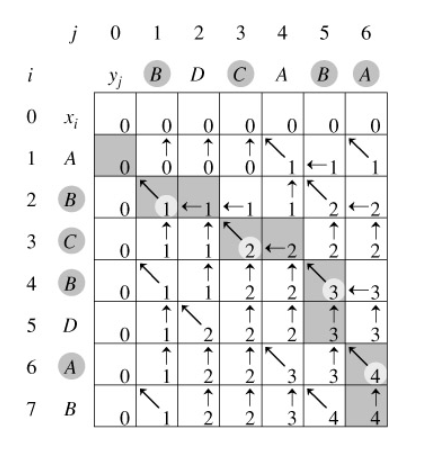
代码实现:
#include <cmath>
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <algorithm>
using namespace std;
char a[1001], b[1001];
int dp[1001][1001], len1, len2;
void lcs(int i,int j)
{
for(i=1; i<=len1; i++)
{
for(j=1; j<=len2; j++)
{
if(a[i-1] == b[j-1])
dp[i][j] = dp[i-1][j-1] + 1;
else if(dp[i-1][j] > dp[i][j-1])
dp[i][j] = dp[i-1][j];
else
dp[i][j] = dp[i][j-1];
}
}
}
int main()
{
while(~scanf(" %s",a))
{
scanf(" %s", b);
memset(dp, 0, sizeof(dp));
len1 = strlen(a);
len2 = strlen(b);
lcs(len1, len2);
printf("%d\n", dp[len1][len2]);
}
return 0;
}时间复杂度:O(n*m),n,m为两个字符串长度。
3.5.2 最长公共子数列
算法思想:通过上述最长子序列长度生成的二维数组,然后逆着找到最长子序列。如果左边、左上角、上面三个数字都比该数字小,则该数字是有左上角加1得到的;如果与左边数字相等,上方也相等则是由上方数字得到;如果与左上角数字大,而且左边数字等于该数字,则是由左边得到的;依次类推找到边上为止。
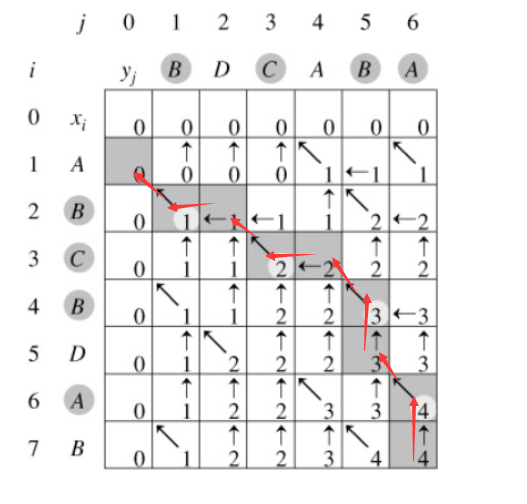
代码实现:
#include <iostream>
#include <cstring>
using namespace std;
const int N = 10;
int c[N][N], b[N][N];
char s1[N], s2[N];
int len1, len2;
void LCS()
{
for (int i = 1; i <= len1; i++) {
for (int j = 1; j <= len2; j++) {
if (s1[i - 1] == s2[j - 1]) { //注:此处的s1与s2序列是从s1[0]与s2[0]开始的
c[i][j] = c[i - 1][j - 1] + 1;
b[i][j] = 1;
}
else {
if (c[i][j - 1] >= c[i - 1][j]) {
c[i][j] = c[i][j - 1];
b[i][j] = 2;
}
else {
c[i][j] = c[i - 1][j];
b[i][j] = 3;
}
}
}
}
}
void LCS_PRINT(int i, int j)
{
if (i == 0 || j == 0) {
return;
}
if (b[i][j] == 1) {
LCS_PRINT(i - 1, j - 1);
cout << s1[i - 1];
}
else if (b[i][j] == 2) {
LCS_PRINT(i, j - 1);
}
else {
LCS_PRINT(i - 1, j);
}
}
int main()
{
cout << "请输入X字符串" << endl;
cin >> s1;
cout << "请输入Y字符串" << endl;
cin >> s2;
len1 = strlen(s1);
len2 = strlen(s2);
for (int i = 0; i <= len1; i++) {
c[i][0] = 0;
}
for (int j = 0; j <= len2; j++) {
c[0][j] = 0;
}
LCS();
cout << "s1与s2的最长公共子序列的长度是:" << c[len1][len2] << endl;
cout << "s1与s2的最长公共子序列是:";
LCS_PRINT(len1, len2);
return 0;
}下列是实验平台运行结果:

4 总结
在学习串这个章节时候,需要读者深入了解串的特性,因为串在许多算法中运用极为广泛。无论是最长前缀后缀子序列,还是KMP算法,或者是字典树,都是十分重要的知识,也是比较难掌握的知识,由于本文篇幅有限,有许多算法未能全部讲完,所以也需要读者自己去了解并掌握。
参考文献:
[1] 苏小红,孙志刚,陈惠鹏等编著. C语言大学实用教程(第四版)[M]. 北京:电子工业出版社,2017.
[2] 严蔚敏,吴伟民. 数据结构[M]. 北京:清华大学出版社.
[3] 罗勇君, 郭卫斌.算法竞赛_入门到进阶[M].北京:清华大学出版社.
作者:
江西师范大学_姜嘉鑫; 江西师范大学_龚俊















 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









