






方法不是我想的,只是转载,希望帮到更多的人
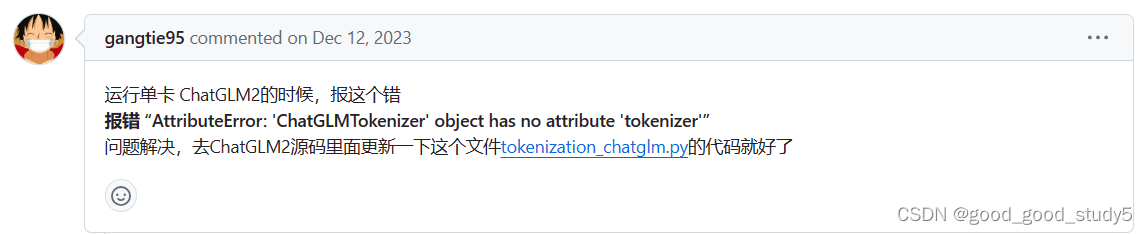
这里大家可以直接看原论坛:
论坛地址:https://github.com/liucongg/ChatGLM-Finetuning/issues/119
为了方便,可以直接一键复制我下面内容,替换CLM中tokenization_chatglm.py文件里面内容
import os
import torch
from typing import List, Optional, Union, Dict
from sentencepiece import SentencePieceProcessor
from transformers import PreTrainedTokenizer
from transformers.utils import logging, PaddingStrategy
from transformers.tokenization_utils_base import EncodedInput, BatchEncoding
class SPTokenizer:
def __init__(self, model_path: str):
# reload tokenizer
assert os.path.isfile(model_path), model_path
self.sp_model = SentencePieceProcessor(model_file=model_path)
# BOS / EOS token IDs
self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.unk_id()
assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()
special_tokens = ["[MASK]", "[gMASK]", "[sMASK]", "sop", "eop"]
self.special_tokens = {}
self.index_special_tokens = {}
for token in special_tokens:
self.special_tokens[token] = self.n_words
self.index_special_tokens[self.n_words] = token
self.n_words += 1
def tokenize(self, s: str):
return self.sp_model.EncodeAsPieces(s)
def encode(self, s: str, bos: bool = False, eos: bool = False) -> List[int]:
assert type(s) is str
t = self.sp_model.encode(s)
if bos:
t = [self.bos_id] + t
if eos:
t = t + [self.eos_id]
return t
def decode(self, t: List[int]) -> str:
return self.sp_model.decode(t)
def decode_tokens(self, tokens: List[str]) -> str:
text = self.sp_model.DecodePieces(tokens)
return text
def convert_token_to_id(self, token):
""" Converts a token (str) in an id using the vocab. """
if token in self.special_tokens:
return self.special_tokens[token]
return self.sp_model.PieceToId(token)
def convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
if index in self.index_special_tokens or index in [self.eos_id, self.bos_id, self.pad_id] or index < 0:
return ""
return self.sp_model.IdToPiece(index)
class ChatGLMTokenizer(PreTrainedTokenizer):
vocab_files_names = {"vocab_file": "tokenizer.model"}
model_input_names = ["input_ids", "attention_mask", "position_ids"]
def __init__(self, vocab_file, padding_side="left", clean_up_tokenization_spaces=False, **kwargs):
self.name = "GLMTokenizer"
self.vocab_file = vocab_file
self.tokenizer = SPTokenizer(vocab_file)
self.special_tokens = {
"<bos>": self.tokenizer.bos_id,
"<eos>": self.tokenizer.eos_id,
"<pad>": self.tokenizer.pad_id
}
super().__init__(padding_side=padding_side, clean_up_tokenization_spaces=clean_up_tokenization_spaces, **kwargs)
def get_command(self, token):
if token in self.special_tokens:
return self.special_tokens[token]
assert token in self.tokenizer.special_tokens, f"{token} is not a special token for {self.name}"
return self.tokenizer.special_tokens[token]
@property
def unk_token(self) -> str:
return "<unk>"
@property
def pad_token(self) -> str:
return "<unk>"
@property
def pad_token_id(self):
return self.get_command("<pad>")
@property
def eos_token(self) -> str:
return "</s>"
@property
def eos_token_id(self):
return self.get_command("<eos>")
@property
def vocab_size(self):
return self.tokenizer.n_words
def get_vocab(self):
""" Returns vocab as a dict """
vocab = {self._convert_id_to_token(i): i for i in range(self.vocab_size)}
vocab.update(self.added_tokens_encoder)
return vocab
def _tokenize(self, text, **kwargs):
return self.tokenizer.tokenize(text)
def _convert_token_to_id(self, token):
""" Converts a token (str) in an id using the vocab. """
return self.tokenizer.convert_token_to_id(token)
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
return self.tokenizer.convert_id_to_token(index)
def convert_tokens_to_string(self, tokens: List[str]) -> str:
return self.tokenizer.decode_tokens(tokens)
def save_vocabulary(self, save_directory, filename_prefix=None):
"""
Save the vocabulary and special tokens file to a directory.
Args:
save_directory (`str`):
The directory in which to save the vocabulary.
filename_prefix (`str`, *optional*):
An optional prefix to add to the named of the saved files.
Returns:
`Tuple(str)`: Paths to the files saved.
"""
if os.path.isdir(save_directory):
vocab_file = os.path.join(
save_directory, self.vocab_files_names["vocab_file"]
)
else:
vocab_file = save_directory
with open(self.vocab_file, 'rb') as fin:
proto_str = fin.read()
with open(vocab_file, "wb") as writer:
writer.write(proto_str)
return (vocab_file,)
def get_prefix_tokens(self):
prefix_tokens = [self.get_command("[gMASK]"), self.get_command("sop")]
return prefix_tokens
def build_prompt(self, query, history=None):
if history is None:
history = []
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n\n问:{}\n\n答:{}\n\n".format(i + 1, old_query, response)
prompt += "[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
return prompt
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A BERT sequence has the following format:
- single sequence: `[CLS] X [SEP]`
- pair of sequences: `[CLS] A [SEP] B [SEP]`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
prefix_tokens = self.get_prefix_tokens()
token_ids_0 = prefix_tokens + token_ids_0
if token_ids_1 is not None:
token_ids_0 = token_ids_0 + token_ids_1 + [self.get_command("<eos>")]
return token_ids_0
def _pad(
self,
encoded_inputs: Union[Dict[str, EncodedInput], BatchEncoding],
max_length: Optional[int] = None,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
pad_to_multiple_of: Optional[int] = None,
return_attention_mask: Optional[bool] = None,
) -> dict:
"""
Pad encoded inputs (on left/right and up to predefined length or max length in the batch)
Args:
encoded_inputs:
Dictionary of tokenized inputs (`List[int]`) or batch of tokenized inputs (`List[List[int]]`).
max_length: maximum length of the returned list and optionally padding length (see below).
Will truncate by taking into account the special tokens.
padding_strategy: PaddingStrategy to use for padding.
- PaddingStrategy.LONGEST Pad to the longest sequence in the batch
- PaddingStrategy.MAX_LENGTH: Pad to the max length (default)
- PaddingStrategy.DO_NOT_PAD: Do not pad
The tokenizer padding sides are defined in self.padding_side:
- 'left': pads on the left of the sequences
- 'right': pads on the right of the sequences
pad_to_multiple_of: (optional) Integer if set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Core on NVIDIA hardware with compute capability
`>= 7.5` (Volta).
return_attention_mask:
(optional) Set to False to avoid returning attention mask (default: set to model specifics)
"""
# Load from model defaults
assert self.padding_side == "left"
required_input = encoded_inputs[self.model_input_names[0]]
seq_length = len(required_input)
if padding_strategy == PaddingStrategy.LONGEST:
max_length = len(required_input)
if max_length is not None and pad_to_multiple_of is not None and (max_length % pad_to_multiple_of != 0):
max_length = ((max_length // pad_to_multiple_of) + 1) * pad_to_multiple_of
needs_to_be_padded = padding_strategy != PaddingStrategy.DO_NOT_PAD and len(required_input) != max_length
# Initialize attention mask if not present.
if "attention_mask" not in encoded_inputs:
encoded_inputs["attention_mask"] = [1] * seq_length
if "position_ids" not in encoded_inputs:
encoded_inputs["position_ids"] = list(range(seq_length))
if needs_to_be_padded:
difference = max_length - len(required_input)
if "attention_mask" in encoded_inputs:
encoded_inputs["attention_mask"] = [0] * difference + encoded_inputs["attention_mask"]
if "position_ids" in encoded_inputs:
encoded_inputs["position_ids"] = [0] * difference + encoded_inputs["position_ids"]
encoded_inputs[self.model_input_names[0]] = [self.pad_token_id] * difference + required_input
return encoded_inputs
感谢观看,如果有用请点赞评论支持一下。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









