






一、环境配置
系统配置——ubuntu16.04
显卡——RTX2080Ti
cuda10.0+cudnn7.5.0——参考 https://blog.csdn.net/wanzhen4330/article/details/81699769
Python3.6+Anaconda
PyTorch1.0.0——官网 https://pytorch.org/get-started/previous-versions/
conda install pytorch==1.0.0 torchvision==0.2.1 cuda100 -c pytorch
超级慢
添加清华镜像源,重新下装
conda install pytorch==1.0.0 torchvision==0.2.1 cuda100
二、git clone
git clone -b pytorch-1.0 --single-branch --depth=1 --recursive https://github.com/jwyang/faster-rcnn.pytorch.git
其中:-b是分支名,--single-branch是clone指定分支的命令,--depth==1是只克隆最近一次更改,--recursive用于循环递归克隆子项目。
三、训练前准备
- 创建数据文件夹
cd faster-rcnn.pyroch
mkdir data
- 下载数据集
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
太慢,不推荐
有镜像网站 https://pjreddie.com/projects/pascal-voc-dataset-mirror/
下载后解压,解压后的目录结构如下:
——data
————local
————results
————VOCdevkit2007
——————VOC2007
————————Annotations
————————ImageSets
————————JPEGImages
————————SegmentationClass
————————SegmentationObject
————VOCcode
- 预训练模型
VGG16: https://filebox.ece.vt.edu/~jw2yang/faster-rcnn/pretrained-base-models/vgg16_caffe.pth
ResNet101:https://filebox.ece.vt.edu/%7Ejw2yang/faster-rcnn/pretrained-base-models/resnet101_caffe.pth
基于caffe训练的模型要比基于pytorch训练的模型表现好些。下载完以后,把这两个模型都放进/data/pretrained_model/里。
- 下载相关安装包
pip install -r requirements.txt
贴一下我的安装包版本
cython==0.29.21
cffi==1.11.5
opencv-python==4.3.0.36
scipy==1.0.0
msgpack==1.0.0
easydict==1.9
matplotlib==3.3.0
pyyaml==5.3.1
tensorboardX==2.1
- 编译CUDA依赖环境
cd lib
python setup.py build develop
训练
在训练之前,设置 正确的保存和加载模型的目录,改变trainval_net和test_net.py中的参数save_dir和loader_dir以适应你的环境。
使用vgg16在pascal_voc上训练你的faster-rcnn模型,运行下面代码:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py \
--dataset pascal_voc --net vgg16 \
--bs $BATCH_SIZE --nw $WORKER_NUMBER \
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP \
--cuda
bs是batch size,默认为1
dataset是要在什么数据集上训练
net是你要使用的预训练模型,可以换为resnet101
epoch是要训练的轮数
nw是number work,我的显卡显存是11G,可以进行4线程读取,如果显存小的话就设为1
lr是学习率
lr_decay_step 8: 每几个epoch学习率衰减一次(默认衰减一次0.1,通过decay_gamma可调);可选参数
use_tfb: 使用tensorboardX实现记录和可视化,不用就不写;可选参数
mGPUs: 多GPU训练,不用就不写该命令;可选参数
cuda:使用cuda;
由上, BATCH_SIZE 和 WORKER_NUMBER 可以根据你的GPU情况来设置。
我的参数设置如下
CUDA_VISIBLE_DEVICES=0 python trainval_net.py --dataset pascal_voc --net res101 --bs 4 --nw 0 --lr 0.001 --lr_decay_step 5 --cuda --use_tfb
运行出现一个错误
ImportError: cannot import name '_mask'
解决——安装CoCO API
cd data
git clone https://github.com/pdollar/coco.git
cd coco/PythonAPI
make
cd ../../..
再运行就OK了
训练loss可视化
进入到faster-rcnn.pytorch文件下
pip install tensorboard
tensorboard --logdir=logs/logs_s_1/losses/ --port=7001
进入网页得到loss曲线

测试
python test_net.py --dataset pascal_voc --net vgg16 \
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT \
--cuda
具体参数根据得到的模型设置
python test_net.py --dataset pascal_voc --net res101 --checksession 1 --checkepoch 18 --checkpoint 2504 --cuda
结果
AP for aeroplane = 0.7395
AP for bicycle = 0.7692
AP for bird = 0.7679
AP for boat = 0.6246
AP for bottle = 0.5593
AP for bus = 0.7996
AP for car = 0.8363
AP for cat = 0.8708
AP for chair = 0.5058
AP for cow = 0.8168
AP for diningtable = 0.6224
AP for dog = 0.8573
AP for horse = 0.8494
AP for motorbike = 0.7673
AP for person = 0.7781
AP for pottedplant = 0.4604
AP for sheep = 0.7470
AP for sofa = 0.7415
AP for train = 0.7469
AP for tvmonitor = 0.7353
Mean AP = 0.7298
训练自己的数据
制作自己的数据
-
数据集放置
注意四个文件夹JPEGImages、Annotations、ImageSets/Main、LabelImages
制作自己的数据集替换下这四个文件夹原来的数据即可
JPEGImages——输入图像
Annotations——图像标签的xml文件
ImageSets/Main——自己制作的trainval.txt、test.txt、 train.txt和val.txt文件
LabelImages——图像标签(有框框) -
python文件修改
第一处:改类名faster-rcnn.pytorch/lib/datasets/pascal_voc.py
 3.修改参数
3.修改参数faster-rcnn.pytorch/lib/model/utils/config.py
Initial learning rate = 0.001
momentum = 0.9
weight_decay = 0.0005
batch_size = 4
epoch = 100
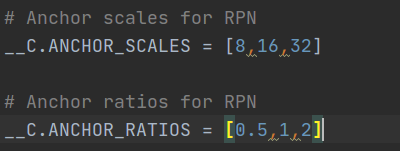
RPN相关参数
batch_size = 16
anchor_scales = (1.375, 2.25, 3.5, 5.75)
anchor_ratios = (0.8, 1, 1.2)
训练结束

测试阶段
出错
 解决——我的数据集标签中没有pose,去把它注释掉就可以了
解决——我的数据集标签中没有pose,去把它注释掉就可以了

truncated也没有,也注释掉。
测试
python test_net.py --dataset pascal_voc --net res101 --checksession 1 --checkepoch 100 --checkpoint 473 --cuda
结果

改了几处的参数,结果


还是不行还要改进
改了参数,ovthresh原来是0.5改为0
 训练
训练
CUDA_VISIBLE_DEVICES=0 python trainval_net.py --dataset pascal_voc --net res101 --bs 4 --nw 0 --lr 0.001 --lr_decay_step 40 --cuda --use_tfb
结果
















 8867
8867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









