






1.进栈和出栈顺序


2. 避免struct的对齐优化

加上__attribute__((packed)),可以防止编译器对结构进行字节对齐优化。
使用__attribute__((aligned(0)))(0为对齐字节数),强制编译器按照0字节对齐。
3. compile 和match
re模块:
import re
re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,他对所有的语言都通用。
re.compile()
re.compile()是用来优化正则的,它将正则表达式转化为对象.
compile(pattern, flags=0)
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等
re.compile()生成的是正则对象,单独使用没有任何意义,需要和findall(), search(), match()搭配使用
pattern.findall() and pattern.match()
re.compile()结合findall(),返回一个列表
pattern.match()总是从字符串‘开头曲匹配’,并返回匹配的字符串的 match 对象
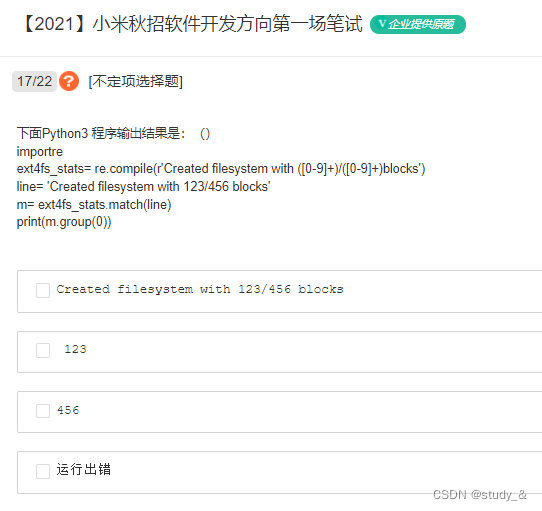
import re
ext4fs_stats= re.compile(r'Created filesystem with ([0-9]+)/([0-9]+) blocks')
line= 'Created filesystem with 123/456 blocks'
m= ext4fs_stats.match(line)
print(m.group(0)) #Created filesystem with 123/456 blocks
n=ext4fs_stats.findall(line)
print(n) #[('123', '456')]
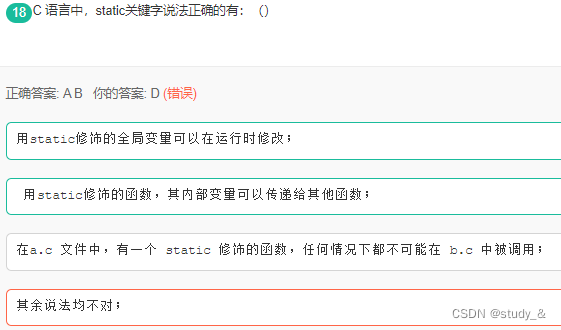
4. C语言中static关键字
5. C++中重载运算符
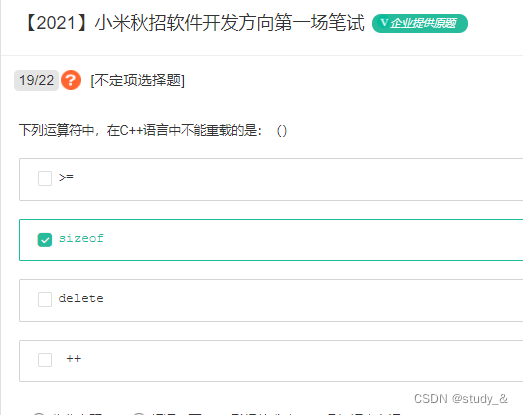
并不是所有的运算符都可以重载。能够重载的运算符包括:

要注意长度运算符sizeof、条件运算符: ?、成员选择符.和域解析运算符::不能被重载。
6.查找的时间复杂度
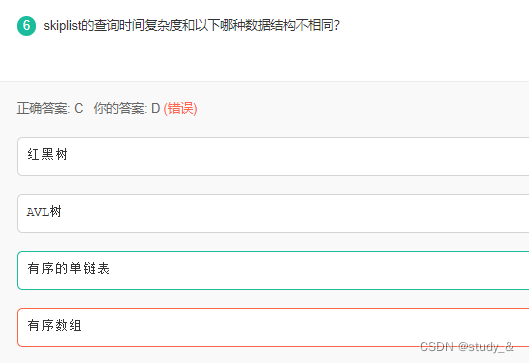
查找:
红黑树,是一颗二叉搜索树,O(log2n)
AVL树,是一颗二叉排序树,O(log2n)
单链表,查找O(n),插入删除O(1)
有序数组,二分查找O(log2n)
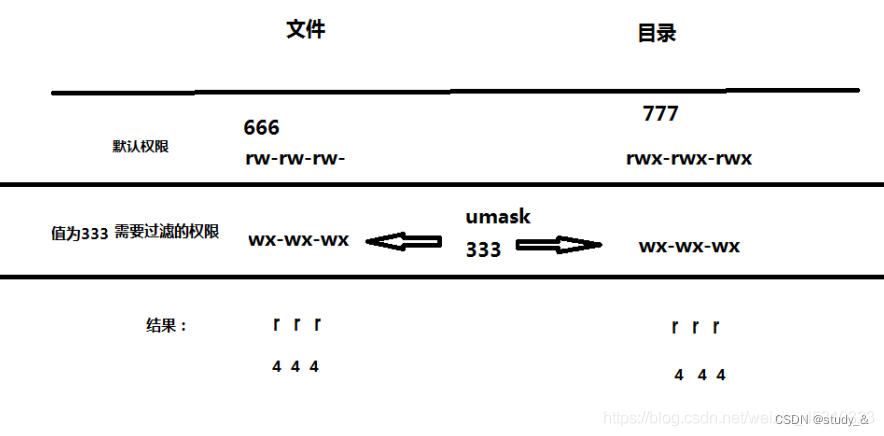
7. touch和umask命令用法

touch命令主要用法是创建一个空文件,touch命令后面跟创建的文件名,如果没有已存在文件则会创建一个空文件,如果有已存在的文件则会更新,创建时间,和修改时间,为当前时间。
umask的中文意思是(去除) 在这里可以理解成(权限过滤符)顾名思义,在创建目录或者文件时都有一个默认创建权限,而umask命令就是用来修改,创建目录或者文件时的默认权限。
8. 首地址和值的区别
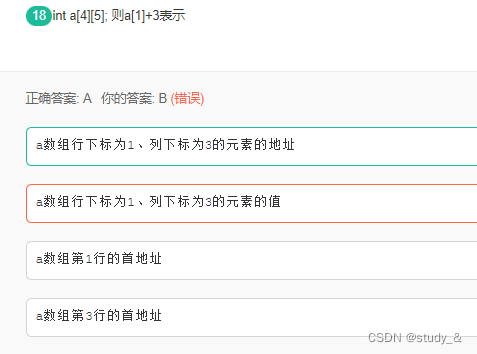
a[1]+3 = &a[1][0]+3 ,也就是&a[1][3]
类似于int a[3]; a+2 的时候a退化为a[0]的地址
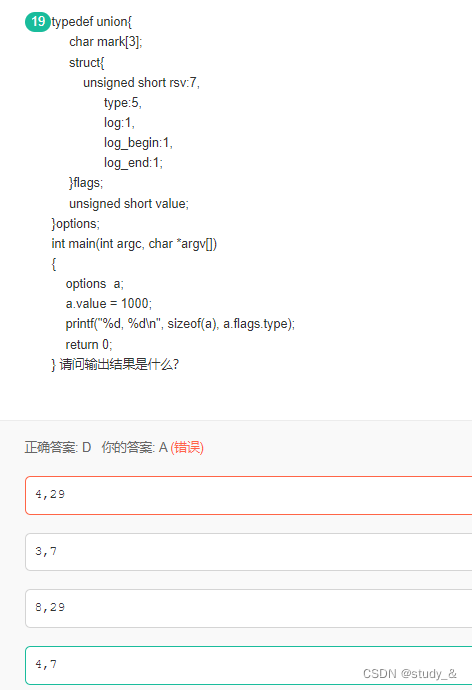
9.
10.检查远端服务器端口命令

常用测试远程主机端口是否打开方法:
- telnet 110.101.101.101 80方式
- nmap ip -p port 测试端口
nmap ip 显示全部打开的端口
根据显示close/open确定端口是否打开 - nc -v host port
端口未打开返回状态为非0
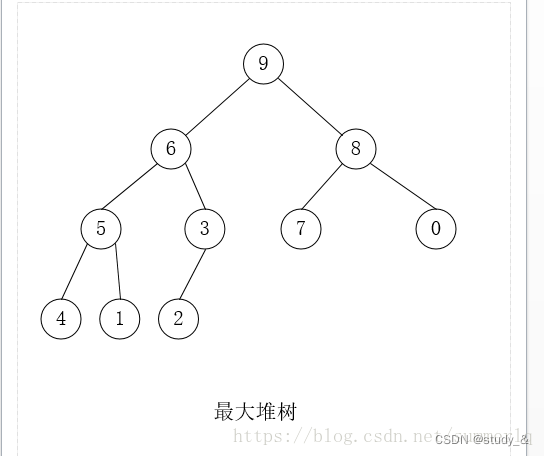
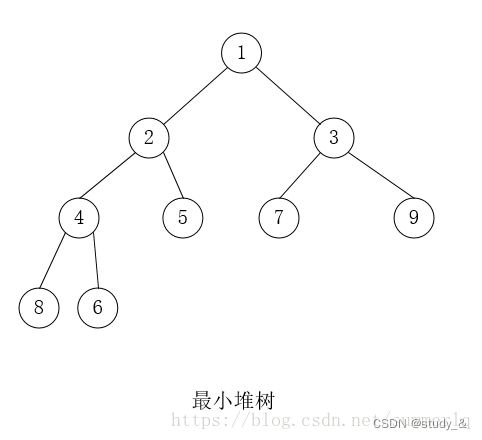
11. 最小堆
![已知最小堆序列[1 5 8 6 7 11 9], 插入3后变成:](https://img-blog.csdnimg.cn/7c8026a467f7446fb7b2e0bc1ee1d60a.png)
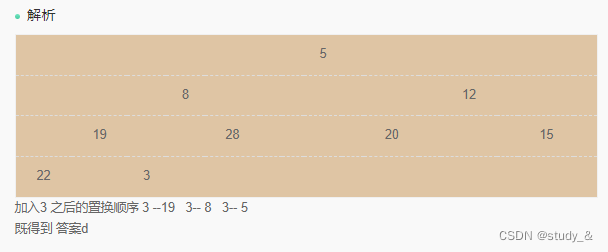
最大堆、最小堆
1、堆是一颗完全二叉树;
2、堆中的某个结点的值总是大于等于(最大堆)或小于等于(最小堆)其孩子结点的值。
3、堆中每个结点的子树都是堆树。
12. 概率求解
将一颗骰子掷3次,至少出现一次6点向上的概率是多少?
解答:
只要求出事件的对立事件“每次都不是6点”的概率,然后用1减就可以了
每次不出现6点,则要在6种可能中选择其他5种,所以每次概率都是5/6
因此三次就是5/6×5/6×5/6=125/216
所以至少出现1次6点的概率是1-125/216=91/216
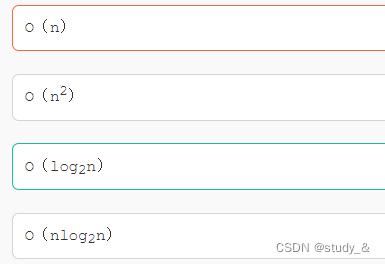
13.查找\排序的时间复杂度
在长度为n 的有序线性表中进行二分查找,最坏情况下需要的比较次数时间复杂度是( )。

说明:1、顺序查找:
(1)最好情况:要查找的第一个就是。时间复杂度为:O(1)
(2)最坏情况:最后一个是要查找的元素。时间复杂度未:O(n)
(3)平均情况下就是:(n+1)/2。
所以总的来说时间复杂度为:O(n)
2、二分查找:O(log2n)->log以2为底n的对数
解释:2^t = n; t = log(2)n;(t代表查找次数)
最好情况:要查找的第一个mid就是。时间复杂度为:O(1)
最坏情况:最后一个是要查找的元素。时间复杂度O(log2n)

14.vector::erase()返回值
下列代码编译运行后的结果是()


解答:
erase的解释和用法:
vector::erase():从指定容器删除指定位置的元素或某段范围内的元素
vector::erase()方法有两种重载形式
如下:
iterator erase( iterator _Where);
iterator erase( iterator _First, iterator _Last);
如果是删除指定位置的元素时:
返回值是一个迭代器,指向删除元素下一个元素;
如果是删除某范围内的元素时:返回值也表示一个迭代器,指向最后一个删除元素的下一个元素;
vecNum.erase(iter);执行完毕后,iter指向的值被删除,iter也被释放。因此接下的 ++ iter 会在执行的时候报错导致程序崩溃。因为iter此时是无指向的。
正确写法:iter=vecNum.erase(iter); //我们将erase的返回值赋给iter,则程序正常执行。
15.基类指针指向派生类对象、派生类指针指向基类对象
以下代码运行后的输出结果是()
#include using namespace std;
class A
{
public:
void virtual print()
{
cout << "A" << endl;
}
};
class B : public A
{
public:
void virtual print()
{
cout << "B" << endl;
}
};
int main()
{
A* pA = new A();
pA->print();
B* pB = (B*)pA;
pB->print();
delete pA, pB;
pA = new B();
pA->print();
pB = (B*)pA;
pB->print();
}
using namespace std;
class A{
public:void virtual print(){
cout << "A" << endl;}
};
class B : public A{
public:void virtual print(){
cout << "B" << endl;}
};
int main(){
A* pA = new A();//基类指针指向基类对象
pA->print();
B* pB = (B*)pA;//派生类指针指向基类对象
pB->print();
delete pA, pB;
pA = new B();//基类指针指向派生类对象
pA->print();
pB = (B*)pA;//派生类指针指向派生类对象
pB->print();
}

解答:
-
A* pA = new A()//基类指针指向基类对象,毫无疑问调用的是A类的print
输出A -
B* pB = (B*)pA;//派生类指针指向基类对象,这里疑问会比较大。首先是为什么这里不会报错,为什么派生类指针指向基类对象可以成立?理论上指针的可访问范围一定大于对象的大小,会指向一些未知区域导致运行出错,但是要注意的是,这个题目里面B类不存在新增数据成员,所以不会出错。还有就是由于是基类对象,还没有发生虚函数掩盖
输出A -
pA = new B();//基类指针指向派生类对象。基类指针之所以可以访问派生类对象是因为指针的可访问范围一定小于对象的大小,所以做完切割即可,即切割一些派生类中存在而基类中不存在的成员即可。此时派生类对象的vptr指向的虚函数表中,派生类虚函数已经把基类同名虚函数掩盖掉了,所以指向的肯定是派生类虚函数
输出B -
pB = (B*)pA;//派生类指针指向派生类对象。注意此时pA指向的是派生类对象
输出B
总结:(在分析完运行不出错的前提下)看指向的对象是啥类型,而不是看指针的类型
这题涉及到的知识点
虚函数预备常识
需要知道一些常识,一个类所有的函数都是再code代码区中唯一的存放一份。而数据成员则是每个对象存储一份,并按照声明顺序依次存放。
类A中有了虚函数就会再类的数据成员的最前面添加一个vfptr指针(void** vfptr),这个指针用来指向一个vtable表(一个函数指针数组)(一个类只有一个该表),该表存储着当前类的所有 虚函数 的地址。这样vfptr就成为了一个类似成员变量的存在。访问虚函数的时候通过vfptr间址找到vtable表,再间址进而找到要调用的函数。这样就在一定程度上摆脱了类型制约。
示例:
(People类是基类,student类是People类的派生类, Senior类是Student派生类)
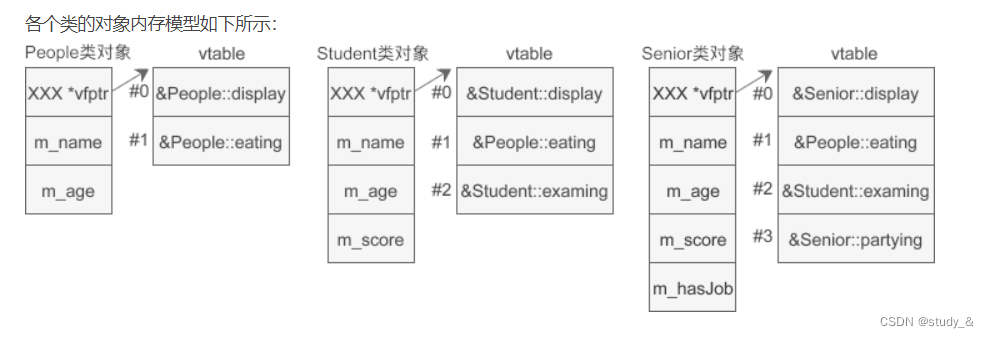
(在虚函数表中,基类的虚函数在 vtable 中的索引(下标)是固定的,不会随着继承层次的增加而改变,派生类新增的虚函数放在 vtable 的最后。如果派生类有同名的虚函数遮蔽(覆盖)了基类的虚函数,那么将使用派生类的虚函数替换基类的虚函数,这样具有遮蔽关系的虚函数在 vtable 中只会出现一次。)
只要vptr的值不同,那么访问函数成员的时候使用的vtable表就不同,就可能访问到不同类的函数成员。B类对象中的vptr指向B类自己的vtable。
当B类继承A类的时候,因为A中有虚函数,编译器就自动的给B类添加vfprt指针和vtable表。也可以理解为B类继承来了A类中的那个vptr指针成员。
当A类指针指向B类对象时,发生假切割。要知道这个过程只是切掉A类中没有的那些成员。(即当People类指针指向Student类对象时,切割掉m_score这个People类中没有的成员)
由于vptr是从A类中继承来的,所以这个量仍将保留。而对于vptr的值则不会改变,仍然指向B类的vtable表。所以访问F1函数的时候是通过B类的vtable表去寻址的,自然就是使用子类的函数(拿图中的情况举例,子类的Student::display()函数已经覆盖了People::display()函数,此时A类指针访问虚函数display()时也是访问到子类的Student::display()函数)。
当B类的指针指向A类的对象时(当B类存在新增数据成员时可能出错),同理。
而对于普通函数则受类型的制约,(因为没有vptr指针)使用哪个类的指针调用函数,那么所调用的就是那个累的函数。
总而言之,普通函数通过对象或指针的类型来找所调用的函数,而虚函数是通过一个指针来找到所要调用的函数的。
示例
#include <iostream.h>
class A
{
public:
virtual void F1()
{
cout<<"A1"<<endl;
}
void F2()
{
cout<<"A2"<<endl;
}
};
class B :public A
{
public:
void F1()
{
cout<<"B1"<<endl;
}
void F2()
{
cout<<"B2"<<endl;
}
};
void main(){
A *pa;
B *pb;
B TB;
A TA;
pa = &TB;//基类指针指向派生类对象
pa->F1();
pa->F2();
pb =(B *) &TA;//派生类指针指向基类对象
pb->F1();
pb->F2();
}
输出:
B1
A2
A1
B2
基类指针指向派生类对象:如果基类声明的不是虚函数就调用基类的,如果是虚函数并在派生类中实现,就调用派生类的函数;
派生类指针指向基类对象:如果基类声明的是虚函数就调用基类的,如果不是虚函数并在派生类中实现,就调用派生类的函数.结果就知道了
参考
【1】牛客网
【2】touch,umask,文件隐藏属性,文件特殊权限,file
【3】linux 检测远程端口是否打开
【4】数据结构——小顶堆的构建,添加,删除
【5】常用的排序/查找算法的时间复杂度和空间复杂度
【6】几种查找的时间复杂度
【7】C++ 派生类指针指向基类对象















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









