







整体框架
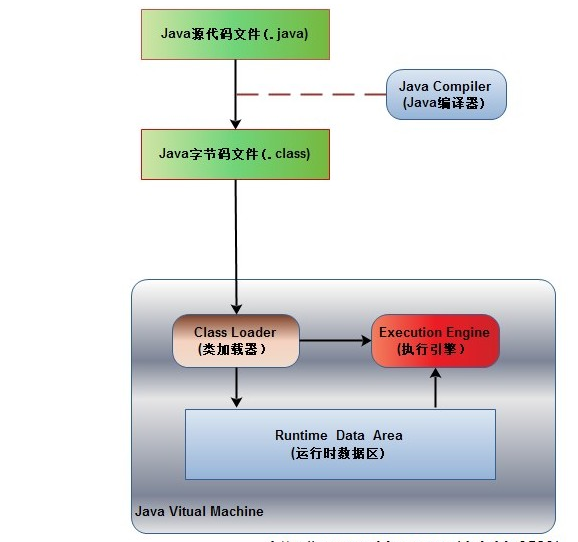
以内存的形式整体分析流程
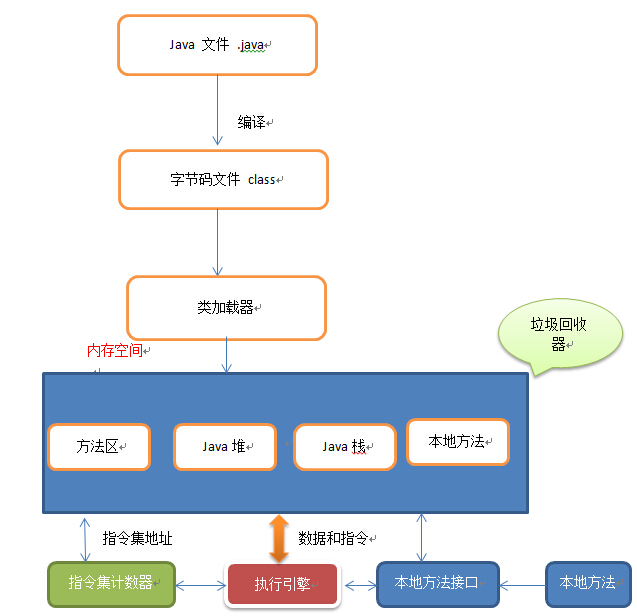
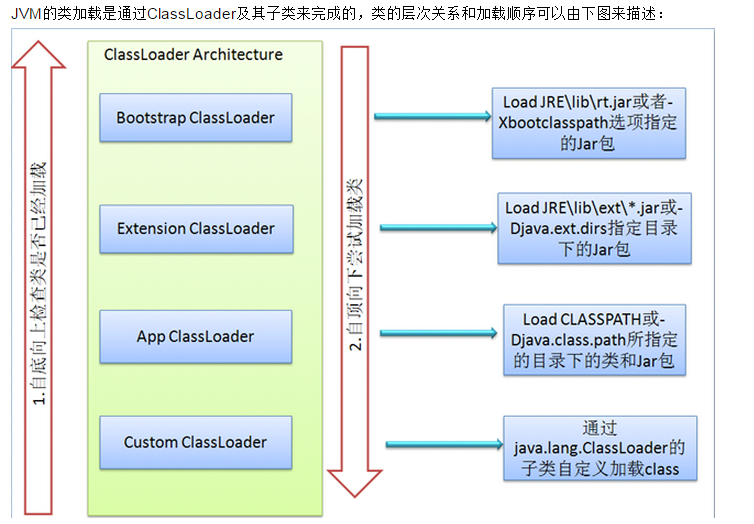
类加载过程:
以编译过程的形式的整体流程
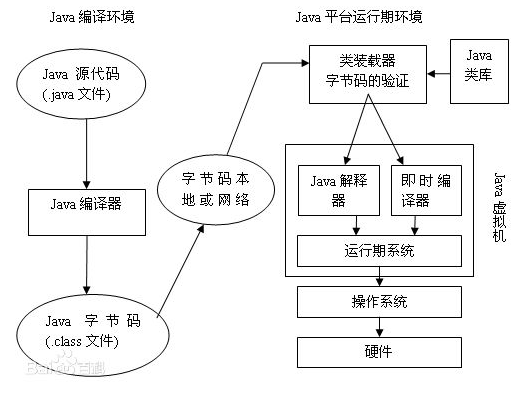
即时编译和解释执行:
java程序最初是仅仅通过解释器解释执行的,即对字节码逐条解释执行,这种方式的执行速度相对会比较慢,尤其当某个方法或代码块运行的特别频繁时,这种方式的执行效率就显得很低。于是后来在虚拟机中引入了JIT编译器(即时编译器),当虚拟机发现某个方法或代码块运行特别频繁时,就会把这些代码认定为“Hot Spot Code”(热点代码),为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各层次的优化,完成这项任务的正是JIT编译器
现在主流的商用虚拟机(如Sun HotSpot、IBM J9)中几乎都同时包含解释器和编译器(三大商用虚拟机之一的JRockit是个例外,它内部没有解释器,因此会有启动相应时间长之类的缺点,但它主要是面向服务端的应用,这类应用一般不会重点关注启动时间)。二者各有优势:当程序需要迅速启动和执行时,解释器可以首先发挥作用,省去编译的时间,立即执
行;当程序运行后,随着时间的推移,编译器逐渐会返回作用,把越来越多的代码编译成本地代码后,可以获取更高的执行效率。解释执行可以节约内存,而编译执行可以提升效率。
HotSpot虚拟机中内置了两个JIT编译器:Client Complier和Server Complier,分别用在客户端和服务端,目前主流的HotSpot虚拟机中默认是采用解释器与其中一个编译器直接配合的方式工作。
运行过程中会被即时编译器编译的“热点代码”有两类:
被多次调用的方法。
被多次调用的循环体。
基于采样的热点探测:采用这种方法的虚拟机会周期性地检查各个线程的栈顶,如果发现某些方法经常出现在栈顶,那这段方法代码就是“热点代码”。这种探测方法的好处是实现简单高效,还可以很容易地获取方法调用关系,缺点是很难精确地确认一个方法的热度,容易因为受到线程阻塞或别的外界因素的影响而扰乱热点探测。
基于计数器的热点探测:采用这种方法的虚拟机会为每个方法,甚至是代码块建立计数器,统计方法的执行次数,如果执行次数超过一定的阀值,就认为它是“热点方法”。这种统计方法实现复杂一些,需要为每个方法建立并维护计数器,而且不能直接获取到方法的调用关系,但是它的统计结果相对更加精确严谨
在HotSpot虚拟机中使用的是第二种——基于计数器的热点探测方法,因此它为每个方法准备了两个计数器:方法调用计数器和回边计数器。
在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的阀值,当计数器的值超过了阀值,就会触发JIT编译。触发了JIT编译后,在默认设置下,执行引擎并不会同步等待编译请求完成,而是继续进入解释器按照解释方式执行字节码,直到提交的请求被编译器编译完成为止(编译工作在后台线程中进行)。当编译工作完成后,下一次调用该方法或代码时,就会使用已编译的版本。
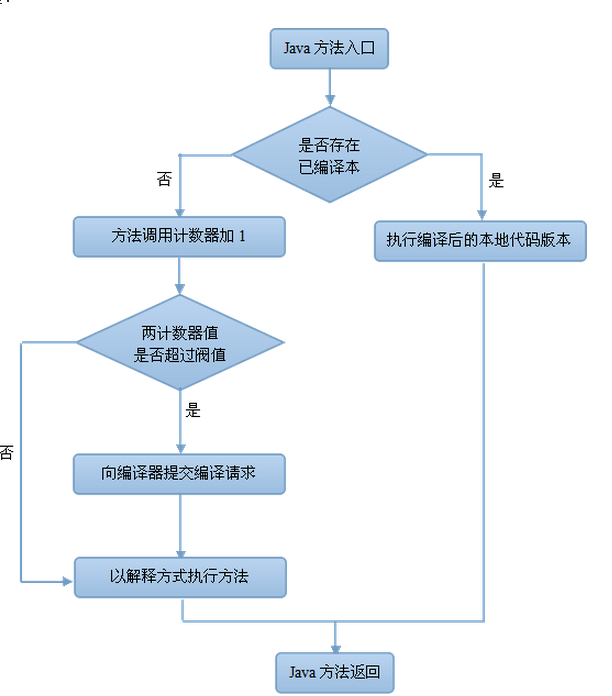
Javac字节码编译器与虚拟机内的JIT编译器的执行过程合起来其实就等同于一个传统的编译器所执行的编译过程。
我们知道JVM是基于栈执行的,每个线程会建立一个操作栈,每个栈又包含了若干个栈帧,每个栈帧包含了局部变量、操作数栈、动态连接、方法的返回地址信息等。其实在我们编译的时候,需要多大的局部变量表、操作数深度等已经确定并写入了Code属性,因此运行时内存消耗的大小在启动时已经已知。
1:运行时数据区
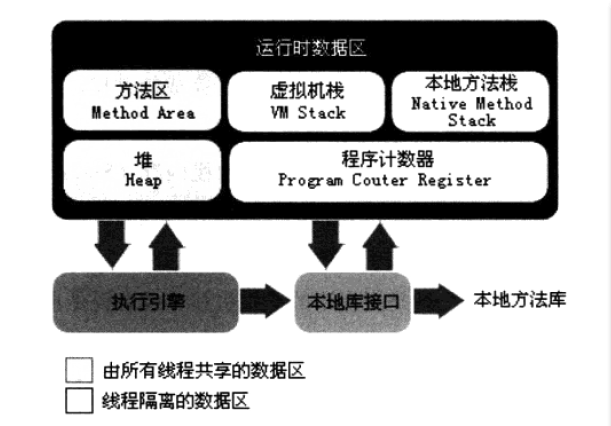
整个运行时分布
2:程序计数器
概念:是一块较小的内存空间,可以看做是当前线程所执行的子界面的行号指示器。在虚拟机的概念中,字节码解释器工作时就是通过程序计数器的值来选取下一行要执行的字节码指令,分支,循环,跳转,异常处理线程的恢复都需要依赖这个计数器来完成.
Java 虚拟机是轮流执行多线程操作,在任何时间处理器只能执行一行指令所以为了每次线程恢复都可以恢复到准确的位置,所以说每个线程都需要独立的程序计数器.每个线程的计数器独立存在互不影响,是线程私有的独立内存空间
如果线程执行的是一个java程序 则计数器记录是正在执行的字
节码地址,如果是native方法则计数器为null;
整个文章也是我从整体到部分的理解,结构图也是借鉴很多前辈的加上自己对jvm 认识















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









